







CVPR 2024
大多数神经压缩模型都是在大规模图像或视频数据集上进行训练,为了更强的泛化性。
提出C3,将一个小模型分别过拟合到单个图像或视频中,而不是将一个大模型泛化到所有图像或视频。
C3的解码复杂度比具有相似RD性能的基线低一个数量级。
用MAC(multiply-accumulate:乘法累加)操作的次数衡量解码的复杂度。
贡献
1.首次在单幅图像上提出低复杂度的编解码器,与VTM匹配,但解码所需的MAC比现有的编解码器少一个量级。
2.扩展到视频场景,以低于0.1%的解码复杂度匹配VCT的RD性能。
局限性
专注于提高RD性能同时最小化解码复杂度。因此,C3的编码速度较慢,不能实时编码。
但在某些情况下是有用的,如:在流媒体服务中,一个流行的视频被编码一次,但解码数百万次。
COOL-CHIC
原始的COOL-CHIC网络,一个很普通的AE结构。
区别在于COOL-CHIC是单图像压缩方法,其中所有组件都只适应每个图像,牺牲泛化性为代价降低bpp。
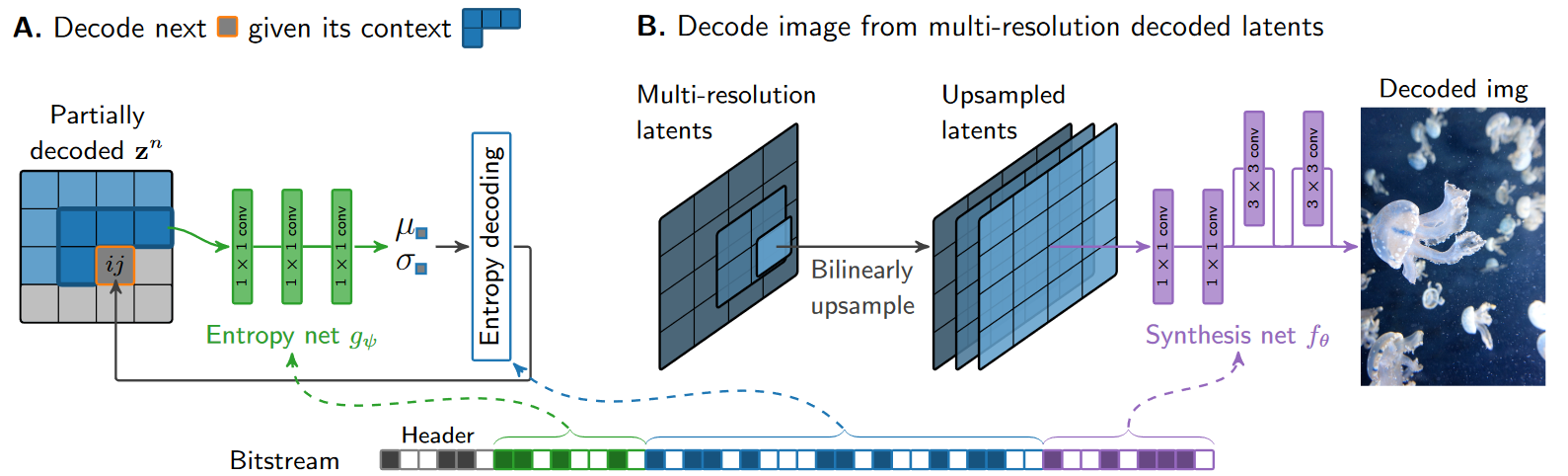
用多分辨率网格提取图片特征z,网格默认大小(h,w),(h/2,w/2),…,(h/2N−1, w/2N−1)。
用多分辨率特征上采样得到特征,再经过合成网络θ得到预测图像。
多分辨率特征经过量化,熵编码变成比特流进行保存,熵编码网络ψ和合成网络θ参数也保留(用于无损压缩)。
隐变量z和参数ψ,θ通过RD权重λ来权衡更好的重建结果和更可压缩的隐变量。
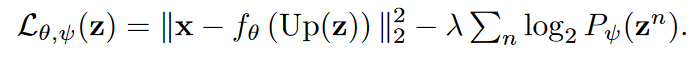
优化过程分为两步:
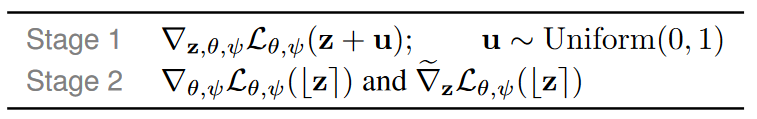
Stage 1:计算损失函数Lθ,ψ 相对于z,θ和ψ的梯度,u是[0,1]区间内均匀分布的随机变量。
Stage 2:计算损失函数 Lθ,ψ相对于θ和ψ梯度,输入为⌊z⌉(即z取整)。
计算 Lθ,ψ相对于z的近似梯度∇~z,输入同样为⌊z⌉。
C3
对COOL-CHIC进行了一系列简单有效的改进,称为Cooler-ChiC(C3)。
在相似的译码复杂度下,显著提高了RD性能。
优化改进
保持了COOL- CHIC的两阶段优化结构,但在两个阶段都做了一些改进,最值得注意的是如何近似量化。
1.在加入噪声前后应用一个软取整函数。这个函数的平滑程度由温度参数T控制。
对于大的T值,趋近于恒等变换;对于小的T值,趋近于四舍五入。
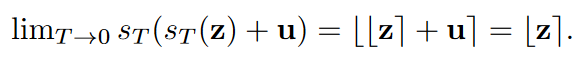
通过T,可以在四舍五入和简单的均匀噪声加法之间进行变换。
虽然软化四舍五入不创建信息瓶颈,但仍需要添加噪声以确保可靠的压缩效果。
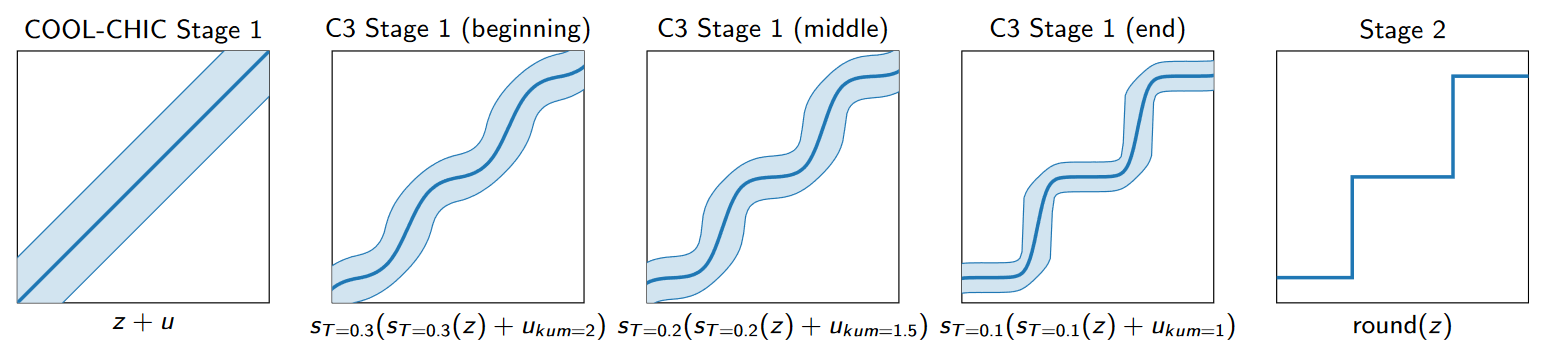
2. 用Kumaraswamy分布替代均匀噪声,在逼近四舍五入时具有更低的梯度方差,提升了压缩效果。
3.在前向传播中对潜在变量z用硬量化,在后向传播中用软量化估计梯度,并以很低的T开始第二阶段。
4.当RD损失在固定步数内未改善时,自适应地降低学习率。
模型改进
1.引入多分辨率潜在网格,允许特定位置的上下文也包含来自前一个网格的值,P(zn|zn-1)。
2.激活函数改变:ReLU → GELU
3.Adaptivity:可选择性地扫描每个图像或视频块的多个架构选择,以在每个实例的基础上找到最佳的RD-tradeoff。如:对于低比特率,不使用高分辨率的潜在网格可能是有益的。
4.Shift log-scale: 参数量化的小改动会显著影响影响。如:熵分布的尺度如何从原始网络输出计算会显著影响优化动态,特别是在初始化时;发现将预测的对数尺度转移到指数化之前一致地提高了性能。
迁移到视频领域
1.将2D参数和操作对应转换为3D。
3D潜在网格Zn,大小为(t/2n,h/2n,w/2n)。熵模型的上下文变为(zn,(τ,i,j))。
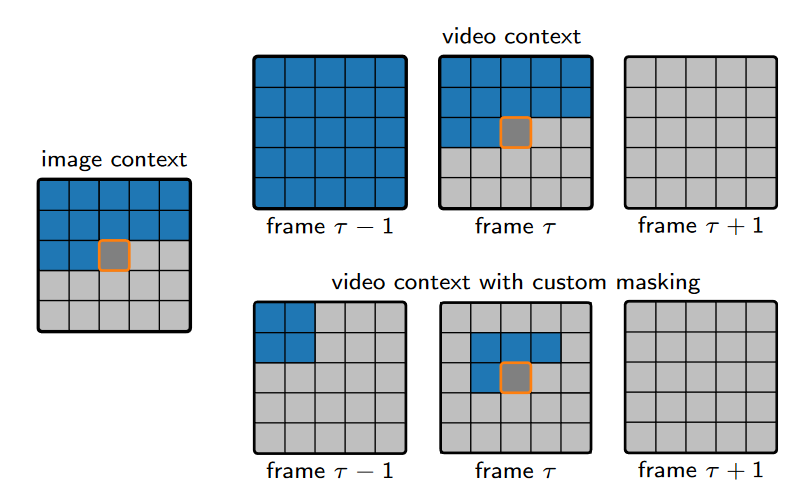
2.将视频分割成更小的视频块,对每个块拟合一个C3模型。发现较大的块对于较低的比特率效果最好,而较小的块对于较高的比特率效果最好。patch块大小从(30、180、240)到(75、270、320)不等。
3. 对于快速运动的视频片段,小的上下文(5-7在像素宽)可能小于特定关键点在连续帧中的位移。
这意味着对于目标潜在像素,前一潜在帧中的上下文不包含熵模型预测所需的相关信息。
使用更宽的空间上下文(65个潜在像素)来增强对快速运动视频的预测。
4. 盲目增加上下文大小也会增加熵模型的参数数量。使用一个掩码,以当前潜在帧的目标潜在像素为中心,并为前一潜在帧使用一个小的矩形掩码,掩码位置可学习。
Results
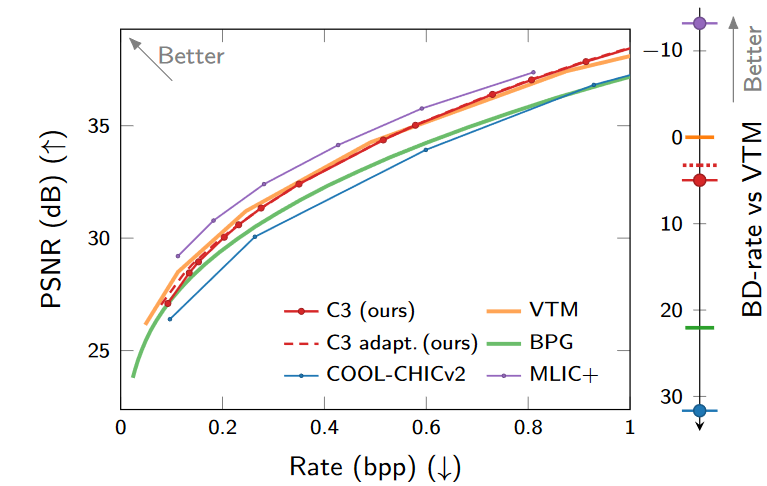
在Kodak和CLIC2020上图像压缩的结果。
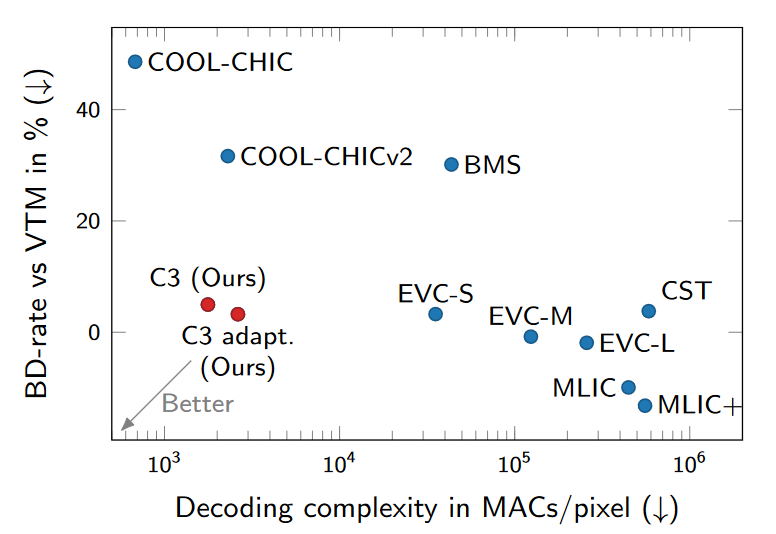
在Kodak上的BD-rate和解码复杂度对比。
虽然C3还不能匹配MLIC+(sota)的RD性能,但在解码时减少了两个数量级的操作,成本大幅降低。
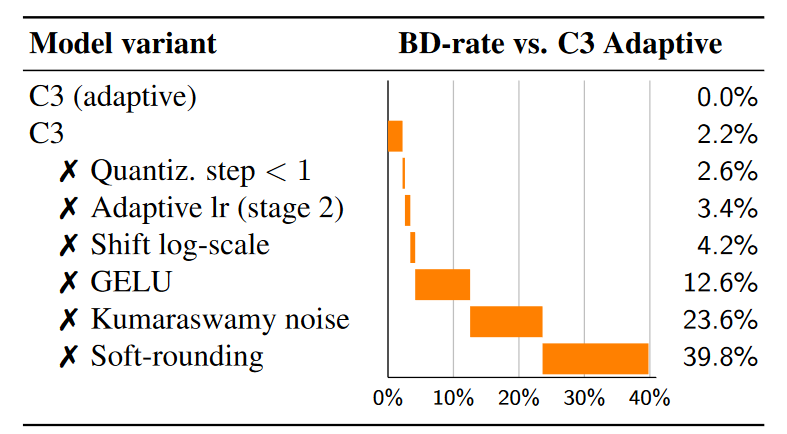
消融实验:依次删除改进后,相对于C3的BD-rate。
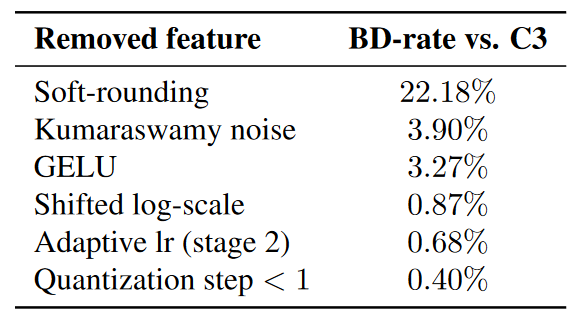
消融实验:分别禁用单个特征时,相比C3的BD-rate。
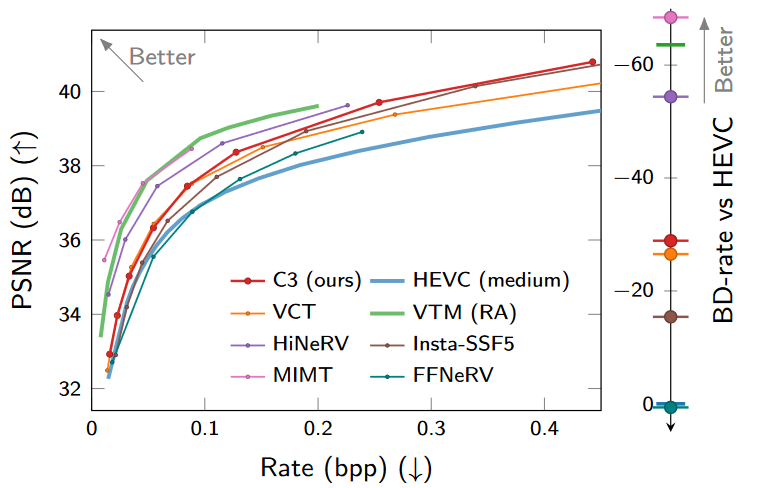
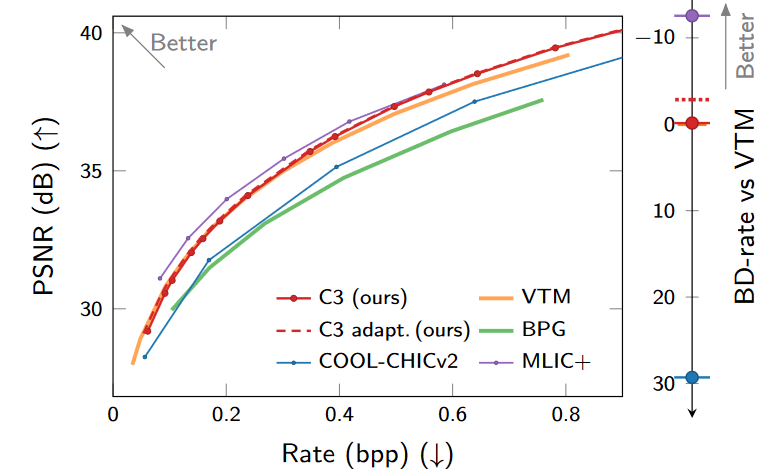
在UVG-1k上视频压缩的结果。
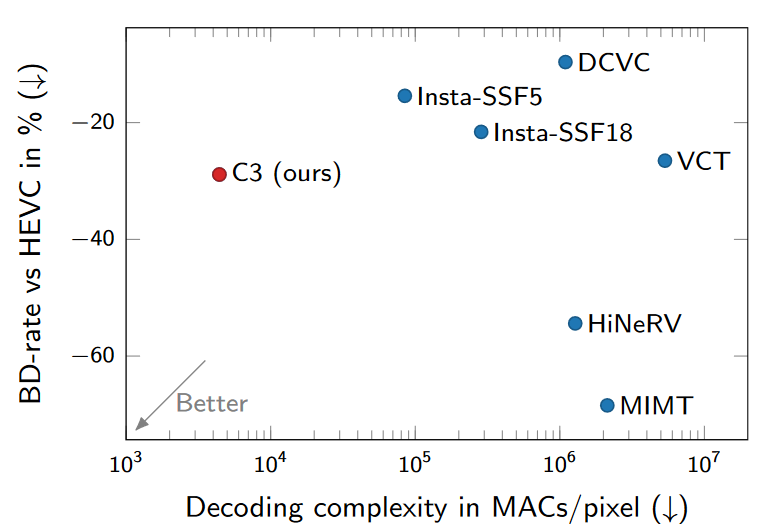
在UVG-1k上的BD-rate和解码复杂度对比。
















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









