







ICCV 2023
创新点
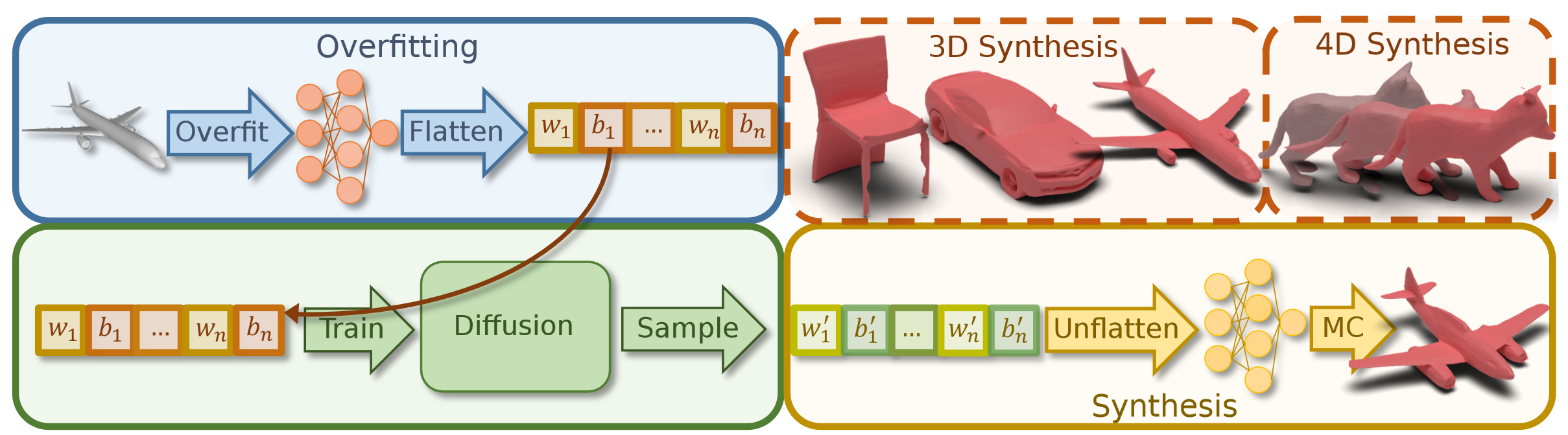
HyperDiffusion:一种用隐式神经场无条件生成建模的新方法。
HyperDiffusion直接对MLP权重进行操作,并生成新的神经隐式场。
HyperDiffusion是与维度无关的生成模型。可以对不同维度的数据用相同的训练方法来合成高保真示例。
局限性
扩散过程仅在优化后的MLP参数上运行,而不了解任何表面重建过程。
只用单个mlp拟合模型,如果加上grid会有更好的空间表达能力?
Pipeline
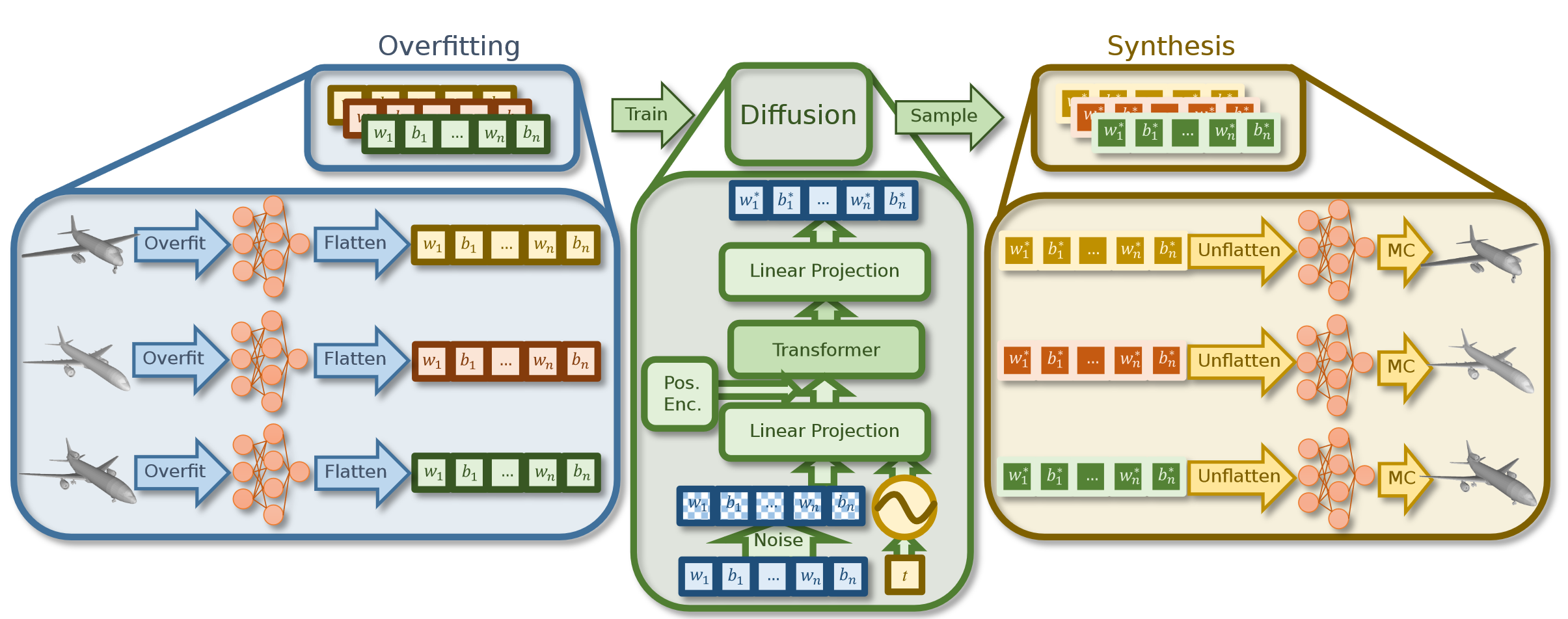
1.过拟合mlp,使得每个mlp精确表征一个模型,然后把网络参数展平成一维向量。
2.将优化后的一维向量送到扩散模型中,这个模型无需任何先验知识。
3.训练完成后,可用随机采样的噪声进行反向扩散过程来合成新的MLP,该权重对应于新的神经隐式场。
Per-Sample MLP Overfitting
对训练数据集中的不同样本{Si,i=1,…,N}使用相同的MLP架构,但权重是专门针对每个数据样本进行优化的。
指定模型i,以及模型的某一处位置x,可计算表面表示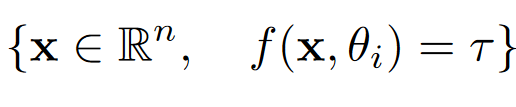 。
。
用bce损失优化模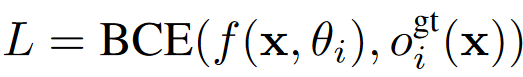 。其中ogt是真实的占用率。
。其中ogt是真实的占用率。
mlp架构
包含3个隐藏层,每个隐藏层有128个神经元,最终输出占用值。
在3D空间内随机采样100k个点,将所有实例归一化到[−0.5,0.5]3。
进一步对mesh表面附近采样100k个点。
两组点组合起来,这些占用用于监督过度拟合过程。使用每批次2048点来优化MLP,并使用BCE损失进行800个epoch的训练,直到收敛,每个形状大约需要6分钟。
4D形状
对于每个时间帧,按照3D形状采样对200k个点及其占用进行采样,对序列的每一帧重复采样过程。
为每个序列优化一组MLP权重和偏差来表示每个4D形状。
参数初始化
通过一致的权重初始化来指导MLP优化过程。
优化第一组MLP权重和偏差θ1来表示第一个样本S1,并使用θ1的优化权重来初始化其余MLP。

消融实验也证明使用第一个MLP优化后的参数进行初始化会带来更好的效果。
MLP Weight-Space Diffusion
Transformer已被证明可以在语言域中优雅地处理长向量,因此是MLP权重空间建模的合适选择。
使用transformer T作为去噪网络,T 直接预测去噪的MLP权重,而不是噪声。
对每个向量θ应用标准高斯噪声t次。然后将噪声向量与t的正弦嵌入一起输入到线性投影。
将投影与可学习的位置编码向量相加。
transformer输出去噪的token,经过投影生成预测的去噪MLP权重w*。
使用去噪权重θ*和输入权重θ之间的均方误差(MSE)损失进行训练。
Experiments
3层128维的MLP包含约36k个参数,这些参数被展平并标记化以进行扩散。批大小为32,初始学习率为2e−4,每200个epoch减少20%。训练约4000个epoch直到收敛,在单个A6000上需要约4 天。
对于3D形状生成,使用ShapeNet数据集的汽车、椅子和飞机类别。
对于4D形状生成,使用DeformingThings4D中的16帧动物动画序列。
对3D形状使用243的分辨率,对4D形状使用16×243的分辨率(最大空间分辨率,以便可以轻松地训练4D网格)。
远小于8i。
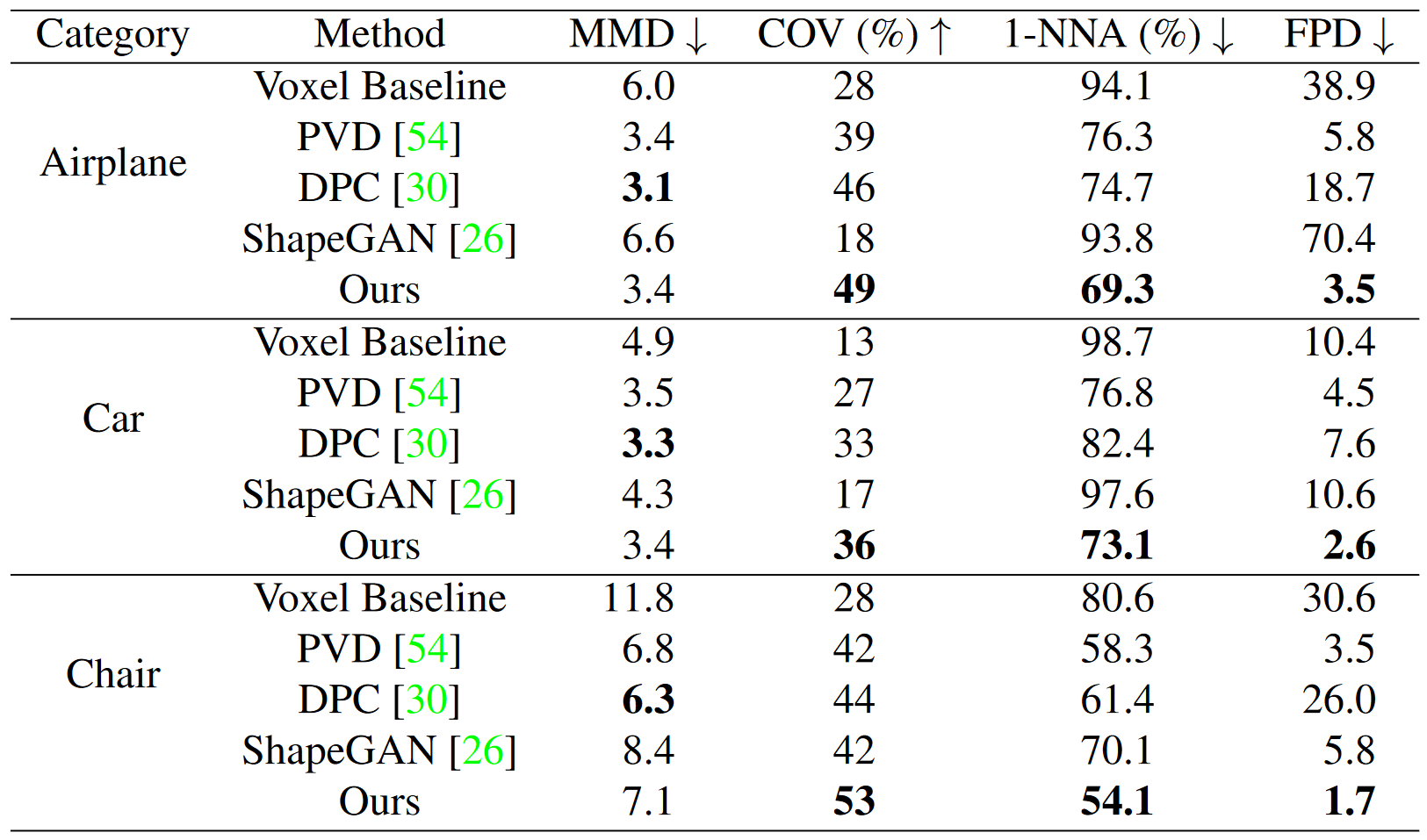
对于ShapeNet的3D形状生成的比较。

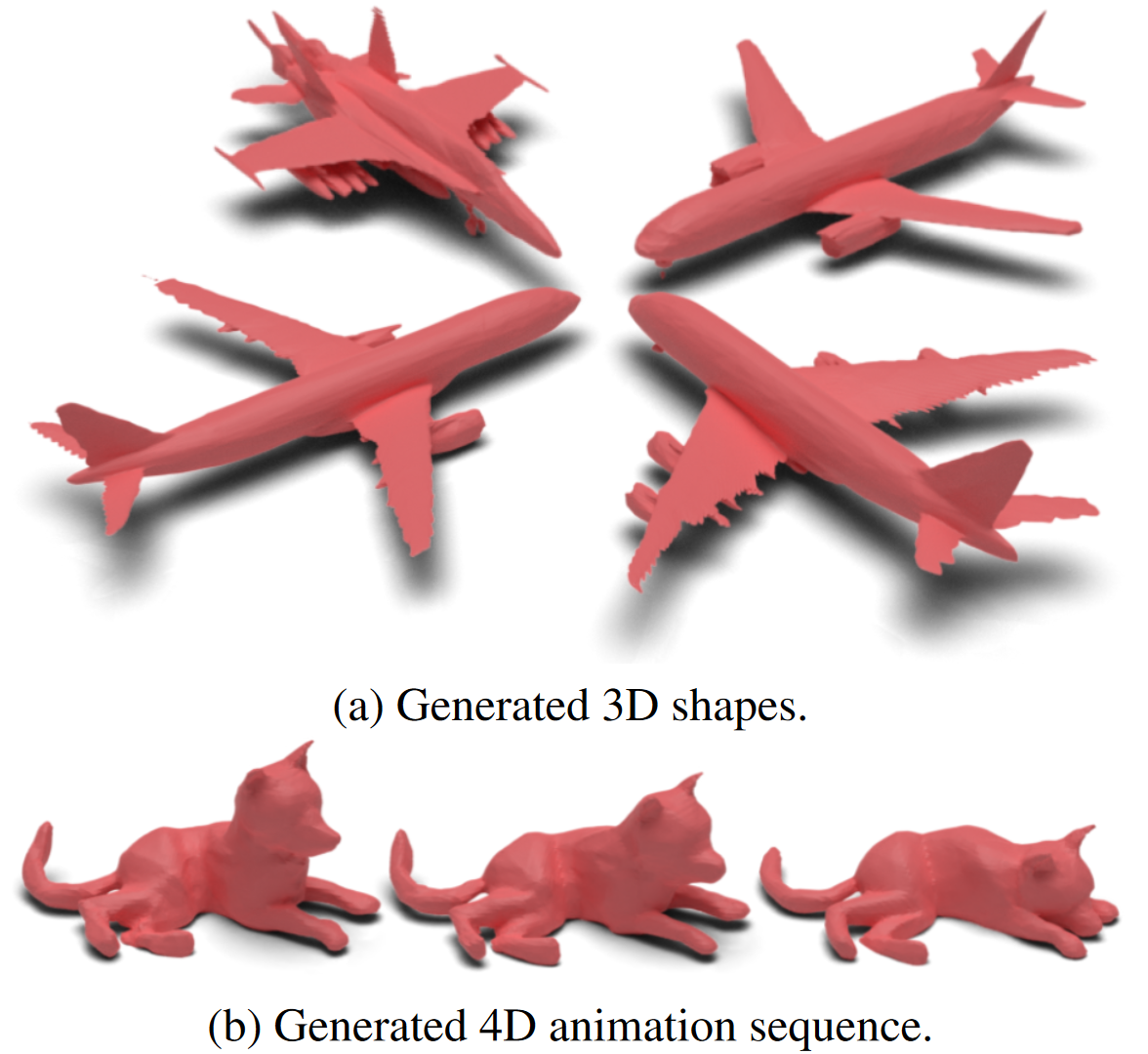
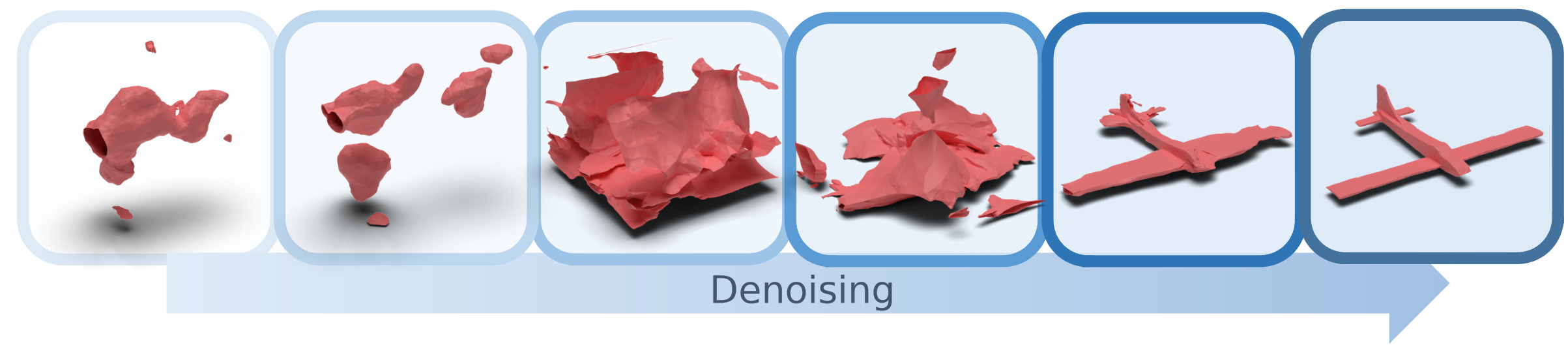
生成3D模型的可视化对比。基于体素的diffusion的结果分辨率相对较低,sota的PVD和DPC只能合成离散点云。
相比之下,我们的神经场合成可以生成高质量、连续的表面表示,很容易提取为网格。

4D动画合成的可视化对比。生成更详细的动画,而且实现了更平滑的时间一致性。


















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









