







ECCV2024
用扩散模型做任意分辨率的图像上采样。
当前困境
扩散模型在图像生成方面表现出了很显著的性能。然而对于生成超高分辨率的图像(如4096×4096),其占用的内存也会平方增加,因此生成的图像的分辨率通常限制在1024×1024。
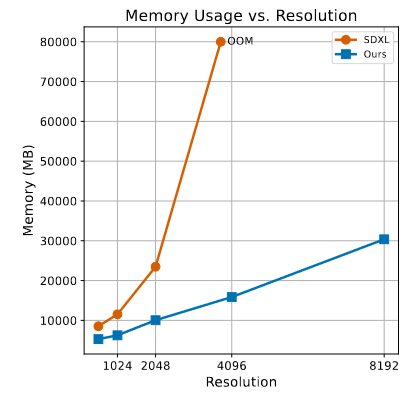
传统的U-Net架构(SDXL)生成4096×4096的图像,要超过80GB的内存,还不包括优化模型的梯度,优化器等。
创新点
1.提出一种单向块注意力(UniBA)算法,将空间复杂度从O(N2)降低到O(N),大幅度提升了最高分辨率。
该机制还能够通过调整并行生成块的数量来适应各种内存限制,在内存和时间开销之间进行权衡。
2.基于diffusion transformer(DiT),训练了Inf-DiT模型,能够对不同分辨率和形状的图像进行上采样。
3.设计多种技术来进一步增强局部和全局一致性,并提供了灵活的文本控制的零样本能力。
UniBA
主要思想是分块。原始输入图片x∈RH×W×C,分割成xb∈Rh×w×B2×C,h=H/B,w=W/B,其中B为块大小。
但大多数之前的结构(UNet、DiT等),块之间的依赖关系是双向的,图像中的所有块必须同时生成。
设计一种算法,将图像中的块分成若干个Batch,每个Batch只生成一部分块,且这些Batch是按顺序生成的,则只需要在内存中保留少量块的隐藏状态,就可以生成超高分辨率图像。
算法要求:
1.块之间的生成依赖是单向的,可以形成一个有向无环图(DAG)。
2.每个块对其他块只有少数几个直接依赖关系,因为块的隐藏状态和它的直接依赖关系要保存在内存中。
3.为了保证整幅图像的一致性,要求图像块具有足够大的感受野来管理长距离的依赖关系。
对于每一层,每个块都直接依赖于三个相邻块:上面的块、左侧的块和左上角的块。
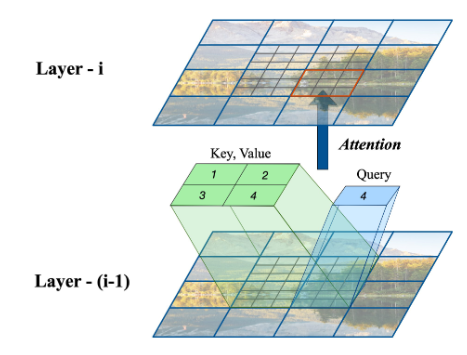
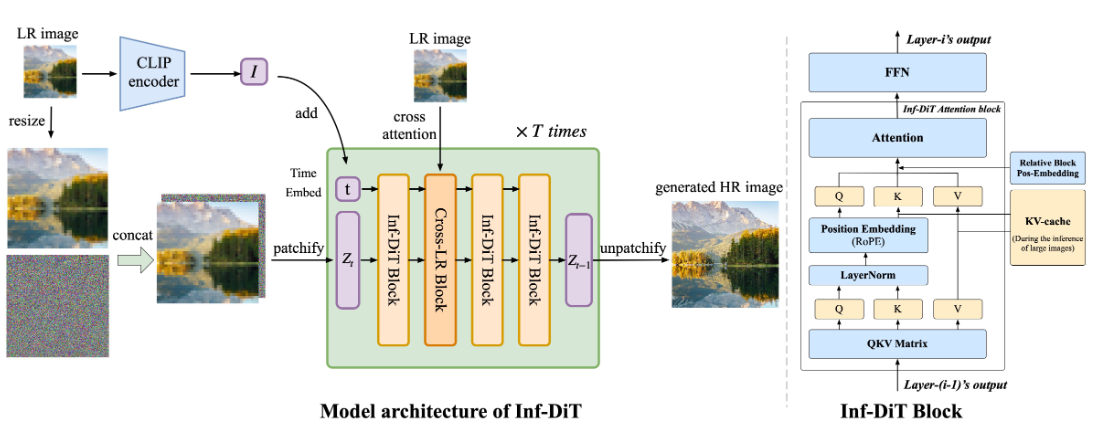
Inf-DiT根据内存大小每次生成n×n的块,只有后续块所依赖的块的KV-cache被存储在内存中。
虽然每个块在每一层中只关注少量的相邻块,但是随着特征的逐层传播,块可以间接地与远处的块进行交互,从而同时捕获长程和短程关系。
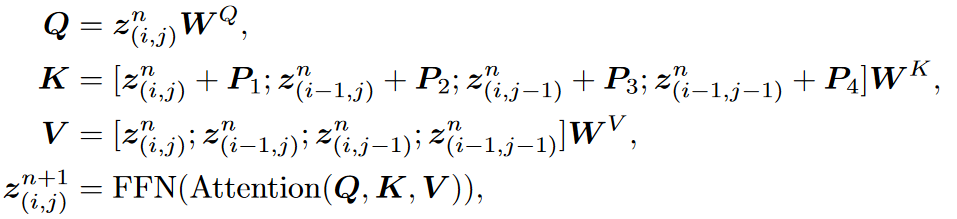
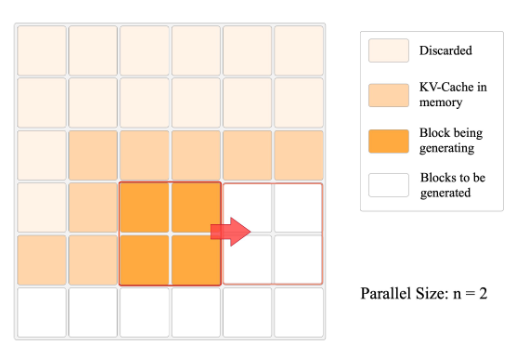
不同于自回归生成模型,在我们的模型中,任意数量的块可以并行生成,只要它们的依赖块的并集已经生成。
一次性生成n×n个块,从左上到右下。生成一组块之后,丢弃隐藏状态,并将新生成的KV-cache放到内存中。
图中KV-cache保存了尽可能多数量(w+n)的块,是为了证明空间复杂度小于On,不是真实的KV-cache。
当图片的h>w时:推理按从左上到右下的横向顺序,明显在内存中保留的KV-cache数量总是≤w+n。
假设生成单个块时模型所需空间为M1,一个块的KV-cache空间为M2,其他基本空间消耗为C,则推理过程的最大空间占用为n2M1+(w+n)M2+C。当n远小于w时,内存消耗与w成正比,即On。当w>h时也是同理。
在实际应用中,尽管对于不同的n值,图像生成的总FLOPs保持不变,但由于算子初始化时间和内存分配时间等开销,生成时间会随着n的增加而减少。因此,在内存限制允许的范围内选择最大的n是最优的。
Model Architecture
Model input
在超分辨率为f倍的情况下,Inf-DiT先对低分辨率的RGB图像进行f倍的上采样,然后与扩散在特征维度上的噪声输入进行级联,输入到模型中。
Position Encoding
基于Transformer的模型需要辅助输入显式的位置信息来学习patch之间的关系。
最近 LLM 的结果表明,与绝对位置编码相比,相对位置编码在捕获词位置相关性方面更有效。
将隐藏状态的通道分成两半,一个用于编码x坐标,另一个用于编码y坐标,分别使用RoPE。
创建一个足够大的Rotary位置编码表。为了确保训练过程中模型可以看到位置编码表的所有部分, 作者使用随机起点: 对于每个训练图像, 为图像的左上角随机分配一个位置 , 而不是默认的 。
考虑到同一个Block内和不同Block间的交互差异, 还引入了Block级别的相对位置编码P1~4, 根据注意前的相对位置分配一个不同的可学习嵌入。
Global and Local Consistency
用CLIP保持全局一致性
利用预训练的CLIP编码器从低分辨率图像中提取图像嵌入ILR,称之为语义输入。这样可以有效地从低分辨率图像中提取全局信息。将全局语义嵌入加入到diffusion transformer的时间嵌入中,并将其输入到每一层,使得模型可以直接从高层语义信息中学习。
全局语义嵌入的另一个有趣优势是,使用 CLIP 中的对齐图像-文本 Latent Space,即使本文模型没有在任何图像-文本对上进行训练, 也可以使用文本来指导生成。给定一个正提示cpos 和一个负提示cneg, 可以更新图像嵌入:
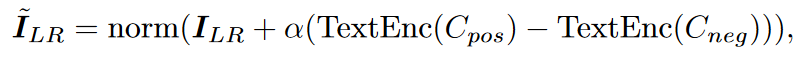
α可以控制引导的强度。可以简单地用I~LR代替ILR作为全局语义嵌入来进行控制。
例如,为了得到更清晰的结果集,Cpos = "clear"和Cneg = "blur"会有所帮助。
用交叉注意力保持局部一致性
模型学习 LR 和 HR 图像之间的局部对应关系时仍然可能存在连续性问题。为了解决这个问题,引入了 Nearby LR Cross Attention。
每个块对周围的3 × 3 LR块进行交叉注意,以捕获附近的LR信息。实验表明,这种方法显着减少了生成不连续图像的概率。
Experiments
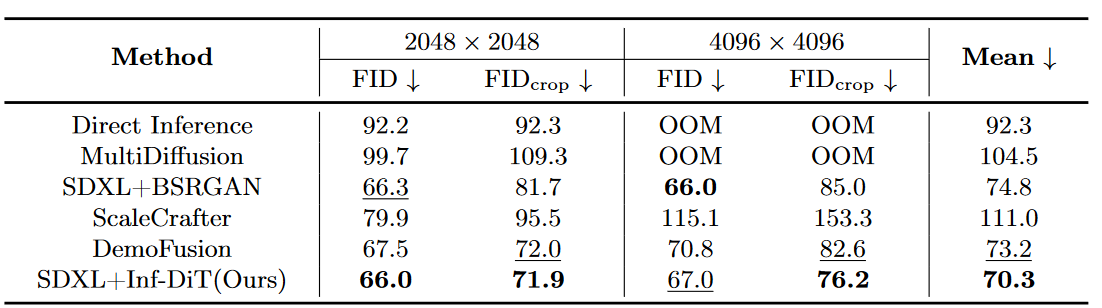
在HPDV2数据集上生成超高分辨率图像与现有sota的比较结果。
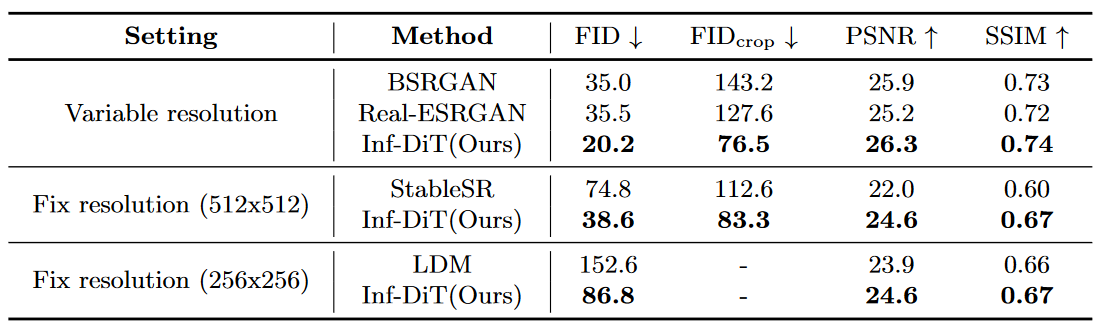
在DIV2K数据集上超分辨率与现有sota的比较结果。
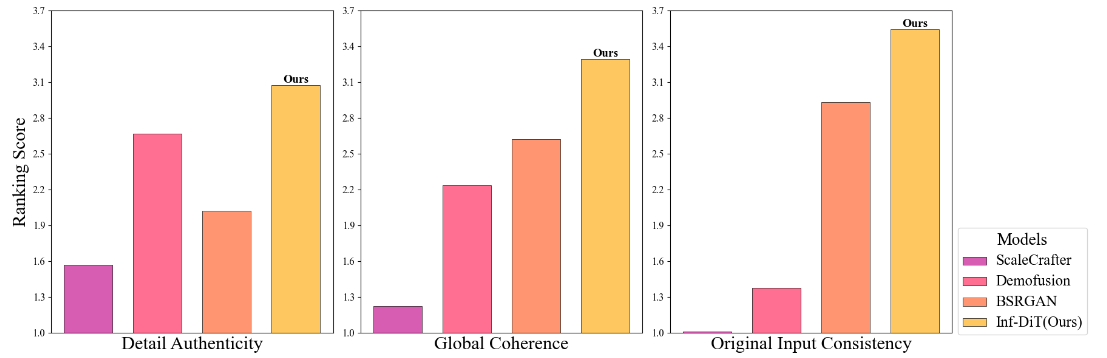
Inf-DiT 在细节真实性、全局连贯性和与低分辨率输入的一致性这3个标准上都取得了最高分。

Inf-DiT 可以多次上采样自己生成的图像,并在相应分辨率下生成不同频率的细节。
但缺点是若在低分辨率未能准确生成,后续很难纠正错误。
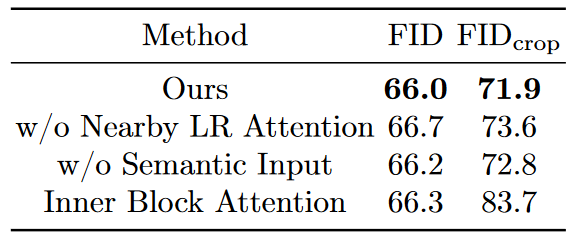
去除局部一致性和全局一致性后效果都有下降。
去除块与块之间的注意力后效果下降明显。什么东西,就是UniBA?
















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









