









Flow-Based Model
文章目录
简介
Flow-Based对概率密度函数的直接建模,这使得它们在数据生成和推断方面具有优势,并且在潜在空间中的操作更加直观。但是,它们可能在处理复杂数据分布时受限,因为需要设计适合数据分布的逆变换
与其他生成模型原理区别:
- Flow-based模型:这种模型通过学习数据的概率密度函数来进行生成。它们学习了数据的分布,并利用这种分布来生成新的样本。
- VAE:变分自编码器利用潜在变量的分布来建模数据。它通过编码器将输入数据映射到潜在空间中,并通过解码器从潜在空间中的采样重建输入数据。
- GAN:生成对抗网络通过生成器生成假样本,同时使用鉴别器来区分真实和假的样本。生成器和鉴别器相互竞争,以提高生成器生成逼真样本的能力。
总览
为了得到更好的generator,采用极大似然估计,最大化 l o g P G ( x ) log^{P_G(x)} logPG(x),也就是最小化 P d a t a P_{data} Pdata和 P G P_G PG两个分布之间的距离(KL散度)。
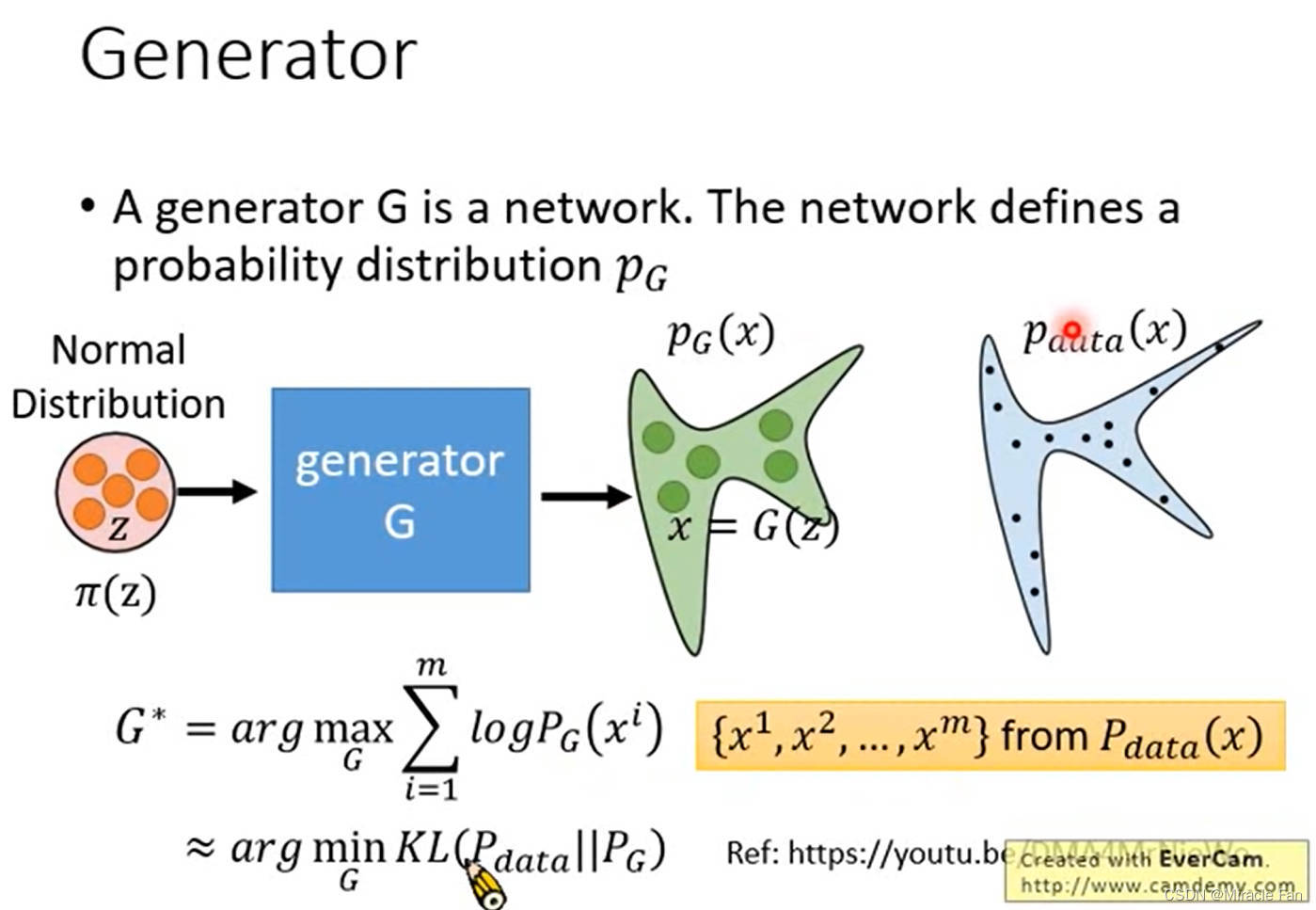
θ ∗ = a r g max θ ∏ i = 1 m P G ( x i ; θ ) = a r g max θ l o g ∏ i = 1 m P G ( x i ; θ ) = a r g max θ ∑ i = 1 m l o g P G ( x i ; θ ) { x 1 , x 2 , . . . , x m } from P d a t a ( x ) ≈ a r g max θ E x ∼ P d a t a [ l o g P G ( x ; θ ) ] = a r g max θ ∫ x P d a t a ( x ) l o g P G ( x ; θ ) d x − ∫ x P d a t a ( x ) l o g P d a t a ( x ) d x = a r g min θ K L ( P d a t a ∣ ∣ P 0 ) \begin{aligned} \theta^{*} &=arg\max_{\theta}\prod_{i=1}^mP_G(x^i;\theta)=arg\max_{\theta}log\prod_{i=1}^mP_G(x^i;\theta) \\ &=arg\max_\theta\sum_{i=1}^mlogP_G(x^i;\theta)\quad\{x^1,x^2,...,x^m\}\operatorname{from}P_{data}(x) \\ &\approx arg\max_\theta E_{x\sim P_{data}}[logP_G(x;\theta)] \\ &=arg\max_\theta\int_xP_{data}(x)logP_G(x;\theta)dx-\int_xP_{data}(x)logP_{data}(x)dx \\ &=arg\min_{\theta}KL(P_{data}||P_{0}) \end{aligned} θ∗=argθmaxi=1∏mPG(xi;θ)=argθmaxlogi=1∏mPG(xi;θ)=argθmaxi=1∑mlogPG(xi;θ){x1,x2,...,xm}fromPdata(x)≈argθmaxEx∼Pdata[logPG(x;θ)]=argθmax∫xPdata(x)logPG(x;θ)dx−∫xPdata(x)logPdata(x)dx=argθminKL(Pdata∣∣P0)
数学基础
jacobian matrix

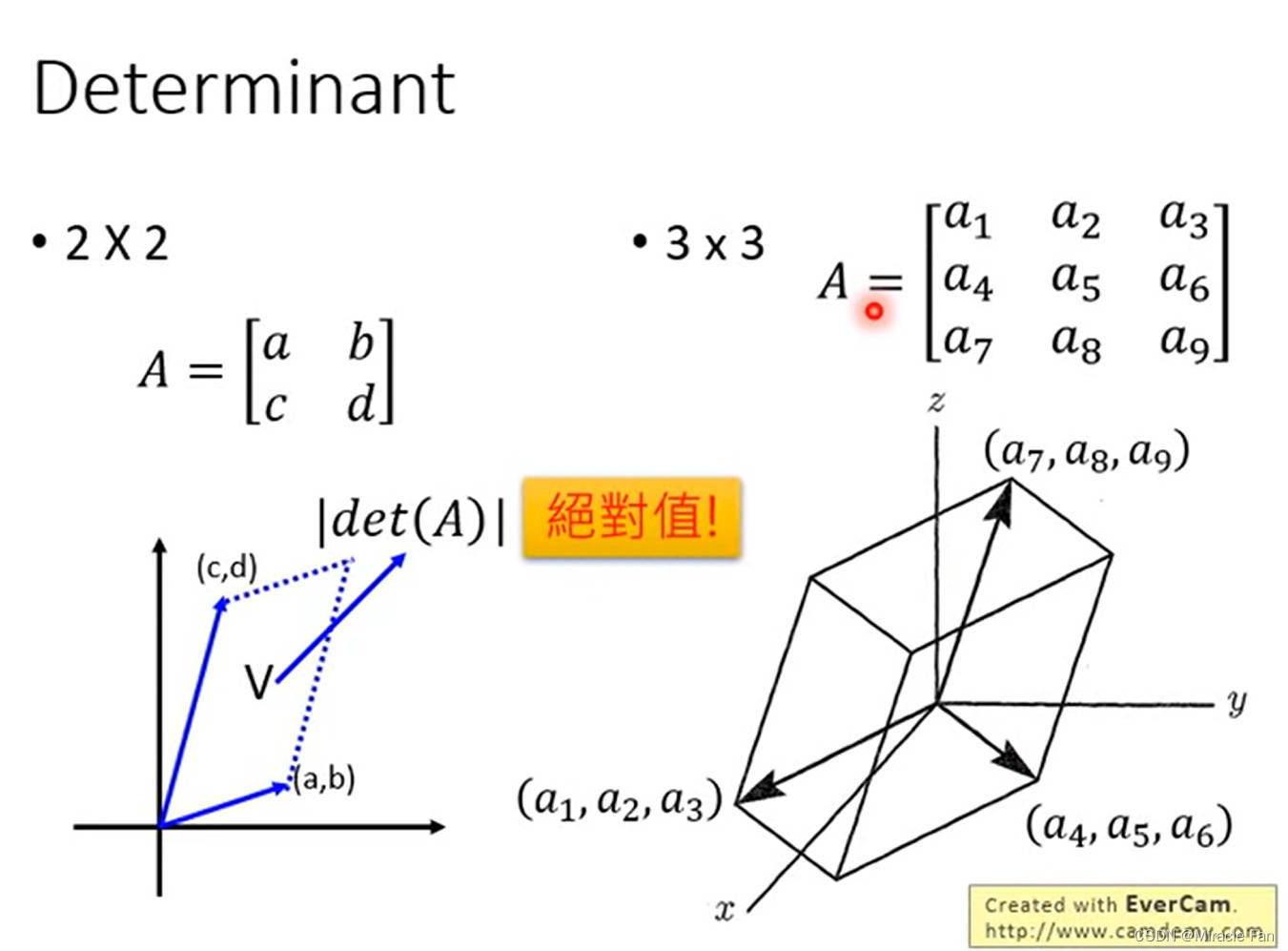
determinant行列式
给出行列式值的几何形式——面积、体积
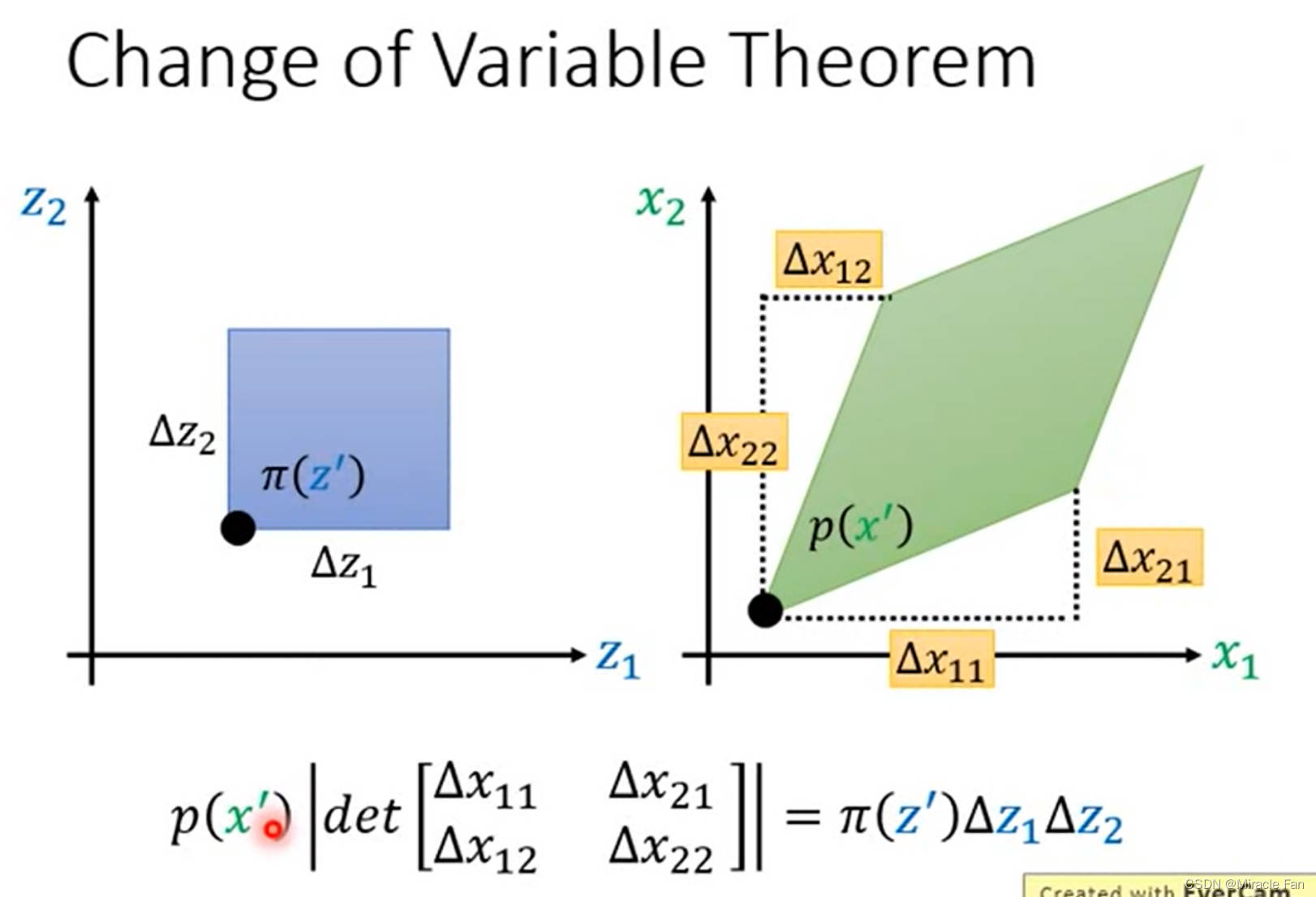
Change of variable theorem
p
(
x
′
)
∣
d
e
t
[
Δ
x
11
Δ
x
21
Δ
x
12
Δ
x
22
]
∣
=
π
(
z
′
)
Δ
z
1
Δ
z
2
x
=
f
(
z
)
p
(
x
′
)
∣
1
Δ
z
1
Δ
z
2
d
e
t
[
Δ
x
11
Δ
x
21
Δ
x
12
Δ
x
22
]
∣
=
π
(
z
′
)
p
(
x
′
)
∣
d
e
t
[
Δ
x
11
/
Δ
z
1
Δ
x
21
/
Δ
z
1
Δ
x
12
/
Δ
z
2
Δ
x
22
/
Δ
z
2
]
∣
=
π
(
z
′
)
p
(
x
′
)
∣
det
[
∂
x
1
/
∂
z
1
∂
x
2
/
∂
z
1
∂
x
1
/
∂
z
2
∂
x
2
/
∂
z
2
]
∣
=
π
(
z
′
)
p
(
x
′
)
∣
det
[
∂
x
1
/
∂
z
1
∂
x
1
/
∂
z
2
∂
x
2
/
∂
z
1
∂
x
2
/
∂
z
2
]
∣
=
π
(
z
′
)
p
(
x
′
)
∣
det
(
J
f
)
∣
=
π
(
z
′
)
p
(
x
′
)
=
π
(
z
′
)
∣
1
det
(
J
f
)
∣
p
(
x
′
)
=
π
(
z
′
)
∣
d
e
t
(
J
f
−
1
)
∣
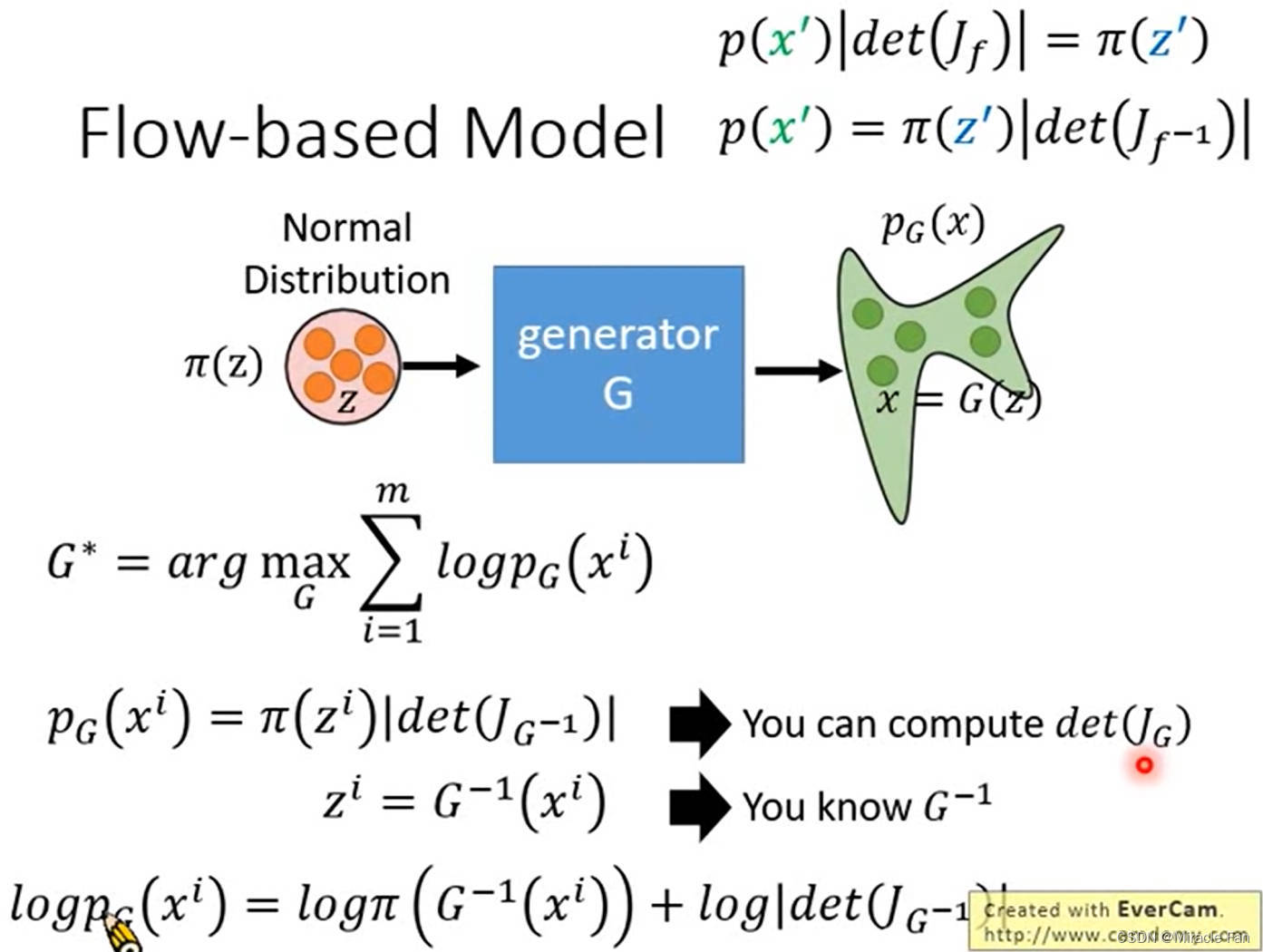
\begin{aligned} &\left.p(x^{\prime})\left|det\begin{bmatrix}\Delta x_{11}&\Delta x_{21}\\\Delta x_{12}&\Delta x_{22}\end{bmatrix}\right.\right|=\pi(z^{\prime})\Delta z_{1}\Delta z_{2}\quad\mathrm{x=f(z)} \\ &\left.p(x^{\prime})\left|\frac{1}{\Delta z_{1}\Delta z_{2}}det\begin{bmatrix}\Delta x_{11}&\Delta x_{21}\\\Delta x_{12}&\Delta x_{22}\end{bmatrix}\right.\right|=\pi(z^{\prime}) \\ &\left.p(x^{\prime})\left|det\begin{bmatrix}\Delta x_{11}/\Delta z_{1}&\Delta x_{21}/\Delta z_{1}\\\Delta x_{12}/\Delta z_{2}&\Delta x_{22}/\Delta z_{2}\end{bmatrix}\right.\right|=\pi(z^{\prime}) \\ &\left.p(x')\left|\det\begin{bmatrix}\partial x_1/\partial z_1&\partial x_2/\partial z_1\\\partial x_1/\partial z_2&\partial x_2/\partial z_2\end{bmatrix}\right.\right|=\pi(z') \\ &\left.p(x^{\prime})\left|\det\begin{bmatrix}\partial x_1/\partial z_1&\partial x_1/\partial z_2\\\partial x_2/\partial z_1&\partial x_2/\partial z_2\end{bmatrix}\right.\right|=\pi(z^{\prime}) \\ &p(x^{\prime})|\det(J_{f})|=\pi(z^{\prime})\quad p(x^{\prime})=\pi(z^{\prime})\left|\frac{1}{\det(J_{f})}\right| \\ &p(x^{\prime})=\pi(z^{\prime})|det(J_{f^{-1}})| \end{aligned}
p(x′)
det[Δx11Δx12Δx21Δx22]
=π(z′)Δz1Δz2x=f(z)p(x′)
Δz1Δz21det[Δx11Δx12Δx21Δx22]
=π(z′)p(x′)
det[Δx11/Δz1Δx12/Δz2Δx21/Δz1Δx22/Δz2]
=π(z′)p(x′)
det[∂x1/∂z1∂x1/∂z2∂x2/∂z1∂x2/∂z2]
=π(z′)p(x′)
det[∂x1/∂z1∂x2/∂z1∂x1/∂z2∂x2/∂z2]
=π(z′)p(x′)∣det(Jf)∣=π(z′)p(x′)=π(z′)
det(Jf)1
p(x′)=π(z′)∣det(Jf−1)∣
架构
输入z和输出x的尺寸一样,区别于其他的生成模型(输入使用low resolution)。同时,因为我们需要使用 G − 1 G^{-1} G−1, G G G矩阵需要可逆,方便求取。
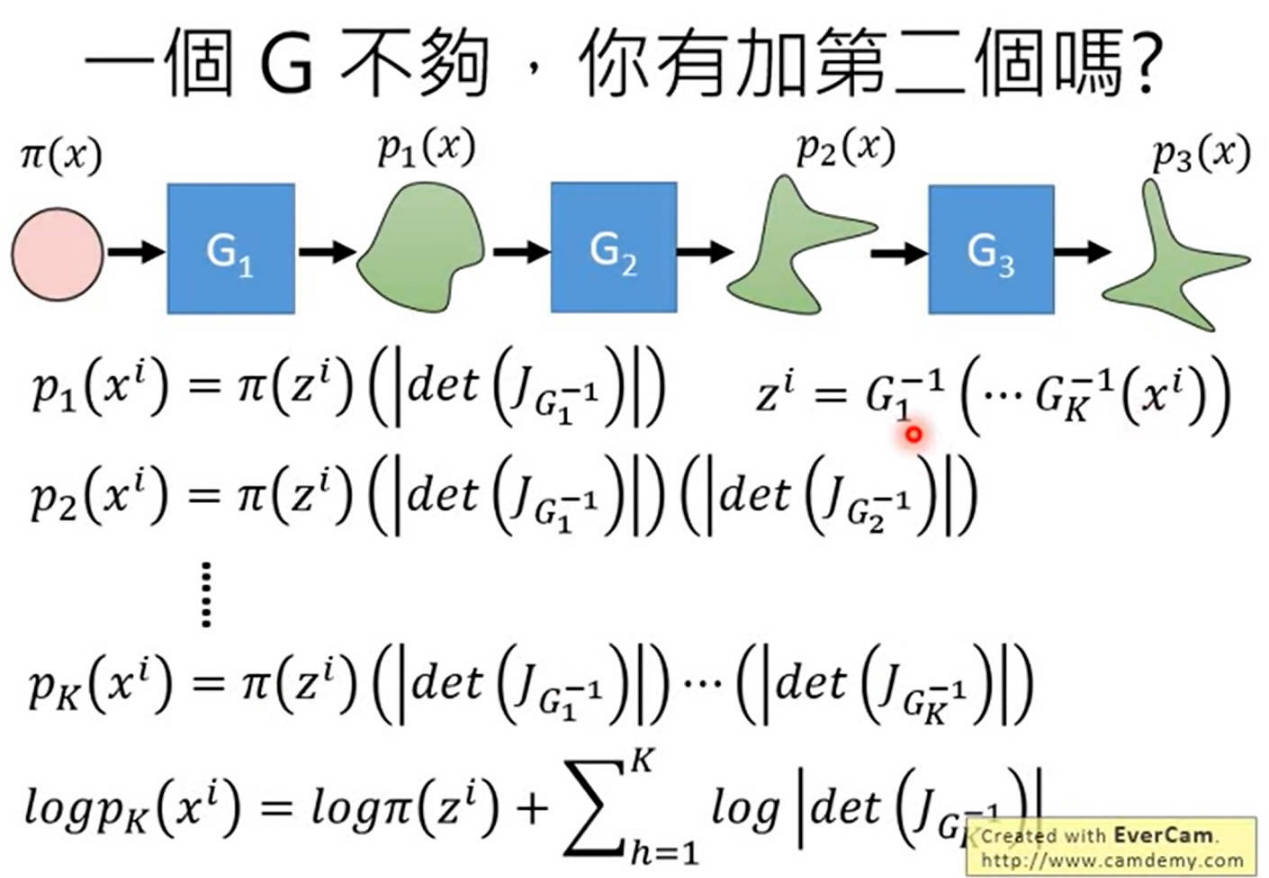
常见几种方法
coupling layer
很容易的计算 G G G的数值
NICE: Non-linear Independent Components Estimation
Density estimation using Real NVP
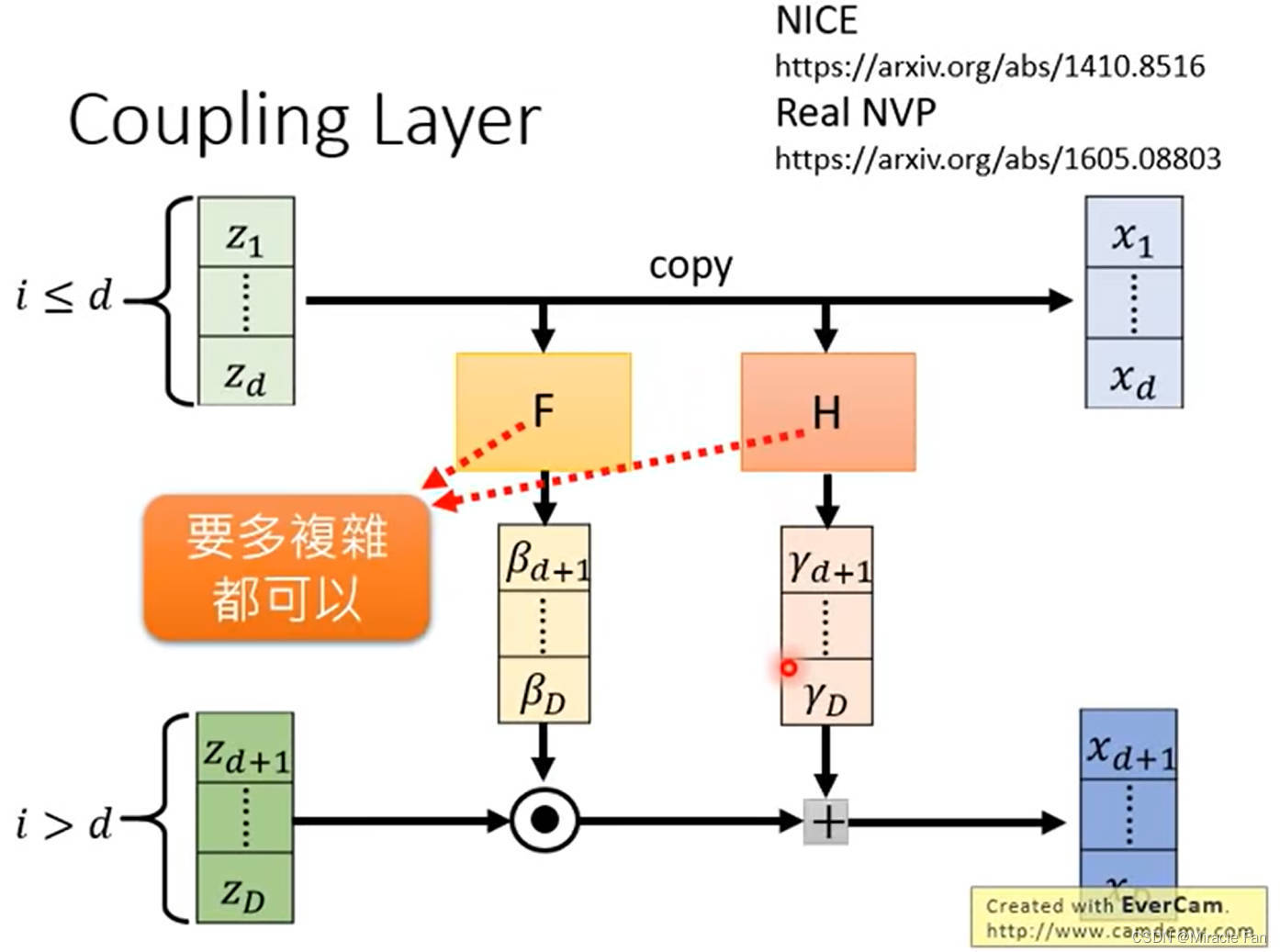
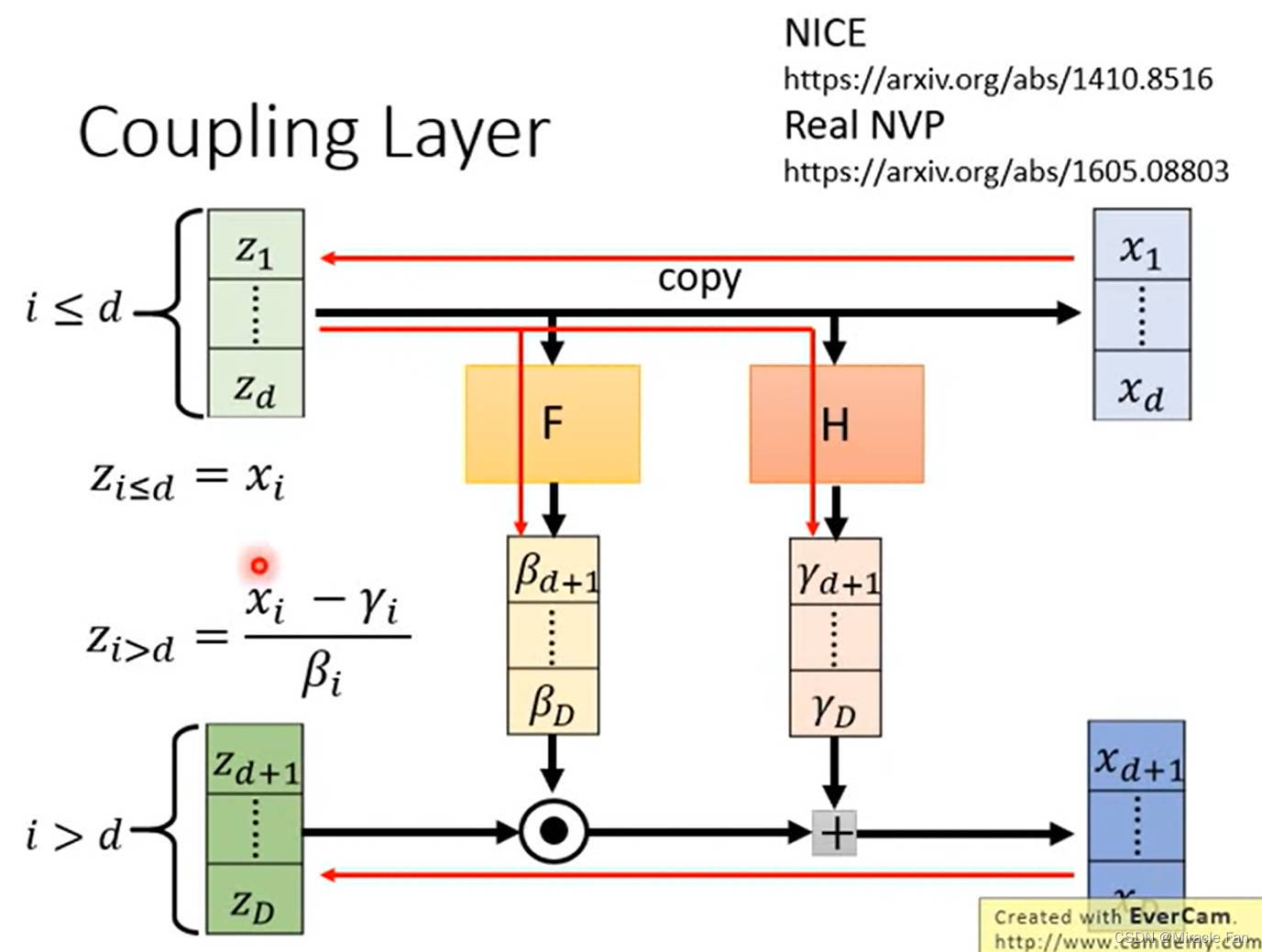
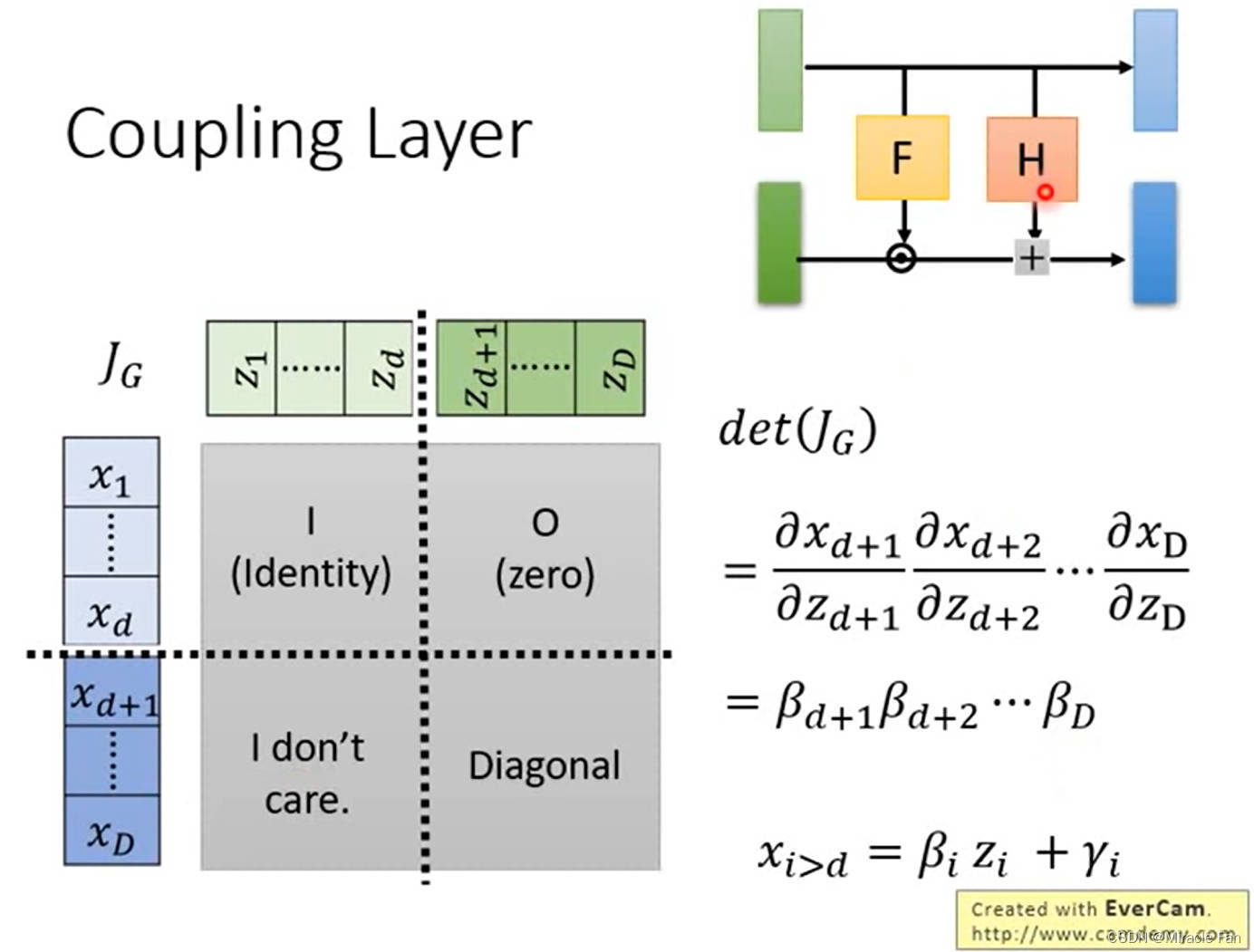
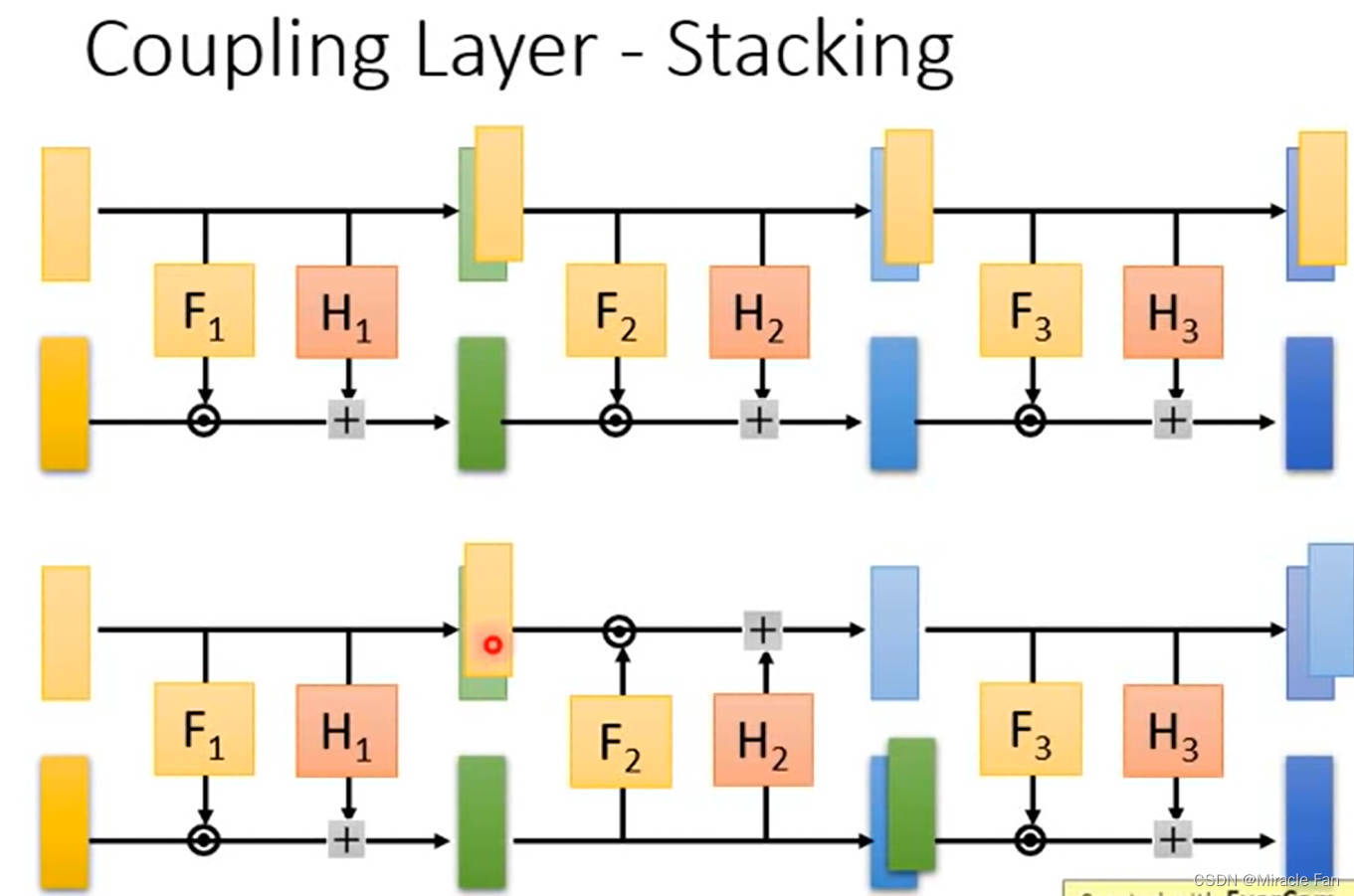
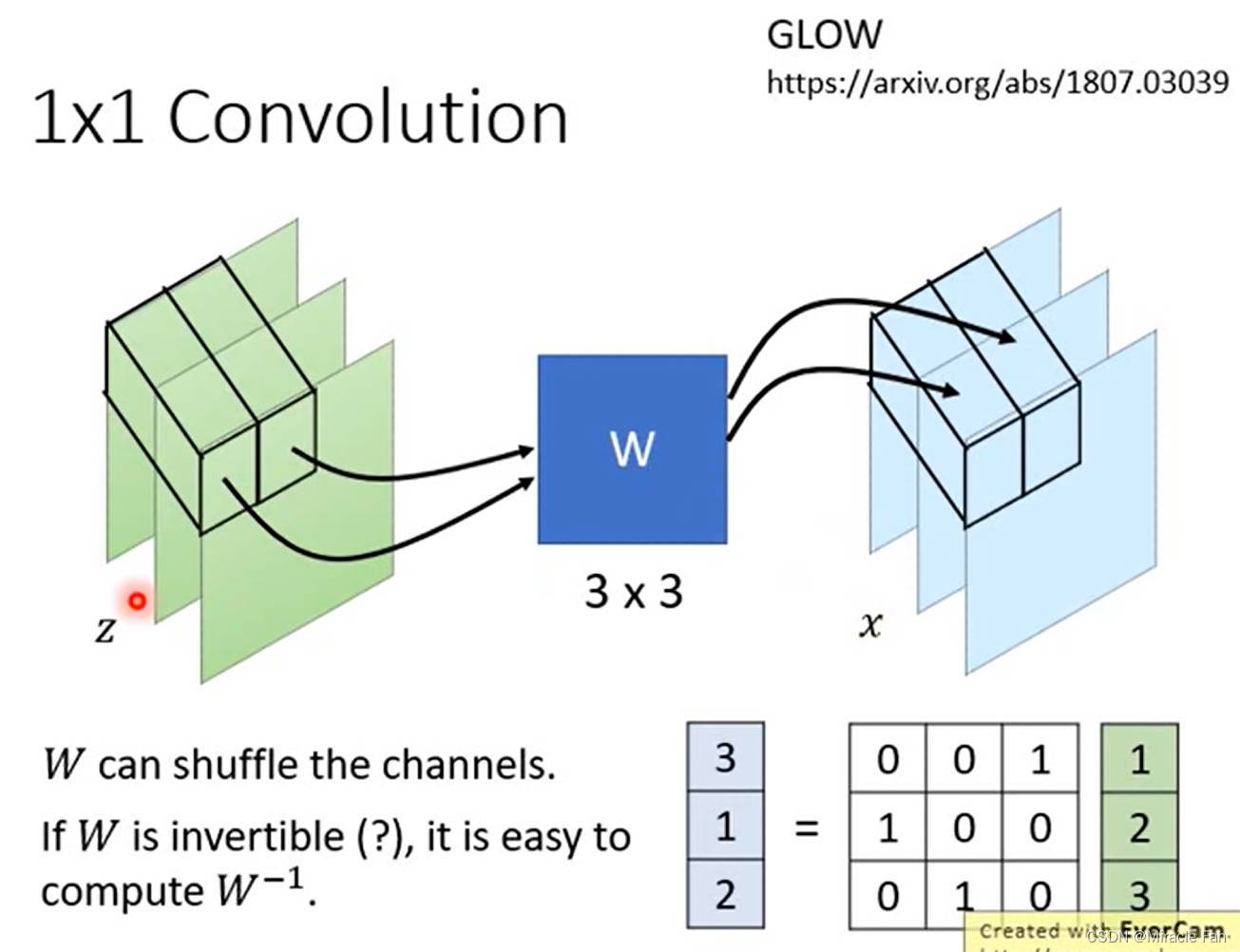
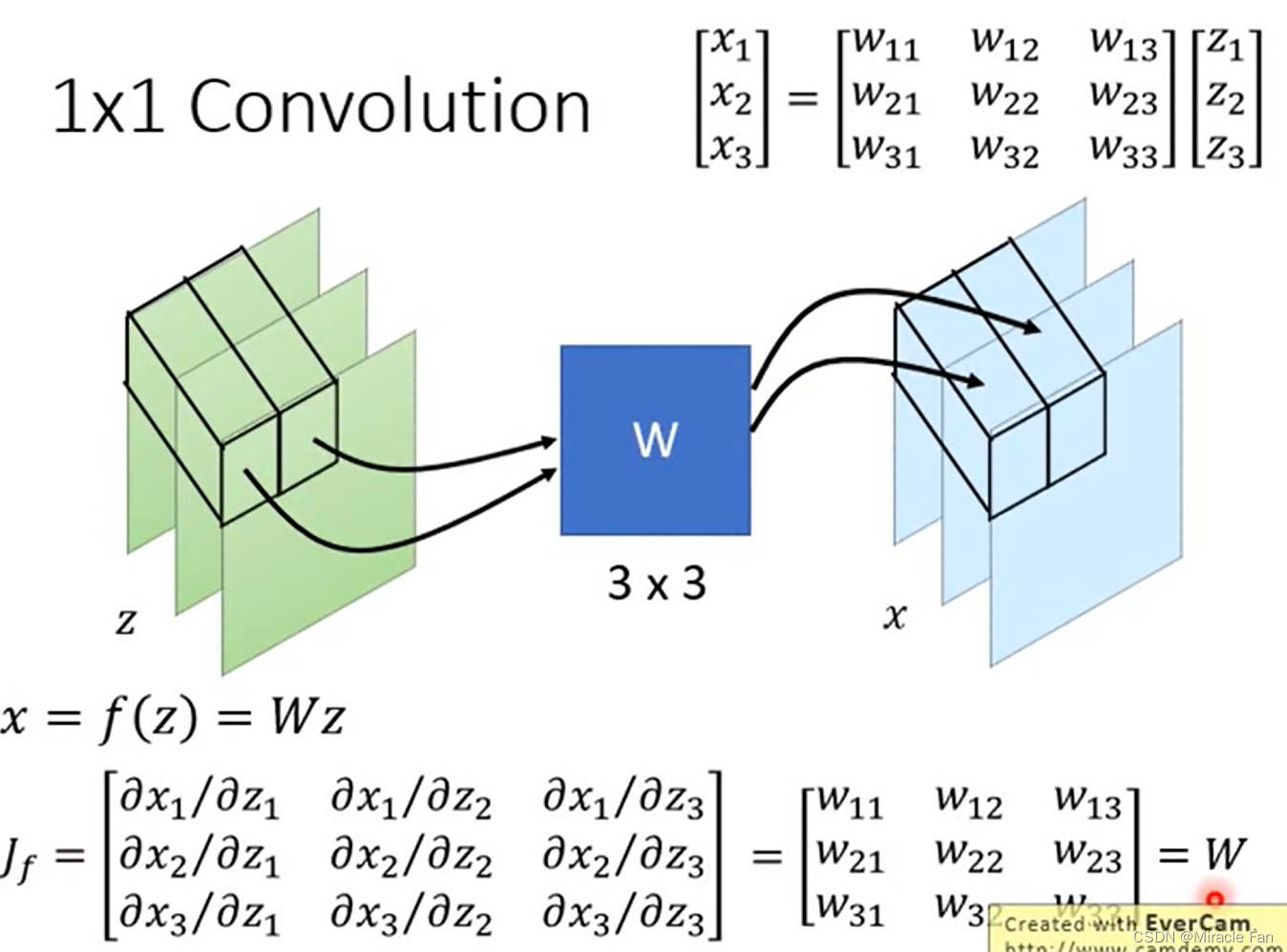
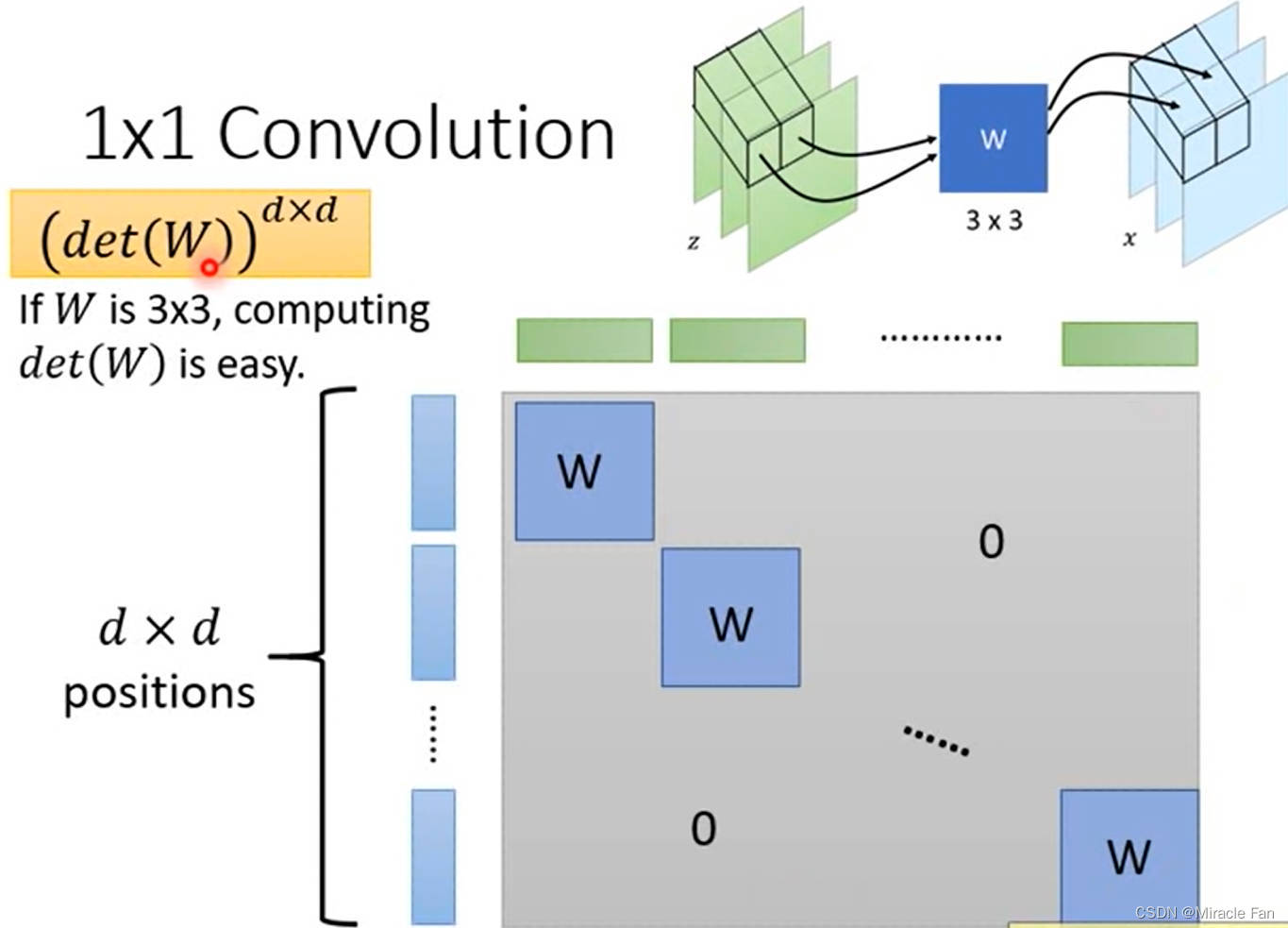
采用1*1卷积进行channel shuffle
Glow: Generative Flow with Invertible 1x1 Convolutions
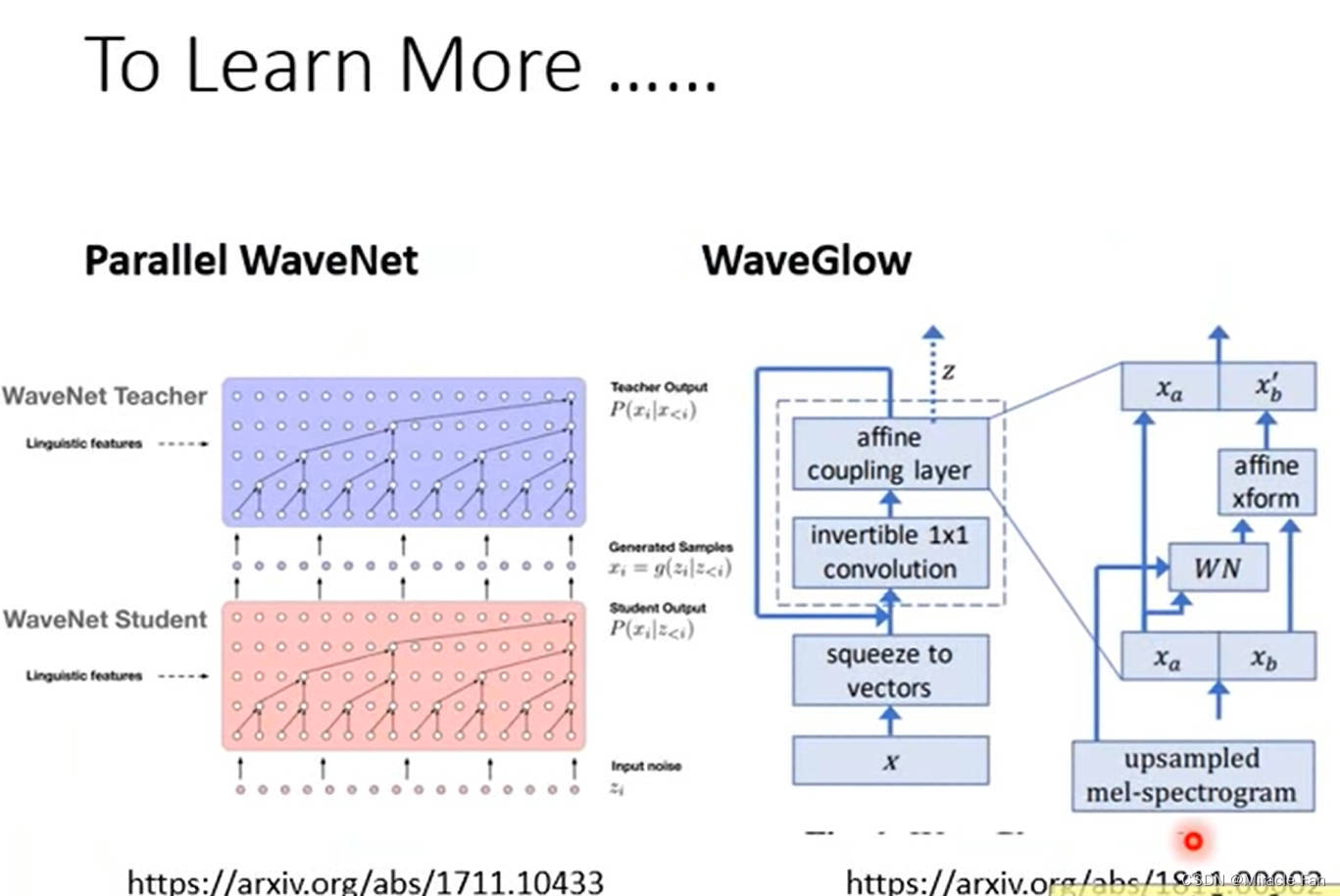
Parallel WaveNet: Fast High-Fidelity Speech Synthesis
WaveGlow: A Flow-based Generative Network for Speech Synthesis
参考视频:
















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











