






层次级任务网络Hierrarchicla Task Network
行为树是反应型AI,只会对输入做出预先定义的反应,却没有具体的目标。层次级任务网络(下面简称HTN)则能使AI像人类一样有具体的计划。

AI的HTN一般包括如下几个要素:
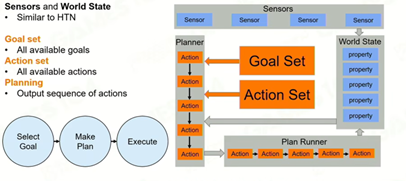
world state:世界观,AI对世界认知的描述
Sensors:感知器,接收游戏中的信息并修改其world state
HTN Domain:HTN的主要结构,将层次化的task放在里面,描述task和task之间的关系
Planner:根据世界观和HTN Domain来制定计划
Plan Runner:监控所有在执行的task的状态并根据世界观的变化而改变优先级和内容

HTN的任务类型
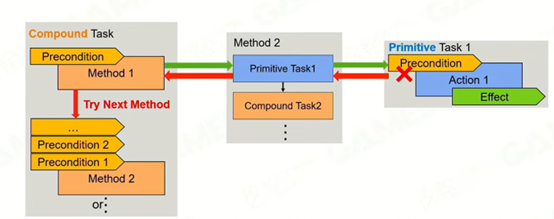
Primitive Task:基础任务,其必须包括的要素有三个:任务需要执行的动作(对现实世界的影响,用脚本等实现),Precondition(读取world state并判断是否满足条件),Effect(对于AI自身的world state的修改)。

Composed Task:复合任务。由多个method构成,优先级由高到低,上层precondition不满足的话会继续判断下一层,直到有method被执行或全部判断完。
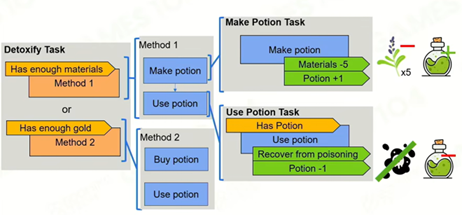
HTN任务设计的优势:相比于行为树,HTN的任务设计模式更容易被理解。
一套完整的Task体系共同组成了HTN Domain,即任务系统。

Planning:根据world state,从root task里选择一个目标task,再从root task里展开。这里面有个实现细节:将worldstate在domain里做一个拷贝,并在domain里面根据选择的task进行推演(假设所有action都成功),通过这种方法可以选择一系列有前置task条件的task进入plan中。若一系列task中有一个没完成,不断向上返回false直到一个复合task中能选择下一个task。这种方式能防止world state中途发生变化,导致决策过程出现问题。
简单来说,Planning的过程就是决策的过程。这和行为树有点像,但其设计更加人性化,更接近人的思考过程。
replan:指重新开始选择计划的过程。replan的前置条件有如下三种:没有plan,当前plan已经执行完毕或者返回failure,sensor改变了当前的world state。
我的理解是这套系统的Planner每次会根据当前的world state和自身的任务系统预先制定一个任务列表,并输入到plan runner中逐个完成。replan相当于Planner的触发器,每次满足条件后都会触发Planner重新制定一套计划并输入到plan runner中。
HTN的优势:与行为树相似,但是比行为树效率高(行为树每个Tick都需要从根节点跑一次)且利于理解,其输出的计划有一个长期的效果。
缺点:配置precondition和effect时,如果task过多,极可能由于设计失误无法完成整个task链。很长的task链也容易在途中失败,即花费大量时间制定的计划在还未完成时就需要重新制定,这非常地影响效率。
基于目标的行动计划Goal-Oriented Action Planning
基于行动的目标计划(以下简称GOAP)的任务机结构基本和HTN一样。但它将任务task系统划分成了两部分:Goal Set和Action Set。Goal set存储了AI要实现的目标目标goal,而Action set则存储了用于实现目标的行为Action。
Goal Set:每个goal有前置条件,结果和优先级,不同的是每个goal都是由一系列状态指标组成的,goal的需求是在执行完一系列action后goal能达到指标(状态指标一般用true和false来表示而非一个数字,因为这会简化后面的动态规划流程)
Action Set:包括Precondition,Effect和Cost三个部分,Cost用于判断在完成某个goal时执行哪个action最为方便,由设计师设计。

Goal的计划过程:由目标到具体行动。
step1.首先确定goal(在precondition满足的情况下优先级最高),将goal里不能满足的东西加入一个stack of unsatisified states中(满足后会移出)。
step2. 查找哪个action的precondition满足并能最终达到要求。
step3.如果action的precondition都不能满足,那么将precondition中不能满足的条件加入stack里。根据stack中内容选择新的action加入action list。
step4. 重复上述过程直到Stack中为空。
核心目标:规划出一条路径,使得加入goal后stack of unsatisified states中最终为空,且最好所有action cost加在一起最小。
State-Action-Cost Graph:根据当前的state和任务之间的依赖关系生成一张有向图,将GOAP路径规划问题变成一个图问题,Node为State的组合,Edge为对应的action,distance为action对应的cost。起点是当前状态,而终点是目标状态。由此该问题变成了一个由当前状态到目标状态的最短路径问题,可以用最短路径寻找类算法解决。

cost的设计:目标状态和当前状态越接近的state选择的权重越高,即cost越低。
算法优点:让AI更加灵活;分开了goal和action,使得即使是同一个goal但是action却不一定一样。
缺点:算法计算量大,运行较慢;需要对游戏世界进行定量(true/false)表达,这对于很多游戏来说都是难以做到的,因此一般适用于确定性较高的游戏(对于RTS一类的高博弈类游戏可能不太适合)
Monte Carlo Tree Search
Monte Carlo Tree Search:模拟人对于可能性的推演并根据推演结果选择最佳步骤的一种决策方式。
首先,根据当前的状态和数据集训练来获得集中可能的行为方向。即将问题给抽象成一个数学模型:将当前状态看作一个state,而要执行的action看做一个edge。

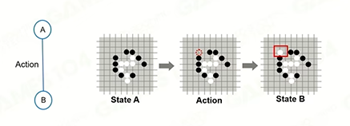
State Space:通过上述的建模过程可以获得一个以当前状态为root的树状结构。这个结构叫做State Space。
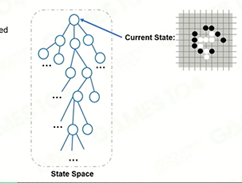
Default Policy:一个由人为设定或数据集训练而获得的某种规则性质的行为方式(如围棋AI是根据训练集中的内容选取一个高胜率的走法并作为一种后续策略),即制造分支的方式(如果每种可能性都试一遍的话分支太多,某种角度上这是一种人为制定的剪枝策略)。
Simulation:根据Default Policy快速模拟整个游戏过程并获得结果。
如何判断下一步走的好坏:有两个指标,Q(模拟中的获胜分支上的节点数)和N(总节点数),Q/N获得这一步的获胜概率。

基础迭代步骤:
Expandable Node:未被完全开发的Node,即这个Node下的所有分支状态并没有被完全穷尽。
1. Selection:选择一个最有希望赢且没有被完全展开的结点。
选择策略:有Explotation(开发)和Exploration(探索)两种策略,分别代表了最优优先(选择胜率最高的结点)和未探索优先(选择未探索结点最多的结点)或者两者结合。

UCB理论:是两种选择策略的结合,根据未探索结点数和胜率综合选择下一步的策略。常数C为权值。
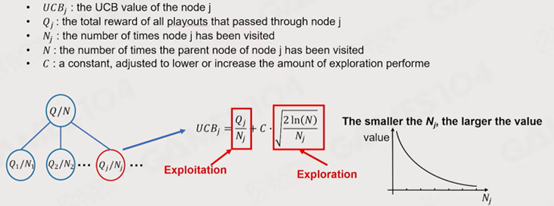
从根结点以UCB值为依据向下选择,直到选择到一个未探索结点(Expandable Node)。

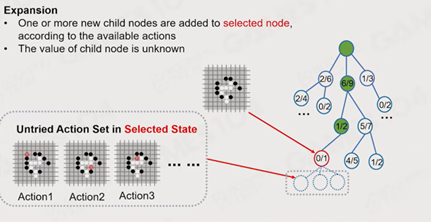
2. Expansion:展开计算该action方向的结点,即从被选择结点根据Default Policy向外扩展一组可能性,即生成该节点下的,一定深度的子树。
3.Simulation:模拟该节点的后续过程并获得一个输出结果(输或赢)。
4.Backpropagate:以该输出来更新原来结点的QN值。
终止条件:当内存达到一定限额或simulation迭代达到一定次数时,停止迭代。此时会获得一棵以当前状态为根节点的树。
最佳选择策略:此时有多重策略来选择后续策略。
- Max Child:选择Q值(获胜次数)最多的子树结点。
- Robust Child:选择后续展开最多的子树结点(一般后续胜利越多展开也越多,因此直接采用N值而非Q/N)。
- Max-Robust child:Q值和N值都最大的结点。如果现在没有满足需求的结点,则继续迭代直到满足需求。
- Secure child:计算LCB(综合采样次数和Q值来获得的一个值)来判断选择哪个树。
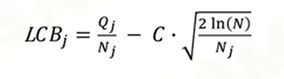
蒙特卡洛树搜索(MCTS)的优点:决策拥有自主性,解决问题的搜索空间大
缺点:对于一些复杂游戏的情况很难精确表达输赢,以及对当前状态的影响,不能适应所有的游戏类型。而且计算复杂度很大。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









