






简介:视频实例分割是对于视频中感兴趣的对象实例进行分类,分割和跟踪的任务,文章提出了一个被称为VisTR的视频实例分割框架,它将分个任务视为一个端到端的并行序列解码预测问题,即给定一个由多个图像帧组成的视频剪辑作为输入,VisTR按序列输出视频中每个实例的掩码序列。VisTR从相似性的角度,将视频作为一个整体进行监督和分割。这一模型建立在Transformer框架上。
Introduction
视频实例分割(VIS)要求计算机对于视频序列中感兴趣的对象实例进行分类,分割和追踪。本文提出了一种基于Transformer的实例分割模型,它需要在检测连续的视频帧之间的关联性以实现追踪等功能。
目前的方法分为两种:自上而下的方法遵循传统的检测跟踪规则,它们严重依赖图像级的实例分割模型和复杂的人为设计的规则来认知图像实例之间的关联性。自下而上的方法通过聚类像素来分离对象实例,它严重依赖于密度预测算法的质量,且步骤往往较多,因此速度很慢。
视频序列隐式包含了运动模式和时间一致性等信息,因此分析一个视频序列整体比逐帧分析图像所能获取的信息更多。本质上说,实例跟踪和分割都涉及到相似度学习,分割学习的是像素级的相似度,而跟踪则是实例级的。因此这些任务所基于的算法框架也可以是同一种。
本文的算法框架是基于Transformer实现的。首先,Transformer可以被作为算法中的一个通用编码器模块,这使它能够很方便地在处理信息后通过不同的头根据需要输出不同的内容(如分割通过一个MLP输出分割结果,追踪通过另一个MLP输出追踪结果),因此它可以被应用于不同输入输出的计算机视觉任务中。其次,transformer是一个序列到序列的学习模型,它能学习不同帧之间的关系,并可以通过自关注机制来学习特征间相似性。这些特性使它能在VIS任务中发挥巨大作用。
本文提出的VisTR模型将VIS任务视为一个并行序列解码/预测问题。给定一个由多个图像帧组成的视频剪辑作为输入,VisTR直接按顺序输出视频中每个实例的掩码序列。本文将每个实例的输出序列称为实例序列。
整个VisTR管道如图所示。在第一阶段,给定一个视频帧序列,标准CNN模块提取单个图像帧的特征,然后将多个图像特征按帧顺序连接起来,形成剪辑级特征序列。在第二阶段,Transformer将剪辑级特征序列作为输入,并按顺序输出一系列对象预测。在图中,相同的形状表示对同一图像的预测,相同的颜色表示不同图像的相同实例。预测序列遵循输入图像的顺序,每个图像的预测遵循相同的实例顺序。

要实现这一目标,有两个主要的挑战:1)如何维护输出的顺序,以及2)如何获得Transformer网络中每个实例的掩码序列。相应的,文章介绍了实例序列匹配策略和实例序列分割模块。实例序列匹配通过在输出实例序列和真值实例序列之间进行二部图匹配来维护输出顺序。实例序列分割通过自注意力机制将每个实例的掩码特征跨多帧累积,并通过三维卷积根据每个实例的掩码序列进行帧的分割。
主要贡献:
1)提出一种新的,端到端的视频实例分割框架VisTR。
2)VisTR从相似性学习的角度来完成任务,实例分割是学习像素级的相似度,而实例跟踪是学习实例间的相似度。
3)框架中实例序列匹配和分割的新策略使该模型能够在整个序列级别上监督和分割实例。
Related Work
视频对象分割VOS
VOS和VIS关系密切,VOS需要在视频的第一帧给出物体的初始分割标注,并在此基础上对视频后续帧中的标定物体进行跟踪和分割,它是类别无关的(即不会在任务之前预定物体的类别范围)。而VIS则是在预定的物体类别范围内实现无第一帧标签的物体检测,分类,跟踪和分割。
视频实例分割VIS
VIS任务需要对每个帧中的实例进行分类、分段,并跨帧链接相同的实例。先进的方法通常需要复杂的pipeline来解决问题。MaskTrack R-CNN基于Mask R-CNN来跟踪实例间的特征,而Makprop则基于多任务级联网络通过掩码来裁剪提取的特征,并通过传播的方式来提升分割和追踪的质量。STEm-seg将视频序列视为一个三维的对象,通过聚类学习来分离对象中的实例。上述方法要么依赖于复杂的启发式规则来关联实例,要么需要多个步骤来迭代地生成和优化掩码。相比之下,文章构建的是一个简单的端到端可训练的VIS框架。
Transformer
Transformer最初是一个用于序列导序列的机器学习任务的模型,它的核心是自注意力机制。DETR构建了一个基于Transformer的目标检测系统,大大简化了传统的检测流水线。ViT将Transformer引入到图像识别中,并将图像建模为patch序列,与最先进的卷积网络相比,它获得了出色的结果。以上工作表明了Transformer在图像理解任务中的有效性。可以直观地看到,Transformer建模远程依赖关系的优势使其成为学习视频理解任务中跨多个帧的时间信息的理想候选者。为了效率,本文使用的是Transformer的非自回归的并行输出变体。
Method
文章将视频实例分割任务建模为直接序列预测问题来解决它。给定一个由多个图像帧组成的视频剪辑作为输入,VisTR按顺序输出视频中每个实例的掩码序列。为了实现这一目标,文章引入了实例序列匹配和分割策略,将实例作为一个整体在序列级进行监督和分割。
VisTR结构
VisTR包括四个主要组件:一个用于提取多帧的特征表示的CNN主干,一个用于学习像素级和实例级特征相似性的编码器-解码器模式的Transformer,一个用于监督模型的实例序列匹配模块,一个分割模块。

CNN backbone:该部分的作用是提取视频片段的像素级特征序列,设初始视频片段包含T帧,分辨率为H0*W0,因此输入数据大小为T*3*H0*W0,CNN主干会为每一帧生成一个低分辨率的特征图,然后连接每一帧的特征,形成大小为T*C*H*W的特征图片段。
Transformer Encoder:编码器部分用于学习片段的像素特征之间的相似性。首先,通过1*1卷积将输入数据的C降维到d,即得到新的大小为T*d*H*W的特征映射。然后,为了可以输入到Transformer中,文章将时间空间维度转为1维,即得到了d*(T*H*W)大小的2D特征序列,输入的时间顺序与初始输入顺序一致。编码器的架构为标准架构,即由一个多头自注意力模块和一个FFN构成。
时空位置编码:文章使用了原始transformer的位置编码应用于本文(就是sine编码)。
Transformer decoder:参考了DETR,文章使用了固定数量的输入嵌入来从像素特征中查询实例特征,称为实例查询。假设模型每帧要检测n个实例,则对于T帧,实例查询数为n = n·T。该部分的输入为编码器的输出E和N个实例查询Q,输出N个实例特征O。整体预测的顺序遵循输入帧的顺序,对于每一帧,他们各自的实例预测顺序也是相同的。因此可以根据输出顺序直接查询到不同帧中对应实例的跟踪结果。
实例匹配策略
VisTR在一次解码器解码过程中推断出一个固定大小为N的预测序列。该框架主要挑战之一是维护不同图像中同一实例预测的相对位置。为了对预测结果进行整体监督,文章引入了实例序列匹配策略。用y^i表示预测的第i个结果,yi表示真值,假定每一帧设定的实例预测数n大于真实所需的实例预测数,也认为y是一个大小为n的真值集合,中间用空值∅填充。通过公式2查找一个最佳的实例匹配方式。

这里应该是保证了帧与帧之间的序列性和帧之间对应实例位置的序列性,而帧内部的实例匹配顺序是自由的。举个例子,有两帧的预测实例序列a1,a2,a3,a4,a5,b1,b2,b3,b4,b5;帧a和b的相对位置,a1和b1,a2和b2等的相对位置都应当是固定的,但是a1,a2,a3等这些的相对位置是可以变化,即通过最佳匹配来获得的,即预测序列根据最佳匹配结果不同也可以变为a1,a3,a5,a2,a4, b1,b3,b5,b2,b4这样子。
公式中,Lmatch是基础真值和预测序列之间的成对匹配代价,通过匈牙利算法可以有效的计算出最优匹配。这个代价是由相似度得出的。由于直接计算掩码序列相似度计算量过大,因此只用一个粗略的包围盒预测匹配来计算相似度。通过在解码器后附加一个带ReLU函数的3层FFN和一个线性投影层来获得目标预测。FFN直接预测包围盒的中心坐标和长宽,线性层则被添加一个softmax函数用于预测实例对应的标签。同时,添加了一个“background”类用于表示空实例。
最终,通过解码器获得一个n*T大小的包围盒序列。匹配损失考虑到了类标签预测和包围盒之间的相似性。对于实例的真值集合,其中的每个元素可以通过公式3表示。ci表示该实例的类标签号(可能为∅),bit则定义了该实例在帧t中对应的中心坐标和宽高。T表示输入帧的个数。
![]()
对于第i个实例的预测结果,其预测的对应的标签概率集合可以用公式4来表示,而其预测的包围盒集合可以用公式5来表示。根据上述内容,匹配损失可以用公式6来表示。ci 不能为 ∅(不考虑空缺部分的匹配损失?),基于上述准则,可以通过匈牙利算法获得最优匹配,并根据匹配结果计算损失函数。损失函数是预测标签,包围盒损失和掩码损失的线性组合,如公式7。其中 σ是计算出的最佳匹配,同样地,计算该损失函数时ci不能为 ∅。
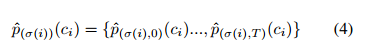



包围盒损失用的是IOU损失和每个像素的L1损失的线性组合,如公式8。这些损失都会根据预测实例的数量被归一化。

实例序列分割
实例序列分割模块旨在预测每个实例的掩码序列。为了实现这一点,该模型需要首先需要累积每个实例的多帧的掩码特征,然后根据累积的特征生成掩码序列。
为了简化计算,实例分割模块每次只计算某一帧下某一实例的掩码。对于每一帧,将decoder输出的某一帧下某一实例O和encoder输出的经过自注意力卷积的特征图E输入到一个自注意力模块中(这个地方总觉得应该是以E为主导输入的交叉注意力模块,但是文章没提O到底是什么结构,也可能O是一个特征图,而这里用的是通道拼接),自注意力模块的输出与E和backbone输出的初始特征图B拼接后输入到一个可变形的3D卷积层中,最终输出不同帧不同实例的掩码序列。
同一实例在不同帧中的掩码特征应当是能够相互学习和增强的,文章用三维卷积来实现这一点。假设帧t下某一实例的掩码特征git大小为1*a*(H0/4)*(W0/4),其中a为通道数。将T帧的实例特征做连接,形成gi,其大小为1*a*T*(H0/4)*(W0/4)。实例分割模块以gi作为输入,直接输出该实例在每一帧的掩码序列mi,其大小为1*1*T*(H0/4)*(W0/4)。三维卷积部分由三个三维卷积层和具有ReLU的group normalization层组成的模块构成。但是,最后一层卷积后不进行归一化和激活。最后一层输出通道号为1,这样就得到了T帧实例的掩码。公式7定义了该模块的损失函数,它计算的是掩模损失,有Dice loss 和 Focal loss组合得到(有关两种loss可见这篇文章:focalloss,diceloss 知识点总结_dice loss和focal loss_啥也不会就会混的博客-CSDN博客)。
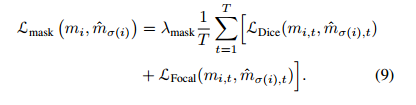
Experiments
数据集和实现细节
本文在YoutubeVIS数据集上进行了实验。该数据集包含2238个训练视频片段,302个验证视频片段和343个测试视频片段。数据集的每个视频都用每像素分割掩码、类别和实例标签进行注释。对象类别号为40。文章在验证集上评估了模型,评估指标是根据IOU和阈值得出的平均精度和平均召回率。YouTube-VIS中标注的视频长度最大为36,文章将此值作为默认输入视频片段长度t,该模型每帧预测10个对象,因此对象查询总数为360。模型通过Pytorch实现。对于在不同帧中被分类到不同类别的实例,我们使用最频繁预测的类别作为最终实例类别
消融实验
视频和图像的主要区别在于视频包含时间信息。如何有效地学习和利用时间信息是视频理解的关键。
时间长度:如表1a所示,在帧长度从18到36的范围内,AP从29.7%单调增加到33.3%。这一结果表明,更多帧的信息确实有助于模型更好地学习。文章认为如果使用更大的数据集,VisTR可以获得更好的结果。

视频序列顺序:由于真实场景中物体的运动是连续的,文章认为时间信息的顺序也很重要。为了评估,文章对随机顺序和时间顺序输入视频序列训练的模型进行了比较。从表1c的结果可以看出,根据时间顺序信息学习的模型得分高出1分,这说明了时间顺序的重要性。

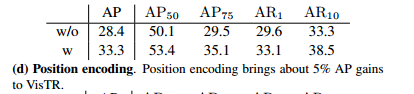
位置编码:该模型对视频序列补充了空间和时间位置编码,以表示视频序列中某帧的相对位置。尽管视频序列本身的顺序实际上隐式蕴含了位置信息,但是加上位置编码后能强化这种信息。表格1d体现了位置编码的重要性。
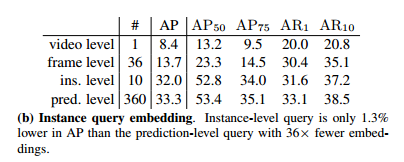
实例查询:假设模型每帧解码n个实例,帧号为T。输入实例查询号应该是n × T,以便为预测解码相同的数字。在默认设置中,一个嵌入负责一个预测,模型直接学习n × T唯一的嵌入。在表1b中称为“pred. level”。在“video level”中,对所有实例预测学习一个嵌入,即相同的嵌入重复n × T次作为解码器的输入。在“frame level”设置中,模型只学习T个唯一的嵌入,并重复它们n次。在“ins. level”设置中,模型只学习n个唯一的嵌入,并重复它们T次。令人惊讶的是,“ins. level”查询可以达到32.0%的AP,只比默认设置低1.3个点。这表明一个实例的查询可以被VisTR模型共享,从而使跟踪变得自然。但是对同一帧的查询不能共享。
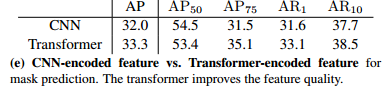
用于特征编码的Transformer:如前文所描述,实例分割模块采用三种类型的特征作为输入:来自主干的特征“B”,来自编码器的特征“E”,以及由特征“E”计算得出来自decoder的实例掩码特征图输出O。为了说明Transformer编码器的优越性,用编码器部分的原始输入代替B做了实验,并比较了结果。实验结果如表e。这说明了Transformer能基于自注意力机制学习特征图之间的成对相似性并更新这些信息。
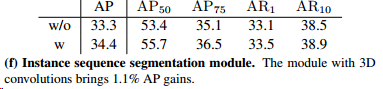
实例序列分割:分割过程包含实例掩码特征积累和实例序列分割两个模块。实例序列分割模块将实例序列作为一个整体。文章期望通过三维卷积学习时间信息来增强掩模预测。因此,当物体处于遮挡或运动模糊等具有挑战性的情况下时,该模块可以学习从其他帧传播信息以帮助分割。此外,从多个帧中提取同一实例的特征可以帮助网络更好地识别实例。在本实验中,文章对带有或不带有3D实例序列分割模块的模型进行了研究。对于前一种情况,文章对每帧的每个实例的掩码特征应用一个输出通道为1的2D卷积层来获得掩码。比较结果如表1f所示。实例序列分割模块将分割结果提高了1.1分,这验证了该模块的有效性。
实验结果比较
文章将VisTR与当时的一些先进方法进行了比较,包括一些为了跟踪和VOS的目的提出的方法,MaskTrack RCNN、MaskProp和STEmSeg。可以看出除了MaskProp外,VisTR的结果多数都更好。文章认为VisTR与MaskProp之间的AP差距主要来自于MaskProp结合了多个网络,而本文设计的是一个简单的端到端网络。此外,VisTR还表现出了较快的处理速度。本文是串行加载数据的,而这一步是很容易并行化的,意思是速度还可以更快。VisTR在YouTube-VIS验证数据集上的可视化如图3所示,每一行都包含从同一视频中采样的图像。在具有挑战性的情况下,VisTR可以很好地跟踪和分割实例,例如:(a)实例重叠,(b)实例之间相对位置的变化,(c)同一类别实例靠近在一起的混淆,以及(d)不同姿势的实例。

Conclusion
本文提出了一个新的基于transformer的视频实例分割框架,该框架将VIS任务视为直接的端到端并行序列解码/预测问题。与现有的方法相比,本文的方法速度更高,且与多数方法相比更加准确。















 1846
1846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









