






摘要:本文提出的神经网络是基于PolyWorld神经网络的改进,它从图像中提取物体顶点并将它们最佳地连接以生成精确的多边形。本工作的目的是克服原始模型的缺点和不足,并引入改进的多边形表示,以获得一种通用的图像多边形提取方法。该结构经过重新设计,不仅利用了顶点特征,而且还利用了边缘的视觉外观。
Introduction
利用神经网络进行多边形生成的两个问题:1.预测顶点过多,导致出现伪影;2.预测顶点过少,无法捕捉细节。
本文提出了Re:PolyWorld来改进PolyWorld这个神经网络。Polyworld模型使用卷积神经网络(CNN)提取建筑角的位置和视觉描述符,并通过评估顶点之间的连接是否有效来生成多边形。连接通过置换矩阵表示。但该模型的多边形生成过程也只基于局部的视觉特征向量,即探测到的角点向量。同时,该模型并未在其它应用上实验过。本文正是针对这些内容的改进。
本文的贡献:
1. 提出一种新的多边形场景广义表示;
2. 为模型添加了新的边缘感知注意机制;
3. 在不同的应用领域评估了模型,包括建筑物提取,平面图重建,甚至线框解析。
Related Work
建筑轮廓的检测和多边形化
传统方法通常在逐像素预测边界后,通过复杂的算法提取边界和简化多边形。
PolyMapper先通过边界框来检测建筑物,然后应用RNN来逐个预测建筑物和道路的顶点。
Frame Field Learning产生一个矢量场,编码有用的边界信息和相应的分割掩码。在后处理步骤中,通过主动骨架模型对轮廓进行优化。它是目前提取建筑多边形最有效的方法之一。
平面图和建筑结构的重建
FloorSP通过Mask-R-CNN来检测房间分段,并通过求解优化问题选择分段来重建平面图。
Montefloor也使用了Mask-R-CNN来检测分段,并使用蒙特卡罗树来筛选分段。
HEAT提出了一种基于自注意力机制的神经网络,它通过传统方式检测角点,并使用整体边缘分类架构对角点之间的候选边缘进行选择。
线框解析
该类模型灵感来源于用于估计人体姿势的深度学习模型,这导致了L-CNN的出现和发展。该算法利用采样方案根据预测的连接点生成备选线段,并利用线段验证模块对其进行分类。其问题是计算成本过高,且生成模块忽视的备选线段信息可能会导致验证模块无法充分被利用的问题。
基于吸引场图(attraction field map, AFM)的方法[22,23]在线段检测方面达到了出色的性能,而无需在学习过程中利用连接点信息来获得备选线段。
HAWP的方式与L-CNN类似。但是它通过引入一种新的线段预测方法来实现更准确的解析,从而实现了最先进的性能。
Method
多边形表示方式
与PolyWorld类似,这项工作旨在将图像中的多边形表示为一组顶点,并通过相应的矩阵表示它们之间的连接关系。PolyWorld通过置换矩阵来表示连接关系,通过最小化最优传输损失(一种衡量变换所需最小cost的损失函数)来训练网络。PolyWorld被用于预测强边(明显的边缘),并最终生成多边形。但是这有一个限制:由于预测是基于置换矩阵的,因此如果图像包含具有共享顶点的多边形,PolyWorld是无法预测和表示的。
本文改进了多边形场景的表示方法,通过用k个相同的顶点实例集合Vi = {v1i,v2i,...,vki}代替原本单独的一个顶点vi,使得顶点vi最多可被k个边共享。边缘的编码方式从置换矩阵变成了邻接矩阵A,每个顶点对应一行,这使得每个顶点能连接多个边。A的每行每列的和都为k。A可以被展开为数个领接矩阵P的组合。其中每一行都分配给特定的顶点实例vj i,并指示下一个顺时针连接的顶点。
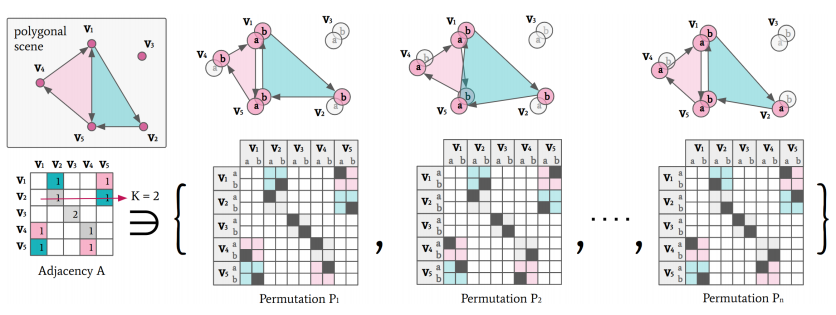
Ai,j表示顶点vi和vj之间的连接数,等于排列矩阵P中连接vi和vj的元素的总和。
P不具有唯一性,即同属于一个A的Pi和Pj可能表示的是起点不同或相同的同一个多边形。
简单来说,矩阵定义了数个多边形的连接方式。每行每列的和为K限制了每个角点的最大连接数目。若一个角点i连接数小于k或者没有连接,则它多余的数字会被分配到i行i列这一格中。
神经网络架构
Re:PolyWorld的输入为图像,输出为一组2D坐标表示定点和一个排列矩阵来表示他们之间的连接关系。
该架构基于图像边缘感知的考虑,提出了一个由三个块组成的神经网络:一个图编码器网络用于检测图像中的显著顶点,并为顶点和边缘生成视觉描述符,即特征向量;一个边缘感知图神经网络,用于对图结构进行推理并更新节点和边缘的表示;一个用于预测最优的顶点匹配方式的最优链接网络。

图编码器网络
作为第一个模块,它的作用是为图像编码。它接收3*H*W大小的图像作为输入,并用CNN主干将其转为D*H*W大小的特征图。再通过一种投影方式F来获得H*W的顶点预测映射(应该是预测该处为顶点的概率),最后通过非极大抑制层(NMS,通过抑制非极大值来获得极大值序列的一种方式,此处应当是获得一系列最有可能为顶点的位置)生成一组N个2d位置pi,表示检测到的N个峰值。简单来说,就是找特征图上的极大值位置并将其作为角点备选。
在检测出顶点位置后,根据顶点位置和特征图F获得边特征描述符。边特征描述符通过公式(1)获得。该公式大体意思是输入顶点i到顶点j连线上各个像素位置的特征向量,对每个向量进行线性投影后,拼接并输入到一个MLP中,最终压缩成一个边特征向量ei->j。

边缘感知图神经网络
该模块的主要功能为通过聚合特征的方式来考虑上下文,以丰富和精确化顶点和边缘的特征向量。其输入为由编码器网络提取的顶点特征和边缘特征,通过图神经网络传播的方式来计算用于顶点匹配描述子di和边缘匹配描述子ei->j。
由于希望通过全局信息流更新图像中检测到的元素的局部表示,因此考虑用一个全连接图,即每个检测出的顶点都考虑所有的其它顶点及连接的边缘的信息。节点由检测到的顶点di表示,边缘带有属性ei->j。信息通过消息传递公式沿边缘传播。该模块由L层组成,每个层用并发形式聚合所有连接边的信息。消息传递公式如(2),其中mi为聚合与di相关的信息后的结果。公式大体意思就是将聚合信息和di拼接后输入一个MLP,输出和di用sum的方式聚合,获得迭代后的新的di。

边的信息也基于类似的方式进行更新,即将边的信息与其相连的两点的聚合信息拼接,然后输入到MLP,结果通过sum与ei->j聚合,获得新的ei->j
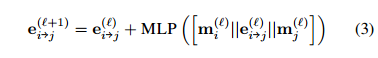
神经网络的第一层接收来自CNN的视觉描述符,最终输出用于下一模块的匹配描述符。
m代表了某个节点聚合信息的过程,其计算过程是基于自注意力机制进行的。其计算公式如下,基本就是将自注意力机制公式化了。σij代表两个点之间的连通性,它的计算方式就是对ei->j执行一个线性投影,即σij = E(ei->j)。

![]()
在某些应用中,顶点的具体位置可能不能固定在一处,如平面图生成要求边角90度,而检测出的顶点可能没法完美地实现这一要求。因此,需要在神经网络中实现调整顶点位置的功能。设顶点的偏移量为oi,它通过对某个顶点聚合的结果di进行MLP处理后获得。最终pi的位置被表示为oi+pi。
![]()
最优连接网络
最优连接网络生成一个N*N大小的,其中每项值的范围在[0,K]的排列矩阵P来连接检测到的顶点(这个排列矩阵的详细说明可以看前面的多边形表示方式一节),首先,网络生成一个N*N大小的分数矩阵S来表示每对顶点之间的连接强度。通过最小化∑PijSij来估计最优分配。
给定描述符di,dj和ei->j,网络通过计算得分i来评估第i个顶点是否按顺时针顺序连接第j个顶点,即得分I。每对之间的得分I组成了分数矩阵S。

同时,为了保证分数的双向(顺逆时针)相通性,因此用另一个MLP来计算逆时针链接的分数,即公式(9)。
此处有一个疑点,作者说由于顺时针的分数矩阵实质是逆时针分数矩阵的转置,因此最终分数其实可用原分数矩阵和转置分数矩阵相加获得。即下列公式。但是这样的话之前的顺时针分数矩阵计算就没用了。个人认为这个地方提供的是一种简化计算的备选方案(这个地方可能指的是那些需要保证对称性的排列矩阵会这么计算,不需要的则用两个MLP分别计算顺时针和逆时针再相加?)。
![]()
最后,使用Sinkhorn算法来计算整体分数和的最小值。这个地方注意要满足排列矩阵的条件,即每行,每列的值之和为K。最终,根据这个可以获得排列矩阵。
损失值
顶点检测损失Ldet:通过计算顶点预测图和真实的顶点位置图之间的加权交叉熵来计算损失。
匹配损失Lmatch:通过预测的排列矩阵与真实排列矩阵之间的交叉熵损失Lmatch来学习生成顶点连接。
细化偏移量oi:即细化顶点位置的偏移量,通过角度损失Lang和分割损失Lseg的组合来鼓励神经网络生成90°角的多边形。这在建筑轮廓提取或平面图重建中很重要。
训练过程
顶点的匹配方案
首先,确保顶点的数目一定大于gt中的点的数目。然后,根据欧几里得距离将每个真实点与最近的预测点联系起来。多余的预测顶点被分配到排列矩阵的对角线上,即他们的K个边都分布在排列矩阵对角线上(表示无效边)。
gt的排列指导
gt的排列矩阵不一定是唯一的(即可以由多种不同的排列矩阵表示)。为了解决这个问题,通过公式10来获得一个最优的(即与当前预测的排列可能最接近的)排列矩阵表示。(这里有个问题,此处使用的是最大化分数和的排列矩阵,但是之前预测时用的是最小化分数和来计算排列矩阵。这地方是不是错了?)

值得注意的是,矩阵的n次方是为了利用邻接矩阵的一个属性:元素An i,j给出了从顶点i到顶点j的长度为n的有向行走的次数。因此,这个属性可以用来排除(从可能的排列集合中)编码具有特定顶点数量的多边形的解。在平面图重建或建筑检测等应用中,我们设置n = 2以避免获得具有两个顶点(线)的多边形。在线框解析中,需要检测某条单独的边,因此使用n = 1。
阶段性训练
PolyWorld的训练分为三个步骤。首先,只使用Ldet对顶点检测路径进行预训练;其次,结合Ldet + Lmatch联合训练检测路径和匹配路径。最后,如果应用程序需要,通过训练具有完整目标的网络来学习偏移量:Ldet + Lmatch + Lang + Lseg。
使用CrowdAI Mapping Challenge数据集进行了建筑边框提取实验,并进行了消融实验,发现额外使用边框信息是有用的,且在各项指标上(IOU,最大切角误差max tangent angle error,复杂度感知IOUcomplexity aware IOU)都表现出了更高的分数。


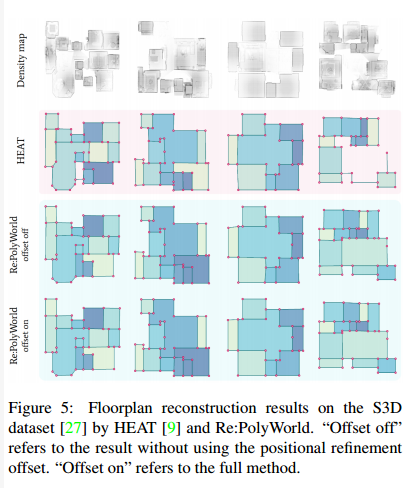
在structured3D上进行依据密度图的平面图重建实验,以证明模型的泛用能力。这两个数据集都需要一个能够将顶点连接到多个节点的模型,这使得多边形检测任务具有挑战性。然而,通过训练最大顶点实例数K = 4的Re:PolyWorld,可以有效地泛化到这些多边形场景,生成精确且视觉上准确的多边形。值得注意的是,当优化偏移量启用以增强顶点定位时,生成的多边形显示出更逼真的外观,并且可以在实际应用中使用,而不需要昂贵的后处理步骤。

通过将每条线定义为一个双顶点多边形,PolyWorld也可以用于预测图像片段或线框。通过以这种方式解释多边形场景,得到的排列矩阵P是对称的,因此不需要双路一致性。考虑到这些因素,通过使用单个MLP来计算分数矩阵S(如11)与其他方法相比,Re:PolyWorld方法产生的线框建议数量明显更少,其数量级与gt的数量相同。



Limitations
训练这种网络需要高质量的向量注释来成功训练关键点检测器。有噪声的注释,例如那些不对齐或缺失的注释,可能会抑制检测过程识别所有顶点,导致在匹配阶段遗漏对象角。简单来说就是对角点标注数据集的质量要求很高,不然结果会很差。
Conclusion
本文介绍了PolyWorld的一个修复和改进版本,PolyWorld是一个神经网络,它通过从图像中提取物体顶点并通过解决最优传输问题来优化连接它们来生成精确的多边形。该方法从图像中提取边缘和顶点的局部视觉描述符,并利用图神经网络结合全局线索和先验。在本文中,我们提出了一个边缘感知注意机制作为模型的核心部分,允许网络更有效地对场景进行推理,并最终生成更精确的多边形。















 4779
4779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









