






摘要
1介绍
本文提出了一种基于神经衰减场(Neural Attenuation Fields, NAF)的快速自监督稀疏视图CBCT重建方法。在这里,我们使用“自我监督”来强调NAF不需要外部CT扫描,而是需要感兴趣物体的x射线投影。受三维重建工作的启发[13,16],我们将衰减系数场参数化为INR,用自监督网络管道模拟x射线衰减过程。具体来说,我们训练了一个多层感知器(MLP),其输入是一个编码的空间坐标(x;y;Z),其输出为该位置的衰减系数µ。我们没有使用常见的频域编码,而是采用哈希编码[14],这是一种基于学习的位置编码器,可以帮助网络快速学习高频细节。投影是通过预测采样点沿射线轨迹的衰减系数并相应地衰减入射光束来合成的。通过最小化真实投影和合成投影之间的误差,采用梯度下降法对网络进行优化。我们证明,在人体器官和幻影数据集上,NAF在数量和质量上都优于现有的解决方案。虽然大多数INR方法需要几个小时的培训,但我们的方法可以在10-40分钟内重建出详细的CT模型,与迭代方法相当。
- 我们提出了一种新的快速自监督稀疏视图CBCT重建方法。除了主题的投影外,既不需要外部数据集也不需要结构先验。
- 所提出的方法达到了最先进的精度,并且计算时间相对较短。该方法的性能和效率为临床CT应用提供了可行性。
- 守则将公开供调查之用。
2方法
2.1管道
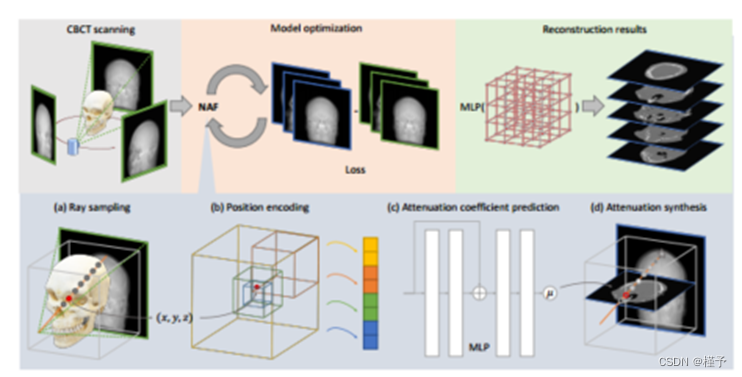
图1:NAF管道。灰色块:CBCT扫描仪从不同角度捕获x射线投影。蓝色方块:NAF模拟投影。橙色块:NAF通过比较真实投影和合成投影进行优化。绿色块:NAF通过查询相应体素生成CT模型。
2.2神经衰减场
射线采样投影图像的每个像素值都是x射线穿过立方体空间并被内部介质衰减的结果。我们在射线与立方体相交的地方采样N个点。采用分层抽样方法[13],将一条射线分成N个间隔均匀的箱子,在每个箱子上均匀取样一个点。设置N大于期望的CT大小确保至少一个样本分配到x射线遍历的每个网格单元。然后将采样点的坐标发送到位置编码模块。
位置编码一个简单的MLP理论上可以近似任何函数[9]。然而,最近的研究[18,21]表明,由于“频谱偏差”,神经网络更倾向于学习低频细节。为此,引入位置编码器将三维空间坐标映射到高维空间。
为了利用扫描对象的上述特征,我们使用哈希编码器[14],这是一种基于学习的稀疏编码解决方案。哈希编码器MH的方程为:
![]()
哈希编码器通过L个多分辨率体素网格来描述有界空间。为每个体素网格分配一个大小为T的可训练特征查找表Θ。在每个分辨率级别,我们1)检测查询点p的相邻角c(图1(b)中不同颜色的立方体),2)以哈希函数方式H[23]查找其对应的特征H, 3)使用线性插值生成特征向量i。哈希编码器的输出是所有分辨率级别的特征向量的串联。哈希函数及其符号的更多细节可以在[14]中找到。
衰减系数预测我们用一个简单的MLP Φ表示有界场,它以编码的空间坐标作为输入,输出该位置的衰减系数µ。如图1(c)所示,该网络由4个全连接层组成。前三层有32个通道宽,中间有ReLU激活功能,而最后一层有一个神经元,后面跟着一个s型激活。包括一个跳过连接,将网络输入连接到第二层的激活。相比之下,Zang等人使用6层256通道MLP从频率编码器学习特征。我们的网络要小10倍。
衰减综合根据比尔定律,x射线穿越物质的强度通过其路径上衰减系数的指数积分来降低。对衰减过程进行数值合成:
![]()
其中I0为初始强度,δi = kpi+1 - pik为相邻点之间的距离。
2.3模型优化与输出
NAF通过最小化真实投影和合成投影之间的L2损失来更新。损失函数L定义为:
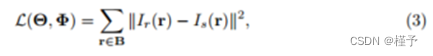
其中B为射线批,Ir和is分别为射线r的实投影和合成投影。我们在训练过程中同时更新哈希编码器Θ和衰减系数网络Φ。
最后的输出是一个离散的三维矩阵。我们建立一个具有所需尺寸的体素网格,并将体素坐标传递给训练好的MLP来预测相应的衰减系数。这样就恢复了CT模型。
3实验
3.1实验设置
我们在包含人体器官和幻影数据的五个数据集上进行实验。详情见表1。
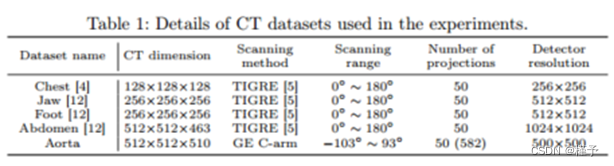
人体器官:我们使用人体器官ct的公开数据集来评估我们的方法[4,12],包括胸部、颌骨、足部和腹部。胸部数据来自LIDC-IDRI数据集[4],其余数据来自开放科学可视化数据集[12]。由于这些数据集只提供体积CT扫描,我们通过层析成像工具箱TIGRE[5]生成投影。在TIGRE[5]中,我们在180°范围内捕获了50个带有3%噪声的投影。我们用这些投影训练我们的模型,并用原始体积CT数据评估其性能。
幻影:我们通过使用GE c臂医疗系统扫描一个硅主动脉幻影来收集幻影数据集。该系统捕获582 500×500透视投影,定位主要角度为-103◦至93◦,定位次要角度为0◦。一个512×512×510 CT图像也生成与内置算法为基础的事实。我们只用50个投影来做实验。
Baselines我们将我们的方法与四种基线技术进行比较。首先选择FDK[7]作为分析方法的代表。第二种方法SART[2]是一种鲁棒迭代重建算法。ASD-POCS[20]是另一种带全变分正则器的迭代方法。我们实现了IntraTomo[28]的CBCT变体,命名为IntraTomo3D,作为频率编码深度学习方法的一个例子。
实现细节我们提出的方法是在PyTorch[17]中实现的。我们使用Adam优化器,其学习率从1 × 10−3开始,逐步降低到1 × 10−4。每次迭代的批处理大小为2048条射线。每条射线的采样量取决于CT数据的大小。例如,我们在128×128×128胸部CT的每条射线上采样192个点。我们对哈希编码器使用与[14]相同的超参数设置。关于超参数的更多细节可以在补充材料中找到。所有实验均在单个RTX 3090 GPU上进行。我们根据峰值信噪比(PNSR)和结构相似性(SSIM)[25]对五种方法进行了定量评价。PSNR (dB)统计评估伪信号抑制性能,而SSIM衡量两个信号之间的感知差异。PNSR/SSIM值越高代表重构越准确,反之亦然。
效果我们的方法在表2所列的人体器官和幻影数据集中都产生了定量上最好的结果。PSNR和SSIM值均显著高于其他方法。例如,我们的方法在腹部数据集中的PSNR值比第二好的方法SART高3.07 dB。
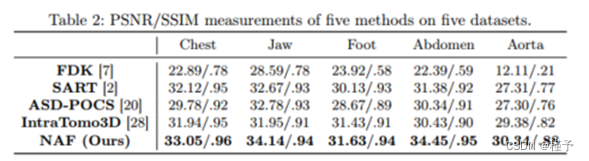
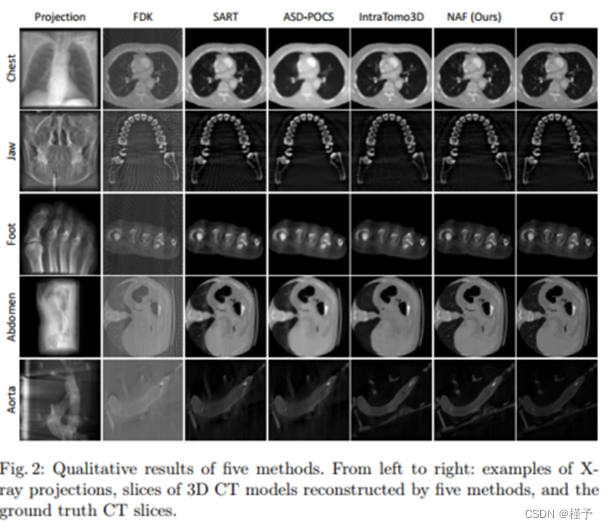
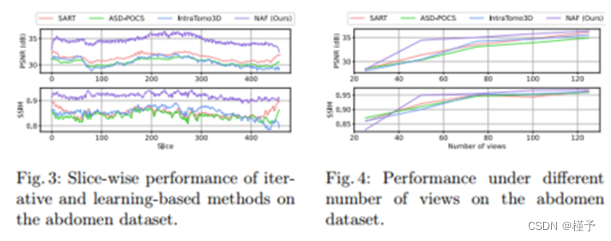
图4显示了迭代方法和基于学习的方法在不同视图数下的性能。很明显,性能随着输入视图的增加而提高。在大多数情况下,我们的方法比其他方法取得更好的效果。
时间我们记录迭代和基于学习的方法的运行时间,如图5所示。所有方法都使用CUDA[15]来加速计算过程。总的来说,这些方法在具有小投影的数据集(胸部、下巴和脚)上花费的时间更少,而在大数据集(腹部和主动脉)上花费的时间越来越多。IntraTomo3D需要一个多小时来训练网络。得益于紧凑的网络设计,NAF的运行时间与迭代方法相似,比频率编码深度学习方法IntraTomo3D快3倍。

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









