






摘要
计算机断层扫描(CT)是一种有效的医学成像模式,在临床医学领域广泛用于诊断各种病症。多探头 CT 成像技术的进步使其具备了更多的功能,包括生成薄片多平面横截面人体成像和三维重建。然而,这需要病人暴露在相当大剂量的电离辐射下。过量的电离辐射会对人体造成确定性的有害影响。本文提出了一种深度学习模型,可学习从几张甚至单张视图 X 光片重建 CT 投影。该模型基于一种基于神经辐射场的新型架构,通过从二维图像中分离表面和内部解剖结构的形状和体积深度,学习 CT 扫描的连续表示。我们的模型是在胸部和膝盖数据集上训练出来的,我们展示了定性和定量的高保真渲染,并将我们的方法与其他最新的基于辐射场的方法进行了比较。我们的代码和数据集链接见 abrilcf/mednerf (github.com)临床相关性--我们的模型能够从几张或单视角 X 光片中推断出解剖三维结构,显示了在成像过程中减少电离辐射暴露的未来潜力。
1. 引言
2. 方法
A.数据集准备
为了训练我们的模型,我们生成DRRs,而不是收集成对的x射线和相应的CT重建,这将使患者暴露在更多的辐射中。此外,DRR生成删除了患者数据,并能够控制捕获范围和分辨率。我们通过使用[15],bb0的20次CT胸部扫描和[17],[18]的5次CT膝关节扫描来生成DRRs。这些扫描覆盖了不同对比类型的不同患者,显示了正常和异常的解剖结构。假设辐射源和成像面板绕垂直轴旋转,每5度产生一个分辨率为128×128的DRR,每个物体产生72个DRR。在训练期间,我们对每个患者使用整套72个drr(360度垂直旋转范围内所有视图的五分之一),并让模型渲染其余部分。我们的工作不涉及人类受试者或动物的实验程序,因此不需要机构审查委员会的批准。
B. GRAF概述
GRAF[14]是一个从NeRF构建的模型,并在生成对抗网络(GAN)中定义它。它由预测图像patch P pred的生成器Gθ和将预测的patch与从真实图像中提取的patch P real进行比较的鉴别器Dφ组成。与原始的NeRF[12]和[19]等类似方法相比,GRAF已经显示出从2D图像中分离物体三维形状和视点的有效能力。因此,我们的目标是将GRAF的方法转化为我们的任务,在第II-C节中,我们描述了我们的新鉴别器架构,它允许我们从drr中分离出3D属性。
我们考虑实验设置来获得辐射衰减响应,而不是在自然图像中使用的颜色。为了获得姿态为ξ的任意投影K在像素位置处的衰减响应,首先,我们考虑模式ν = (u;s)在K × K图像贴片P内采样R个x射线束。然后,我们沿着从像素位置出发的x射线束r采样N个3D点x i r,并在投影的近面和远面之间排序(图1a)。
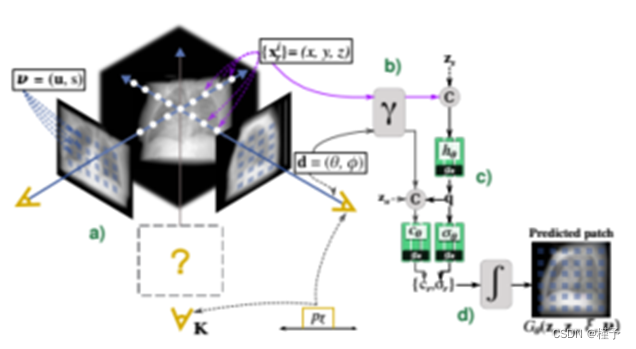
对象表示在多层感知器(MLP)中编码,该感知器以3D位置x = (x;y;Z),观察方向d = (θ;φ),生产作为输出的是密度标量σ和像素值c。为了学习高频特征,将输入映射为二维表示(图1b):
![]()
为了建模解剖结构的形状和外观,设zs ~ ps和za ~ pa分别为从标准高斯分布中采样的潜在代码(图1c)。为了得到密度预测σ,将形状编码q通过密度头σθ转换为体积密度。然后,网络gθ(·)作用于一个形状编码q = (γ(x);zs),然后与位置编码d和外观编码za连接(图1c):
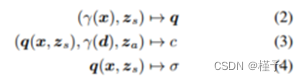

其中α I r = 1 - exp (- σ I r δ I r)是采样点I的α合成值,δ I r =k x I +1 r - x I r k2是相邻采样点之间的距离。
通过这种方法,用网络gθ计算沿光束r的每个采样点的密度和像素值。最后,结合所有R光束的结果,发生器Gθ预测图像patch P pred,如图1d所示。
C. MedNeRF
我们研究了如何将GRAF应用于医学领域,并将其应用于DRRs的体积表示。利用大型数据集,GRAF的鉴别器Dφ能够连续提供有用的信号来训练生成器Gθ。然而,在我们的问题中考虑的医疗数据集通常很小,这导致了两个连续的问题:
缺乏对生成器的真实信息:在GRAF(以及一般的GAN)中,特征的唯一来源用于生成器的训练数据是从鉴别器传递过来的间接梯度。我们发现GRAF鉴别器的单卷积反馈不能很好地传达来自drr的精细特征,导致不准确的体积估计。
脆弱的对抗训练:使用有限的训练数据集,生成器或鉴别器可能会陷入病态设置,例如模式崩溃,这将导致生成有限数量的实例,从而导致次优的数据分布估计。虽然一些工作已经应用数据增强技术来利用医疗领域中的更多数据,但一些转换可能会误导生成器学习不常见甚至不存在的增强数据分布[20]。我们发现,天真地应用经典数据增强的效果不如我们采用的框架好。

为了允许更丰富的drr特征映射覆盖,从而产生更全面的信号来训练Gθ,我们用自监督方法的最新进展取代了GRAF的判别器架构。我们允许Dφ在一个借口任务上学习有用的全局和局部特征,特别是基于自编码的自监督方法。与[21]不同的是,我们只使用两个解码器来处理尺度上的特征图:f1在322上,f2在82上(图2a)。我们发现这种选择允许更好的性能,并实现正确的体积深度估计。因此,Dφ不仅要区分预测的P pred和Gθ,还要从真实图像patch P real中提取综合特征,使解码器能够与数据分布相似。
为了评估来自Dφ的解码补丁的全局结构,我们使用了学习感知图像补丁相似度(LPIPS)度量[22]。我们计算两个VGG16特征空间之间的加权两两图像距离,其中预训练的权重适合于更好地匹配人类感知判断。因此,额外的鉴别器损失为:
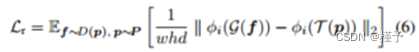
式中φi(·)为预训练VGG16网络的第i层输出,w、h、d分别为特征空间的宽度、高度和深度。设G为对来自Dφ的中间特征映射f的处理,T为对真实图像patch的处理。当加上这种额外的重建损失时,网络学习跨任务传输的表示。
我们通过采用优化GAN (DAG)的数据增强框架[20]来改进Gθ和Dφ的学习,其中数据增强变换Tk(图2b)应用了多个鉴别器头fDkg。为了进一步减少内存使用,我们共享除每个磁头对应的最后一层之外的所有Dφ层(图2c)。由于应用了可微和可逆的数据增广变换,Tk具有Jenssen-Shannon (JS)守恒性[20]:
![]()
其中ptk d是变换后的训练数据分布,ptk g是变换后的由Gθ捕获的分布。通过使用包含翻转和旋转的总共四种转换,我们鼓励对原始数据分布进行优化,这也带来了最大的性能提升。这些选择使我们的模型不仅受益于JS(pd k pg),而且受益于JS(p Tk d k p Tk g),从而提高了Gθ的学习和d φ的泛化。此外,使用权值共享的多重鉴别器提供了Dφ的学习正则化。
将GRAF的物流目标替换为铰链损失,我们将总体损失定义如下:
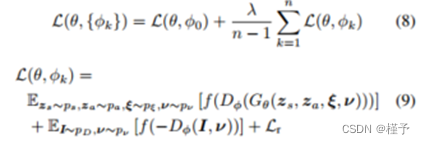
式中f(u) = max(0;1 + u)。我们用n = 4来优化这个损失,其中k = 0对应于单位变换,λ = 0:2(如[20])。
在训练模型后,我们在给定单视图x射线的医疗实例的完整垂直旋转内重建完整的x射线投影。我们遵循[23]中的松弛重建公式,它使生成器适合于单个图像。然后,我们允许对发生器Gθ的参数以及形状和外观潜在向量zs和za进行稍微微调。在GAN方法[24]中,失真和感知权衡是众所周知的,因此我们通过添加失真均方误差(MSE)损失来修改生成目标,从而激励模糊与准确之间的平衡:
![]()
其中NLLL对应负对数似然损失和调谐超参数lr = 0:0005, β1 = 0, β2 = 0:999, λ1 = 0:3, λ2 = 0:1和λ3 = 0:3。一旦模型找到zs和za的最佳组合,我们就复制它们,并通过持续控制角度视点来渲染其余的x射线投影。
3.结果

图3所示。膝关节渲染从连续的视点旋转显示组织和骨骼。给定CT的单视图x射线,我们可以通过稍微微调预训练模型以及形状和外观潜在代码,在完全垂直旋转内生成完整的CT投影集。
表1 .基于单视图x射线输入的渲染x射线投影的PSNR和SSIM的定量结果。

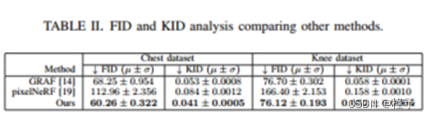
我们在2D渲染任务上评估我们的模型,并将其与pixelNeRF[19]和GRAF[14]基线进行比较,其中使用了原始架构。我们的模型可以更准确地估计体积深度GRAF和pixelNeRF(图4)。
















 9640
9640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









