







目录
1、DDR背景
DDR内存技术从最初的DDR SDRAM发展到DDR4,其背景是计算机处理能力的不断提升和对更快数据处理速度的需求。
(1)SDR SDRAM时代 :
在20世纪90年代,Intel推出了首款同步动态随机存储器SDR SDRAM。
SDR SDRAM采用时钟同步接口,典型时钟频率为66MHz或83MHz,使用2n预取技术。
(2)DDR SDRAM的创新 :
DDR SDRAM,即双倍数据率SDRAM,于2000年左右推出。
DDR技术通过在时钟的上升沿和下降沿都传输数据,使带宽在相同时钟频率下翻倍。
DDR沿用了2n预取技术,并降低了成本和功耗。
(3)DDR技术的演进 :
DDR1:作为最早的DDR技术版本,DDR1通过每个时钟周期进行两次数据传输来提高传输速率。
DDR2:于2003年推出,采用更高的时钟频率和更高的数据传输速率,引入了新的电压规范(1.8V),降低了功耗。
DDR3:于2007年推出,进一步提升了数据传输速率、时钟频率和内存容量,采用更高的时钟频率和更低的电压(1.5V)。
DDR4:于2014年推出,具有更高的数据传输速率、更高的时钟频率和更大的内存容量支持,采用了Low Power Memory Access(LPA)技术,降低了功耗并提高了内存访问效率。
(4)需求推动:
随着CPU和其他计算机组件性能的不断提升,对内存的性能要求也越来越高。用户对更快的数据处理速度、更大的内存容量和更低的功耗的需求不断增长。随着互联网、多媒体应用、大型数据库和高性能计算等对内存性能要求极高的应用的普及,内存技术需要不断进步以满足这些需求。DDR内存技术的演进反映了整个计算机行业对更高效率、更好性能和更优能效比的不懈追求。每一次技术的更新换代都旨在提供更快的数据传输速度和更高的系统性能,以满足日益增长的计算需求。
2、了解内存
DIMM(Dual In-line Memory Module)是一种内存模块,它代表了内存条的基本形态,用于连接到计算机主板上的内存插槽。以下是从专业角度对DIMM及其不同类型进行的整理和总结:
(1)DIMM的定义和历史:
- DIP (Dual In-line Package):在80286时代,内存颗粒以DIP封装形式直接插在主板上。
- SIMM (Single-Inline Memory Module):随着80386时代的到来,内存颗粒被焊接在电路板上,形成了SIMM,其位宽为32位,即每个周期可以读取4个字节。
- DIMM (Double-Inline Memory Module):随着奔腾处理器的推出,内存位宽增加到64位,即每个周期可以读取8个字节,SIMM因此演变为DIMM,这种形态至今仍被使用。
(2)DIMM的分类:
-
RDIMM (Registered DIMM):
- 用途:主要用于服务器领域。
- 特点:包含寄存器(Register),提供额外的地址和控制信号缓冲,以提高内存的容量和稳定性。
- ECC:大多数RDIMM配备错误校正码(ECC),以增强数据的安全性。
-
UDIMM (Unbuffered DIMM):
- 用途:通常用于标准台式电脑。
- 特点:没有寄存器,因此成本较低,但稳定性和容量可能不如RDIMM。
- ECC:UDIMM可以有无ECC版本,但大多数消费级产品通常不配备ECC。
-
SO-DIMM (Small Outline DIMM):
- 用途:专为笔记本电脑设计。
- 特点:尺寸较小,以适应笔记本电脑的紧凑空间。
- ECC:根据需求,SO-DIMM可以配备ECC。
-
Mini-DIMM:
- 用途:用于对体积有严格要求的高端领域,如刀片式服务器。
- 特点:是RDIMM的缩小版本,保持了RDIMM的高性能和稳定性,同时减小了尺寸。
不同类型的DIMM根据其用途和性能需求被设计出来,以满足从个人电脑到高端服务器等不同应用场景的需求。RDIMM因其稳定性和容量优势在服务器领域广泛使用,而UDIMM和SO-DIMM则更常见于消费级市场。Mini-DIMM则满足了特定高端应用对小尺寸和高性能的双重需求。
3、DDR介绍
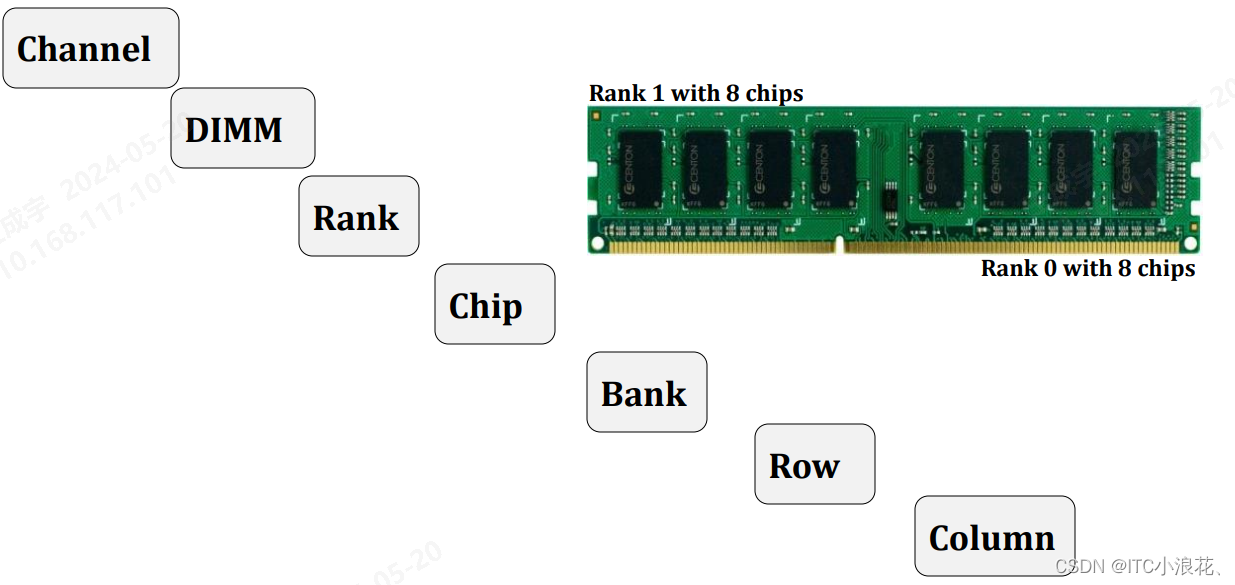
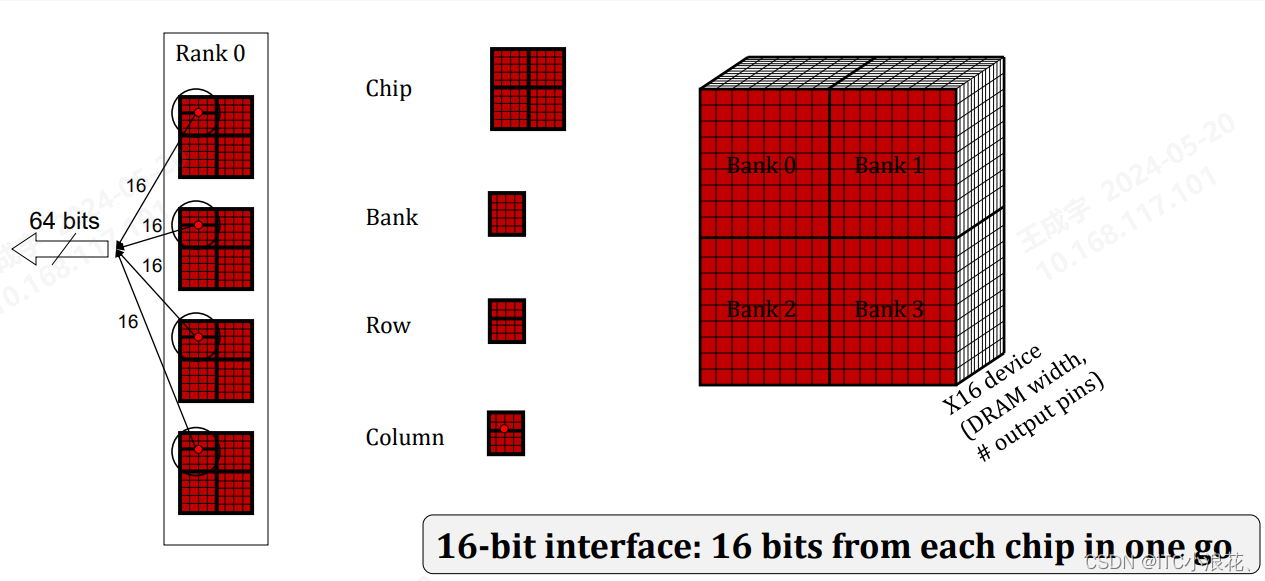
Channel:内存通道(Channel)是内存控制器与内存模块之间的通信路径。在多通道配置中,每个通道可以独立工作,从而提高内存的带宽和性能。
DIMM (Dual In-line Memory Module):DIMM是物理内存模块,即我们通常所说的内存条。一个DIMM可以包含一个或多个Rank。
Rank:Rank是一组共享相同地址和控制信号的内存芯片集合。在图片中,每个DIMM有两个Rank(Rank 0和Rank 1),每个Rank由8个芯片组成。
Chip:芯片(Chip)是构成Rank的基本单元,每个芯片拥有自己的存储容量和内部结构。
Bank:每个芯片可以进一步划分为多个Bank。Bank是内存中可以独立操作的存储区域,可以提高并行访问数据的能力。
Row and Column:在每个Bank内部,存储矩阵由行(Row)和列(Column)组成。数据的存取通过指定行和列来实现。
4、常见信号介绍
片选(Chip Select)信号:
S0# 和 S1# 是片选信号,它们用于选择特定的内存Rank。每个信号的状态决定了哪个Rank被选中进行数据访问。
Bank地址线(BANK ADDRESS):
BA0-BA2 是Bank地址线,总共有3位,可以表示2^3=8个不同的Bank。这些地址线用于在多个Bank中选择一个特定的Bank进行访问。
列选(Column Address Select)信号:
CAS# 是列选信号,当它为低电平时,表示列地址有效。这意味着此时在地址线A0-A13上传输的是列地址信息。
行选(Row Address Select)信号:
RAS# 是行选信号,当它为低电平时,表示行地址有效。此时,地址线A0-A13上传输的是行地址信息,用于定位特定的行。
地址线:
A0-A13 是地址线,它们用于传输行和列的地址信息。尽管这些地址线在物理上是共用的,但在不同的时间点上,它们分别表示行地址或列地址。
数据线:
DQ0-DQ63 是数据线,用于在内存和外部设备之间传输64位的数据。
命令线(COMMAND):
COMMAND线用于传输各种内存访问命令,如读、写等。这些命令决定了内存操作的具体类型和流程。
(1)内存访问流程
1、行有效阶段:
- RAS# 为低电平,CAS# 为高电平。
- 地址线A0-A13上传输行地址信息,以定位特定的行。
2、列有效阶段:
- RAS# 为高电平,CAS# 为低电平。
- 地址线A0-A13上传输列地址信息,与先前选定的行结合,以唯一确定一个内存单元(即“小方格”)。
- 数据读取或写入阶段:
- 根据COMMAND线上的命令,执行数据的读取或写入操作。
- 数据通过数据线DQ0-DQ63在内存和外部设备之间传输。
请注意,在这个系统中,没有专门的内存颗粒选择信号线。一旦Rank被选中,该Rank中的所有内存颗粒(在本例中为8个)将同时被选中,共同提供64位的数据带宽。
(2)时延(Latency)
在内存操作中,时延是一个关键参数,它决定了从发出命令到实际数据可用之间的时间间隔。以下是关于内存时延中几个重要参数的详细解释:
1、CAS Latency (CL):
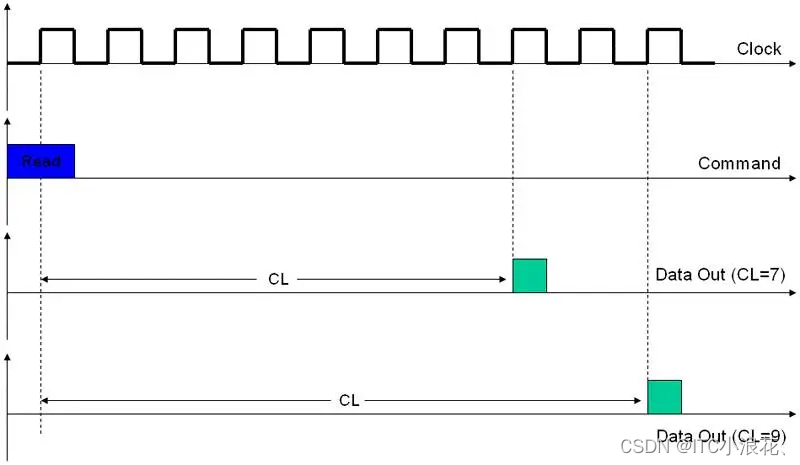
- CAS Latency,简称CL,指的是从CAS(Column Address Strobe,列地址选通)信号发出到第一笔数据实际被读取并输出的时间间隔。由于CL主要在读取操作中起作用,因此也被称为读取时延(RL, Read Latency)。
- CL是内存性能评估中的一个重要指标。例如,CL7的内存意味着在发出读取命令后,需要等待7个时钟周期才能获得数据,而CL9的内存则需要等待9个周期。由于DDR3内存的每个时钟周期实际传输两次数据(双倍数据传输率),因此真正的时钟频率需减半计算。
- 在相同频率的内存中,较低的CL值(如CL7)相较于较高的CL值(如CL9)可以带来显著的性能提升,有时甚至能高达22%。
2、tRCD (RAS to CAS Delay):
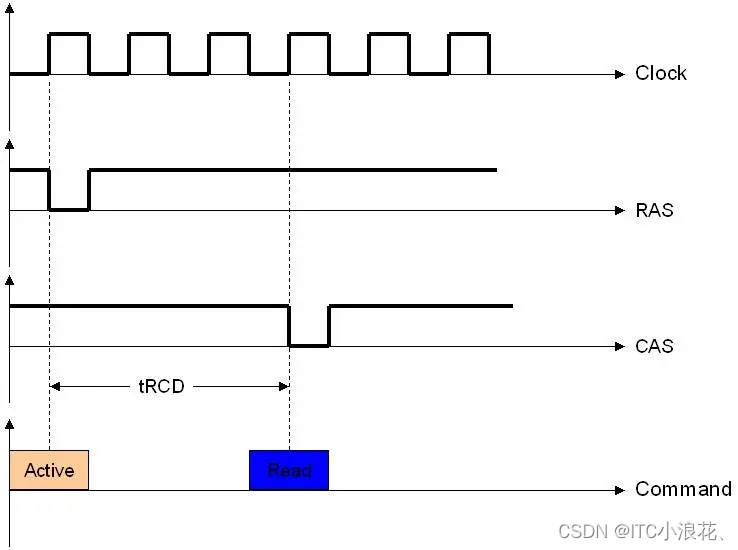
- tRCD代表从RAS(Row Address Strobe,行地址选通)命令激活到CAS命令发出之间的时间间隔。这是为了确保存储阵列中的电子元件有足够的时间响应并准备数据传输。
- 简而言之,tRCD是行地址激活与列地址读取之间的必要延迟。较短的tRCD值意味着更快的行到列的转换时间。
3、tRP (Precharge Command Period):
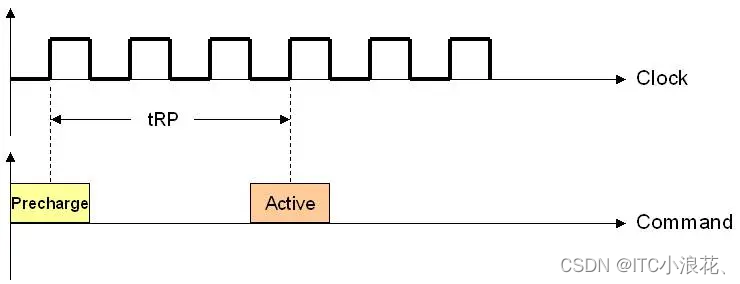
- tRP指的是在前一次数据传输完成后,到下一次行地址激活之前,内存模块进行预充电所需的时间。预充电是内存操作中的一个关键步骤,它重置了行地址并准备进行下一次的读取或写入操作。
- 较短的tRP值有助于减少内存访问的整体延迟,从而提高性能。
除了上述三个参数外,还有tRAS(Active to Precharge Delay)和CMD(Command Rate)等其他时延参数,它们共同构成了内存操作的整体时延。优化这些参数可以显著提升内存的性能和响应速度。然而,请注意,这些参数的设置通常需要基于特定的硬件和配置进行细致的调整。
5、读写操作
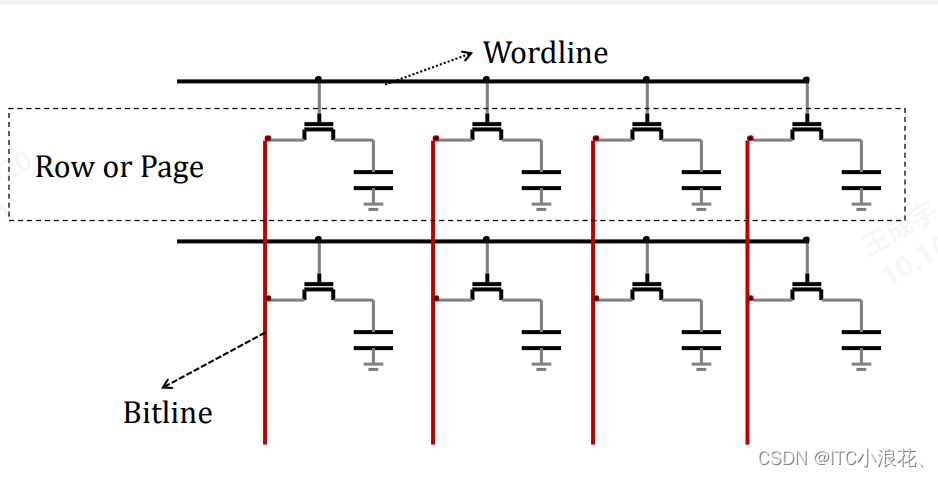
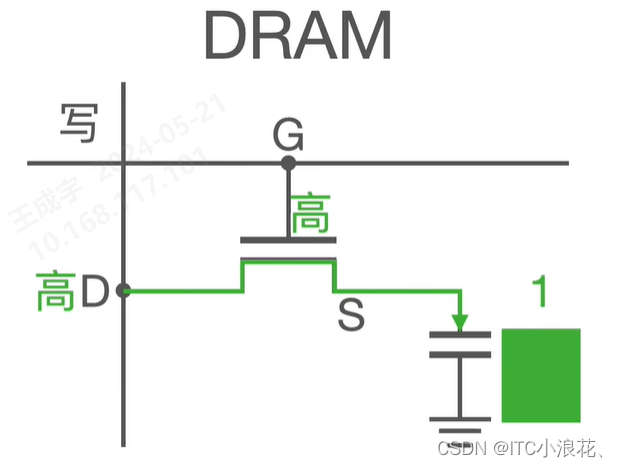
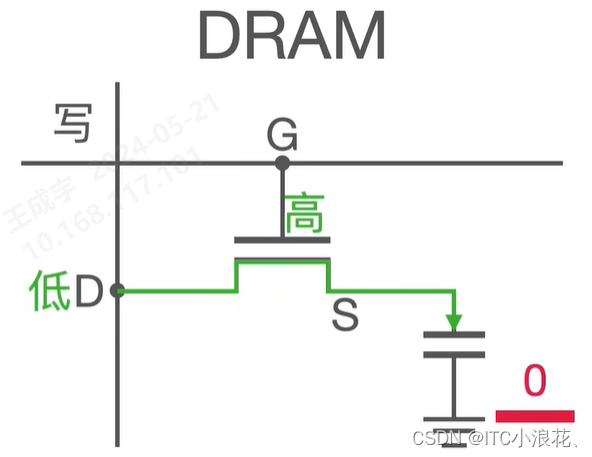
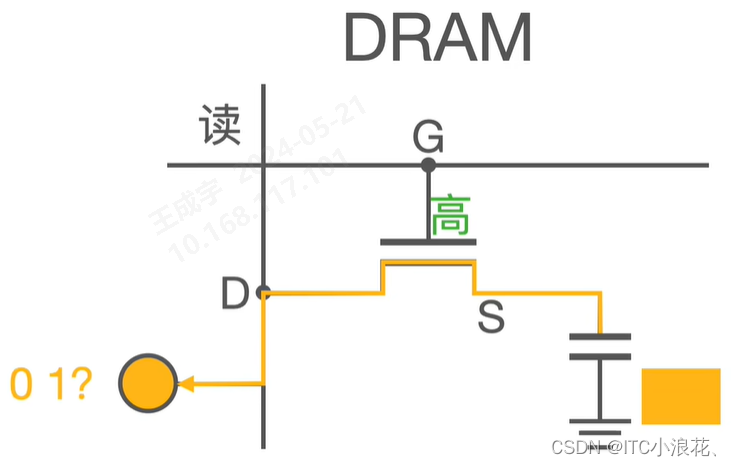
(1)读操作
一个完整的读操作包含了 Precharge 预充电、Access 访问、Sense 感知、Restore 恢复 四个阶段。
Precharge 预充电阶段
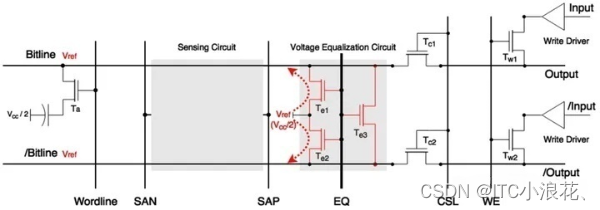
在这个阶段,通过激活EQ(Equalize)信号,使得连接到Bitline和/Bitline的晶体管Te1、Te2、Te3导通,从而将Bitline和/Bitline连接到一个共同的参考电压Vref(Vcc/2)。这个过程确保了在读取操作开始之前,Bitline和/Bitline上的电荷被释放,并且它们的电压被拉到一个新的参考电平Vref。
这个操作的结果是,无论Bitline和/Bitline在上一次操作后保持了什么样的电荷状态,它们现在都被拉到了一个中间电平,为即将到来的读取操作提供了一个稳定的起点。这种电压均衡是差分放大电路正确工作的前提,因为它允许差分放大器准确地检测存储单元电容与Bitline和/Bitline之间的微小电压差异,从而读取存储的数据。
想象一下你有一个天平,两边分别放着两个盘子,我们用这两个盘子来代表Bitline和/Bitline。在读取存储在电容中的信息之前,我们需要确保这两个盘子是平衡的,也就是说,它们都处于同一个水平线上。
在之前的读写操作中,可能已经在这两个盘子上放了不同重量的物品(代表不同的电压电平)。如果不进行Precharge(预充电或电压均衡),那么当这次我们要读取新的信息时,如果直接打开连接到存储电容的开关(Ta开关),那么由于两个盘子上的重量(电压电平)可能不同,它们就会相互影响,导致天平失去平衡。
具体来说,如果Bitline上的电压比/Bitline高,那么当Ta开关打开时,Bitline上的电荷可能会流向存储电容,试图将电容的电压拉高。但如果电容中存储的是相反的电压(比如电容中的电荷是负的),那么Bitline上的正电荷就会与电容中的负电荷中和,导致电容中的信息丢失。
因此,Precharge过程就像是在读取信息之前,先把两个盘子上的所有物品都移走,让它们回到同一个水平线上(Vref电平)。这样,当我们再次打开Ta开关读取信息时,两个盘子(Bitline和/Bitline)就都是从同一个平衡状态开始,不会相互干扰,从而确保了存储电容中的信息能够被正确读取,不会被错误地中和或冲刷掉。
Access 访问阶段
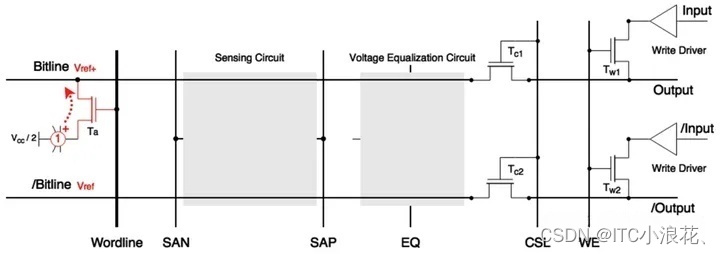
在这个阶段,Wordline信号被激活,使得特定的访问晶体管(Access Transistor,通常称为Ta)导通,从而将选定的存储单元的电容与相应的Bitline连接起来。如果存储单元电容中存储的是正电荷(代表逻辑1),那么这些电荷将开始流向Bitline,但由于Bitline的寄生电容远大于存储单元电容,Bitline的电压只会从预充电阶段设定的参考电压Vref上升到一个略高的水平,通常表示为Vref+。这个微小的电压变化是存储单元电容中电荷状态的直接反映,并且为接下来的感知(Sense)阶段提供了必要的条件,其中差分感知放大器将放大这个微小的电压差,以确定存储单元电容中存储的是逻辑1还是逻辑0。这个过程对于确保数据的准确读取和维持存储器的性能至关重要。
Sense 感知阶段
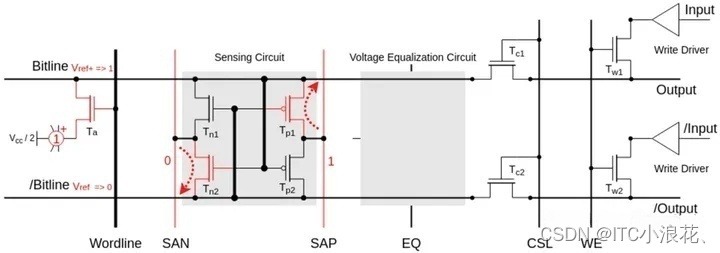
在DRAM的读取操作中,Access阶段之后,进入Sense感知阶段,此阶段的核心是差分感知放大电路(Differential Sense Amplifier)的工作。在Access阶段,由于访问晶体管Ta的导通,存储单元电容与Bitline之间的电荷转移导致Bitline电压上升至Vref+,而其互补路径/Bitline保持在Vref。这个微小的电压差是感知放大器工作的基础。
差分感知放大电路由两对互补的MOSFETs组成,即NMOS Tn2和PMOS Tp1,它们分别对应于Bitline和/Bitline。当Bitline电压略高于/Bitline时,NMOS Tn2的栅极-源极电压差足够使其形成微小的导电沟道,允许电荷从SAN(Sense-Amplifier N-Fet Control,逻辑0电压,即0V)流向/Bitline,从而进一步降低/Bitline的电压。相反,PMOS Tp1在/Bitline电压略低于Bitline时形成导电沟道,允许电荷从SAP(Sense-Amplifier P-Fet Control,逻辑1电压,即Vcc)流向Bitline,从而进一步增加Bitline的电压。
随着SAN和SAP的强电压作用,Tn2和Tp1的导电沟道迅速扩大,导致/Bitline和Bitline的电压分别向逻辑0和逻辑1电平放大。这个过程是正反馈的,因为随着电压差的增加,沟道的导电性增强,进一步增加电压差。最终,Bitline和/Bitline的电压差被放大到一个可以被电路清晰识别的水平,即逻辑1或逻辑0。
在这一过程中,另外两个MOSFETs,即Tp2和Tn1,保持在截止状态,它们是感知放大器的负载设备,用于在感知放大过程结束后维持Bitline和/Bitline的状态。
差分感知放大电路的工作原理是利用MOSFET的开关特性和正反馈机制,而不是直接放大存储电容中的电荷。这种设计使得DRAM能够在读取操作中快速且准确地检测和放大存储单元电容的微小电荷变化,从而可靠地恢复存储的信息。
想象一下,你有两个水槽,一个叫Bitline,另一个叫/Bitline,它们开始时都被灌满了半水槽的水,水的高度代表电压,都是Vref。现在,我们通过一个小管子(访问晶体管Ta)从一个小水库(存储单元电容)向Bitline水槽中加水,使得Bitline水槽的水位稍微上升了一点,变成了Vref+。而/Bitline水槽的水位保持不变。
接下来,我们有两个帮手,一个叫Tn2,另一个叫Tp1,它们分别站在Bitline和/Bitline水槽旁边。Tn2手里拿着一个水管,水管的另一头连接着一个水源(SAN,逻辑0电压,0V)。Tp1手里也拿着一个水管,连接着另一个水源(SAP,逻辑1电压,Vcc)。
当Bitline水槽的水位比/Bitline高一点点时,Tn2就开始工作,打开水管,让0V的水流向/Bitline水槽,使得/Bitline的水迅速下降到0V。同时,Tp1看到/Bitline的水槽水位下降,也开始工作,打开水管,让Vcc的水流向Bitline水槽,使得Bitline的水迅速上升到Vcc。
这个过程就像是两个帮手在比赛,谁先把对方水槽的水放完或者加满。因为Bitline和/Bitline开始时只差一点点水位,所以这个比赛会迅速决出胜负。最终,一个水槽的水被放光(逻辑0),另一个水槽的水被加满(逻辑1)。
在这个过程中,还有两个帮手Tp2和Tn1,它们暂时没有工作,只是在旁边待命,准备在比赛结束后,帮助维持水槽的水位状态。
通过这个比喻,我们可以理解Sense感知阶段的核心原理:通过差分放大的方式,利用微小的电压差来快速准确地放大信号,从而确定存储单元电容中存储的是逻辑1还是逻辑0。这个过程是自动化的,一旦开始,就会迅速且准确地完成,确保我们能够读取DRAM中存储的信息。
Restore 恢复阶段
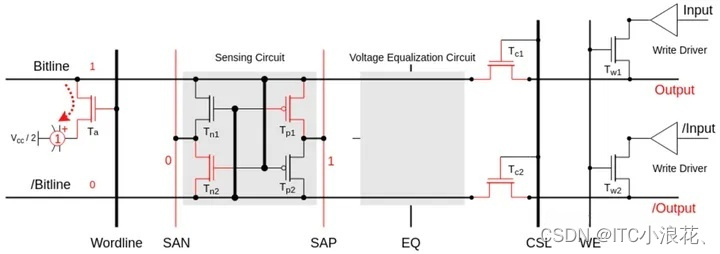
在完成 Sense 阶段的操作后,Bitline 线处于稳定的逻辑 1 电平 Vcc,此时 Bitline 会对电容器进行充电。经过特定的时间后,电容器中的电荷就可以恢复到读取操作前的状态。
最后,通过 CSL 信号,让 Tc1 和 Tc2 进入导通状态,多路复用的 Read Latch 电路(未画出) 就可以从 Bitline 差分线上从容地读取信息,并锁存起来。
(2)写操作
DRAM的写入操作在前期与读取操作相似,包括Precharge、Access、Sense和Restore阶段。在Restore阶段之后,写入操作进入Write Recovery阶段。在Write Recovery阶段,通过激活WE(Write Enable)信号,特定的写入晶体管Tw1和Tw2被导通。此时,Bitline被输入信号input拉至逻辑0电平,而其互补路径/Bitline则被输入信号的反相/input拉至逻辑1电平。经过一定时间后,存储电容中的电荷被完全放电,达到0状态。随后,通过控制Wordline信号,关闭连接存储电容的MOS晶体管,完成写入0的操作。这个过程确保了存储电容被正确地更新为所需的逻辑状态,无论是0还是1,从而完成了数据的写入。



















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











