







目录
1.1、可视化数据(Visualizing the data)
1.2、逻辑函数(Logistic function or sigmoid function)
1.3、代价函数和梯度(Cost function and gradient)
2.1、可视化数据(Visualizing the data)
2.2、代价函数和梯度(Cost function and gradient)
作业结构

这次的作业全都是必做的,下面我会使用MATLAB来完成该作业。
代码已上传至github,需要自取:代码地址
一、逻辑回归(Logistic Regression)
在这个例子中,我们有一个逻辑回归的模型,要根据一个学生的两门成绩来判断一个学生是否会被录取。
1.1、可视化数据(Visualizing the data)
首先导入ex2data1.txt中的数据,该数据第一行和第二行是学生的两门成绩,第三行是学生是否被录取(0或1),所以输入X矩阵为数据集中第一行和第二行的数据,输出y矩阵为第三行的数据。
data = load('ex2data1.txt');
X = data(:, [1, 2]); y = data(:, 3);然后再来可视化这些数据,pos用来存放输出y为1的数据的下标,neg用来存放输出y为0的数据的下标,X(pos, 1)即被录取的学生的第一门成绩,X(pos, 2)即被录取的学生的第二门成绩。
figure;
hold on;
pos = find(y==1); neg = find(y == 0);
% Plot Examples
plot(X(pos, 1), X(pos, 2), 'k+','LineWidth', 2, 'MarkerSize', 7);
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y', 'MarkerSize', 7);
xlabel('Exam 1 score')
ylabel('Exam 2 score')
legend('Admitted', 'Not admitted')
hold off;注:
- find(y==1)函数返回的是y矩阵中数值为1的数据的下标(按先从上往下,再从左往右的顺序数)
- hold on和hold off是为了不让后面未被录取(y==0)的学生打印的数据覆盖前面被录取(y==1)的学生打印的数据
然后执行代码,打印图像:

1.2、逻辑函数(Logistic function or sigmoid function)
首先看一下逻辑回归中的假设函数定义:
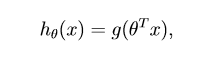
其中函数g就是逻辑函数,其定义为:
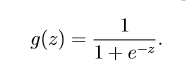
接下来完成逻辑函数在matlab中的实现(z可能为矩阵、向量或者数值):
function g = sigmoid(z)
g = zeros(size(z)); %初始化
len = size(z); %矩阵z的行数和列数
for i = 1 : len(1)
for j = 1 : len(2)
g(i,j) = 1 / (1 + exp(-z(i,j))) %计算
end
end
end
1.3、代价函数和梯度(Cost function and gradient)
下面我们要计算逻辑回归中的代价函数梯度,先回顾一下逻辑回归中的代价函数形式:

其对θ的偏导为:

然后再来实现这个函数,函数要求返回代价函数的计算结果和梯度:
function [J, grad] = costFunction(theta, X, y)
m = length(y); % number of training examples
J = 0;
grad = zeros(size(theta));
J = sum(-y .* log(sigmoid(X * theta)) - (1 - y) .* log(1 - sigmoid(X * theta))) / m; %计算代价函数
temp = ((sigmoid(X * theta) - y) .* X) / m; %临时数组存放计算结果
len = size(theta);
for i = 1 : len(1)
grad(i) = sum(temp(:,i)); %求和得到梯度
end
end执行ex2.m中的第二个模块可以得到如下结果:

1.4、高级优化算法
可以直接调用matlab中的fminunc函数来实现该算法,这样我们就不需要手动些一些循环了。该算法已经在文档中写好,可以直接拿来用:
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 400);
% Run fminunc to obtain the optimal theta % This function will return theta and the cost
[theta, cost] = fminunc(@(t)(costFunction(t, X, y)), initial theta, options);
注:options是为了设置一些选项,将GradObj设置为on代表告诉fminunc函数我们的costFunction能返回代价函数的计算结果和梯度;MaxIter设置为400代表该算法至多运算400次
最后的运行结果为:


中间那条直线即为我们的决策边界(DecisionBoundary)。
1.5、逻辑回归的预测
对于这个例子,如果有新的样例,我们要能正确预测输出,其输出为为0(未录取)或1(被录取)两种可能,但是我们上面得到的假设函数h(x)只能得到其被录取的概率,所以我们还需要做一些工作,使其输出为0或1。
我们可以设置一个门限,使当h(x) ≥ 0.5时,我们可以预测y=1,当h(x)﹤0.5时,我们可以预测y=0
二、正则化的逻辑回归
在第二部分中我们会使用另外一个例子,从两个测试的结果判断一个芯片是否合格。
2.1、可视化数据(Visualizing the data)
首先,和上面一样,我们可以利用之前写的代码把给定的数据集可视化一下,方便我们后续的学习:

可以明显看到,这次的数据集无法只用一条直线来划分,我们需要使用更复杂的决策边界来划分数据集,但这也加大了过拟合的可能性,所以我们引入了正则化的方法。
2.2、代价函数和梯度(Cost function and gradient)
先回顾一下正则化后的代价函数,就是在原来的基础上加上一个项:

其偏导为


注:由于我们不想对第0项做正则化,所以把第0项和其他项分开求。
代码和之前写的差不多,只是要在后面加上额外的一项:
function [J, grad] = costFunctionReg(theta, X, y, lambda)
m = length(y); % number of training examples
J = 0;
grad = zeros(size(theta));
theta_s = [0;theta(2:end)]; %因为不需要对第一个参数正则化,所以第一项为0
J = sum(-y .* log(sigmoid(X * theta)) - (1 - y) .* log(1 - sigmoid(X * theta)))/ m + (lambda / (2*m)) * sum(theta_s.^2); %计算代价函数
temp = ((sigmoid(X * theta) - y) .* X) / m; %临时数组存放计算结果
len = size(theta);
for i = 1 : len(1)
grad(i) = sum(temp(:,i)); %求和得到梯度
end
grad = grad + (lambda / m) * theta_s;
end运行正则化后的梯度下降算法可以得到我们的参数,从而可以得到我们的决策边界,我们可视化看一下得到的决策边界:

当我们设置λ = 0时候,即没有正则化,发现出现了过拟合的情况:

当我们设置λ = 100时候,即使正则化的权重过大,发现出现了欠拟合的情况:

所以可知合适的逻辑参数的选择也是非常重要的。
最后submit一下作业的结果:

可以看到满分通过,作业结束!















 7699
7699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









