







目录
文章目录
RISC-V处理器的设计与实现(一)—— 基本指令集_Patarw_Li的博客-CSDN博客
RISC-V处理器的设计与实现(二)—— CPU框架设计_Patarw_Li的博客-CSDN博客
RISC-V处理器的设计与实现(三)—— 上板验证_Patarw_Li的博客-CSDN博客
RISC-V处理器设计(四)—— Verilog 代码设计-CSDN博客
RISC-V处理器设计(五)—— 在 RISC-V 处理器上运行 C 程序-CSDN博客
一、前言
前面我们使用 verilog 完成了一个 risc-v cpu 的设计,但 cpu 最终也是为了程序服务的,不能执行程序的 cpu 没有任何意义。所以这一节我们要研究如何在自己设计的 cpu 上运行 C 程序。项目仓库如下:
risc-v-cpu: 一个基于 RISC-V 指令集的 CPU 实现(成功移植到野火征途 PRO 开发板),以及从零开始写一个基于 RISC-V 的 RT-Thread~ - Gitee.com
本节涉及到的代码都在仓库的 rt-thread 目录下。
二、从 C 程序到机器指令
当然,cpu 肯定不能直接执行 C 程序,cpu 只能识别机器语言,机器语言就是由 0 和 1 组成的一条二进制序列,比如 ADD 指令有如下格式:

在确定 rs1、rs2、rd 三个寄存器后,就能确定 ADD 指令的二进制序列,cpu 能够识别并执行这个二进制序列。 risc-v 指令集相关内容可以看我的这篇文章:
RISC-V处理器的设计与实现(一)—— 基本指令集_risc_v-CSDN博客
那么我们如何从 C 程序得到我们想要的机器指令呢?答案就是使用编译器,编译分为如下四个阶段(程序从编译到运行-CSDN博客):
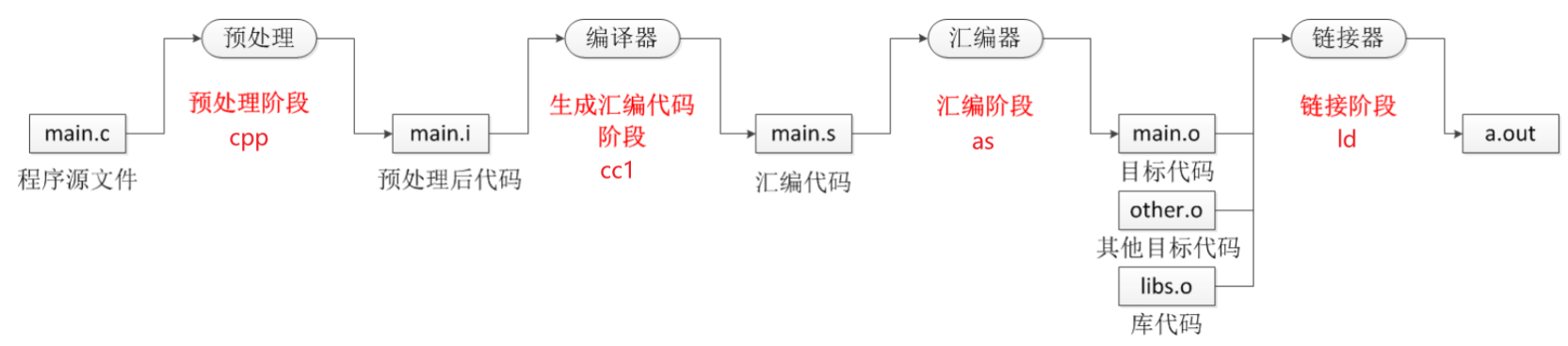
即预处理阶段、生成汇编代码阶段、汇编阶段、链接阶段,你可能会问为什么图里面的编译器只参与了一个阶段的工作,这是因为现在的编译工具功能非常强大,比如 linux 下的 gcc,我们只需要一行指令就能帮我们完成四个阶段的操作:
gcc hello.c最终生成的 a.out 即为操作系统(如 Linux、Ubuntu)上的可执行程序,此时的 a.out 虽然能在 像 Linux 这种操作系统上运行,但是 cpu 并不能直接识别并运行,编译生成的 a.out 大多是 ELF 格式。
ELF 格式的可执行文件包含了很多 cpu 不能识别的信息,但像 Linux 这样的操作系统可以识别这些信息,比如判断该可执行文件可以在哪种架构上运行,该可执行文件的各个段的位置在哪等等。关于 ELF 文件的解析可以看如下博客:
为了得到 cpu 能直接识别的内容,我们可以通过 objcopy 指令将生成的 a.out 转变为去掉了这些无用信息的 hello.bin 文件,具体怎么操作可以看我的这篇博客:
开发一个RISC-V上的操作系统(一)—— 环境搭建_riscv操作系统开发_Patarw_Li的博客-CSDN博客
同时,如果要编译出我们 risc-v 架构的 cpu 能识别的机器指令,我们还需要选择对应的交叉编译器,如 Ubuntu 20.04 下可以使用官方提供的 riscv64-unknown-elf-gcc。如果你使用的是 x86 下的gcc,那么编译出来的机器指令则只能由 x86 架构的 cpu 识别。
三、实验
实验的目录在本仓库的 rt-thread 目录下,该目录下新增了一个 demo 目录,可供用户自己设计 C 程序到本 cpu 上运行。其他的 experiment 目录都是和 rt-thread 移植相关的,后续也会更新相应的文章。
3.1 实验环境
下面是两种平台下的编译环境搭建,大家可以根据自己的情况自行选择。
3.11 Windows 平台下环境搭建
- GNU 工具链(链接:https://pan.baidu.com/s/1Bdmn-FH0T7ekm2kMxkzJTw?pwd=qn69 提取码:qn69),百度云下载解压后,将 bin 目录添加到环境变量里即可。
- make 工具(链接:https://pan.baidu.com/s/1X-F1BVPMa3-B-V1EHB4tEQ?pwd=418d 提取码:418d),百度云下载解压后,将 bin 目录添加到环境变量里即可。
- Python 3.7
3.12 Ubuntu 平台下环境搭建
Ubuntu 版本:
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.2 LTS
Release: 20.04
Codename: focal
$ uname -r
5.15.0-76-generic安装Ubuntu 20.04官方提供的 GNU工具链:
sudo apt update
sudo apt install build-essential gcc make perl dkms git gcc-riscv64-unknown-elf并且要将 Makefile 里面的 include ../common.mk 修改为 include ../common_ubuntu.mk。
3.13 实验涉及到的代码或目录
- include:公共头文件目录;
- lib:公共函数目录;
- start.S:启动文件;
- link.lds:链接脚本;
- common.mk:Makefile 的公共部分(Windows 平台下);
- common_ubuntu.mk:Makefile 的公共部分(Ubuntu 平台下);
- demo:用户可以在本目录下编写能在本 CPU 上运行的 C 程序;
3.2 各文件作用介绍
3.2.1 link.lds
link.lds 被称为链接脚本,是编译器链接步骤的重要部分。 官方文档
链接操作都是由链接脚本(Linker Script)所控制的,按照官方的话来说,链接脚本用来描述 input file(比如 hello.c 和 printf.c,编译器会将他们分别编译成 hello.o 和 printf.o,这两个文件就是链接操作的输入)中的每个 section 应该如何被映射到 output file(最终生成的可执行文件)中,并且控制 output file 中的内存布局。
我们可以自己编写链接脚本,也可以使用默认的链接脚本,如果要使用自己编写的链接脚本,则需要在编译时使用 -T 参数来指定。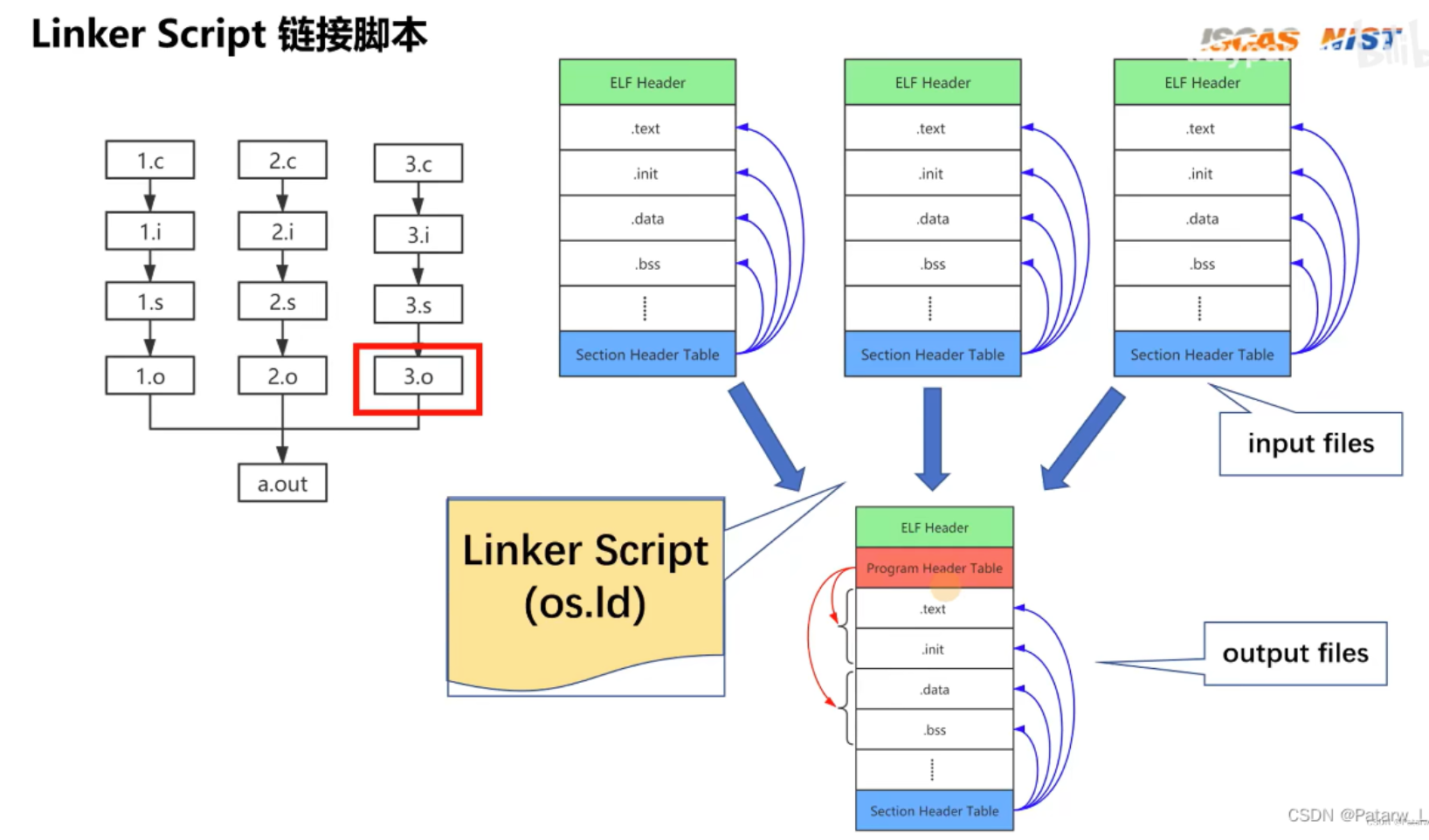
关于链接脚本的语法大家可以自行查阅资料,这里我只介绍对于本次实验比较重要的部分:
1. ENTRY 来确定程序的入口为 _start,该符号在 start.S 中声明:
ENTRY(_start)2. MEMORY 部分,这部分是根据 soc 上的 flash 和 ram 在总线上的起始地址以及所支持的空间大小来配置的。比如本 cpu 的 rom 起始地址为 0x00000000,大小为 16KB:
MEMORY
{
flash (rxai!w) : ORIGIN = 0x00000000, LENGTH = 16K
ram (wxa!ri) : ORIGIN = 0x10000000, LENGTH = 8K
}3. 定义程序栈大小,如果其他地方没有 __stack_size 的定义就把栈大小定义为 2KB:
__stack_size = DEFINED(__stack_size) ? __stack_size : 2K;4. 有些段是可读可写的,比如 .data 段,这些段是不能放到 flash 上的(flash 只读),所以我们在链接脚本中会把 .data 段指定到 ram 上存储(使用 >ram):
.lalign :
{
. = ALIGN(4);
PROVIDE( _data_lma = . );
} >flash AT>flash
.dalign :
{
. = ALIGN(4);
PROVIDE( _data = . );
} >ram AT>flash
.data :
{
*(.rdata)
*(.gnu.linkonce.r.*)
*(.data .data.*)
*(.gnu.linkonce.d.*)
. = ALIGN(8);
PROVIDE( __global_pointer$ = . + 0x800);
*(.sdata .sdata.*)
*(.gnu.linkonce.s.*)
. = ALIGN(8);
*(.srodata.cst16)
*(.srodata.cst8)
*(.srodata.cst4)
*(.srodata.cst2)
*(.srodata .srodata.*)
} >ram AT>flash
. = ALIGN(4);
PROVIDE( _edata = . );
PROVIDE( edata = . );但这样会导致生成的二进制文件中间产生很大的空洞,因为 flash 和 ram 的地址一般是不同的,所以我们需要使用 AT>(关于 AT> 的作用可以看这篇博客https://www.cnblogs.com/LogicBai/p/16982841.html),这样可以把 .data 段先放到 flash 中,然后在启动文件 start.S 中通过 _data_lma、_data、_edata(分别对应 .data 段在 flash 中的实际地址、在 ram 上的逻辑起始地址、在 ram 上的逻辑末尾地址)这三个地址来把 .data 段从 flash 上搬运到 ram 上,这样就可以将数据存储的位置和运行的位置区分开来。
5. 因为 .bss 段的数据都为 0,所以无需占用存储空间,只需要保存 .bss 段的运行时的逻辑起始地址和末地址(__bss_start 和 _end),然后在启动时使用 start.S 将起始地址到末地址中间的内容初始化为 0 即可:
PROVIDE( __bss_start = . );
.bss :
{
*(.sbss*)
*(.gnu.linkonce.sb.*)
*(.bss .bss.*)
*(.gnu.linkonce.b.*)
*(COMMON)
. = ALIGN(4);
} >ram AT>ram
. = ALIGN(8);
PROVIDE( _end = . );3.2.2 start.S
启动文件 start.S 作为 cpu 上电复位后第一个执行的程序,主要完成以下工作:
- 初始化 gp (global pointer) 全局指针寄存器、sp (stack pointer) 栈指针寄存器;
- 将 .data 段的数据从 flash 中加载至 RAM 中;
- 清空 bss 段数据;
- 进入 main 函数运行;
start.S 的代码如下:
.section .init;
.globl _start;
.type _start, @function
_start:
.option push
.option norelax
la gp, __global_pointer$
.option pop
la sp, _sp
/* 把 data section 从 flash 搬运到 ram 中 */
la a0, _data_lma
la a1, _data
la a2, _edata
bgeu a1, a2, 2f
1:
lw t0, (a0) /* 从 flash 中取出一个 word 的数据 */
sw t0, (a1) /* 将取出的数据存入 ram 中对应位置 */
addi a0, a0, 4
addi a1, a1, 4
bltu a1, a2, 1b
2:
/* 将 bss section 初始化为 0 */
la a0, __bss_start
la a1, _end
bgeu a0, a1, 2f
1:
sw zero, (a0)
addi a0, a0, 4
bltu a0, a1, 1b
2:
/* 调用初始化函数 */
call _init
/* 跳转到 main */
call main
/* never came here */
loop:
j loop第 8 行, 加载全局指针寄存器 gp。
第 10 行,加载栈指针寄存器 sp。
第 13 ~ 22 行,把 .data 段从 flash 搬运到 ram 中。
第 25 ~ 31 行,将 .bss 段初始化为 0。
第 35 行,调用初始化函数,定义在 init.c 中。
第 37 行,调用 main 函数,执行用户编写的程序。
第 40、41 行,为了防止执行用户程序后,cpu 跑飞的情况,最后写了一个死循环。
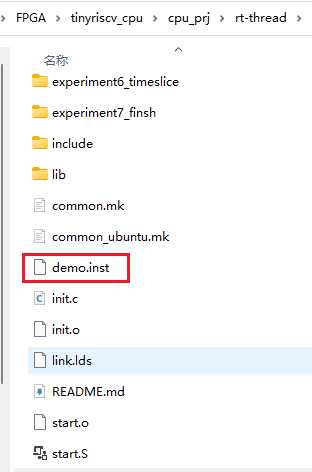
3.2.3 lib 和 include 目录
这两个目录主要提供一些公共的函数,比如串口、printf 函数等,用户可以在 main.c 文件里面包含头文件后使用里面定义的函数。
3.2.4 common.mk
该文件为 Makefile 编译脚本的公共部分,所有 Makefile 文件(比如 demo 里面的 Makefile)都会包含 common.mk。
common.mk 的内容如下:
CROSS_COMPILE = riscv-none-embed-
RISCV_GCC := $(CROSS_COMPILE)gcc
RISCV_AS := $(CROSS_COMPILE)as
RISCV_GXX := $(CROSS_COMPILE)g++
RISCV_OBJDUMP := $(CROSS_COMPILE)objdump
RISCV_GDB := $(CROSS_COMPILE)gdb
RISCV_AR := $(CROSS_COMPILE)ar
RISCV_OBJCOPY := $(CROSS_COMPILE)objcopy
RISCV_READELF := $(CROSS_COMPILE)readelf
.PHONY: all
all: $(TARGET)
ASM_SRCS += $(COMMON_DIR)/start.S
C_SRCS += $(COMMON_DIR)/init.c
C_SRCS += $(COMMON_DIR)/lib/uart.c
C_SRCS += $(COMMON_DIR)/lib/printf.c
C_SRCS += $(COMMON_DIR)/lib/hw_timer.c
LINKER_SCRIPT := $(COMMON_DIR)/link.lds
INCLUDES += -I$(COMMON_DIR)
LDFLAGS += -T $(LINKER_SCRIPT) -nostartfiles -Wl,--gc-sections -Wl,--check-sections
ASM_OBJS := $(ASM_SRCS:.S=.o)
C_OBJS := $(C_SRCS:.c=.o)
LINK_OBJS += $(ASM_OBJS) $(C_OBJS)
LINK_DEPS += $(LINKER_SCRIPT)
CLEAN_OBJS += $(TARGET) $(LINK_OBJS) $(TARGET).dump $(TARGET).bin ../$(TARGET).inst
CFLAGS += -march=$(RISCV_ARCH)
CFLAGS += -mabi=$(RISCV_ABI)
CFLAGS += -mcmodel=$(RISCV_MCMODEL) -nostdlib -ffunction-sections -fdata-sections -fno-builtin-printf -fno-builtin-malloc -Wall
$(TARGET): $(LINK_OBJS) $(LINK_DEPS) Makefile
$(RISCV_GCC) $(CFLAGS) $(INCLUDES) $(LINK_OBJS) -o $@ $(LDFLAGS)
$(RISCV_OBJCOPY) -O binary $@ $@.bin
$(RISCV_OBJDUMP) --disassemble-all $@ > $@.dump
python ../../tools/bin_to_mem.py $@.bin ../$@.inst
$(ASM_OBJS): %.o: %.S
$(RISCV_GCC) $(CFLAGS) $(INCLUDES) -c -o $@ $<
$(C_OBJS): %.o: %.c
$(RISCV_GCC) $(CFLAGS) $(INCLUDES) -c -o $@ $<
.PHONY: clean
clean:
rm -f $(CLEAN_OBJS)第 1 ~ 10 行,配置工具链。
第 15 ~ 20 行,指定需要编译的公共汇编文件和 C 文件。
第 23 行,配置链接脚本的路径。
第 25 行,指定公共头文件目录。
第 27 行,指定链接参数
- -nostartfiles:指定链接时不要使用标准的系统启动文件,自定义入口函数(_start)时必须使用 -nostartfiles 选项进行链接。
- -Wl,--gc-sections:在链接生成最终可执行文件时,如果带有
-Wl,--gc-sections参数,并且之前编译目标文件时带有-ffunction-sections、-fdata-sections参数,则链接器ld不会链接未使用的函数,从而减小可执行文件大小。 - --check-sections:检查段地址是否重叠 (默认)。
3.2.5 demo 目录
此目录下包含了 main.c 文件和 Makefile,在此目录下执行 make 命令即可生成 demo.bin 和 demo.inst 文件,下面上板测试会用到这两个文件。
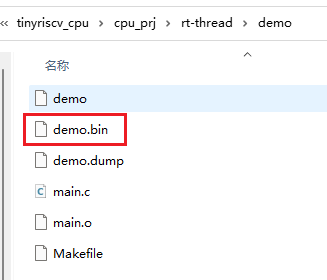
main.c 文件的内容是一个简单的加法,然后输出加法的结果,用户可以改成自己的 C 程序:
/* 头文件声明 */
#include "../include/printf.h"
#include "../include/uart.h"
/* main 函数 */
int main(void)
{
int a = 1;
int b = 2;
int c = a + b;
printf("The result of c: %d\n", c);
/* stop here */
while(1){};
}3.3 上板测试
有两种将编译好的二进制程序在本 CPU 上执行的方法。
第一种:直接作为 FPGA 比特流的一部分下载到板子上。
将 FPGA/rtl/perips/rom.v 文件里面的如下部分的注释打开,并且将路径改为生成的指令文件 demo.inst 的路径:

重新编译后,直接烧录到板子上即可:

使用串口工具连接板子,配置好串口号和波特率并打开串口后,按下板子上的复位键即可看到输出:
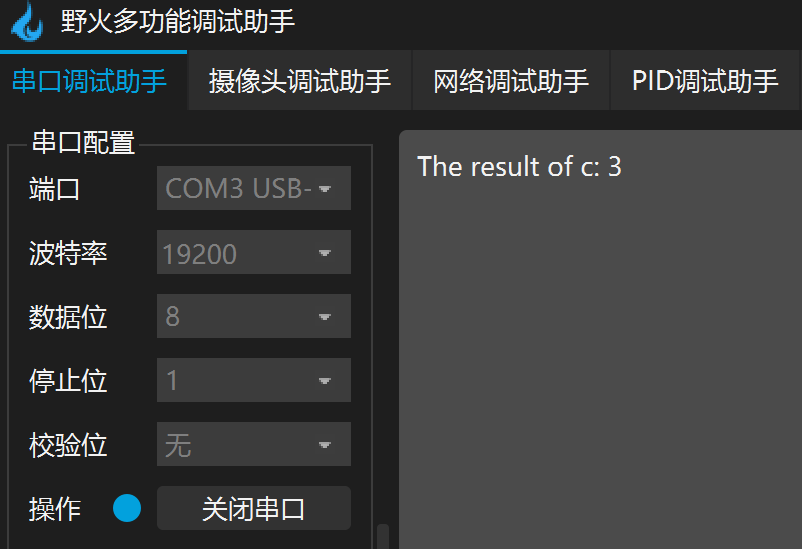
第二种:使用串口烧录程序。
将 demo.bin 二进制文件复制到 serial_utils/binary 目录下,然后进入 serial_utils 目录,先按住 key1 不动:

然后使用命令行执行如下命令烧录 demo.bin 文件,烧录完成即可松开 key1:
# 这里的 COM 号要根据你自己的来选,我这里是 COM3
python .\serial_send.py COM3 .\binary\demo.bin
使用串口工具连接板子,配置好串口号和波特率并打开串口后,按下板子上的复位键即可看到输出:
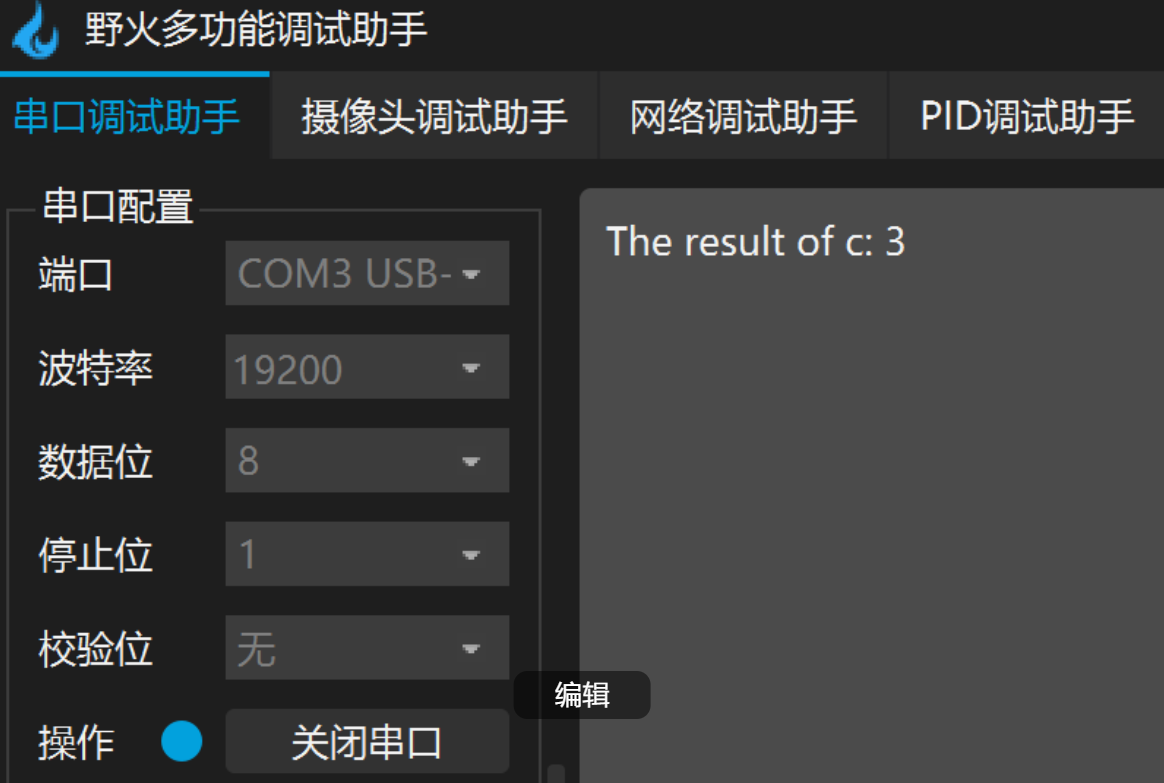
两种方法相比,第一种方法更为稳妥,第二种方法更为灵活,这里更建议大家使用第一种方法,在程序出问题的时候,第一种方法还可以使用 modelsim 仿真调试。
第二种方法目前还不太稳定,如果遇到第二种方法烧录失败可以多烧录几次(可能因为接触不良),或者尝试一下第一种方法。
四、写在最后
至此,如何在本项目的 CPU 上运行 C 程序已经介绍完了,既然能运行 C 程序,那么运行一个实时操作系统应该也是没问题的,这也对应了本项目的 rt-thread 实验,大家感兴趣的话可以继续学习本仓库,后续也会出相应的文章!
如果遇到问题也欢迎加群 892873718 交流~

















 6462
6462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









