







1. 集成学习
1.1 集成学习的概念
集成学习(Ensemble learning)就是将若干个弱分类器通过一定的策略组合之后产生一个强分类器。 弱分类器(Weak Classifier)指的就是那些分类准确率只比随机猜测略好一点的分类器,而强分类器( Strong Classifier)的分类准确率会高很多。这里的"强"&"弱"是相对的。弱分类器又被称 为“基分类器”。
通俗来讲就是三个臭皮匠 胜过诸葛亮,构建若干个模型,再将这些模型组合就是集成学习需要做的事。
1.2 bagging
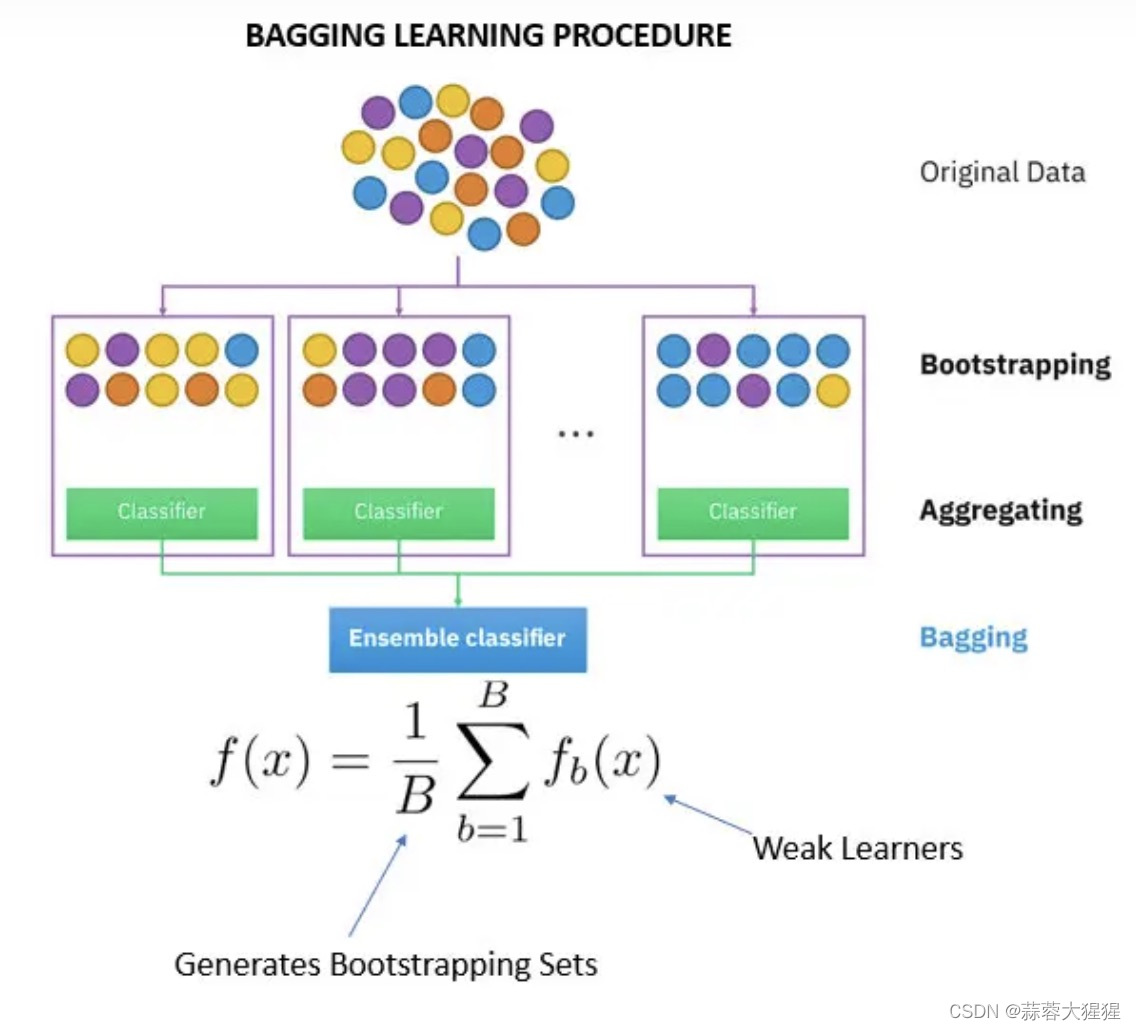
是一种根据均匀概率分布从数据集中重复抽样的技术。每个新数据集大小相等。由于新数据集中的每个样本都是从 原始数据集中有放回的随机抽样出来的,所以新数据集中可能有重复的值,而原始数据集中的某些样本可能根本就没出现在新数据集中。
比方高中数学所学概率论,抽小球再放回,假设抽了10次,那么这10个球作为一个训练样本参与模型的构建。不断重复以上过程,最后得到n个训练样本,n个训练样本得到n个模型,这些模型我们就称之为“弱分类器”;
使用这些模型时,我们将n个训练样本投喂我们的测试样本,然后根据每个弱分类器返回的结果,我们可以采用一定的组合策略得到我们最后需要的强分类器。
其中的代表算法就是我们老生常谈的随机森林了。
1.3 boosting
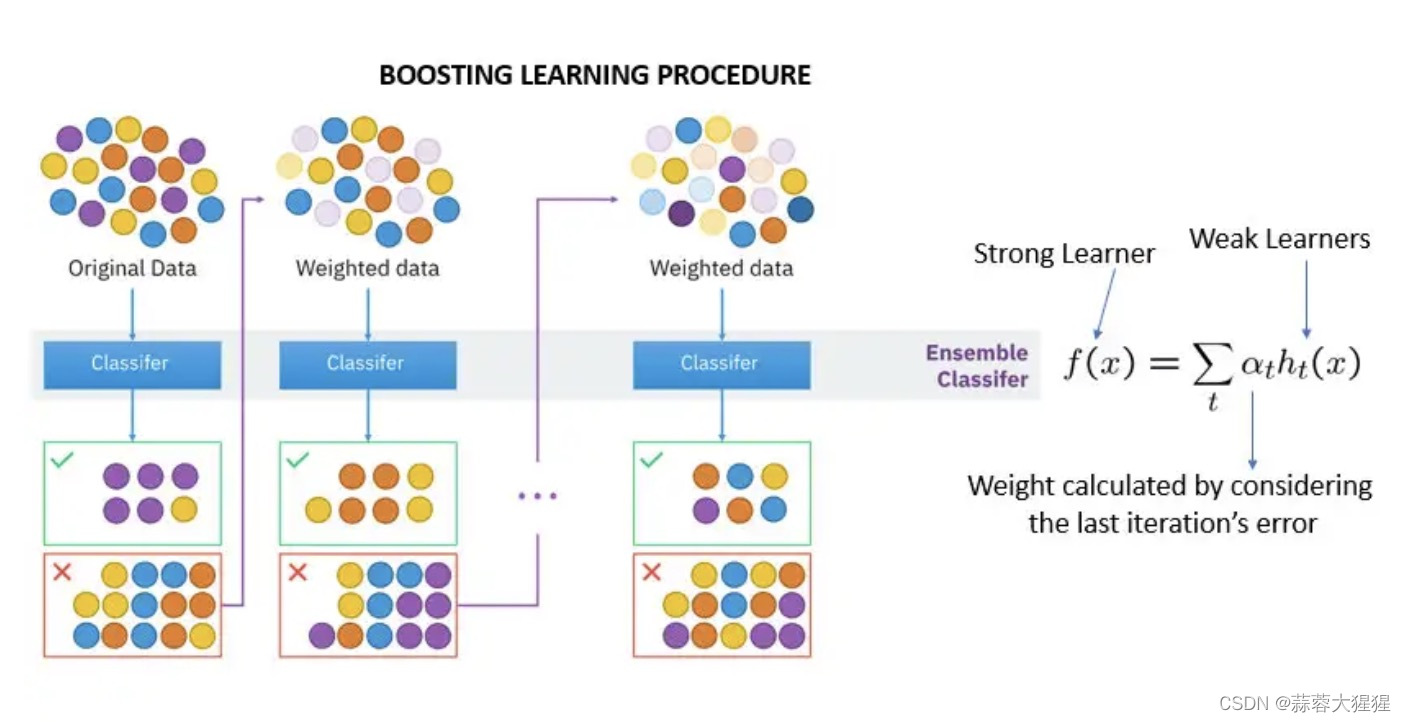
boosting与bagging有部分异曲同工之妙。
boosting是先有n种弱分类器,是一个迭代算法,我们不断改变训练样本数据的权重去训练不同的弱分类器,最后再通过组合策略得到强分类器。
boosting中每个弱分类器用得到都是同一个训练样本,只是权重不同。当一个弱分类器获得训练样本投喂后,将会自动调整训练样本权重,然后带权重的训练样本再去投喂下一个弱分类器。不断迭代,最后集成得到强分类器。
2. 选择方式
2.1 平均法
对于预测数值的模型而言,平均法是最常见的,各个基分类器所预测的数值加总求平均得到最后的预测数值。
2.2 投票法
对于分类问题,最常用的是投票法,如同现实生活一般,每个基分类器预测出的类别进行投票,少数服从多数。
3. Adaboost算法流程
3.1 计算样本权重
赋予训练集中每个样本一个权重,构成权重向量D,将权重向量D初始化相等值。设定我们有m个样本,每个样本的权重都相等,则权重为:
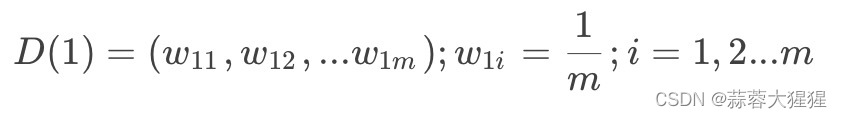
3.2 计算错误率
错误率=(分类错误的样本数量 / 样本总数量)* 样本的权重
之前就已经被错误分类的样本权重更大
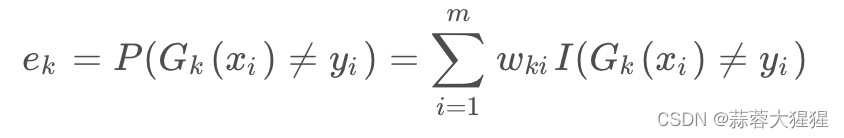
3.3 计算弱分类器权重
为当前分类器赋予权重值alpha,则alpha计算公式为:
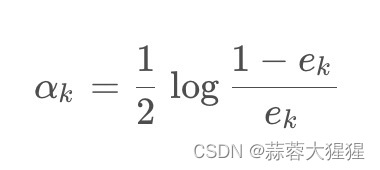
3.4 调整权重值
根据上一次的训练结果,我们需要对样本的权重进行更新,被分类错误的样本权重增大,使得新的基分类器能够更好的去识别
-根据当前弱分类器的表现更新每个样本的权重,如果样本被错误分类,权重就会增加,如果正确分类,权重就会减小。
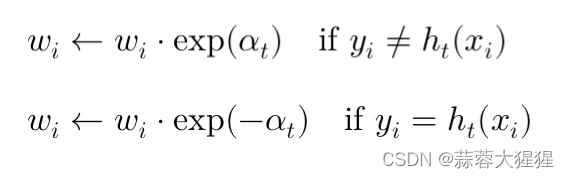
3.5 归一化权重
为了确保在下一轮迭代形成有效的概率分布,需要将权重归一化,使所有的权重总和为1.
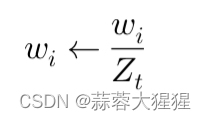
3.6 迭代
设置迭代次数或者迭代结束条件,将强分类器生成。
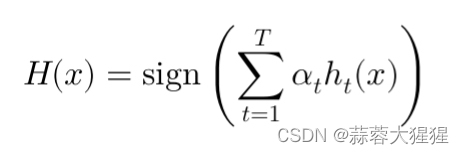
举例说明
假设有4个样本,初始权重各为0.25,经过一轮训练后,弱分类器的错误率为0.3
1. 计算分类器权重:
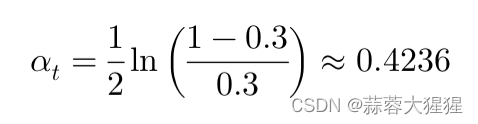
2. 更新权重

3. 归一化权重

这样不断调整样本权重,使得后续的弱分类器能够更多的关注被前一轮分类错误的样本,从而提高模型的整体性能。

4. 手写代码实现
首先为了打比方,我们先构建基分类器:
#单层决策树生成函数
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): #把这个函数当作两个分类器
#dimen为datamat的列索引值,threshVal为阈值对比方式
retArray = np.ones((np.shape(dataMatrix)[0],1))
if threshIneq == 'lt': #lt代表小于
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = 1.0
return retArray构建一个函数,获得在目前权重样本下最后基分类器以及对应的权重错误率:
def buildStump(dataArr,classLabels,D):
dataMatrix = np.mat(dataArr);labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0
bestStump = {} #存储最佳决策树
bestClasEst = np.mat(np.zeros((m,1)))
minError = 1000
for i in range(n): #遍历每个特征 相当于要找出那个分类器最好的分类特征
rangeMin = dataMatrix[:,i].min();rangeMax = dataMatrix[:,i].max()
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']: #不同阈值方式进行比较 相当于遍历不同的分类器
threshVal = (rangeMin + rangeMax)/numSteps
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = np.mat(np.ones((m,1))) #错误
errArr[predictedVals == labelMat] = 0 #没错的记为0
weightedError = D.T * errArr #计算加权错误
print(weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i #最好的分类维度
bestStump['thresh'] = threshVal #最好的分类阈值
bestStump['ineq'] = inequal #最好的过滤方式
return bestStump,minError,bestClasEst #返回最好的分类器,特征不断迭代基分类器,获得强分类器:
#基于单层决策树的AdaBoost训练
def adaBoostTrainsDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m,1))/m) #归一化初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt): #迭代多少次 40次基分类器
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
print(D)
alpha = float(0.5*np.log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = np.multiply(D,np.exp(expon))
D = D/D.sum() #归一化处理
aggClassEst += alpha*classEst #更新
aggErrors = np.multiply(sign(aggClassEst) != np.mat(classLabels).T,np.ones((m,1)))
errorRate = aggErrors.sum() / m #计算错误率
if errorRate == 0.0:break
return weakClassArr#返回分类器调用我们最终的强分类器:
#调用AdaBoost分类函数
def adaClassify(datToClass,classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)): #根据分类器个数
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],classifierArr[i]['thresh'],classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst #权重与结果想乘的和
return sign(aggClassEst)5. 调包实现
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 数据切分
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# 初始化AdaBoost分类器
clf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50,
learning_rate=1.0,
random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 评估
accuracy = accuracy_score(y_test, y_pred)
print(f"Test Accuracy: {accuracy}")6. Adaboost优点与局限性
6.1 优点
1. 提高分类性能:通过迭代调整样本权重,使分类器更关注那些难以分类的样本,从而提高整体分类准确率
2. 适应性强:Adaboost能够自适应地调整样本权重,以此聚焦难分类的样本
3. 无需特征选择:对特征的选择没有强烈的依赖,可以在不进行特征选择的情况下直接应用于原始数据
6.2 局限性
1. 模型解释性差:Adaboost是多个弱分类器的加权组合,这种模型的解释性差,不容易理解每个特征的具体贡献
2. 对弱分类器的依赖: Adaboost性能高度依赖于弱分类器的表现,如果错误率接近50%,其提升风险可能不明显
3. 对噪声敏感:由于在每次迭代中增加错误分类样本的权重,噪声数据对最终模型产生较大的影响
4. 计算成本高:算法需要进行多次迭代,每次迭代都会重新训练一个弱分类器,这在处理大规模数据集时可能会导致较高的计算成本
7. 应用前景
1. 图像分类与识别:
-人脸识别:将弱分类器组合为强分类器,能够有效识别人脸特征
-目标检测:在计算机视觉中, 可以用于检测和识别各种目标
2. 网络安全:
-入侵检测:通过组合多个简单的特征分类器来检测异常网络和入侵行为
-恶意软件检测
3. 自动驾驶与智能交通:
交通流量预测:提供更加准确的交通管理决策
4. 自然语言处理:
文本分类:如垃圾邮件过滤,情感分析,主题分类等
信息检索:在信息检索系统中,Adaboost可以用于提高文档的相关性排序性能,帮助更准确地检索用户所需信息
8. 参考资料
《机器学习实战》
















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









