







目录
1.引言与背景
多维尺度分析(Multi-Dimensional Scaling, MDS)是一种统计学方法,用于将复杂、高维的相似性或距离数据转化为直观的、低维的可视化表示。MDS最初由Torgerson于1952年提出,其核心思想是通过保持原始数据中对象间距离关系的近似,将数据映射到一个较低维度的空间中,使得这些对象在新空间中的位置关系能够反映出原始数据中的相似性或距离。MDS在社会科学、心理学、生物学、地理信息系统、信息检索、数据挖掘等领域有着广泛的应用,尤其在复杂数据集的可视化、模式识别、聚类分析等方面发挥着重要作用。
2.MDS定理
MDS的基本原理是通过优化目标函数来实现高维到低维的映射。目标函数通常包含两个部分:一是保持原始数据中对象间距离的近似度(stress函数),二是映射到低维空间的约束条件。具体来说,MDS试图找到一个低维空间中的点阵P,使得P中各点之间的距离与原始数据中对应对象间的相似性或距离度量尽可能接近。优化过程通常涉及最小化以下形式的目标函数:
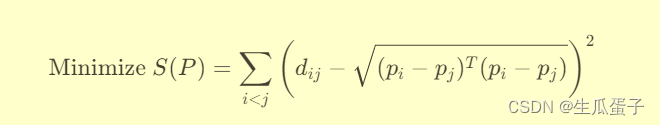
其中,dij表示原始数据中对象i和j之间的相似性或距离度量,pi,pj分别为它们在低维空间中的坐标向量。通过最小化stress函数S(P),MDS力求在低维空间中保持原始数据的距离结构。
3.算法原理
MDS算法通常分为两大类:度量MDS(Metric MDS, MMDS)和非度量MDS(Non-metric MDS, NMDS)。两者的主要区别在于对原始数据中相似性或距离度量的假设:
-
度量MDS:假设原始数据中的相似性或距离度量满足三角不等式,即对于任何三个对象i、j、k,有
。在这种情况下,MDS可以通过经典线性代数方法(如奇异值分解SVD)来求解。
-
非度量MDS:不假设原始数据满足度量性质,而是通过秩次排序来表示对象间的相对相似性或距离。非度量MDS通常采用迭代优化算法(如SMACOF算法)来逼近最优解。
无论哪种类型的MDS,其基本流程如下:
-
计算原始数据的相似性或距离矩阵。
-
选择合适的MDS方法(度量或非度量)。
-
通过优化目标函数,求解低维空间中的点阵P。
-
将点阵P可视化,分析对象在低维空间中的分布和聚类结构。
4.算法实现
下面是使用Python的sklearn库来实现多维尺度分析(MDS)。我们将以一个简单的例子说明如何创建一个距离矩阵,并使用度量MDS将其降维到二维空间以便可视化。代码讲解如下:
Python
import numpy as np
from sklearn.manifold import MDS
import matplotlib.pyplot as plt
# Step 1: 构造原始数据
# 假设我们有一个5个样本的高维数据集,每个样本有10个特征
np.random.seed(0)
X_high_dim = np.random.rand(5, 10)
# Step 2: 计算样本间的距离矩阵
# 在MDS中,我们需要提供一个距离或相似性矩阵作为输入。
# 这里我们使用欧氏距离作为示例,但实际应用中可根据数据特性和需求选择其他距离度量。
from sklearn.metrics.pairwise import euclidean_distances
dist_matrix = euclidean_distances(X_high_dim)
# Step 3: 实例化MDS模型并进行降维
# 我们使用度量MDS(Metric MDS),并指定目标维度为2,以便于后续可视化
mds = MDS(n_components=2, dissimilarity='precomputed')
X_mds = mds.fit_transform(dist_matrix)
# Step 4: 可视化降维后的结果
plt.figure(figsize=(8, 6))
plt.scatter(X_mds[:, 0], X_mds[:, 1], s=100, color='steelblue', alpha=0.8)
plt.title('2D MDS Visualization')
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.grid(True, linestyle='dotted')
plt.show()代码详解:
-
导入所需库:
numpy用于生成随机高维数据和进行数值计算。sklearn.manifold.MDS是sklearn库中实现MDS的类。matplotlib.pyplot用于数据可视化。
-
构造原始数据: 使用
numpy.random.rand生成一个5行10列的随机数组,模拟5个具有10个特征的样本。 -
计算距离矩阵: 使用
sklearn.metrics.pairwise.euclidean_distances函数计算样本间的欧氏距离,得到一个5x5的对称距离矩阵。 -
实例化MDS模型并进行降维:
- 创建一个
MDS对象,设置n_components=2表示目标维度为2。 - 使用
fit_transform方法对距离矩阵进行降维处理,返回的是一个形状为(5, 2)的二维数组,即5个样本在2维空间中的坐标。
- 创建一个
-
可视化降维结果:
- 使用
matplotlib.pyplot.scatter绘制散点图,横坐标为降维后第一维(X_mds[:, 0]),纵坐标为第二维(X_mds[:, 1])。 - 设置标题、轴标签、网格线等样式,最后通过
plt.show()显示图形。
- 使用
通过上述代码,您已经成功实现了多维尺度分析(MDS),并将高维数据可视化为二维空间中的点分布,从而直观地观察数据的结构和聚类特性。在实际应用中,您可以替换为自己的数据集,并根据需要调整距离度量方法和MDS参数。
5.优缺点分析
优点:
- 直观可视化:MDS能够将高维数据映射到二维或三维空间,便于直观地观察数据分布和结构。
- 保持距离关系:MDS在低维空间中尽可能保留了原始数据的距离结构,有助于发现潜在的聚类或模式。
- 适用范围广:无论是度量还是非度量数据,MDS都能找到合适的处理方法。
缺点:
- 对距离矩阵依赖性强:MDS结果的可靠性很大程度上取决于输入的距离矩阵的质量。若距离矩阵计算不当或含有噪声,可能导致映射结果失真。
- 计算复杂度较高:对于大规模数据集,尤其是非度量MDS,优化过程可能较为耗时。
- 解释性有限:虽然MDS能够生成可视化结果,但对于映射到低维空间后的具体坐标值,其物理或实际意义可能不明确。
6.案例应用
- 社会网络分析:利用MDS将社交网络中个体间的亲密度或交互频率转化为二维图,揭示社区结构和影响力中心。
- 生物信息学:对基因表达数据或蛋白质序列相似性进行MDS,发现潜在的分类或进化关系。
- 消费者行为研究:通过分析消费者对产品或服务的评价相似性,利用MDS可视化消费者偏好分布,指导市场细分和产品定位。
7.对比与其他算法
- 与PCA对比:主成分分析(PCA)也是一种降维方法,但其目标是最大化数据方差的保留,而非保持距离关系。PCA更适合于线性相关性强的数据集,而MDS对非线性关系的处理能力更强。
- 与t-SNE对比:t-distributed Stochastic Neighbor Embedding(t-SNE)也是一种流行的降维可视化方法,其特点是擅长揭示高维数据的局部结构。相比MDS,t-SNE对局部聚类效果更好,但全局结构可能不如MDS清晰。
8.结论与展望
多维尺度分析作为一种经典的降维与可视化技术,凭借其保持距离关系的特点,在诸多领域中发挥了重要作用。随着数据科学的发展,MDS与其他现代降维方法(如深度学习驱动的降维)相结合,有望进一步提升大规模、高复杂度数据的分析与理解能力。同时,对MDS算法的理论研究和优化,特别是在非度量MDS的收敛性和稳定性方面,也将有助于扩大其在实际问题中的应用范围。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









