







目录
1.引言与背景
在现代机器学习,特别是在自然语言处理(NLP)和计算机视觉(CV)领域,注意力机制已经成为一种核心组件,它允许模型在处理复杂输入时聚焦于最相关的信息片段。注意力机制通过模拟人类大脑的注意力处理机制,有效提升了模型对输入数据的利用效率和理解深度。在众多注意力机制中,键值对注意力(Key-Value Attention)脱颖而出,以其直观且高效的特性,在诸如序列到序列模型、图像描述生成等任务中发挥着关键作用。
背景动机
传统神经网络,尤其是循环神经网络(RNNs)在处理长序列数据时面临计算瓶颈和梯度消失问题。键值对注意力机制的引入,打破了这一限制,它不仅能够并行处理所有输入,而且通过直接关注输入序列中最有价值的部分,显著提升了模型的表达能力和计算效率。该机制最初在NLP领域得到广泛应用,随后扩展到了CV和其他领域,成为跨领域的基础构建模块。
2.键值对注意力定理
定义
键值对注意力机制的核心思想是将输入数据分为两部分:键(Keys)和值(Values),并通过查询(Query)来索引这些键值对,以获取与查询最为相关的值。具体来说,对于每个查询,模型会计算查询与所有键之间的相似度(通常通过点积实现),然后利用这些相似度(权重)对相应的值进行加权求和,得到最终的上下文表示。
理论基础
键值对注意力的数学表达可以形式化为:
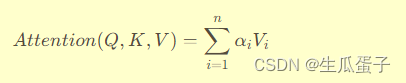
其中,Q是查询向量,K是键向量矩阵,V是值向量矩阵,n是键值对的数量。注意力权重 由查询 Q 和对应的键
计算得出,通常通过softmax函数归一化,以确保权重总和为1,即:
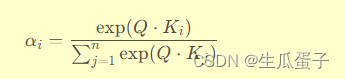
3.算法原理
计算流程
-
键值对准备:将输入序列映射为键 K 和值 V 的集合。通常,这一步骤通过不同的线性变换实现,确保查询、键和值处于同一向量空间。
-
计算相似度:对每个查询 Q,与所有的键
计算点积,以评估它们之间的相关性。
-
权重分配:利用softmax函数将相似度转化为概率分布 α,代表每个值
对查询的贡献程度。
-
加权求和:根据 α 对所有值 V 进行加权求和,生成最终的上下文向量,即注意力机制的输出。
多头注意力机制
为了增强模型的表达能力,键值对注意力通常与多头注意力机制结合使用。每个头可以专注于输入的不同表示子空间,最后再将各头的结果拼接或聚合,以捕捉更丰富的上下文信息。
键值对注意力机制因其高度的灵活性和高效性,已成为现代深度学习模型不可或缺的一部分。它不仅解决了长序列处理的难题,还通过聚焦关键信息,提升了模型的性能和理解能力。随着研究的深入和技术的进步,键值对注意力机制将继续在更广泛的领域内发挥其潜力,推动人工智能技术迈向新的高度。未来的研究方向可能会集中在进一步优化注意力机制的效率、探索更复杂的数据结构和场景适应性,以及深化对注意力机制内在机理的理解。
4.算法实现
实现细节
在实践中,键值对注意力机制的实现往往依托于深度学习框架,如TensorFlow或PyTorch。以下是一个基于PyTorch的简化实现示例:
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Scaled Dot-Product Attention implementation.
"""
dim_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(dim_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, value)
return output, attention_weights
# 假设query, key, value已经通过线性变换准备好了
query = torch.randn((batch_size, num_heads, seq_len, head_dim))
key = torch.randn((batch_size, num_heads, seq_len, head_dim))
value = torch.randn((batch_size, num_heads, seq_len, head_dim))
output, attn_weights = scaled_dot_product_attention(query, key, value)此代码段展示了如何计算点积注意力,并通过softmax获得注意力权重,进而加权求和得到输出。num_heads表示多头注意力中的头数,增加了模型的并行处理能力和表达能力。
多头注意力实现
在多头注意力机制中,除了上述基本步骤外,还需在计算前对输入进行线性变换以生成不同头的键、值、查询向量,并在计算后将各个头的结果合并。这可以通过定义一个额外的多头注意力层实现,该层负责分割和合并操作。
5.优缺点分析
优点
- 增强模型表达力:通过动态地为不同输入部分分配注意力权重,模型能更好地理解输入序列的复杂结构和上下文依赖。
- 提高计算效率:与RNN相比,注意力机制能够并行处理,大大减少了序列处理的时间复杂度。
- 灵活的上下文选择:允许模型在需要时“回顾”到输入序列的任何位置,非常适合长序列数据处理。
- 多头机制:增加了模型的并行性和对多种特征的捕获能力,提升了学习效率和泛化能力。
缺点
- 计算成本:尽管并行处理提高了效率,但大规模应用时,特别是在高维度或长序列上,注意力机制仍可能消耗大量计算资源。
- 解释性:注意力权重提供了某种程度的解释性,但复杂的交互和多头机制使得直接解释变得困难。
- 过拟合风险:强大的表达能力也可能导致过拟合,尤其是在数据量不足时,需要合适的正则化策略。
6.案例应用
自然语言处理
键值对注意力机制在机器翻译、文本摘要、情感分析等NLP任务中展现了卓越性能。例如,在Transformer模型中,多头注意力机制作为核心组件,显著提高了翻译质量和生成文本的质量。
计算机视觉
在CV领域,注意力机制被用于图像分类、物体检测和图像描述生成等任务。例如,在图像描述生成中,模型利用注意力机制聚焦于图像的关键区域,生成更加准确和细致的描述。
推荐系统
键值对注意力也被应用于个性化推荐系统中,通过关注用户历史行为中的关键项,为用户提供更为精准的推荐内容。
语音识别
在语音识别领域,注意力机制帮助模型在长序列音频数据中聚焦于重要的语音特征,从而提升识别准确率。
综上所述,键值对注意力机制凭借其强大的灵活性和高效性,在多个领域展现出广泛的应用前景和深远影响,不断推动着人工智能技术的发展边界。随着算法的不断优化和新应用场景的探索,其在未来智能系统中的作用将更加显著。
7.对比与其他算法
与传统循环神经网络(RNN)的对比
传统的循环神经网络通过隐藏状态传递信息,处理序列数据时存在梯度消失/爆炸问题,且在长序列上计算效率低下。相比之下,键值对注意力机制不依赖于顺序处理,可以并行计算,大大提高了训练速度和处理长序列的能力。此外,注意力机制允许模型直接“跳跃”到序列中的重要部分,提高了对上下文的理解能力,而RNN则需要按部就班地通过时间步传播信息。
与自注意力(Self-Attention)的对比
虽然键值对注意力和自注意力都属于注意力机制家族,但它们的应用场景和侧重点有所不同。自注意力机制中,查询、键和值都来源于同一输入序列的不同位置,适用于序列内部元素间的相互依赖建模,如Transformer模型的核心部分。而键值对注意力明确区分了查询和键值对,常用于跨序列的匹配和检索任务,比如机器翻译中的源语言到目标语言的映射,或是推荐系统中用户兴趣与商品特征的匹配。
与卷积神经网络(CNN)的对比
卷积神经网络通过局部感受野和权值共享捕捉空间局部特征,适用于图像处理等领域。与之相比,键值对注意力没有固定的局部感受野限制,可以全局考虑输入信息,更适合处理需要全局上下文理解的任务。在某些视觉任务中,结合CNN的局部特征提取能力与注意力机制的全局上下文理解,可以进一步提升模型性能。
8.结论与展望
键值对注意力机制作为一种高效的序列数据处理方式,以其强大的表达能力和灵活的上下文选择能力,在自然语言处理、计算机视觉、推荐系统等多个领域展现了卓越的性能。通过与现有技术如RNN、自注意力以及CNN的对比,我们不难发现,键值对注意力机制不仅克服了传统方法的局限,还在特定任务上实现了性能上的飞跃。
未来,随着对注意力机制更深入的研究,我们可以期待以下几个方面的进展:
- 模型优化与轻量化:研究如何在保持性能的同时减少计算和存储开销,使其更适用于资源受限的环境。
- 可解释性增强:开发新的可视化工具和技术,提高注意力机制的可解释性,帮助研究人员和开发者更好地理解模型决策过程。
- 跨模态应用:探索键值对注意力在跨模态学习中的应用,如图文匹配、视频理解等,进一步拓宽其应用场景。
- 理论基础深化:加强注意力机制的理论研究,包括但不限于注意力分布的优化准则、注意力机制的泛化能力分析等,为算法设计提供坚实的理论支撑。
总之,键值对注意力机制作为现代机器学习的重要组成部分,将继续推动人工智能技术的创新与发展,其潜力远未被完全挖掘。随着技术的不断进步,我们有理由相信,它将在未来智能系统的构建中发挥更加核心和多样化的作用。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









