






 本文概述了监督学习(如决策树、信息增益和SVM)和无监督学习(如聚类和降维)的特点,重点介绍了决策树的构建、信息熵的计算以及支持向量机的算法思想和核函数的应用。同时,对比了线性判别分析(LDA)与PCA的差异。
本文概述了监督学习(如决策树、信息增益和SVM)和无监督学习(如聚类和降维)的特点,重点介绍了决策树的构建、信息熵的计算以及支持向量机的算法思想和核函数的应用。同时,对比了线性判别分析(LDA)与PCA的差异。
监督学习方法的特点
1.数据集是给定带有标签信息
2.训练一个从x和映射到f的映射,进行预测等
3.应用于回归或者分类任务中
三部分内容:
1.从训练数据集中得到映射函数f
2.在测试数据集上测试映射函数f
3.在未知数据集上测试映射函数f
无监督学习方法的特点(对比监督学习)
1.数据集是给定带有无标签信息
2.挖掘数据中有价值的有用信息
3.应用于聚类或降维任务中
决策树
定义:是一种通过树形结构来进行分类的方法,决策树可以看作是一系列以叶子结点为输出的决策规则。
构建决策树
这里涉及到纯度的概念,纯度越高,则更便于决策,有三种方法(指标)可以对纯度以及如何进行决策进行判断。
信息熵(E(D)):信息熵越高,集合的不确定性越大,纯度越低,越不利于分类,通常先选择信息熵最低的属性
信息熵的公式:(记得负号)
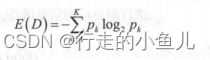
1.信息增益(Gain)
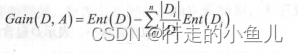
此时的Ent(D)算的是目标变量的信息熵
Ent(Di)计算的是某个属性中,每个子样本集(每个分支结点)在目标变量的影响下得到的信息熵
2.信息增益率(Gain-ratio)
在信息增益Gain上除以属性本身带来的信息info
![]()
属性本身带来的信息info:
![]()
3.Gini系数
![]()
支持向量机
支持向量机
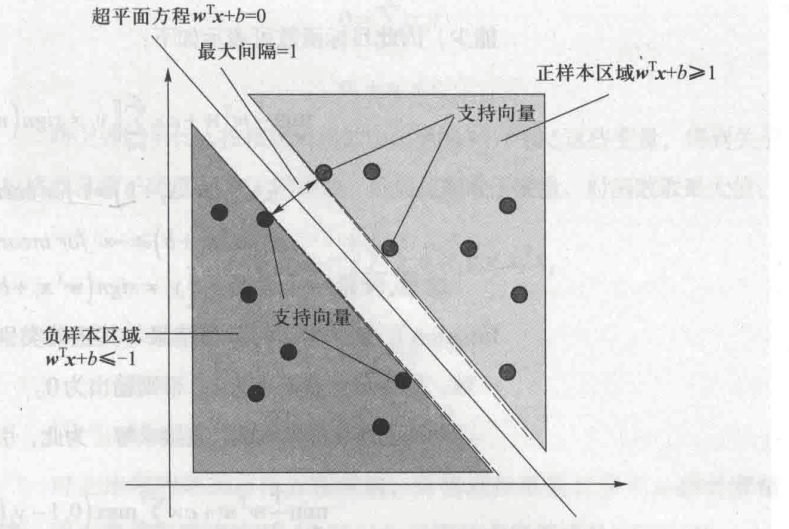
以往的模型性能从训练样本集所得经验风险来衡量,而svm通过结构风险最小化来解决过学习问题。支持向量机会寻找一个最佳超平面,使得每个类别中距离超平面最近的样本点到超平面的最小距离最大。
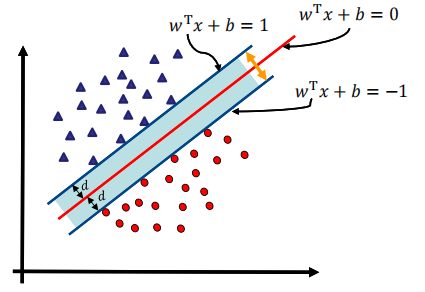
算法思想
找到集合边缘上的若干数据(支持向量),找一个超平面,使得支持向量到该平面的距离最大
超平面
![]()
点到超平面的距离
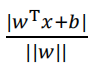
![]()
点到平面的距离
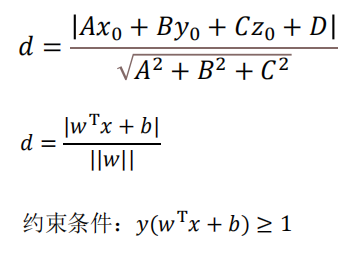
算法目的
找w和b,最大化d
算法求解
最小化目标 以及 限制
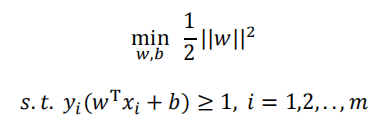
利用拉格朗日乘子法和KKT条件求最优解
![]()



核函数
原始的样本空间不一定是线性可分的,此时可以将样本原始的空间映射到一个更加高位的特征空间去,使得样本在这个特征空间中高改了线性可分

线性可分svm


松弛变量 软间隔 hinge损失函数
核函数(线性不可分svm)
![]()
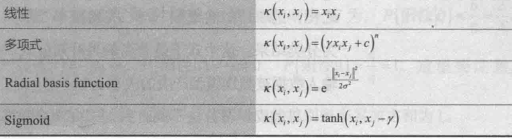
线性判别分析(LDA)
定义:LDA是一种基于监督学习的降维方法,LDA利用类别信息将高维数据线性投影到一个低维空间,和PCA一样,都在寻找最佳解释数据的变量线性组合,均是优化寻找特征向量w来实现降维
与PCA的区别:
寻找目标不同:

降维的维度选择不同:

原则:类内方差小,类间间隔大
协方差矩阵
![]()
假设目标变量的类别为2
投影后的表达式
![]()
类别C1投影后的协方差矩阵
![]()















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









