







1.理解监督学习
根据目标值的不同可以将监督学习划分为两种形式:
分类:
使用数据来预测类别,叫做分类。例如一张图像中是否含有一个猫或者狗。两类类别的是叫做二分类问题,而对于两类的时候比如当预测多个类别就是多类问题。
回归:
使用数据预测真实值的监督学习就叫回归。例如我们呢预测股票的价值,不像预测股票的类别那样,回归的目标尽可能准确地预测目标值;比如尽可能小的误差来预测股票价格。
所以判断需要做的是那个问题:分类还是回归
2.Opencv中的监督学习
Opencv建立模型的步骤:
1.初始化:通过名字调用模型船舰一个模型的空的事例
2.设置参数:模型的参数需要同通过函数进行设置,不同的模型会有不同的设置方法。比如,为了设置KNN算法,需要指定它的开放参数K
3.训练模型:利用一个train函数来拟合模型。
4.预测标签:利用一个predict函数预测新数据的标签、
5.评估模型:每一个模型必须提供一个calcError的类函数,用于评估模型的性能。每个模型的计算方法可能会不同。
scikitlearn中也有一些机器学习的包是opencv中没有的。
3.使用评分函数评估模型性能
评估模型的质量:
在二值分类任务中,有常见指标如下。
accuracy_score: 准确率指的是在测试数据中,那些预测正确的数据点的数据量除以整个测试数据集的大小。图片被分为A和B两类。图片被正确分类的比例
**precision_score:**精确率描述的是分类器把包含A的图片不分为B的能力。就是说在所以分类器认为测试数据中是A类的图片中,精确率是其中真正包含A的图片的比例。(所有识别为A中的真的是A的比率)(类别精确比例)
**recallscore:**召回率(敏感率senti)换句话,在测试数据中所有的A类图片中,召回率是那些已经被正确识别为A的比例。(真的是A中被识别成A) (被正确挑选 的比例)
回归任务中:
mean_squared_error:回归问题的误差指标计算训练数据集中数据点的预测值和真实值的平方误差,再在说有数据点上计算它们的平均值.
explained_variance_score:这是一个描述计算模型对于测试数据的方差或者离散程度的已经解释的程度。一般来说可释方差常常用于相关系数计算。
r2_score:r的数值与可释方差密切相关,但是使用无偏执方差轨迹。它也被称作决定系数。
4.理解线性回归
回归是用于预测连续的输出而不是预测离散的类别的标签。最简单的回归模型叫做线性回归。线性回归的概念是通过特征线性组合来描述目标变量。(区别于MLP的激活函数层)
我们呢简化问题,仅仅考虑两个特征。假设想要使用两个特征(今天的股票价格和昨天的股票价格)来预测明天的股票价格。把今天的股票价格作为第一个特征f1,昨天的股票价格作为特征f2.接下来线性回归的目标就是学习两个权重系数:w1,w2.
这样就可以使用下面的公式来预测明天的股票价格。
Y=w1f1+w2f2
Y是预测数值,y是真实数值
仅仅有一个特征变量的特殊例子叫做简单线性回归。
可以轻易对此进行扩展,从过去的股票价格样本获取 更过的特征。如果有M个特征
Y=w0+sum(wifi)
这是一组多元的线性空间。
增加一个偏执使得超平面可以不通过零零点。
最终线性回归的目标就是学习一组权重参数进而在预测时候尽可能准确的接近真实数值。与分类器可以直接得到的模型准确率的数值不同,回归里面的评分函数常常使用所谓的损失函数来表示.
最常用的就是均方误差,计算每一个数据点i的预测数值Y和目标输出数值y之间的误差平方,然后取所有的误差平方的平均值。
4预测房价波士顿
import matplotlib.pyplot as plt
import pylab
from sklearn.datasets._samples_generator import make_blobs
import cv2
import numpy as np
from sklearn.datasets import make_moons
from sklearn.cluster import SpectralClustering
import numpy as np
from sklearn import datasets
from sklearn import metrics
from sklearn import model_selection as modsel
from sklearn import linear_model
import matplotlib.pyplot as plt
plt.style.use('ggplot')
#加载数据集
boston=datasets.load_boston()
print(boston.data.shape)
print(boston.target.shape)
#构建网络模型
linreg=linear_model.LinearRegression()
X_train,X_test,y_train,y_test=modsel.train_test_split(boston.data,boston.target,test_size=0.1,random_state=42)
linreg.fit(X_train,y_train)#scikitlearn 中的train函数就是fit
metrics.mean_squared_error(y_train,linreg.predict(X_train))
print("确定系数{}".format(linreg.score(X_train,y_train)))
#测试模型
y_pred=linreg.predict(X_test)
metrics.mean_squared_error(y_test,y_pred)
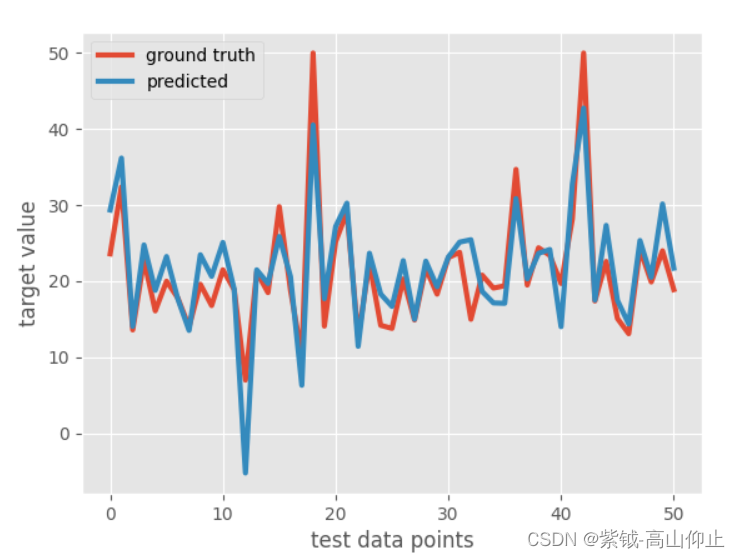
plt.figure()
plt.plot(y_test,linewidth=3,label='ground truth')
plt.plot(y_pred,linewidth=3,label='predicted')
plt.legend(loc='best')
plt.xlabel('test data points')
plt.ylabel('target value')
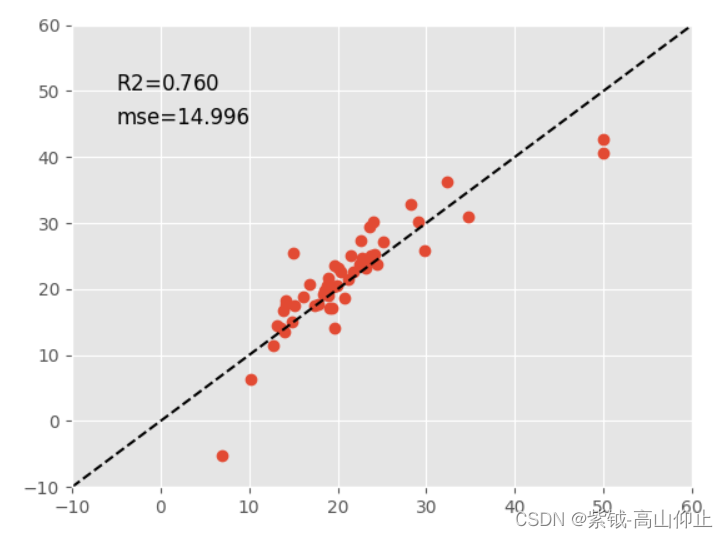
plt.figure()
plt.plot(y_test,y_pred,'o')
plt.plot([-10,60],[-10,60],'k--')
plt.axis([-10,60,-10,60])
s=linreg.score(X_test,y_test)
m=metrics.mean_squared_error(y_test,y_pred)
scorestr=r"R$2$=%.3f"%s
errstr="mse=%.3f"%m
plt.text(-5,50,scorestr,fontsize=12)
plt.text(-5,45,errstr,fontsize=12)
pylab.show()
















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











