










Contrastive Deep Graph Clustering with Learnable Augmentation (可学习增强对比深度图聚类)
文章目录
1. 来源

arxiv 2022
2. 动机
现有的方法首先生成具有随机增强的图视图,然后用交叉视图一致性原理对网络进行训练。虽然已经取得了良好的性能,但
- 实验观察到现有的增强方法通常是随机的;
- 并且依赖于预定义的增强,这是不够的;
- 并且缺乏与最终的聚类任务之间的反馈和协调;
为了解决这一问题,论文提出了一种新的可学习图数据增强算法(GCC-LDA)的图对比聚类方法,该方法完全由神经网络进行优化。模型设计了一种对抗性学习机制,在潜在空间中保持交叉视图的一致性,同时确保增强视图的多样性。在框架中,构建了一个结构增强器和一个属性增强器,用于结构级和属性级的增强学习。为了提高学习到的亲和矩阵的可靠性,在学习过程中引入了聚类方法,并利用高置信度伪标签矩阵和横视图样本相似度矩阵对学习到到的亲和矩阵进行了改良。在训练过程中,为了对学习到的视图进行持久的优化,模型设计了一个两阶段的训练策略,以获得更可靠的聚类信息。
3. 模型框架
模型设计了一种对抗学习机制,以保持潜在空间中的一致性,同时确保增强视图的多样性。此外,还设计了结构和属性增强器,分别动态学习结构和属性信息。此外,还从两个方面优化了增强视图的结构。
具体地说,一方面,利用两阶段的训练策略,我们得到了高置信度的聚类伪标签矩阵Z。另一方面,我们计算了交叉视图相似度矩阵S来反映节点的邻接关系。然后,我们用Z和S对可学习的结构Aug_S进行了改良,从而将聚类任务和增强学习集成到统一的框架中。
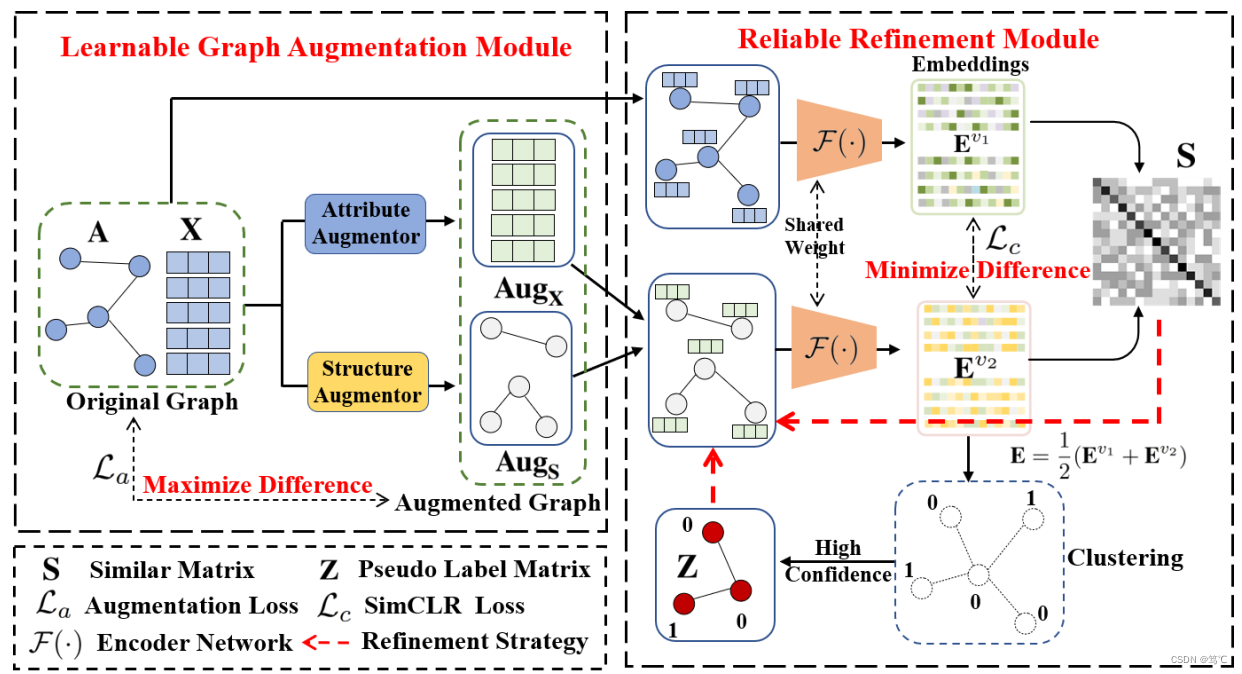
4. 方法介绍
4.1 总览
如图所示,模型的组成部分主要包括可学习的图增强模块和可靠的反馈改良模块。
4.2 可学习的图增强模块
4.2.1 结构增强器
- MLP-based
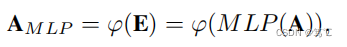
- GCN-based
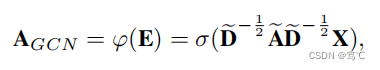
- Attention-based
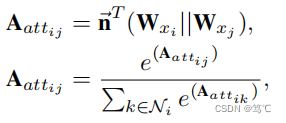
4.2.2 属性增强器
- MLP-based
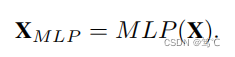
- Attention-based
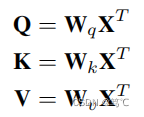
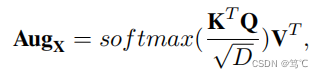
4.3 可靠的改良模块
通过增强模块,我们可以得到图数据的两个视图(原始图和增强视图)。
首先通过将编码器
F
(
)
\mathcal F()
F()将两个视图进行编码,并融合
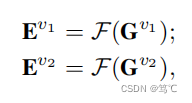
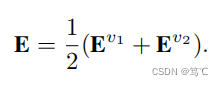
接着对E进行K-means算法,得到聚类结果。然后,将对学习视图进行改良,即相似矩阵和伪标签矩阵改良。
4.3.1 相似矩阵改良
通过编码器
F
(
)
\mathcal F()
F(),我们可以获得每个视图的嵌入。随后,相似度矩阵S表示第一个视图中的第 i 个样本与第二个视图中的第 j 个样本之间的相似度,公式如下:
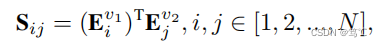
其中,
S
i
j
S_{ij}
Sij为交叉视图相似度矩阵。相似度矩阵S通过综合考虑属性和结构信息来度量样本之间的相似度。不同节点之间的连接关系可以用S来反映,因此,我们利用S对增强结构视图进行改良:
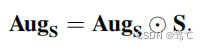
4.3.2 伪标签矩阵改良
为了进一步提高学习到的结构矩阵的可靠性,我们提取了可靠的聚类信息来构造该矩阵,从而在增广视图中进一步改良该结构。具体地说,我们利用顶部 τ 高置信度伪标签p来构造矩阵如下:
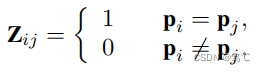
其中,
Z
i
j
Z_{ij}
Zij表示第i个样本和第j个样本之间的类别关系。详细来说,当
Z
i
j
Z_{ij}
Zij = 1时,两个样本具有相同的伪标签。而
Z
i
j
Z_{ij}
Zij = 0表示两个样本具有不同的伪标签。利用高置信度类别信息构造了伪标签矩阵。因此,图中的邻接关系可以很好地反映出来,从而优化了增广视图中学习结构的结构。伪标签矩阵用阿达玛乘积将学习到的结构细化为:
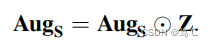
在本小节中,提出了两种策略来细化增广视图的结构。通过此设置,提高了学习结构AugS的可靠性,并保留了重要的拓扑结构。
4.3 损失函数
论文的GCC-LDA模型遵循共同的对比学习范式,其中模型最大化了交叉视图的一致性。详细地,GCC-LDA共同优化了两个损失函数,包括可学习增强损失La和对比损失Lc。
-
具体来说,La是原始图与可学习图之间的均方误差(MSE)损失,可以表示为:
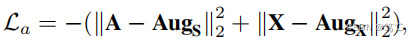
其中,A、AugS和X、AugX分别为原始结构和学习增强结构,分别为原始属性和学习增强属性。 -
在GCC-LDA中,我们利用归一化温度尺度的交叉熵损失(NT-Xent)来紧凑正样本,同时疏远负样本。对比损失的定义为:
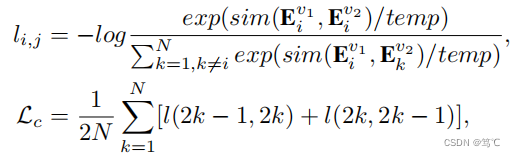
其中tmp为温度参数。sim(·)表示计算相似度的函数,如内积。
最终,得到总损失函数为:
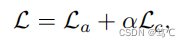
其中α是La和Lc之间的权衡。在等式中的第一项(16)鼓励网络生成具有不同语义的增广视图,以确保输入空间的多样性,而第二项是对比范式,以学习潜在空间中两个视图的一致性。通过对抗性方式最小化总损失函数,可以提高网络的鉴别能力。
5. 实验
- 1
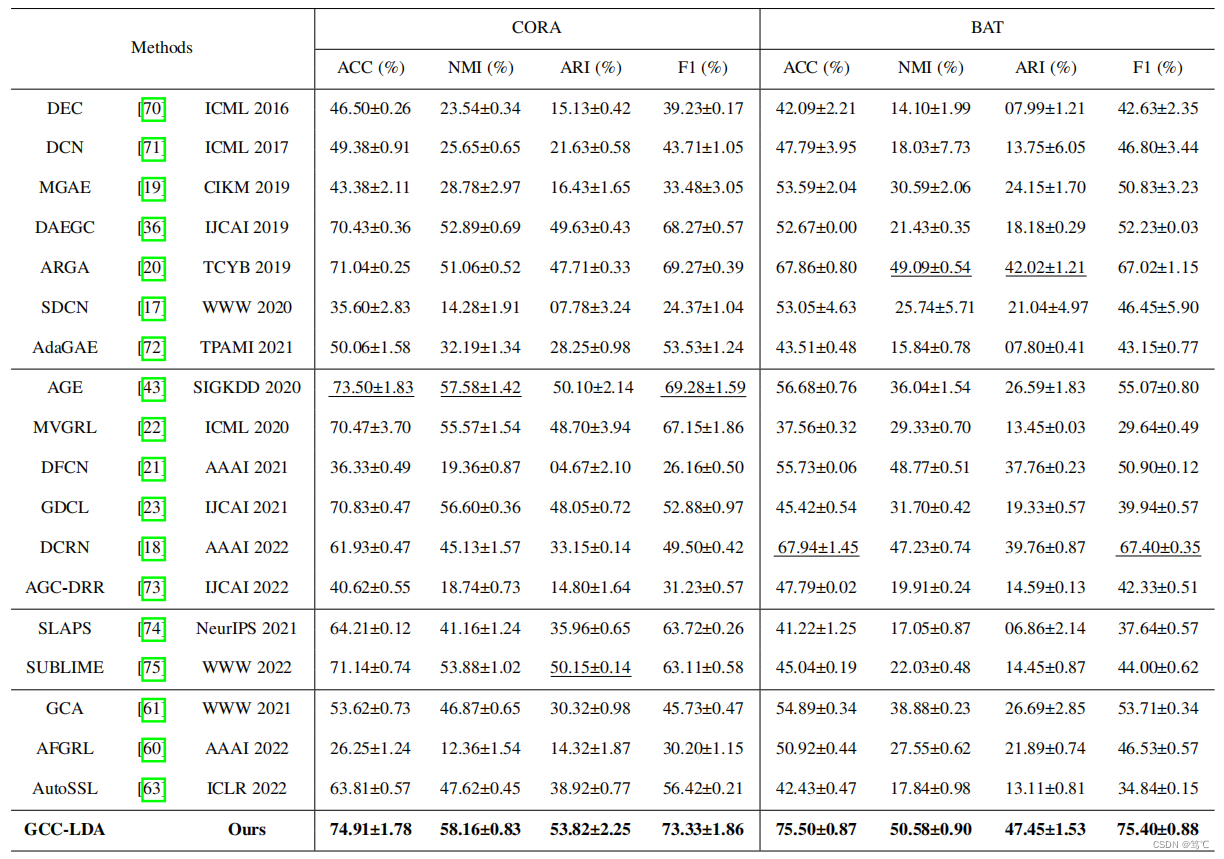
- 2
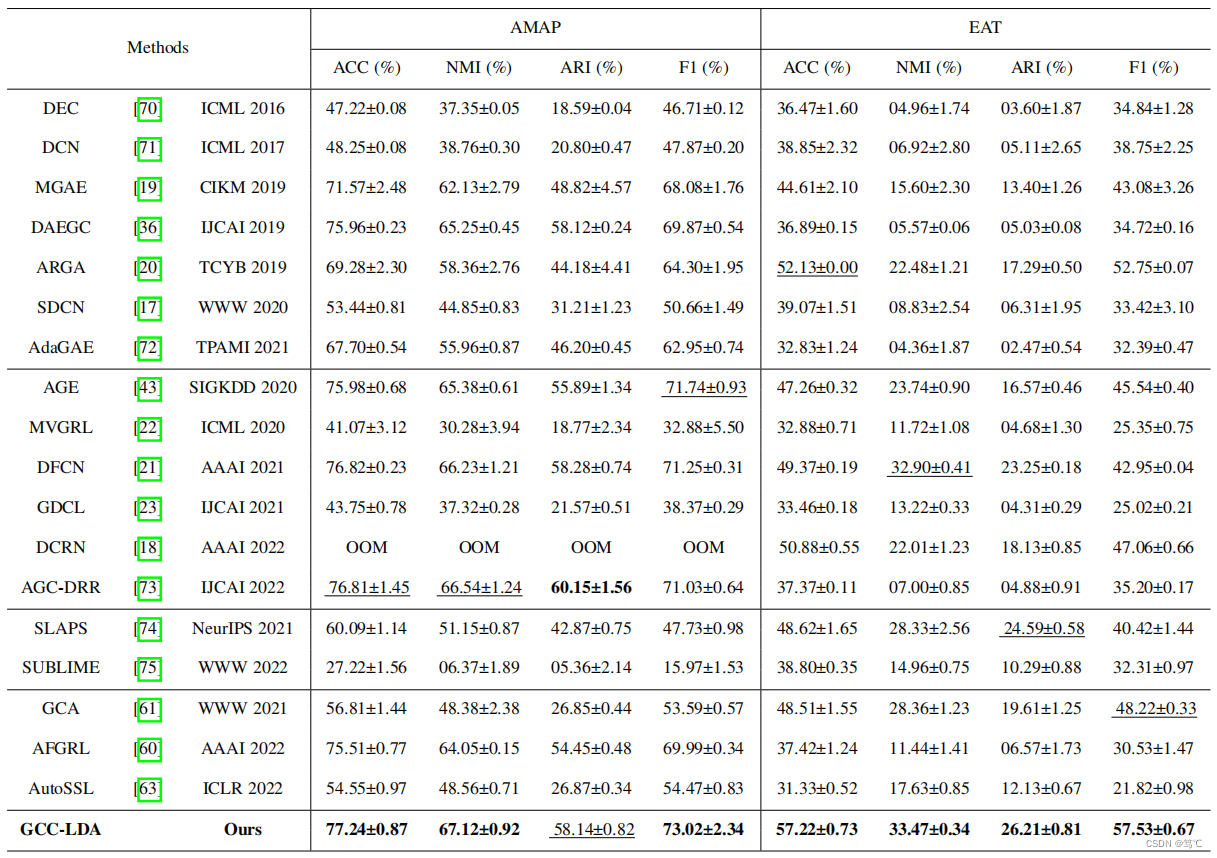
- 3
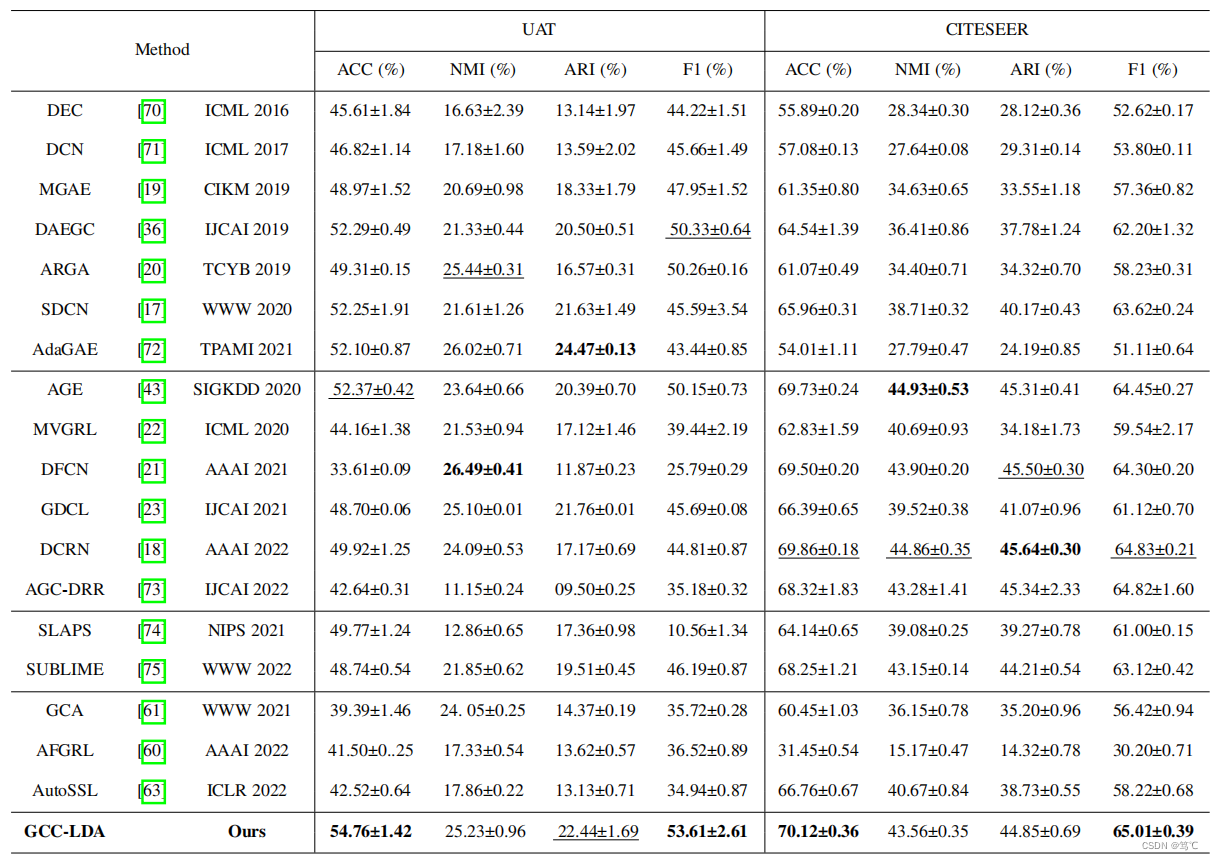
6. 总结
论文提出了一种可学习的图对比聚类的增强方法,称为GCC-LDA。
- 模型设计了一个完全可学习的增强,用结构增强和属性增强分别动态学习结构和属性信息。
- 还设计了一种对抗性机制,在潜在空间中保持交叉视图的一致性,同时确保增强视图的多样性。
- 同时还提出了一种两阶段的训练策略,以在模型训练过程中获得更可靠的聚类信息。得益于聚类信息,我们用高置信度的伪标签矩阵来细化学习到的结构。
- 此外,模型利用交叉视图样本相似度矩阵对增广视图进行了改良,以进一步提高所学习结构的判别能力。
















 1898
1898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











