







数学建模萌新学习笔记(实例:基于数据挖掘的财政分析和经济发展策略的模型)
针对变量关系研究方法,包括了相关关系研究以及影响关系研究,大致将常用分析方法归纳为:相关分析,线性回归分析,Logistic回归分析,SEM结构方程
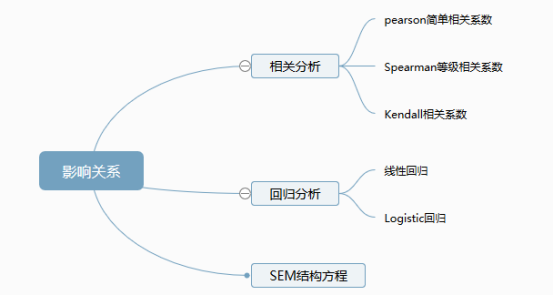
1.相关性检验
为何要进行相关性检验
1.目的主要是观察各自变量和Y是否存在非线性关系。比如对于某个x,明显观察到它和y的散点图是一条抛物线。这种情况下需要把平方项加进来。这种情况下,如果事先没有观察,就会导致遗漏变量
2.相关分析还有一个目的,可以查看一下 自变量之间的共线性程度如何,如果自变量间的相关性非常大,可能表示存在共线性。(*自相关,本组建模缺乏考虑的)
在做回归分析之前为什么要做相关性检验。明明作了相关性检验之后不管结果如何都要全做回归分析的啊。_百度知道 (baidu.com)
2.相关性系数
皮尔逊相关系数与皮尔曼相关系数
两种相关系数的比较
皮尔逊相关系数:

皮尔曼相关系数:
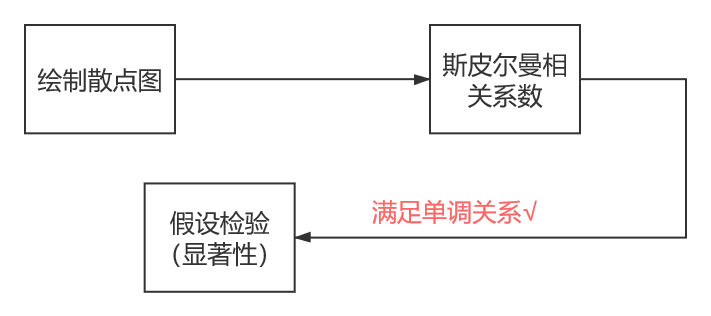
斯皮尔曼相关系数和皮尔逊相关系数选择:
1.连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用spearman相关系数也可以, 就是效率没有pearson相关系数高。
2.上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
3.两个定序数据之间也用spearman相关系数,不能用pearson相关系数。
注:(1)定序数据是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。
eg. 优良差用123表示,加减乘除没有意义。定序数据最重要的意义代表了一组数据中的某种逻辑顺序
(2)斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用
皮尔逊、斯皮尔曼、肯德尔相关系数介绍及其在特征选择中的应用 - 知乎 (zhihu.com)
相关性模型 之 皮尔逊相关系数与斯皮尔曼相关系数_iMoriarty的博客-CSDN博客_斯皮尔曼相关系数和皮尔森相关系数
实战:
1相关系数的判断



根据皮尔逊检测的规定显著性小于0.05说明具有相关性
2.逐步回归分析
结果:

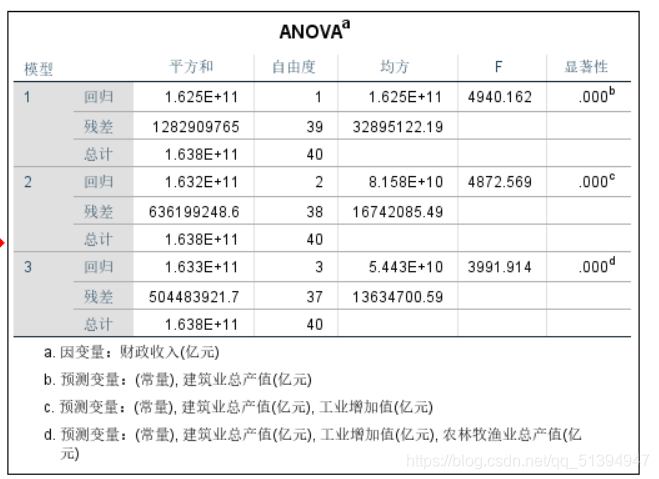
两个表主要说明了各模型的拟合情况
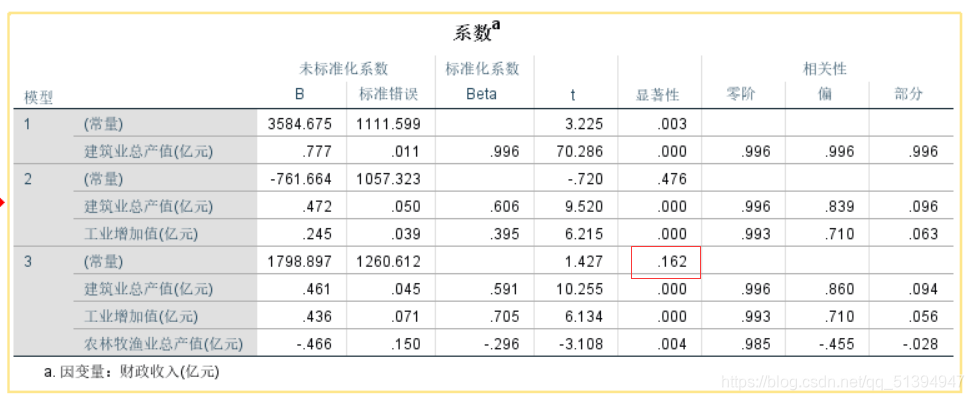
常数显著性过大,应当建立没有常数项的线性回归模型
结果如下:

得出模型为:y=0.436x1+0.404x2-0.326x3
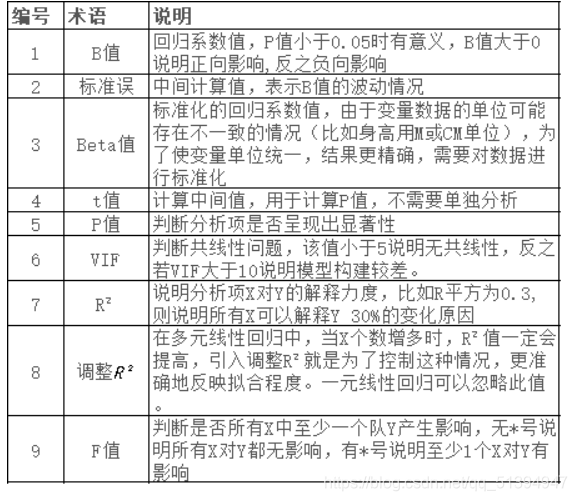
对于数据中字母的解读:
平方和(SS)、自由度(df)、均方(MS)、F(F统计量)、显著性(P值)五大指标。
SS表示均值偏差的平方和和数据的总变化量。
F是F的值,F是方差分析得到的统计量,用来检验回归方程是否显著。
DF表示自由度,自由度是在计算某一测量系统时不受限制的变量数
MS代表均方,其值等于对应的SS除以DF。
1.R:0.996,为高度正相关关系。
R方:判定系数 R²,也称为拟合优度或决定系数,即相关系数R的平方,用于表示拟合得到的模型能解释因变量变化的百分比,R² 越接近1,表示回归模型拟合效果越好,如果R² = 0.666,模型效果一般,也可以接受。
调整后R方:用于修正自变量个数的增加而导致模型拟合效果过高的情况,多用于衡量多重性回归分析模型的拟合效果。
标准估算的错误:大小反映了建立的模型预测因变量时的精度,在对比多个回归模型的拟合效果时,通常会比较该指标,调整后的R方越小,说明拟合效果越好。
2.均方误差=SS/df
3.显著性(P值)是在显著性水平α(常用取值0.01或0.05)下F的临界值,一般我们以此来衡量检验结果是否具有显著性;
显著性(P值)>0.05,不具有统计学意义;
0.01< 显著性(P值)<= 0.05,具有显著性统计学意义;
显著性(P值)<= 0.01,具有极其显著的统计学意义。

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









