






文章目录
Abstract
2018年的讽刺检测综述,迄今为止(到2018年)研究中的三个里程碑:通过半监督模式提取来识别隐含情感、使用基于标签的监督以及使用目标文本以外的上下文。
文章介绍讽刺检测的数据集、方法、趋势和问题,并提供了一个表格,该表格从特征、注释技术、数据形式等不同维度总结了以往的论文
文章安排:第 2 节首先介绍了语言学中的讽刺研究。然后,第 3 节介绍了讽刺检测的不同问题定义。第 4 节和第 5 节分别讨论了数据集和已报道的讽刺语言检测方法。第 7 节强调了讽刺语言检测的发展趋势,第 8 节讨论了反复出现的问题。第 9 节是本文的结论。
2 语言学
从语言学角度介绍讽刺研究,提出了几种讽刺的表述方式和分类标准
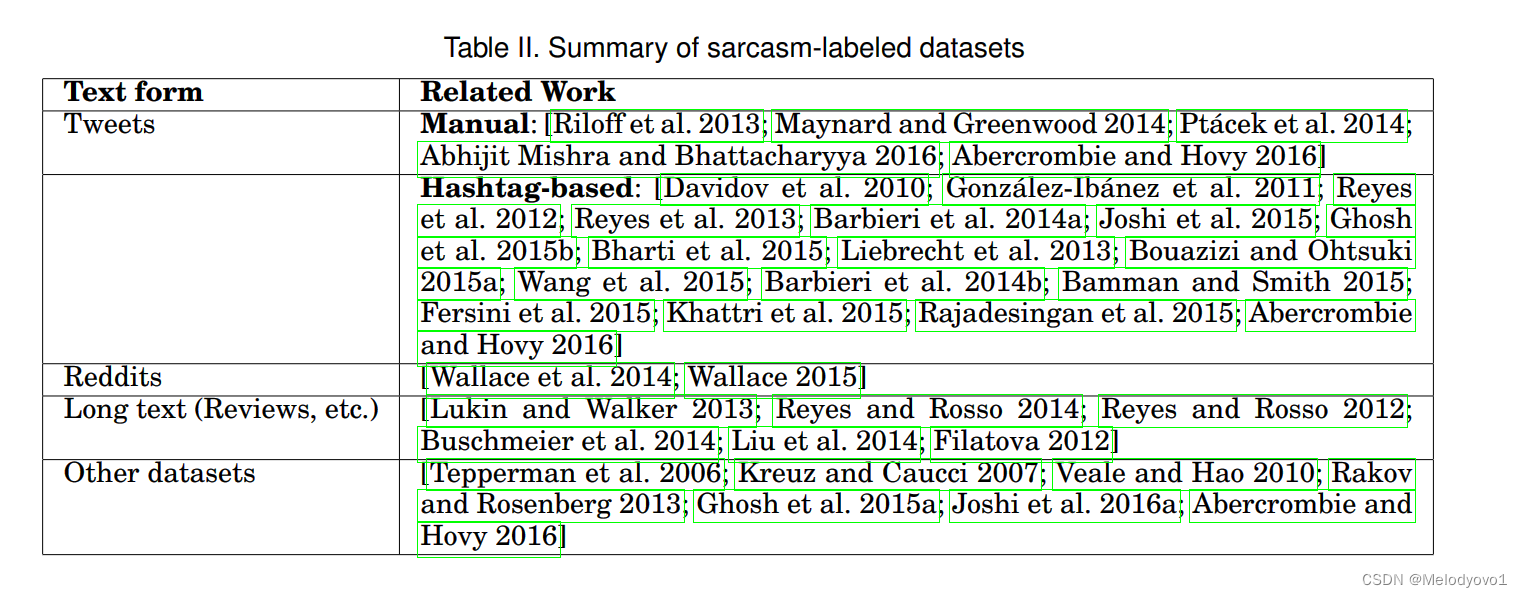
4 数据集
分为三类:短文本(通常以噪音和长度受平台限制的情况为特征,如推文)、长文本(如论坛帖子)和其他数据集。
5 检测方法
5.1基于规则的方法
基于规则的方法试图通过具体证据来识别讽刺,这些证据通过依赖于讽刺指标的规则来捕捉。也就是通过指定相应的规则比如识别给定的比喻,形如 “as a” 。
基于规则的方法太古老
5.2 基于统计的方法
包括特征和学习算法两个方面
5.2.1 使用特征
讨论了用于统计方法中的讽刺检测特征。这一节总结了不同研究报告中使用的特征集合,包括:
- Tsur等人在2010年设计了基于模式的特征,用以指示文本中存在的辨别性模式。
- González-Ibáñez等人在2011年使用了基于情感词典的特征,同时还包括了基于语用学的特征,如表情符号和用户提及。
- Reyes等人在2012年引入了与歧义、意外、情感场景等相关的特征。
- Riloff等人在2013年使用了一系列模式作为特征,这些模式包括正面动词和负面情境词组。
- Liebrecht等人在2013年引入了bigram和trigram作为特征。
- Reyes等人在2013年探索了基于skip-gram和字符n-gram的特征。
- Maynard和Greenwood在2014年包括了一些基于形容词和副词强度、词的同义词和同义词集数量等的特征。
- Barbieri等人在2014年使用了词频、稀有词数量等特征。
- Joshi等人在2015年使用了基于不协调理论的特征,分为隐性不协调和显性不协调两类。
- Rajadesingan等人在2015年使用了基于可读性、词的变形、标点等特征。
- Abhijit Mishra和Bhattacharyya在2016年基于眼动实验设计了认知特征。
- 其他研究还使用了基于单词嵌入相似性的特征。
这些特征为讽刺检测任务提供了丰富多样的信息,有助于统计模型捕捉文本中的讽刺表达。
5.2.2 学习算法
统计学习算法:
- 支持向量机(SVM):许多研究使用SVM作为讽刺检测的分类器,它在此任务中表现出良好的性能。
- 逻辑回归(Logistic Regression):González-Ibáñez等人在2011年使用SVM与逻辑回归,并使用卡方检验来选择区分性特征。
- 朴素贝叶斯(Naive Bayes):Reyes和Rosso在2012年比较了朴素贝叶斯和支持向量机两种分类器。
- 决策树(Decision Tree):Reyes等人在2013年使用朴素贝叶斯和决策树来进行多标签分类。
- 平衡Winnow算法(Balanced Winnow):Liebrecht等人在2013年使用了平衡Winnow算法来识别高评分特征。
- 支持向量机隐马尔可夫模型(SVM-HMM):Wang等人在2015年使用了SVM-HMM来建模对话中的序列输出标签。
- 序列标注算法:Joshi等人在2016年实验验证了在对话数据上,序列标注算法比分类算法表现更好,他们使用了SVM-HMM和SEARN作为序列标注算法。
- 其他分类算法:Liu等人在2014年比较了几种分类方法,包括Bagging、Boosting等。
这些算法为讽刺检测提供了不同的建模视角,丰富了统计方法的研究内容。
5.3 深度学习算法
- 基于词向量相似性:Joshi等人在2016年使用词向量之间的相似性作为特征,并引入了词向量相似性特征的增强,以提高检测效果。
- 基于卷积神经网络:Silvio Amir等人在2016年提出了一个基于卷积神经网络的模型,该模型可以学习用户嵌入和语句嵌入,以捕获用户特定上下文信息。
- 基于组合模型:Ghosh和Veale在2016年使用了卷积神经网络、LSTM和DNN的组合模型,并展示了在讽刺检测任务中相较于递归SVM的改进。
7.1 讽刺模式
发现讽刺模式,并将这些模式用作特征,其实也就是作为统计学习方法的特征来实现检测任务
讽刺模式是指能够表明文本中隐含讽刺倾向或情感倾向的词汇、语法、语义模式。这些模式通常可以从已标注的讽刺句子中自动学习得到。讽刺模式包括以下几类:
- 正面动词+负面情境词组:正面动词和负面情境词组的组合可能表示讽刺。例如,“excellent”和“completely broke”。
- 对比性结构:通过对比或转折关系来表达讽刺意图,例如,“very helpful (but) cost a fortune”。
- 正面形容词+负面实体:正面形容词和负面实体的组合也可能表示讽刺,例如,“amazingly dumb”。
- 反讽结构:使用反问、否定等结构表达讽刺意图。
- 情感反差:正面情感和负面情境之间的反差,例如,“I’m so happy about the traffic jam”。
- 夸张或矛盾:通过夸张或矛盾的表达手法来传达讽刺。
这些模式通常包含词汇、语法和语义层面的信息,可以被自动提取并作为统计分类器的特征,以辅助检测文本中的讽刺。
7.2 上下文
- 作者特定上下文:通过分析作者的历史推文,使用作者的历史情绪来预测推文是否是讽刺意义。有研究者还使用不同维度的特征,包括使用关于作者对 Twitter 的熟悉程度(就主题标签的使用而言)、对语言的熟悉程度(就单词和结构而言)以及对讽刺的熟悉程度的特征,还有考虑作者背景特征的这些特征都可以作为用户嵌入
- 对话上下文:上下文文本特征,考虑对话结构
- 话题语境:某些话题更容易引发讽刺,比如政治话题就比环境话题更具讽刺
8 问题
8.1 节主要讨论了与数据相关的问题。这些问题包括基于hashtag的监督所带来的数据质量问题,数据不平衡问题以及标注者之间的不一致性。其中,基于hashtag监督的数据集质量可能存在疑问,尤其是当使用#not等hashtag来表示不真诚的情感时。数据不平衡问题指的是讽刺现象出现的频率较低,这在数据集中也有所体现。此外,由于讽刺的主观性,标注者之间的一致性差异较大,从0.34到0.81不等。针对这些问题,一些研究采用了多种数据集验证、深度学习等技术来缓解。
8.2 节主要探讨了将情感作为特征的问题。一些研究将表面情感作为特征输入讽刺检测分类器,但这种做法存在争议,因为表面情感与讽刺之间的关系尚不清楚。表面情感指的是句子的表面极性,一些研究利用了这种特征。然而,表面情感是否真的有助于提高讽刺检测的效果还有待进一步验证。
8.3 节主要讨论了处理数据倾斜问题。由于讽刺现象出现的频率较低,这导致了数据集中的倾斜。一些研究采用了不同的方法来处理这个问题,例如使用集成学习和多数投票的方法,使用SVM-perf进行F1优化,使用L1正则化来稀疏化上下文特征,以及使用AUC作为评价指标等。这些方法可以更好地处理数据倾斜问题,提高讽刺检测的效果。

















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









