






1.主机配置
显卡:4070d,12G显存
内存:32G
CPU:i5-12600kf
此时部署deepseek r1,14b的模型,GPU利用率可以达到94%,并且几乎无延迟。
2.下载安装
1.安装ollama
ollama官方网址:ollama官网
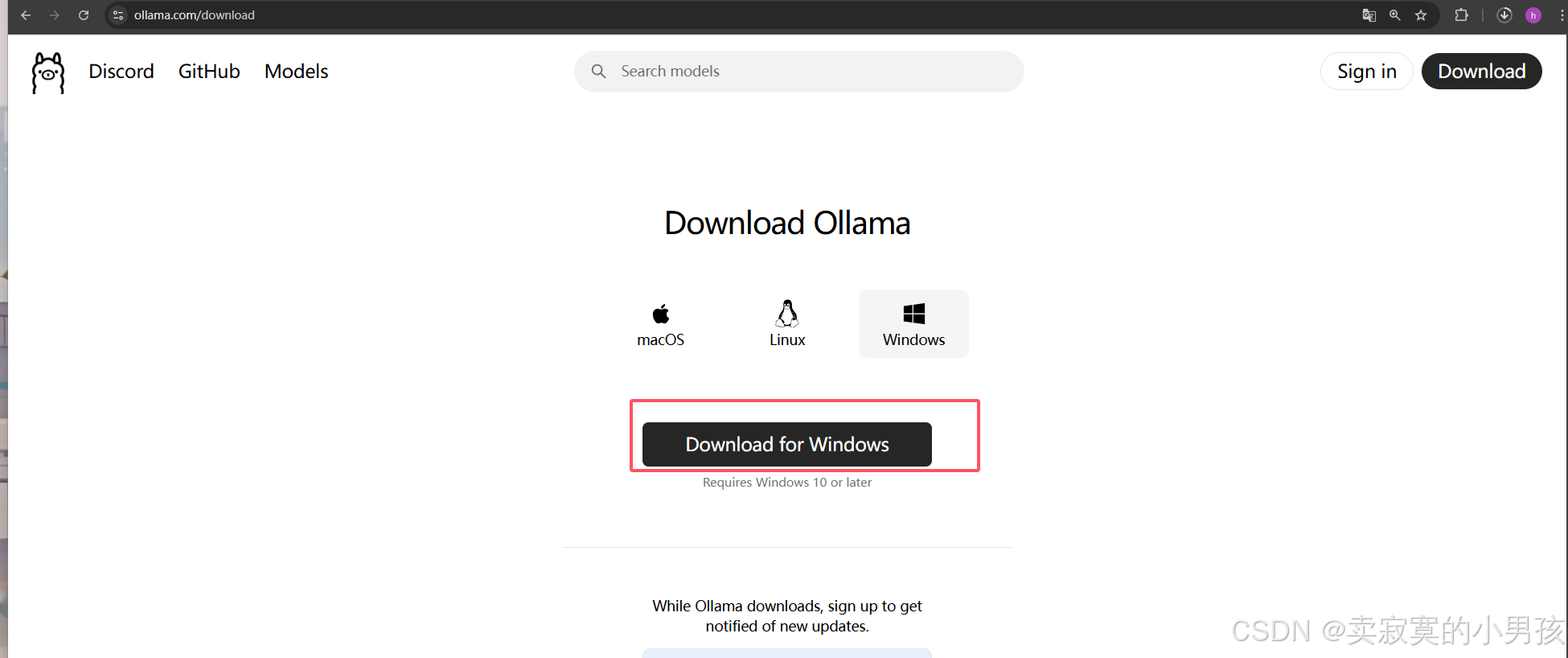
由于ollama默认安装地址为C盘,对于我这种强迫症患者很不友好,因此使用命令行安装:

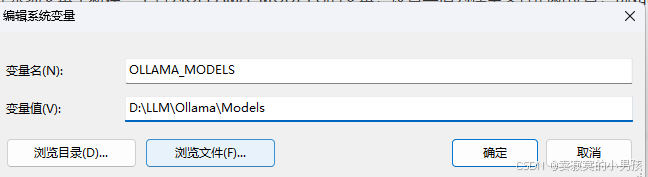
使用命令行参数安装后,还需要修改模型安装的环境变量,否则模型也会默认被安装到C盘,在系统环境变量中添加指定模型安装的位置。
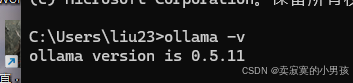
安装成功的标志为在终端执行ollama -v可以显示版本号。
2.安装模型
安装模型也是一键式安装,还是在ollama官网:
deepseek r1模型地址:deepseek r1
注意要按自己电脑的显存选择模型,12G显存推荐14b,32b的GPU利用率会很低(显存会被打满,并且内存会占10G左右),并且非常卡顿。如果有20G的4090推荐使用32b的
ps:b表示模型参数规模,b为billion的首字母,参数越多,模型效果越好。

安装成功界面:

3.使用界面
3.1 终端使用
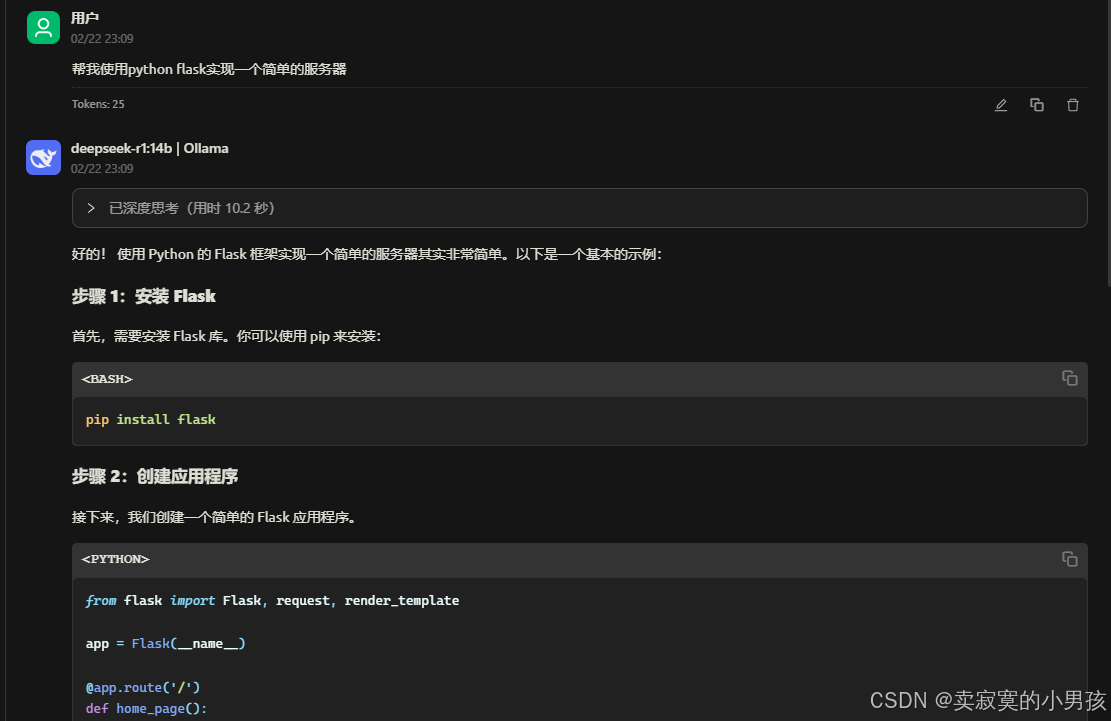
其实直接在终端输入就可以了,可以看到,啪的一下,很快啊,就写完了。

3.2 cherryai(客户端使用)
cherry是一个开源的与大模型相关的客户端,可以调ollama的api。
cherryai官网:cherryai
安装后打开,点击设置->Ollama->管理,选择本地的deepseek-r1,添加即可完成。
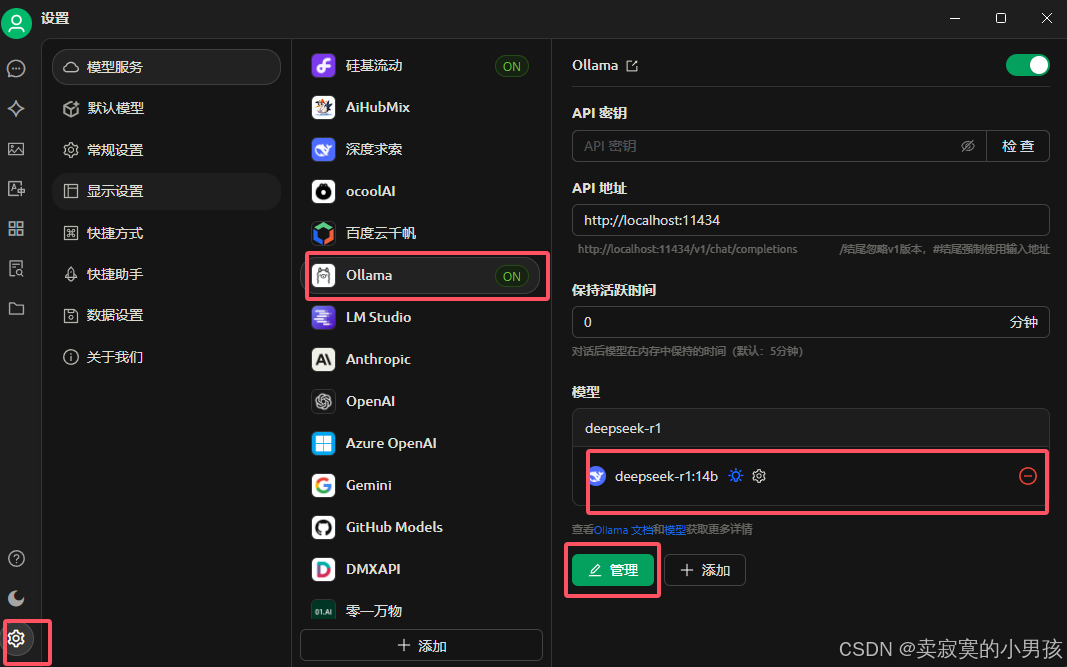
这样就可以在客户端使用deepseek r1了。生成速度也非常的快。
并且可以看到,当在使用模型时,GPU利用率已经达到了94%,非常的完美。



















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











