







通过前面2小节的学习,我们配好了环境,准备了数据。现在开始你的训练之旅~~
同 V1 一样,一行命令搞定你的数据预处理,训练和测试!!
step1: 一行命令数据预处理
使用命令: nnUNetv2_plan_and_preprocess
注意: v2 版本的命令,都是以 nnUNetv2开头
nnUNetv2_plan_and_preprocess -h 可查看使用帮助
nnUNetv2_plan_and_preprocess -d 131(你的数据ID) --verify_dataset_integrity
数据预处理好后,会放在 nnUNet_preprocessed>Datasetxxx_xxx里面
step2: 一行命令开始训练
使用 nnUNetv2_train 命令进行模型训练。命令的一般结构如下:
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD [其他选项,参见 -h]
eg: nnUNetv2_train 131 3d_fullres 1 (表示使用131这个数据集,模型用3d_fullres,训练第一折)
- UNET_CONFIGURATION: 用于标识所需的 U-Net 配置(defaults: 2d, 3d_fullres, 3d_lowres, 3d_cascade_lowres)。
- DATASET_NAME_OR_ID: 指定应在其上训练的数据集,
- FOLD 则指定要训练的 5 折交叉验证中的哪一个折数,0-4表示单个折数,all和5表示5折一起训练。
请注意,并非所有 U-Net 配置都适用于所有数据集。在图像尺寸较小的数据集中,级联 U-Net(以及其中的3D低分辨率配置)会被省略,因为全分辨率 U-Net 的裁剪大小已经涵盖了输入图像的大部分内容。
nnU-Net会每50个epochs存储一次 checkpoint。如果需要继续之前的训练,请将训练命令中添加 --c 参数。
nnUNetv2_train 131 3d_fullres 1 --c
重要提示:如果您计划使用 nnUNetv2_find_best_configuration,请添加 --npz 标记。这会让 nnU-Net 在最终验证期间保存 softmax 输出。它们是必需的。导出的 softmax 预测非常大,因此可能占用大量磁盘空间,因此默认情况下不启用此功能。如果您最初没有使用 --npz 标记运行,但现在需要 softmax 预测,请使用以下命令重新运行验证:
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD --val --npz
您可以通过使用 -device DEVICE 来指定 nnU-Net 应使用的设备。DEVICE 只能是 cpu、cuda 或 mps。如果您有多个 GPU,请使用 CUDA_VISIBLE_DEVICES=X nnUNetv2_train [...] 来选择 GPU ID(需要设备为 cuda)。
有关其他选项,请参阅 nnUNetv2_train -h。
2D U-Net
对于 FOLD 在 [0, 1, 2, 3, 4] 中,运行:
nnUNetv2_train DATASET_NAME_OR_ID 2d FOLD [--npz]
3D 全分辨率 U-Net
对于 FOLD 在 [0, 1, 2, 3, 4] 中,运行:
nnUNetv2_train DATASET_NAME_OR_ID 3d_fullres FOLD [--npz]
3D U-Net 级联
3D 低分辨率 U-Net
对于 FOLD 在 [0, 1, 2, 3, 4] 中,运行:
nnUNetv2_train DATASET_NAME_OR_ID 3d_lowres FOLD [--npz]
3D 全分辨率 U-Net
对于 FOLD 在 [0, 1, 2, 3, 4] 中,运行:
nnUNetv2_train DATASET_NAME_OR_ID 3d_cascade_fullres FOLD [--npz]
请注意级联的 3D 全分辨率 U-Net 需要已完成低分辨率 U-Net 的五个折数!
训练的模型将被写入到nnUNet_results文件夹中。每次训练都会生成一个自动生成的输出文件夹名称:
nnUNet_results/DatasetXXX_MYNAME/TRAINER_CLASS_NAME__PLANS_NAME__CONFIGURATION/FOLD
例如,对于从MSD中获取的Dataset002_Heart数据集,文件结构如下:
nnUNet_results/
├── Dataset002_Heart
│ ├── nnUNetTrainer__nnUNetPlans__2d
│ │ ├── fold_0
│ │ ├── fold_1
│ │ ├── fold_2
│ │ ├── fold_3
│ │ ├── fold_4
│ │ ├── dataset.json
│ │ ├── dataset_fingerprint.json
│ │ └── plans.json
│ └── nnUNetTrainer__nnUNetPlans__3d_fullres
│ ├── fold_0
│ ├── fold_1
│ ├── fold_2
│ ├── fold_3
│ ├── fold_4
│ ├── dataset.json
│ ├── dataset_fingerprint.json
│ └── plans.json
请注意,在这里不存在3d_lowres和3d_cascade_fullres,因为这个数据集没有触发级联。在每个模型训练的输出文件夹(每个fold_x文件夹)中,将创建以下文件:
- debug.json:包含用于训练该模型的蓝图和推断参数的摘要,以及其他一些有用但不易阅读的信息,用于调试。
- checkpoint_best.pth:在训练过程中识别出的最佳模型的检查点文件。除非您显式告诉nnU-Net使用它,否则目前不会使用它。
- checkpoint_final.pth:最终模型的检查点文件(训练结束后)。这是用于验证和推断的模型。
- network_architecture.pdf(仅在安装了hiddenlayer时可用!):一个带有网络架构图的PDF文档。
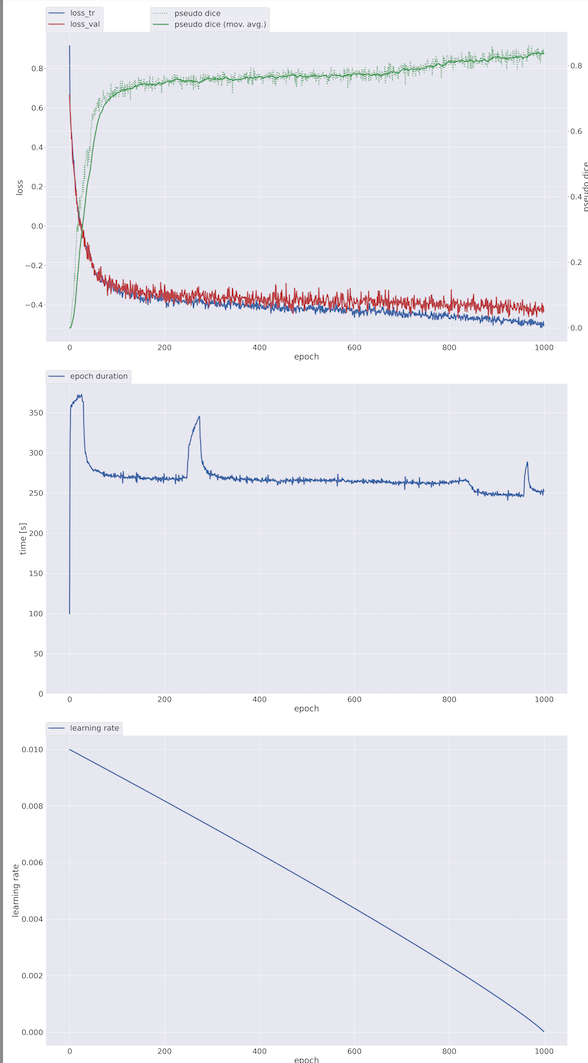
- progress.png:显示训练过程中的loss、Dice系数、学习率和epoch时间。
自动确定最佳配置
一旦所需的配置经过训练(完全5折交叉验证),您就可以告诉 nnU-Net 自动识别最适合您的组合:
nnUNetv2_find_best_configuration DATASET_NAME_OR_ID -c CONFIGURATIONS
具体详见官网,因为我没有完成5折训练,无法进行实验。
step3:一行命令进行推理/预测
nnUNetv2_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -d DATASET_NAME_OR_ID -c CONFIGURATION --save_probabilities
# nnUNetv2_predict -h 查看更多参数解析
- INPUT_FOLDER: 测试数据地址
- OUTPUT_FOLDER: 分割数据存放地址
- CONFIGURATION: 使用的什么架构,
2d or 3d_fullres or 3d_cascade_fullres等,这里训练用的什么就写什么 - save_probabilities:将预测概率与需要大量磁盘空间的预测分段掩码一起保存。
默认情况下,推理将通过交叉验证的所有 5 个折叠作为一个整体来完成(根据5个模型得到一个结果)。我们强烈建议您使用全部 5 折。因此,在运行推理之前必须训练所有 5 个折叠。
要想每个模型分开得到结果,就加参数-f all,或者只为某一折出结果,就加参数-f 1(得到 fold 1 的结果)
举例:得到fold 1 的推理结果
nnUNetv2_predict -i ${nnUNet_raw}/Dataset131_WORD/ImagesTs -o output -d 131 -c 3d_fullres -f 1
# ${nnUNet_raw} 之前设置的环境变量,nnUNet_raw的地址,不会这种方法,可以直接把文件夹的绝对路径写出来
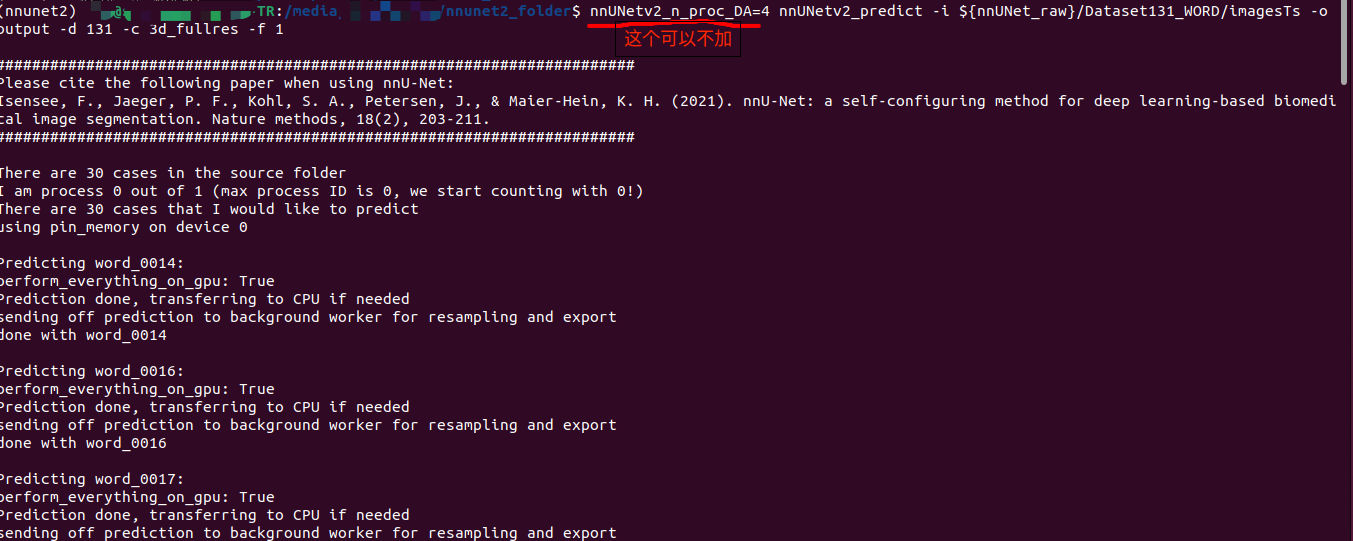
正确推理后终端显示如上,在output文件夹中会出现每个case的分割结果(nii.gz格式)
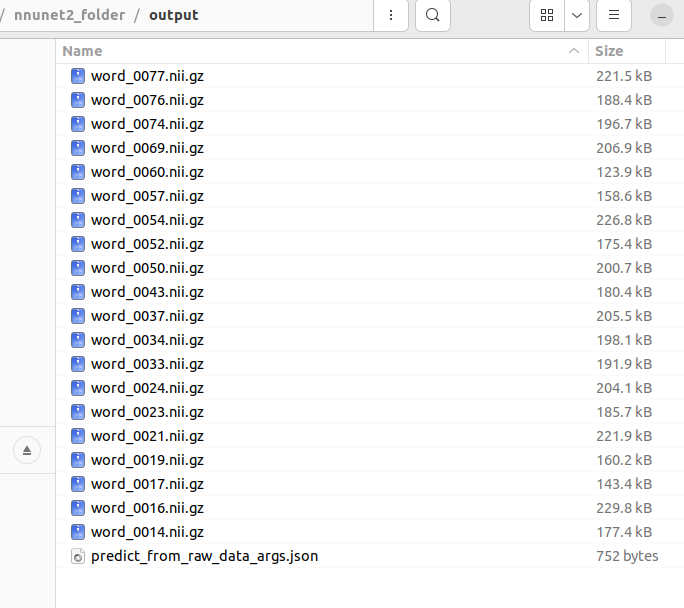
注意,他不会直接得到每个case的dice值等相关分割指标

在之前的文章中,早就分享过各类指标的求法啦。只需要动动小指,按一下 ctrl+c, 在ctrl+v, 再改一下数据地址。就能得到每个case的指标, 如下图所示
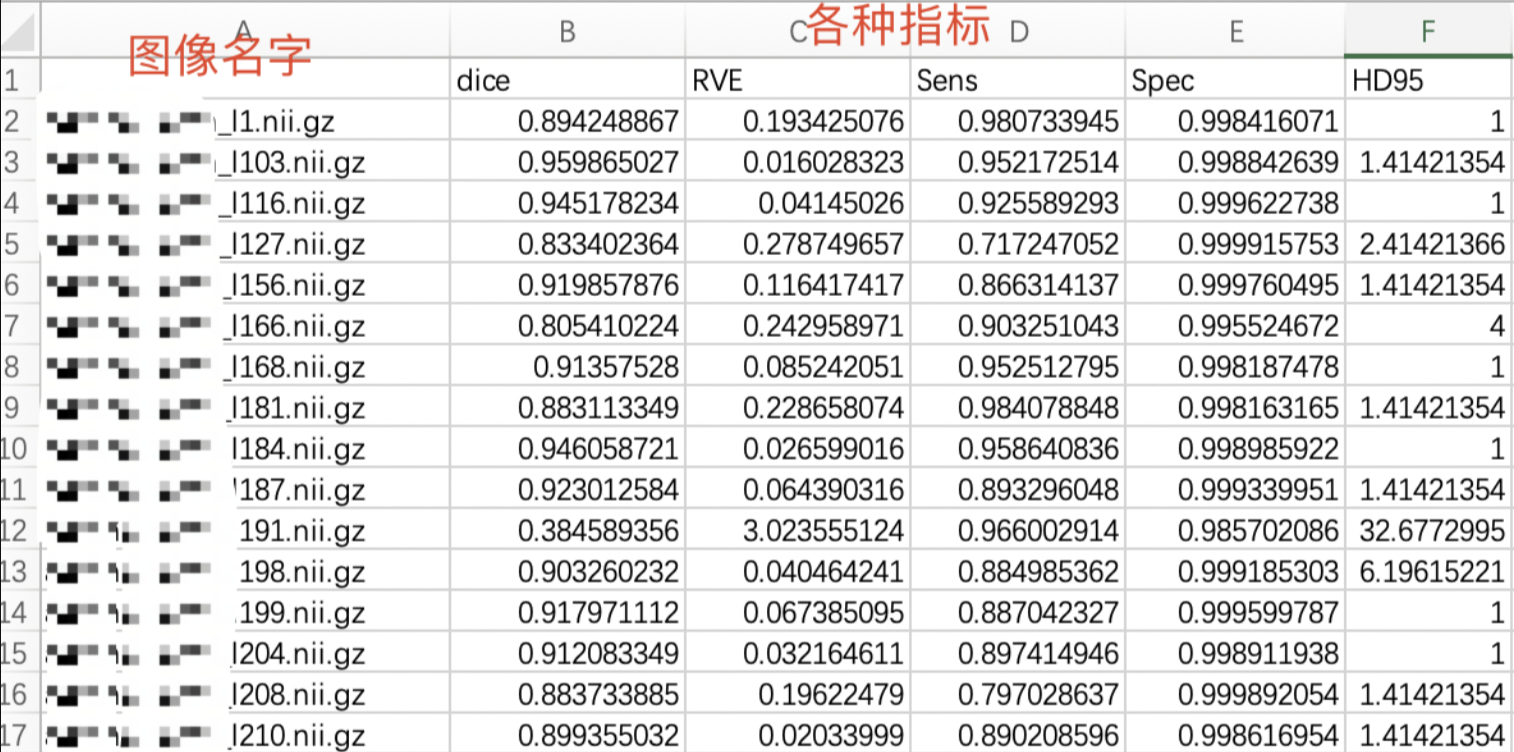
查看之前的文章链接【理论+实践】史上最全-论文中常用的图像分割评价指标-附完整代码
还没完!
这只是得到了每个case的指标,那整体的指标计算呢, 下面一招,直接得到论文结果!
查看之前的文章链接 如何用excel快速实现“平均值±标准差”
nnunet v1 和 v2 分割结果比较
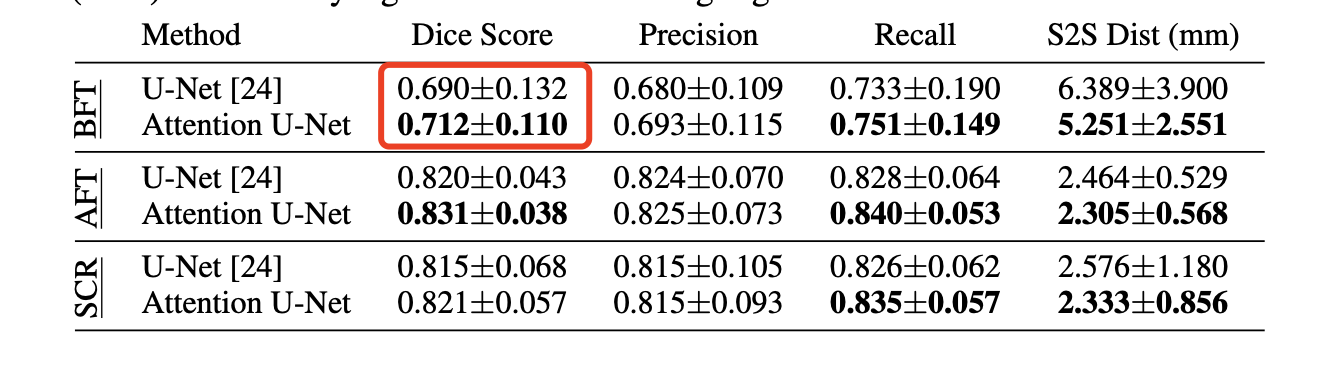
论文里面,数据集WORD腹部16个器官的v1和v2结果比较,相差是不大的
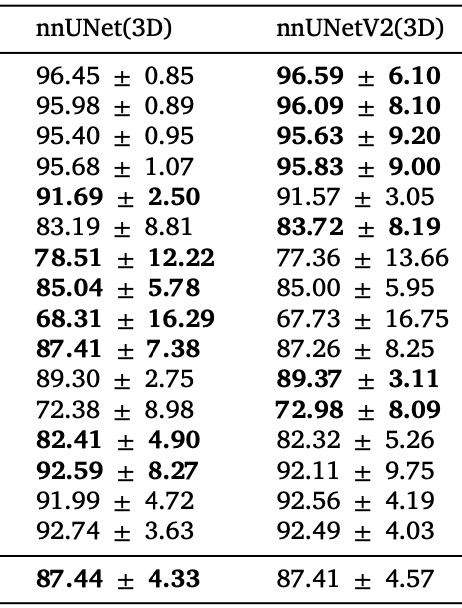
我在该数据集上也跑了一遍,由于时间关系,只跑了一折。

至于哪个版本结果最好,我想应该是没有统一答案的。如果你追求一个最好的指标,高0.01也是高,那我就建议两个版本都跑,每个模型都跑,5折全跑。all in,最后再来筛选。

文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连



















 1626
1626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











