







目录
摘要
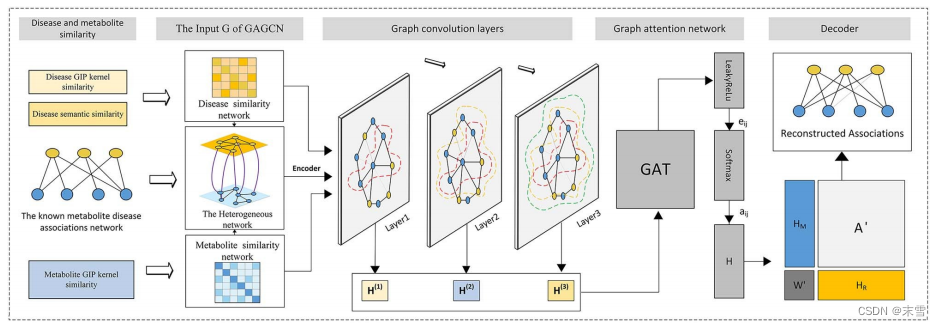
提出一种新的深度学习算法,名为图卷积网络与图注意力网络(GCNAT),用于预测疾病相关代谢物的潜在关联。首先,根据已知代谢物与疾病的关联,代谢物与代谢物的相似性以及疾病的相似性构建一个异构网络。代谢物和疾病特征通过图卷积神经网络进行编码和学习。然后,使用图注意层来组合多个卷积层的嵌入,并计算相应的注意系数,为每个层的嵌入分配不同的权重。然后,通过对最终合成嵌入信息进行解码和评分来获得预测结果。
数据集
人类代谢组学数据库(Human Metabolomics Database,HMDB,http://hmdb.ca/)。从HMDB数据库获取代谢物与疾病的相关性,包括DOID与HMDB和关联信息。
疾病MeSH描述符从美国国家医学图书馆MeSH数据库获取,(https://meshb.nim.nih.gov/)。
相似性计算
1、疾病综合相似性
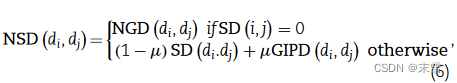
(1)疾病语义相似性
用疾病的医学主题词表(MeSH)描述符来构建有向无环图(DAG),000 00
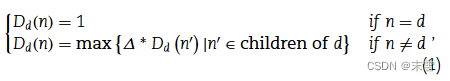 0
0
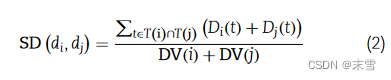
(2)疾病高斯核相似性
构建代谢物与疾病相关性的邻接矩阵作为输入 ,疾病间高斯核相似性网络GIPD公式:
![]()
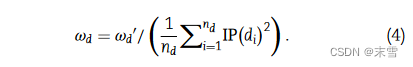
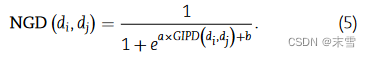
2、代谢物高斯核相似性
与疾病类似。
GCNAT
使用疾病综合相似性矩阵NSD,代谢物高斯核相似性矩阵GIPM,代谢物与疾病相关性矩阵构建异构网络。作为GCN的输入。
代码和数据集
https://github.com/zhaoqi106/GCNAT
以往的方法及文献
1、随机漫步(RWR),采用重启随机漫步法。
Hu Y, Zhao T, Zhang N, et al. Identifying diseases-related metabolites using random walk. BMC Bioinform 2018;19(Suppl 5):116.
2、网络测量方法(KATZ),通过测量节点之间行走的次数和长度来预测代谢物与疾病的相关性。
Lei X, Zhang C. Predicting metabolite-disease associations based on KATZ model. BioData Min 2019;12:19.
3、网页排名算法(PageRank),通过计算相关性排序。
Yates EJ, Dixon LC. PageRank as a method to rank biomedical literature by importance. Source Code Biol Med 2015; 10:16.
4、DNN采用DNN结构,利用更多的训练数据改进学习过程。
Hinton GE, Salakhutdinov RRJS. Reducing the dimensionality of data with neural networks. SCIENCE 313(5786): 504–7.
5、EKRRMDA提出一种核岭回归方法来预测。
Peng LH, Zhou LQ, Chen X, et al. A computational study of potential miRNA-disease association inference based on ensemble learning and kernel ridge regression. Front Bioeng Biotechnol 2020;8:40.
















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









