







DeCLIP:supervision exists everywhere:a data efficient contrastive language-image pre-training paradigm
贡献:
-
论文是为了充分利用单模态和多模态,充分利用单模态特征用自监督(SIMSAM和MLM),多模态用图像文本对比学习实现;
-
一个图片的文本描述大部分都是集中在局部区域,作者使用RRC得到一个图像的局部区域进行实现;
-
一个图片有多种描述方式,提出用最近邻文本检索得到更多文本监督。(i.e.,对图像的文本描述1的特征向量在队列库中求余弦相似性得到最相似的描述2)
在SLIP基础上新增一个文本域的自监督,即该论文使用图片自监督+文本自监督+两倍图像-三倍文本对的对比学习。
模型
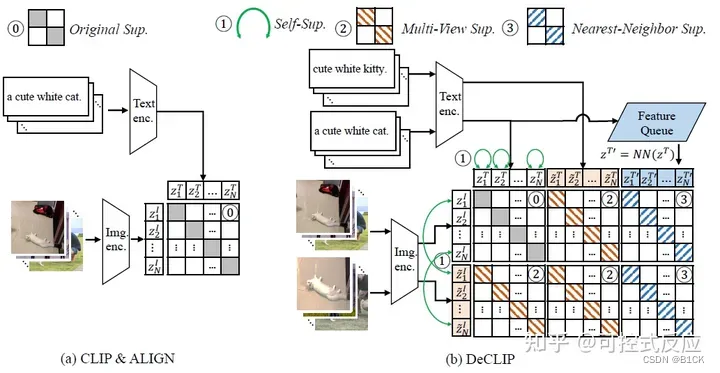
- 图像自监督框架:SimSam
- 文本自监督框架:MLM,每个句子中随机选择15%的单词,然后,80%的时间用【mask】替换单词,用10%的时间用随机token替换单词,用10%的时间不改变单词。最后得到语言模型对应的token域原始token进行交叉熵loss。
- 图像-文本模态:原始的 CLIP 不使用文本增强,仅使用随机方形裁剪图像增强,因此需要大量数据。deCLIP使用随机数据增强,相比于原始CLIP,该论文监督信息更多。
- 在嵌入空间中(具体来说是64K大小的队列)使用了Nearest-Neighbor获得相似性的文本信息。即,论文维护一个队列,在嵌入空间中使用最近邻检索得到一个最相似的文本描述。(隐式存在一对多,提供更好的监督信号,BLIP)
图片里灰色是原本的对比学习,绿的是自监督,橙色也是对比学习,蓝色是Nearest-Neighbor Supervision获得的最相似的文本和两个图片进行对比学习
总损失函数:
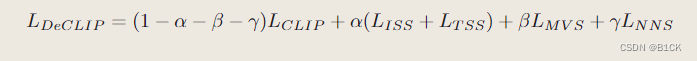
ref
https://zhuanlan.zhihu.com/p/585778761















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









