







Abstract
迄今为止,精度最高的对象检测器是基于R-CNN推广的两阶段方法,其中分类器应用于候选对象位置的稀疏集。相比之下,应用于可能的物体位置的常规、密集采样的一期探测器具有更快、更简单的潜力,但迄今为止的精度落后于两级探测器的精度。在本文中,我们研究了为什么会出现这种情况。我们发现在密集探测器训练过程中遇到的极端前景-背景类不平衡是中心原因。我们建议通过重塑标准交叉熵损失来解决这类不平衡,从而降低分配给分类良好的例子的损失。我们的新焦点损失集中训练在一个稀疏的难样本子集,并防止大量容易的负样本在训练期间压倒检测器。为了评估我们的损失的有效性,我们设计并训练了一个简单的密集探测器,我们称之为RetinaNet。我们的结果表明,当使用焦点损失训练时,视网膜网能够匹配以前的一级探测器的速度,同时超过了所有精确的精度。代码在:https://github.com/facebookresearch/Detectron.
1. Introduction
目前最先进的目标探测器是基于一个两阶段的,提案驱动的机制。正如在R-CNN框架[11]中推广的那样,第一阶段生成一个稀疏的候选对象位置集,第二阶段使用卷积神经网络将每个候选位置分类为前景类之一或背景类。通过一系列先进的[10,28,20,14],这个两阶段框架在具有挑战性的COCO基准[21]上始终达到最高的精度。
尽管两级探测器取得了成功,但一个自然要问的问题是:一个简单的单级探测器也能达到类似的精度吗?一个阶段探测器应用于物体位置、尺度和高宽比的常规密集采样。最近在单级探测器上的工作,如YOLO[26,27]和SSD[22,9],显示出了有希望的结果,与最先进的两阶段方法相比,可以产生更快的探测器,精度在10-40%范围内。
本文进一步推动了包括:我们提出了一个监视对象探测器,它首次与更复杂的两级探测器的最先进的COCO AP相匹配,如特征金字塔网络(FPN)[20]或Faster R-CNN[28]的Mask R-CNN[14]变体。为了实现这一结果,我们将训练过程中的类不平衡确定为阻碍一级检测器实现最先进的精度的主要障碍,并提出了一种新的损失函数来消除这一障碍。
类不平衡在类似r-cnn的检测器中通过两级级联和采样启发式来解决。建议阶段(例如,选择性搜索[35],边框[39],DeepMask[24,25],RPN[28])迅速将候选对象位置的数量缩小到一个小数目(例如,1-2k),过滤掉大多数背景样本。在第二个分类阶段,执行采样启发式方法,如固定的前景与背景比(1:3),或在线硬示例挖掘(OHEM)[31],以保持前景与背景之间可管理的平衡。
相比之下,一级探测器必须处理更大的定期采样的候选对象位置。在实践中,这通常相当于枚举密集覆盖空间位置、尺度和高宽比的∼100k位置。虽然类似的抽样启发式也可以应用,但它们是效率低下的,因为训练过程仍然由容易分类的背景例子所主导。这种低效率是目标检测中的一个经典问题,通常通过诸如自举[33,29]或硬示例挖掘[37,8,31]等技术来解决。
在本文中,我们提出了一个新的损失函数,作为一个更有效的替代方法来处理以前的类不平衡。损失函数是一个动态缩放的交叉熵损失,随着对正确类的置信度的增加,缩放因子衰减为零,见图1。直观地说,这个缩放因子可以在训练过程中自动降低简单例子的贡献,并迅速地将模型集中在硬例子上。实验表明,我们提出的焦点损失使我们能够训练一个高精度的单级检测器,显著优于采样启发式或硬示例挖掘的替代方法,这是以前训练单级检测器的最先进技术。最后,我们注意到焦点损失的确切形式并不是至关重要的,并且我们展示了其他实例化可以获得类似的结果。
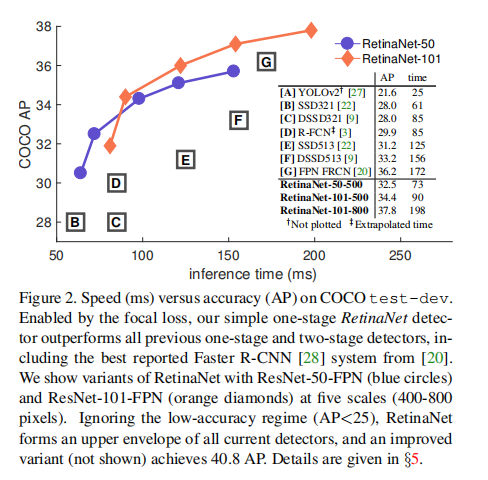
为了证明所提出的焦点损失的有效性,我们设计了一个简单的单级目标检测器,称为RetinaNet,以其在输入图像中对目标位置的密集采样而命名。它的设计特点是一个高效的网络内特征金字塔和锚盒的使用。它借鉴了[22,6,28,20]的各种最新想法。RetinaNet高效、准确;我们的最佳模型基于ResNet-101-FPN骨干,以5帧/秒的速度实现了COCO测试开发AP的39.1,超过了之前发布的一阶段和两阶段探测器的最佳单模型结果,见图2。
2. Related Work
Classic Object Detectors: 滑动窗口范式,即将分类器应用于密集的图像网格上,具有悠久而丰富的历史。最早的成功之一是LeCun等人的经典工作,他将卷积神经网络应用于手写体数字识别[19,36]。Viola和Jones[37]使用增强的物体探测器进行人脸检测,导致了这种模型的广泛采用。随着HOG[4]和积分信道特征[5]的引入,产生了一种有效的行人检测方法。DPMs[8]帮助将密集的探测器扩展到更一般的对象类别,并多年来在帕斯卡尔[7]上取得了最好的结果。虽然滑动窗口方法是经典计算机视觉中领先的检测范式,但随着深度学习[18]的复苏,接下来描述的两阶段探测器迅速成为主导目标检测。
Two-stage Detectors: 在现代目标检测的主导范式是基于一个两阶段的方法。正如在选择性搜索工作[35]中率先提出的那样,第一阶段生成一组稀疏的候选提案,其中应该包含所有的对象,同时过滤掉大多数负面的位置,第二阶段将提案分类为前景类/背景。R-CNN[11]将第二阶段分类器升级为卷积网络,在精度上有了很大的提高,并开创了现代目标检测时代。R-CNN在多年年来得到了改进,无论是在速度[15,10]还是使用学习对象建议[6,24,28]。区域建议网络(RPN)将建议生成与第二阶段分类器集成到一个单一的卷积网络中,形成了Faster RCNN框架[28]。对这个框架提出了许多扩展,例如[20,31,32,16,14]。
One-stage Detectors: OverFeat[30]是第一个基于深度网络的现代单级目标探测器之一。最近,SSD[22,9]和YOLO[26,27]重新引起了人们对一期方法的兴趣。这些探测器已经调整了速度,但它们的精度落后于双阶段的方法。SSD的AP值低了10-20%,而YOLO则专注于更极端的速度/精度权衡。详见图2。最近的研究表明,只要降低输入图像分辨率和建议的数量,两级探测器就可以快速完成,但即使使用更大的计算预算[17],两级方法的精度也会落后。相比之下,这项工作的目的是了解在一级探测器以类似或更快的速度运行时,是否能匹配或超过两级探测器的精度。
我们的RetinaNet探测器的设计与以前的密集探测器有许多相似之处,特别是RPN[28]引入的“锚”概念,以及SSD[22]和FPN[20]中的特征金字塔的使用。我们强调,我们的简单检测器达到最高的结果不是基于网络设计的创新,而是由于我们的新损失。
Class Imbalance: 经典的单阶段目标检测方法,如boosted detectors [37,5]和DPMs[8],以及最近的方法,如SSD[22],在训练过程中都面临着很大的类别不平衡。这些探测器为每张图像评估104-105个候选位置,但只有少数位置包含物体。这种不平衡导致了两个问题:(1)训练是效率低下的,因为大多数位置是容易的负面,没有贡献有用的学习信号;(2)集体,容易的否定会压倒训练,导致退化模型。一种常见的解决方案是执行某种形式的硬负挖掘[33,37,8,31,22],在训练或更复杂的采样/重称重方案[2]。相比之下,我们表明,我们提出的焦点损失自然处理了一级检测器所面临的类不平衡,并允许我们有效地训练所有的例子,没有采样,没有容易的负压倒损失和计算梯度。
Robust Estimation: 人们对设计鲁棒损失函数(例如,Huber损失[13])非常感兴趣,该函数通过降低具有大误差的例子(硬例子)的损失的权重来减少异常值的贡献。相比之下,我们的焦点损失不是解决异常值,而是通过降低权重(简单的例子)来解决类不平衡,这样即使它们的数量很大,它们对总损失的贡献也很小。换句话说,焦点损失的作用与鲁棒损失相反:它集中训练一组稀疏的硬例子。
3. Focal Loss
焦点损失的设计是为了解决单阶段目标检测场景,在训练过程中前景和背景类别之间存在极端的不平衡(例如,1:1000)。对于二值分类1,我们从交叉熵(CE)损失开始引入焦点损失:
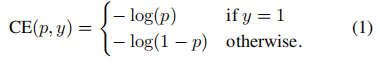
在上面的y∈{±1}指定了地面真实类,p∈[0,1]是模型对标签为y=1的类的估计概率。为了便于标注符号,我们定义了pt:
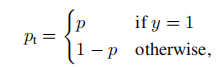
并重写CE(p,y)=CE(pt)=−log(pt)。
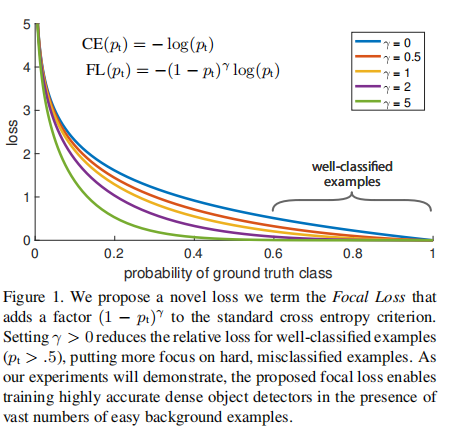
CE损失可以看作是图1中的蓝色(上)曲线。这种损失的一个显著特性,很容易从图中看出,即即使是容易分类的例子(pt.5)也会导致非平凡幅度的损失。当对大量简单的例子进行求和时,这些小的损失值可能会压倒稀有的类。
3.1. Balanced Cross Entropy
解决类不平衡的一种常见方法是为类1引入权重因子α∈[0,1],为类−1引入类1−α。在实践中,α可以通过逆类频率来设置,也可以作为一个超参数,通过交叉验证来设置。为了便于标注,我们对αt的定义类似于我们如何定义pt。我们将α-平衡的CE损失写为:
![]()
这种损失是对CE的一个简单扩展,我们将其作为我们提出的焦点损失的实验基线。
3.2. Focal Loss Defifinition
正如我们的实验将显示的,在训练密集探测器过程中遇到的大类不平衡超过了交叉熵损失。容易分类的负数组成了大部分的损失,并主导了梯度。虽然α平衡了积极/消极的例子的重要性,但它没有区分简单/困难的例子。相反,我们建议重塑损失函数,以减轻简单的例子,从而将训练集中在困难的负样本上。
更正式地说,我们建议在交叉熵损失中增加一个调制因子![]() ,并具有可调聚焦参数γ≥0。我们将焦点损失定义为:
,并具有可调聚焦参数γ≥0。我们将焦点损失定义为:
![]()
图1中γ∈[0,5]的几个值的焦点损失。我们注意到焦点损失的两个性质。(1)当一个例子被错误分类,pt很小时,调制因子接近1,损失不受影响。当pt→1时,因子变为0,分类良好的例子的损失被降低。(2)聚焦参数γ平滑地调整简单例子降低的速率。当γ=0时,FL相当于CE,并且随着γ的增加,调节因子的作用也同样增加(我们发现γ=2在我们的实验中效果最好)。
直观地说,调制因子减少了简单示例的损失贡献,并扩展了示例接收低损耗的范围。例如,在γ=2中,pt=0.9分类的损失比CE低100×,pt≈0.968分类的损失低1000×。这反过来又增加了纠正错误分类的例子的重要性(对于pt≤.5和γ=2,其损失最多减少了4×)。
在实践中,我们使用了焦点损失的α平衡变体:
![]()
我们在实验中采用这种形式,因为它比非α平衡形式略有提高。最后,我们注意到损失层的实现结合了计算p的s型运算与损失计算,从而产生了更大的数值稳定性
虽然在我们的主要实验结果中,我们使用上面的焦点损失定义,它的精确形式并不是关键的。在附录中,我们考虑了焦点损失的其他实例,并证明这些实例可以同样有效。
3.3. Class Imbalance and Model Initialization
二进制分类模型默认初始化为输出y=−1或1的概率相等。在这种初始化条件下,在存在类别不平衡的情况下,由于频繁的类别而造成的损失会主导总损失,并在早期训练中造成不稳定。为了解决这个问题,我们在训练开始时引入了由模型估计的p值的“先验”的概念。我们用π表示先验,并将其设置,使罕见类例子的模型估计p很低,例如0.01。我们注意到,这是模型初始化中的一个变化(见4.1),而不是损失函数的变化。我们发现,在重类不平衡的情况下,这可以提高交叉熵和焦点损失的训练稳定性。
3.4. Class Imbalance and Two-stage Detectors
两级检测器通常使用交叉熵损失进行训练,而不使用α平衡或我们提出的损失。相反,它们通过两种机制来解决类不平衡:(1)是两阶段级联和(2)偏置的小批量采样。第一个级联阶段是一个对象建议机制[35,24,28],它将几乎无限的可能的对象位置集减少到1到2000个。重要的是,所选的建议不是随机的,但很可能对应于真实的对象位置,这消除了绝大多数容易产生的缺点。在训练第二阶段时,有偏抽样通常用于构建包含的小批次,例如,正与负例子的1:3的比例。这个比率就像一个通过抽样实现的隐式α平衡因子。我们提出的焦点损失是为了通过损失函数直接在一级检测系统中解决这些机制。
4. RetinaNet Detector
RetinaNet是由一个骨干网和两个任务特定子网组成的单一、统一的网络。主干网负责计算整个输入图像上的卷积特征图,是一个非自定义的卷积网络。第一个子网对主干网的输出进行卷积对象分类;第二个子网执行卷积边界盒回归。这两个子网具有一个简单的设计,我们专门针对单阶段、密集的检测提出,见图3。虽然对于这些组件的细节有许多可能的选择,但大多数设计参数对实验中所示的精确值并不特别敏感。接下来,我们将描述视网膜网的每个组成部分。
Feature Pyramid Network Backbone: 我们采用[20]中的特征金字塔网络(FPN)作为RetinaNet网络的骨干网络。简而言之,FPN通过自上而下的路径和横向连接增强了标准卷积网络,因此该网络有效地从单一分辨率的输入图像构建了一个丰富的、多尺度的特征金字塔,见图3(a)-(b).金字塔的每一层都可以用于检测不同尺度上的物体。FPN改进了来自全卷积网络(FCN)[23]的多尺度预测,这从RPN[28]和DeepMask-style proposals[24]以及Faster R-CNN[10]或Mask R-CNN[14]等两阶段探测器的收益中就可以看出。
在[20]之后,我们在ResNet架构[16]之上构建了FPN。我们构造了一个级别从P3到P7的金字塔,其中L表示金字塔级别(的分辨率比输入值低
)。在[20]中,所有的金字塔层都有C=256通道。金字塔的细节通常遵循[20],但有一些轻微的不同。2虽然许多设计选择并不是至关重要的,但我们强调使用FPN主干是;仅使用来自最终ResNet层的特性的初步实验产生了低AP。
Anchors: 我们使用类似于[20]中的RPN变体的平移不变锚定箱体。锚在P3到P7金字塔层上的面积分别为32^2到512^2。在[20]中,在每个金字塔水平上,我们使用三个纵横比{1:2,1:1:1,2:1}。为了实现比[20]更密集的尺度覆盖范围,我们在每个级别上添加了原始3个纵横比锚点集的{}大小的锚点。这改善了我们的设置中的AP。总的来说,每个级别都有一个A=9锚,它们覆盖了相对于网络输入图像的32-813像素。
每个锚点被分配一个长度为K的分类目标的一个独热向量,其中K是对象类的数量,以及一个4个盒子回归目标的向量。我们使用来自RPN[28]的分配规则,但修改了多类检测和调整了阈值。具体来说,锚使用交叉联合(IoU)阈值0.5分配给地面真实对象框;如果它们的IoU在[0,0.4)中,则分配到背景。由于每个锚点最多被分配给一个对象框,因此我们将其长度为K个标签向量中的相应条目设置为1,并将所有其他条目设置为0。如果一个锚点未被分配,这可能会在[0.4,0.5)中发生重叠,则在训练过程中被忽略。框回归目标计算为每个锚与其分配的对象框之间的偏移量,如果没有分配则省略。

Classifification Subnet: 分类子网预测每个A锚和K个对象类在每个空间位置存在的概率。这个子网是一个连接到每个FPN级别的小FCN;这个子网的参数在所有金字塔级别上共享。它的设计很简单。从给定的金字塔层获取一个具有C通道的输入特征图,子网应用4个3×3conv层,每个层带有C滤波器,每个层随后是ReLU激活,然后是带有KA滤波器的3×3conv层。最后,s型激活连接到每个空间位置的KA二进制预测,见图3(c).我们在大多数实验中使用C=256和A=9。
与RPN[28]相比,我们的对象分类子网更深,只使用3×3convs,并且不与盒子回归子网共享参数(下面描述)。我们发现这些更高级别的设计决策比超参数的特定值更重要。
Box Regression Subnet: 与对象分类子网并行,我们在每个金字塔层附加另一个小FCN,以便将每个锚盒的偏移回归到附近的地面真实对象,如果存在的话。预测框回归子网的设计与分类子网相同,只是在每个空间位置终止于4A线性输出,见图3(d).对于每个空间位置的每个A锚,这4个输出预测了锚和地面真实框之间的相对偏移量(我们使用来自RCNN[11]的标准框参数化)。我们注意到,与最近的工作不同,我们使用了一个类不可知的边界盒回归器,它使用了更少的参数,我们发现它同样有效。对象分类子网和预测框回归子网虽然共享一个共同的结构,但都使用单独的参数。
4.1. Inference and Training
Inference: RetinaNet形成了一个由ResNet-FPN主干、一个分类子网和一个预测框回归子网组成的单一FCN,见图3。因此,推理涉及到简单地通过网络转发一个图像。为了提高速度,在阈值检测器置信度为0.05之后,我们只从每个FPN级别最多1k个得分最高的预测中解码预测框预测。来自所有级别的顶级预测被合并,并应用阈值为0.5的非最大抑制来产生最终的检测。
Focal Loss: 我们使用本工作中引入的焦点损失作为分类子网输出的损失。正如我们将在5中所展示的,我们发现γ=2在实践中工作得很好,并且RetinaNet对γ∈[0.5,5]相对健壮。我们强调,当训练RetinaNet时,焦点损失应用于每个采样图像中的所有∼100k锚点。这与使用启发式抽样(RPN)或硬示例挖掘(OHEM,SSD)为每个小批选择一组小的锚点(例如,256)的常见做法形成了对比。图像的总焦点损失计算为所有∼100k锚的焦点损失的总和,由分配给地面真实盒的锚的数量归一化。我们通过指定锚的数量来进行归一化,而不是总锚,因为绝大多数锚很容易是负值,在焦点损失下得到的损失值可以忽略不计。最后,我们注意到,分配给稀有类的权重α也有一个稳定的范围,但它与γ相互作用,因此有必要同时选择两者(见表1a和表1b)。一般来说,α应该随着γ的增加而略有降低(对于γ=2,α=0.25效果最好)。
Initialization: 我们用ResNet-50-FPN和ResNet-101-FPN骨干[20]进行实验。基本的ResNet-50和ResNet-101模型在ImageNet1k上进行了预训练;我们使用由[16]发布的模型。为FPN添加的新层将在[20]中初始化。除RetinaNet子网中的最后一个层外,所有新的conv层都用偏置b=0和σ=0.01的高斯权重填充进行初始化。对于分类子网的最后conv层,我们将偏置初始化设置为b=−log((1−π)/π),其中π指定在训练开始时每个锚应该标记为∼π的前景。我们在所有实验中都使用π=.01,尽管结果对精确的值是稳健的。如3.3中所解释的,这种初始化阻止了大量的背景锚点在第一次训练迭代中产生一个大的、不稳定的损失值。
5. Experiments
我们提出了关于具有挑战性的COCO基准[21]的边界盒检测轨迹的实验结果。对于训练,我们遵循常见的实践[1,20],并使用COCO训练35k分割(来自训练的80k图像和来自40k图像val分割的随机35k图像子集的联合)。我们通过评估微小分裂(来自val的其余5k图像)来报告病变和敏感性研究。对于我们的主要结果,我们报告了关于测试-开发分割的COCO AP,它没有公共标签,需要使用评估服务器。
5.1. Training Dense Detection
我们进行了大量的实验来分析密集检测的损失函数的行为以及各种优化策略。对于所有的实验,我们使用深度50或101 ResNets[16],并在顶部构造了一个特征金字塔网络(FPN)[20]。对于所有的消融研究,我们使用600像素的图像尺度来进行训练和测试。
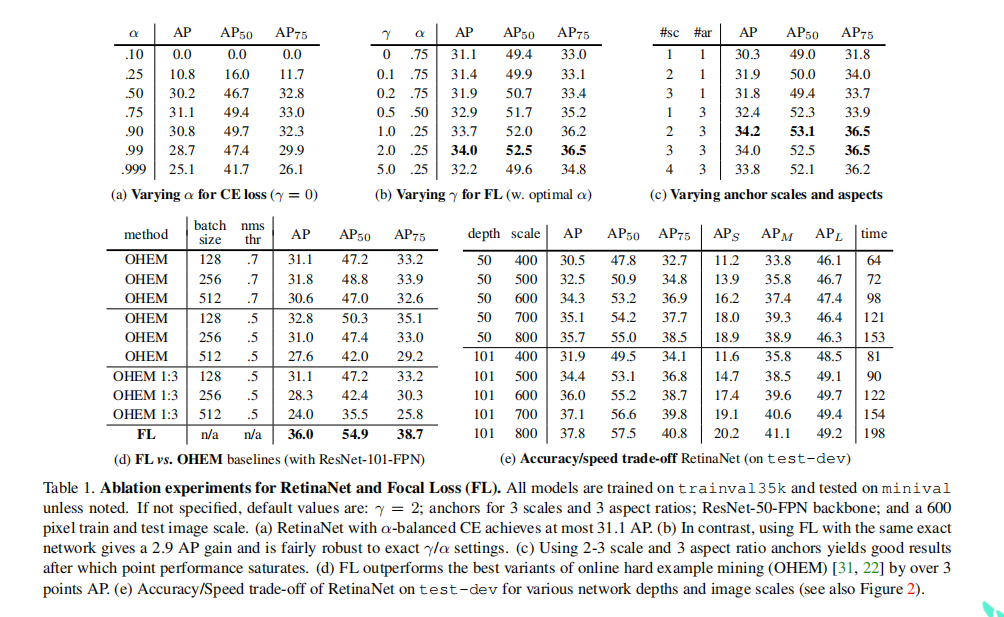
Network Initialization: 在我们第一次尝试训练RetinaNet时,我们使用了标准的交叉熵(CE)损失,而没有对初始化或学习策略进行任何修改。这很快就失败了,因为在训练过程中网络会发生分化。然而,简单地初始化我们的模型的最后一层,这样检测到一个对象的先验概率是π=.01(见4.1),就可以实现有效的学习。使用ResNet-50训练RetinaNet,这种初始化已经在COCO上产生了相当可观的30.2的AP。结果对π的精确值不敏感,所以我们在所有实验中都使用π=.01。
 Balanced Cross Entropy: 我们的下一个尝试是使用3.1中描述的α平衡CE损失来改善学习。不同α的结果见表1a。设置α=.75可获得0.9AP。
Balanced Cross Entropy: 我们的下一个尝试是使用3.1中描述的α平衡CE损失来改善学习。不同α的结果见表1a。设置α=.75可获得0.9AP。
Focal Loss: 使用我们提出的焦点损失的结果如表1b所示。焦点损失引入了一个新的超参数,即聚焦参数γ,它控制了调制项的强度。当γ=为0时,我们的损失相当于CE损失。随着γ的增加,损失的形状会发生变化,从而使低损失的“简单”例子进一步贴现,见图1。随着γ的增加,FL比CE有很大的增加。使用γ=2,FL比α平衡的CE损失提高了2.9 AP。
对于表1b中的实验,为了进行公平的比较,我们找到了每个γ的最佳α。我们观察到,较低的α被选择为较高的γ(因为容易的阴性被降低,较少需要强调阳性)。然而,总的来说,改变γ的好处要大得多,事实上最好的α范围仅为[.25,.75](我们测试了α∈[.01,.999])。我们在所有的实验中都使用了γ=2.0和α=.25,但α=.5的工作效果几乎一样好(更低0.4AP)。
Analysis of the Focal Loss: 为了更好地理解焦点损失,我们分析了收敛模型损失的经验分布。为此,我们取我们的默认ResNet-101 600像素模型,使用γ=2(它有36.0AP)进行训练。我们将该模型应用于大量的随机图像,并对∼107负窗口和∼105正窗口的预测概率进行采样。接下来,对于正和负,我们分别计算这些样本的FL,并将损失归一化,使其之和为1。给定归一化损失,我们可以将损失从最低到最高进行排序,并绘制出正、负样本和γ的不同设置的累积分布函数(CDF)(即使模型是用γ=2训练的)。
正、负样本的累积分布函数如图4所示。如果我们观察阳性样本,我们会看到不同的γ值的CDF看起来相当相似。例如,大约20%的最难的阳性样本约占正损失的一半,随着γ的增加,更多的损失集中在前20%的例子中,但影响很小
γ对阴性样本的影响有显著差异。对于γ=0,阳性和阴性的CDFs非常相似。然而,随着γ的增加,更多的权重将集中在硬负的例子上。事实上,在γ=2(我们的默认设置)中,绝大多数的损失来自于一小部分的样本。可以看出,FL可以有效地忽略容易否定的影响,把所有的注意力都集中在硬否定的例子上。
Online Hard Example Mining (OHEM): 提出了通过使用高损耗实例构建小批次来改进两阶段检测器的训练。具体来说,在OHEM中,每个例子都通过其损失进行评分,然后应用非最大抑制(nms),并使用损失最高的例子构建一个小批。nms阈值和批处理大小都是可调谐的参数。和焦点损失一样,OHEM更强调错误分类的例子,但与FL不同的是,OHEM完全放弃了简单的例子。我们还实现了SSD[22]中使用的OHEM的一个变体:在对所有例子应用nms后,小批被构建为强制执行正和负之间的1:3比例,以帮助确保每个小批有足够的正样本。
我们在我们的单阶段检测设置中测试了这两个OHEM变量,它有很大的类不平衡。原始OHEM策略和选定批大小和nms阈值的“OHEM 1:3”策略的结果如表1d所示。这些结果使用了ResNet-101,我们用FL训练的基线在此设置下达到了36.0 AP。相比之下,OHEM的最佳设置(没有1:3比,批大小128,nms为0.5)达到32.8AP。这是一个3.2AP的间隙,表明FL在训练密集探测器方面比OHEM更有效。我们注意到,我们尝试了OHEM的其他参数设置和变量,但没有取得更好的结果。
Hinge Loss: 最后,在早期的实验中,我们尝试在pt上使用Hinge Loss损失[13]进行训练,将pt的一定值以上设置为0。然而,这是不稳定的,我们并没有设法获得有意义的结果。研究替代损失函数的结果见附录。
5.2. Model Architecture Design
Anchor Density: 在单阶段检测系统中,最重要的设计因素之一是它覆盖可能的图像盒的空间。两级检测器可以使用区域池操作[10]对任何位置、尺度和高宽比下的盒子进行分类。相比之下,由于单级探测器使用固定的采样网格,在这些方法中实现盒子高覆盖率的一种流行方法是在每个空间位置使用多个“锚”[28]来覆盖不同尺度和长宽比的盒子。
我们扫描了在FPN中的每个空间位置和每个金字塔水平上使用的尺度和长宽比锚点的数量。我们考虑了从每个位置的一个正方形锚到每个位置的12个锚,跨越4个亚八度尺度(2^k/4,对于k≤3)和3个长宽比[0.5,1,2]。使用ResNet-50的结果如表1c所示。仅使用一个方形锚就可以获得惊人的好AP(30.3)。然而,当每个位置使用3个尺度和3个高宽比时,AP可以提高近4个点(达到34.0)。我们在这项工作中的所有其他实验中都使用了这个设置。
最后,我们注意到,增加超过6-9个锚点并没有显示出进一步的收益。因此,虽然两级系统可以分类图像中的任意盒子,性能饱和w.r.t.密度意味着两级系统较高的势密度可能不会提供优势。
Speed versus Accuracy: 更大的主干网络产生更高的精度,但也有较慢的推理速度。同样地,对于输入图像比例(由较短的图像侧定义)。我们在表1e中显示了这两个因素的影响。在图2中,我们绘制了RetinaNet的速度/精度权衡曲线,并将其与在COCO测试开发中使用公共数字的最近方法进行了比较。图显示,由于我们的焦点损失,对所有现有方法形成了一个上包络线,扣除低精度的制度。ResNet-101-FPN和600像素的图像比例(为了简单起见,我们用RetinaNet-101-600表示)符合最近发布的ResNet-101-FPNFaster R-CNN[20],而每张图像运行122 ms,172 ms(都在NvidiaM40GPU上测量)。使用更大的尺度允许RetinaNet的精度超过所有两阶段方法的精度,同时仍然更快。对于更快的运行时,只有一个操作点(500像素的输入),使用ResNet-50-FPN比ResNet-101-FPN有改进。解决高帧率机制可能需要特殊的网络设计,如在[27]中,这超出了这项工作的范围。我们注意到,在发表后,现在可以通过[12]的R-CNN的变体获得更快和更准确的结果。
5.3. Comparison to State of the Art
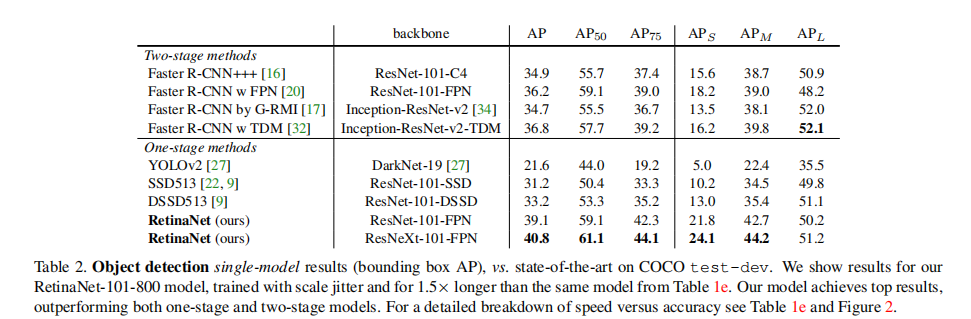
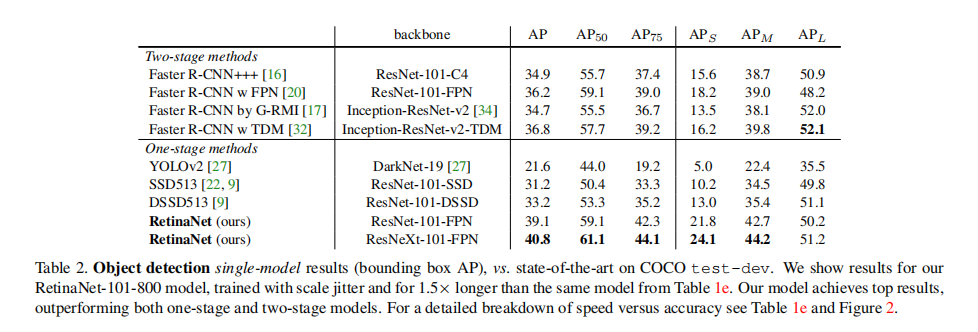
我们在具有挑战性的COCO数据集上评估RetinaNet,并将测试开发结果与最近最先进的方法进行比较,包括一阶段和两阶段模型。表2显示了我们的RetinaNet-101-800模型的结果,并且比表1e中的模型长1.5×(给出1.3 AP增益)。与现有的单阶段方法相比,我们的方法与最接近的竞争对手DSSD[9]实现了良好的5.9点AP差距(39.1 vs.33.2),同时也更快,见图2。与最近的两阶段方法相比,RetinaNet比基于初始-ResNet-v2-TDM[32]的最佳Faster R-CNN模型达到了2.3个点的差距。插入RetNeXt-32x8d-101-FPN[38]作为RetinaNet主干进一步提高了结果1.7AP,超过了COCO的40 AP。
6. Conclusion
在这项工作中,我们确定类不平衡是阻止一级物体探测器超过性能最好的两阶段方法的主要障碍。为了解决这个问题,我们提出了焦点损失,它应用一个调制项的交叉熵损失,以便集中学习硬负的例子。我们的方法简单而高效。我们通过设计一个完全卷积的单级检测器来证明它的有效性,并报告了广泛的实验分析,表明它达到了最先进的精度和速度。
Appendix A: Focal Loss*
焦点损失的确切形式并不重要。我们现在展示了一个焦点损失的替代实例化,它具有类似的性质,并产生了可比较的结果。下面还提供了对焦点损失特性的更多的见解。
我们首先考虑交叉熵(CE)和焦点损失(FL),其形式与正文中略有不同。具体来说,我们定义了一个量xt如下:
![]()
其中,y∈{±1}指定了与前面一样的地面真值类。然后我们可以写出pt=σ(xt)(这与方程2中的pt的定义是兼容的)。例如,在xt>0时被正确分类,在这种情况下是pt>.5。
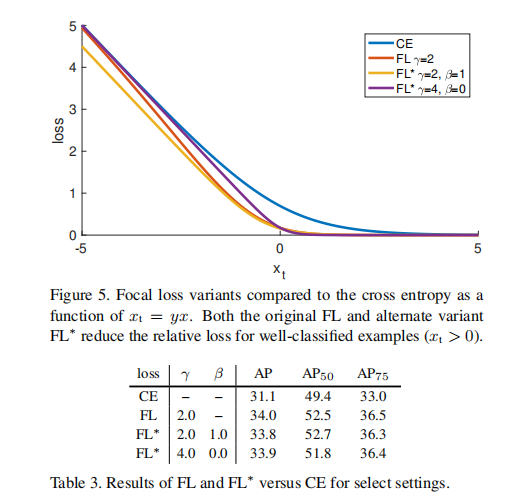
我们现在可以用xt来定义焦点损失的另一种形式。我们对∗和∗∗的定义如下:
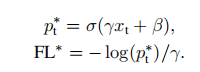
FL∗有两个参数,γ和β,它们控制着损失曲线的陡度和位移。我们绘制了图5中γ和β的两个选定设置的FL∗,以及CE和FL。可以看出,像FL一样,具有选定参数的FL∗减少了分配给分类良好的例子的损失。
我们使用与之前相同的设置来训练RetinaNet-50-600,但我们用选定的参数将FL替换为FL∗。这些模型实现的AP与使用FL训练的AP几乎相同,见表3。换句话说,FL∗是一个合理的替代方案,在实践中很有效。
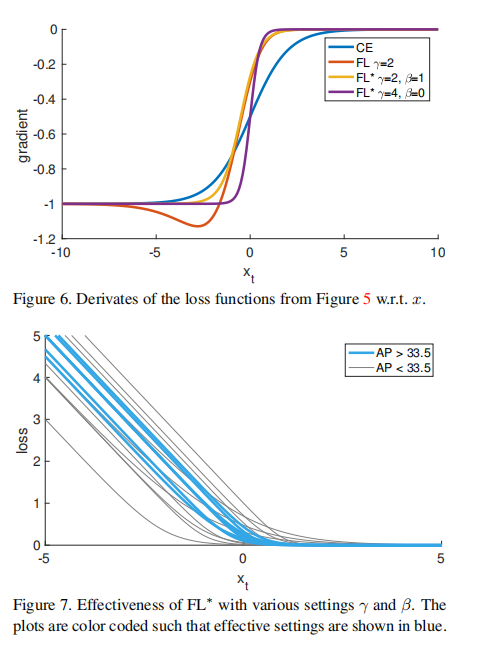
我们发现,各种γ和β设置都提供了良好的结果。在图7中,我们展示了使用FL∗进行大量参数处理的RetinaNet-50-600的结果。损失图用颜色编码,这样有效设置(模型收敛,AP超过33.5)用蓝色表示。为了简单起见,我们在所有实验中都使用了α=.25。可以看出,减少分类良好的例子(xt>0)权重的损失是有效的。
更一般地说,我们期望任何与FL或FL∗具有相似性质的损失函数都同样有效。
Appendix B: Derivatives
作为参考,CE、FL和FL∗w.r.t.的派生x为:

所选设置的绘图如图6所示。对于所有的损失函数,对于高置信度的预测,导数趋于-1或0。然而,与CE不同的是,对于FL和FL∗的有效设置,衍生品只要在xt>0就很小。
















 51
51











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











