







Deep Image Matting
来源 | CVPR/IEEE 2017 |
主题 | Image Matting |
动机 | 传统的Matting算法只利用了图片的颜色、像素位置这种低级的特征,没有充分发挥纹理、语义等高级特征的作用,本文通过神经网络来对图像的高级特征进行学习,进一步进行抠图任务。 |
方法总结 | 该方法主要是用于求解图像的alpha matte。文章中的网络分为俩级,第一级是编码器-解码器网络,用于抽取图像的特征(低级和高级),输入图像的RGB以及trimap,通过编码器中卷积和池化层以及解码器中上采样和卷积层的作用,输出粗略的alpha matte。第二级网络则是对第一级网络输出的alpha matte进行微调,输入原图像RGB三通道以及第一级网络输出的alpha matte,通过卷积层以及残差连接的作用,最终输出更准确的alpha matte。 |
亮点 |
|
技术细节 | 编码(Encoder)-解码(Decoder)块、残差连接、Matting Refinement. |
备注 | 精读 |
ImageMatting 简介
Image Matting是一个基础的计算机视觉的问题,有许多的应用领域,如:图像编辑、电影制作、加快专业工作流程。
Image Matting问题可以用下面的等式来表达:
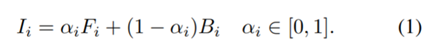
其中,I是像素的RGB颜色,α为alpha matte的值,代表该位置像素属于前景的程度,F为前景的RGB值,B为背景的RGB值。该等式有七个未知数(F、B三个通道有六个未知数,α也未知),但是对于每一个像素来说,RGB只能确定三个等式,因此该问题为欠约束的病态问题,这也是Image Matting问题困难的根源。
研究动机
Image Matting是一个欠约束问题,但是目前的许多方法都有其自身的局限性。目前的方法都关注于求解上述式1,这使得目前的算法都只利用了图像的RGB信息以及像素的位置信息,而忽略了图像的高级特征(比如图像的结构信息、纹理信息、上下文信息)。仅仅关注颜色和位置这样的低级特征,使得当前的算法对颜色十分的敏感,当前景和背景的颜色相近,或是在图像中存在一些透明的目标的时候,这些算法的表现往往非常差。
然而,Image Matting的绝大多数应用场合都是现实中的场景,这也要求抠图的算法对场景不能有过多的限制要求,算法应该具有较强的鲁棒性和泛化能力。
目前的算法主要有俩个问题:
1 只使用低级的特征、缺乏高级的环境信息,极大部分依赖于前后景的颜色和像素的位置。
2 只关注非常小的数据集,而这些数据集背景简单,目标单一,目标均为静态物体,且只有几十个数据,目前的算法都基于一些小的数据集,最终会出现过拟合的现象。
贡献1——合成新的大数据集
以往的数据集由于要严格控制拍照的环境来获得背景真实的图片,数据集一般有以下几个问题:
1、数据少,容易过拟合
2、内容均为静态物体,不符合现实场景的需要
3、拍摄的背景都是小规模的静态场景
4、内容的多样性不强
本文的作者则利用合成的方式合成了一个大的数据集,具体过程如下图:

合成数据集的思路是将真实的前景融合到新的背景中去。首先,需要收集具有简单真实背景的图(a),使用ps将这些图的alpha matte手工标记出来(b),并且抠出来前景的颜色(c)(这里c中多出来了一些轮廓,是为了保证前景完全被抠出来,多出来的区域由于要和alpha matte的值相乘,不会影响到后续的合成)。然后,从背景数据集MS COCO和 Pascal VOC中随机选择背景作为真实背景,将真实前景和背景合成成新的图片,便是新的数据集。
该数据集主要优点是:
1、前景中的目标物体种类非常多样化,目标边缘含有头发、皮毛、半透明的物体,给alpha matte的预测带来了挑战。
2、许多合成图中前景和背景具有相近的前景和背景颜色以及复杂的背景纹理。
但是这个数据集也有其致命的缺陷:
数据集的本质还是合成的,并非真实的,这是否会给学习引入偏置,导致机器学到的是一些前景和背景的光照分布、噪音分布等特征,而不是图片的语义信息。但是在真实场景的图片中该论文的模型表现也比较好,可以认为机器学到了高级特征。(其实我觉得这里或许可以做一些可视化使得结论更有说服力。
网络结构
网络分为俩阶段,第一个阶段是编码器、解码器结构,输入图片的RGB三通道以及trimap,输出略粗略的alpha matte,loss由alpha matte loss 和composition loss组成,第二个是refine阶段,输入RGB三通道和第一阶段输出的alpha matte四个通道的特征,通过卷积和残差shortcut连接获得Refined alpha matte,为最终的输出。整个网络的本质就是在学trimap中(128位置中)的具体alphamatte。
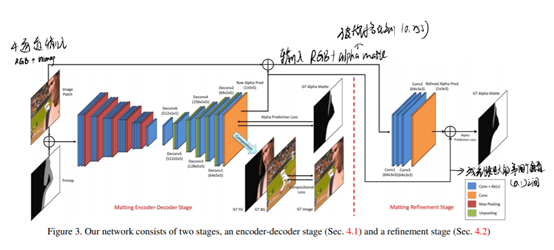
第一阶段:编码层由14个卷积层和5个池化层构成,解码器由五个上采样和七个卷积层构成。第一阶段使用了alpha loss 和 composition loss的组合:
Alphaloss:真实alpha matte和第一阶段预测alpha matte的loss:
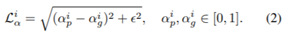
Composition loss:由Refined alphamatte 和真实前景RGB、背景RGB计算出的合成图像的RGB与真实图像RGB之间的loss:
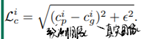
文章中取Wl为0.5,为了减少计算复杂性,只对不确定区域的像素计算loss,而对于完全确定的前景和后景,loss为0。
第二阶段:由四个卷积层以及第一阶段输出的alpha matte的残差连接组成,第二阶段仅使用alpha loss。
训练技巧
为了避免过拟合以及最大程度的对训练数据进行利用,采取了许多训练tricks:
1、网络参数初始化:解码器部分的网络卷积层使用VGG-16的前十四层进行初始化(VGG 16的第十四层是全连接层,也可以转化为卷积层的初始化参数)。由于网络具有四个通道,在第一个卷积层的滤波器参数初始化时候,将第四个通道的参数初始化为0。
2、随机以未知区域为中心裁切320*320的图像和对应的trimap。
3、提升网络对不同尺度图片的处理能力:裁切不同尺寸的训练数据对(640*640,480*480)并且将数据对的大小重新规格化到320*320,使得网络更好的学习到语义信息。
4、数据增强:训练数据可以随机翻转
5、训练的输入对,在每一个training epoch后随机更新。
6、随机对真实的图像alpha matte进行扩展,得到新的trimap,增强网络对trimap 的鲁棒性。
此外,文章对俩阶段网络进行分阶段训练:
1、先固定Stage 2,训练Stage 1 至收敛
2、固定Stage 1,训练Stage 2至收敛。
3、对俩个Stage整体进行微调,使用Adam,学习率很小,只有10-5,且在微调过程中学习率保持不变。
Q&A
为什么需要Refinement stage?
编码器中有很多上采样层,这会导致输出的alpha matte过于光滑,轮廓不够精细。Refinement stage重新借助源RGB图像对第一阶段输出的alpha matte进行精调。
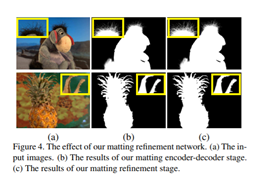
为什么Refinement Stage没有下采样?
为了保留原图像的信息,这些微弱的局部信息对alpha matte的精调具有至关重要的作用。
为什么第一个阶段要将Composition loss考虑进去,第二个阶段只考虑alpha loss?
我个人认为是这也是作者根据性能选择的结果。为什么第一个阶段加入了Composition loss会好一些?我个人认为是前面Stage 1有许多层,实际上Composition loss和alpha loss是强相关的,但是Composition loss由于RGB值的范围比alpha matte的范围更大,会提供更大的梯度,学习收敛有保障。
实验结果
在alphamatting.com dataset效果


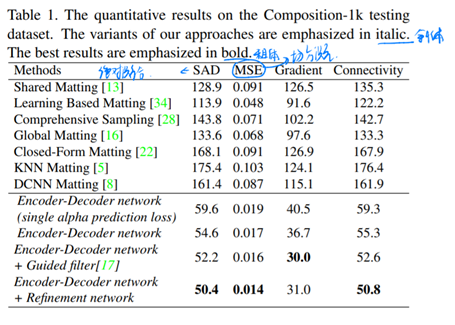
在文章作者自己合成并提出的Composition-1k test set
(感觉这个数据集上面评价有点不讲武德,别的结构都没有在对应的训练集上面训练过
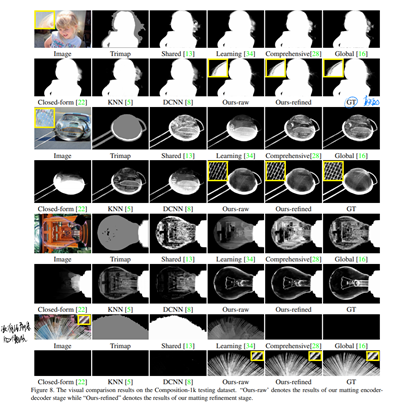
在真实场景图片下的效果
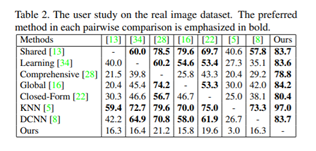
主要是做了User Study。

此外,文章中的网络对trimap的鲁棒性很强:
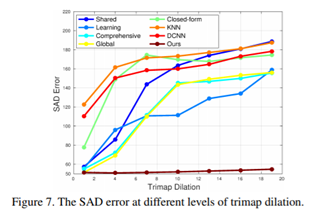
结论
用深度学习来做的效果很好,作者认为这归功于深度学习学到了初级特征和图片中的结构和语义信息。















 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









