







目标检测之DBnet模型
文章目录
前言
本文所介绍的模型DBnet是目前比较流行的文本检测模型。Real-time Scene Text Detection with Differentiable Binarization是发表在AAAI2020的一篇文章。文章地址:原文地址
传统分割方法的后处理,设定一个固定的阈值,将分割网络生成的概率图转换为二值图像;然后,采用像素聚类等启发式技术将像素分组为文本实例。
缺点:由于是在pixel层面操作,比较复杂且时间消耗较大。
DBNet后处理,DBNet的pipeline目的是将二值化操作插入到分割网络中进行联合优化,这样网络可以自适应的预测图像中每一个像素点的阈值(区别去传统方法的固定阈值),从而可完全区分前景和背景的像素。
DBnet中 二值化阈值由网络学习得到,彻底将二值化这一步骤加入到网络里一起训练,这样最终的输出图对于阈值就会具有非常强的鲁棒性,在简化了后处理的同时提高了文本检测的效果。基于分割的方法最关键的步骤是对二值化map的后处理过程,即将分割方法产生的概率图转化为文本框的过程。
文章细节较多,请读者耐心观看!
一、DBnet模型的结构
结构如下图所示:
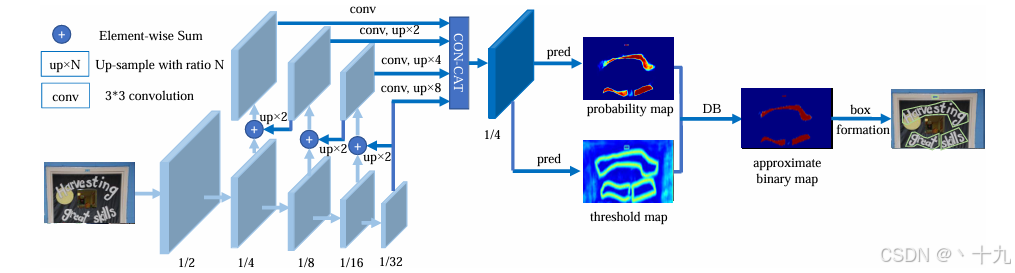
上图展示了DBnet整体的模型结构,可以看出DBnet的模型整体由三部分组成,Backbone,Neck,Head ,Backbone与Neck使用Resnet和FPN结构来完成对图片结构的特征信息提取,在我看来,FPN结构其实可以有待改进,读者可以学习并对之改进。Head部分如下图:
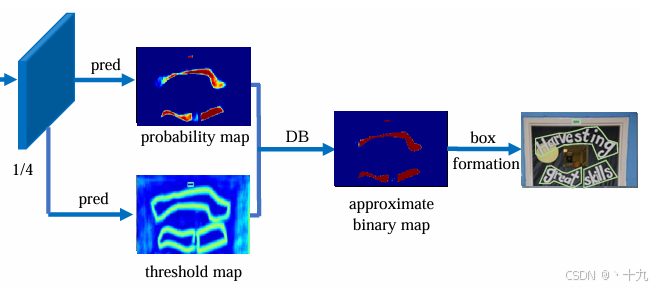
Head部分是本文的创新点所在之处,本文对于Backbone部分就不作赘述,不懂得可以参考其他博客或者是Resnet的原文,下面我们分别对FPN和Head部分进行介绍。
二、FPN结构
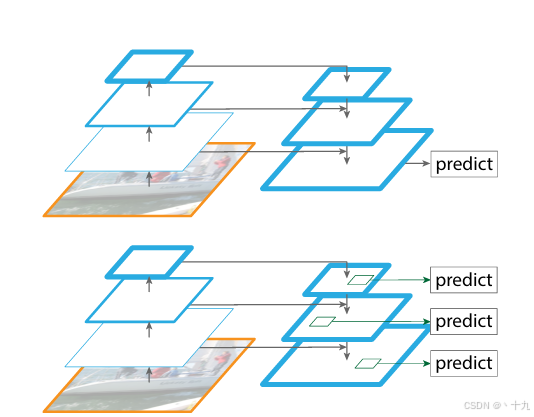
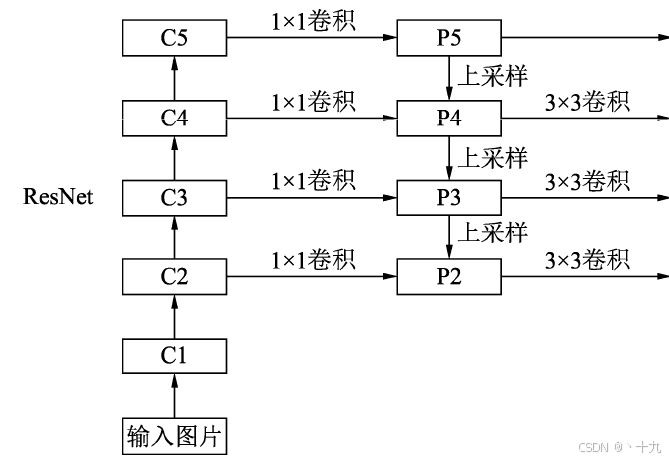
FPN的总体架构如图3所示,主要包含自下而上网络、自上而下网络、横向连接与卷积融合4个部分。
自下而上:
默认ResNet结构用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。如图1所示,原图经过自下而上的Resnet结构,逐渐变为1/2,1/4,1/8,1/16,1/32,这分别对应C1,C2,C3,C4,C5。
自上而下:
首先对C5进行1×1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2尺度相同的特征,以方便下一步进行逐元素相加。这里上采样方法采用2倍最邻近上采样。
横向连接(Lateral Connection):
目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行1×1卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有把C1放到横向连接中。
卷积融合:
在得到相加后的特征后,利用3×3卷积对生成的P2至P5再进行融合,融合时要保证各特征的尺寸相同,我们使用P2尺寸,所以P2不需要上采样,P3至P5分别上采样2倍、4倍、8倍,然后对P2、P3、P4、P5卷积融合。目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
FPN背后的思路是为了获得一个强语义信息,这样可以提高检测性能。使用更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,将处理过的低层特征和处理过的高层特征进行累加,这样做是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此将其结合使用,就构建一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。
最后图像经过FPN网络结构得到特征图F,然后Head部分对这个特征图F进行处理。
三、Head部分
Head部分由Backbone+FPN得到的特征图F计算得到 probability map( P) 和 threshold map (T)
通过P、T计算(通过可微分二值化DB,下文介绍) 得到approximate binary map(B)
该网络网络训练和推理阶段存在不同:
训练阶段:对P、T、B进行监督训练。
推理阶段:通过P或B就可以得到文本框。
1.训练阶段
(1)前向传播
我把图2放在这里,方便读者观看。
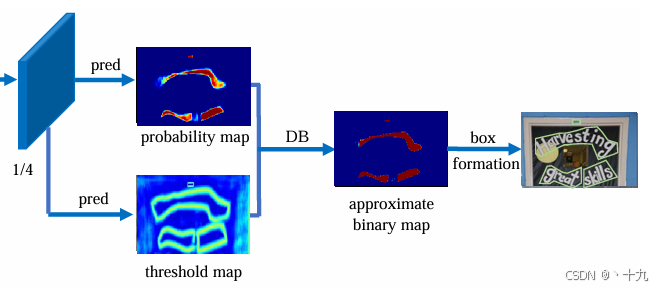
由Backbone+FPN得到的特征图F,其尺寸大小为原图的1/4,然后计算得到,代码如下:
class DBHead(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.probability = nn.Sequential(
nn.Conv2d(in_channels, in_channels // 4, 3, padding=1, bias=False),
nn.BatchNorm2d(in_channels // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 2, 2),
nn.BatchNorm2d(in_channels // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels // 4, 1, 2, 2),
nn.Sigmoid()
)
self.threshold = nn.Sequential(
nn.Conv2d(in_channels, in_channels // 4, 3, padding=1, bias=False),
nn.BatchNorm2d(in_channels // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 2, 2),
nn.BatchNorm2d(in_channels // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels // 4, 1, 2, 2),
nn.Sigmoid())
def forward(self, x):
prob_maps = self.probability(x)
thresh_maps = self.threshold(x)
return prob_maps, thresh_maps
特征图F(shape:(batch,256,1/4W,1/4H))
1)先经过卷积层,将通道压缩为输入的1/4,然后经过BN和relu,得到的特征图shape为(batch,64,1/4W,1/4H);
2)将得到的特征图进行反卷积操作,卷积核为(2,2),得到的特征图shape为(batch,256,1/2W,1/2H),此时为原图的1/2大小;
3)再进行反卷积操作,同第二步,不同的是输出的特征图通道为1,得到的特征图shape为(batch,W,H),此时为原图大小。
4)最后经过sigmoid函数,输出概率图,probability map(P),threshold map (T)同理,不同点在于权重矩阵不同。
probability map(P),threshold map (T)
(2)损失分析
训练数据集是图片中对文本区域的框架,框架是矩形框,DBnet是对于训练数据集是如何操作的呢?
首先我们对损失函数进行分析,论文中总损失函数是由P、T、B三种损失构成,B是什么?
B是由P和T通过可微分二值化DB,下文介绍) 得到approximate binary map,故我们同样的要对训练数据集进行处理,通过训练集图片中的文本区域所对应标注的框架,计算得到与模型输出的P、T以及P,T计算得到的B对应的特征图P1、T1、B1,进而可以计算损失。
所以有必要在数据处理前,我们要介绍本文的创新点DB(可微分二值化),这个可微分二值化是对前向推理的P、T进行计算,得到的B,在本模型中,B仅仅是用来监督训练的,但是也取得了很不错的效果。
(3)DB
标准二值化公式如下:
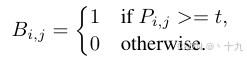
以上的标准二值化公式可以看出,标准二值化操作会给训练带来梯度不可微的情况,如果将二值化操作加入到分割网络进行联合优化,是没法直接用优化算法梯度下降的,本文在此基础上进行创新,提出可微分二值化。
可微分二值化的公式如下:
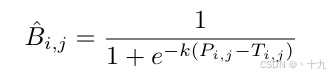
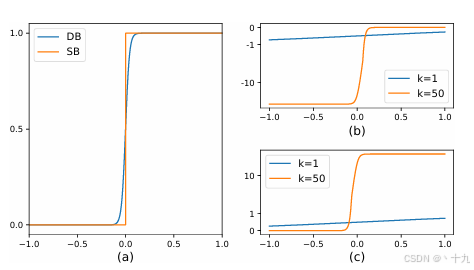
B是由P,T通过一个函数(可微分二值化)计算得到,计算过程看的话,这个函数其实就是一个带系数k的sigmoid函数,其取值范围为0-1,下图(a)是原文中标准二值化曲线与可微分二值化曲线的对比,可见DB曲线是可微分的,可以达到二值化的目的,也可加入分割网络联合优化。图(b)和图(c)是DB函数正负标签的导数曲线,DBNet性能提升的原因可以用梯度的反向传播来解释。首先对于该任务的分割网络,每个像素点都是二分类,即文字区域(正样本为1)和非文字区域(负样本为0),可以使用BCELoss。
B
C
E
l
o
s
s
=
−
y
l
o
g
(
f
(
x
)
)
−
(
1
−
y
)
l
o
g
(
1
−
f
(
x
)
)
BCEloss=-ylog(f(x))-(1-y)log(1-f(x))
BCEloss=−ylog(f(x))−(1−y)log(1−f(x))
y表示正样本1,那么1-y=0
所以正样本的BCELoss和负样本的BCELoss分别为:
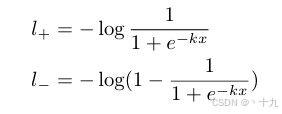
那么链式法则求得偏导数为:
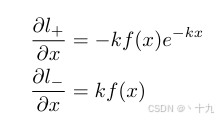
所以可以由此来分析下图中的图(b)和图(c)
(1)梯度被放大 因子k增大;
(2)对比曲线中的黄线和蓝线,横轴为预测取值,故在错误预测的区域(
l
+
l_+
l+的x<0区域,
l
−
l_-
l−的x>0区域)这一放大效果更为显著,也就是loss更大,这可以促进模型的优化过程并产生更为清晰的预测结果。
(4)自适应阈值
对于自适应阈值,论文中是这样介绍的:
The threshold map in Fig. 1 is similar to the text border map
in (Xue, Lu, and Zhan 2018) from appearance. However, the
motivation and usage of the threshold map are different from
the text border map. The threshold map with/without super
vision is visualized in Fig. 6. The threshold map would high
light the text border region even without supervision for the
threshold map. This indicates that the border-like threshold
map is beneficial to the final results. Thus, we apply border
like supervision on the threshold map for better guidance.
An ablation study about the supervision is discussed in the
Experiments section. For the usage, the text border map in
(Xue, Lu, and Zhan 2018) is used to split the text instances
while our threshold map is served as thresholds for the bina
rization.
翻译一下:
首先介绍下图各图:
图b为概率图,图c为没有监督的阈值图,图d为带监督的阈值图
图中的阈值图从外观上类似于文本边界图。但是,我们的阈值映射的用法与文本边界映射不同。有无视觉的阈值图如图所示。即使没有对阈值映射的监督,阈值映射也会对文本边界区域进行高亮显示。这表明类似边界阈值图对最终结果有利。因此,我们在阈值图上应用类似 边界的监督 以获得更好的指导。有关监督的消融研究在实验部分讨论。对于用法,文本边界映射通常用于拆分文本实例,而我们的阈值映射用作二值化的阈值。
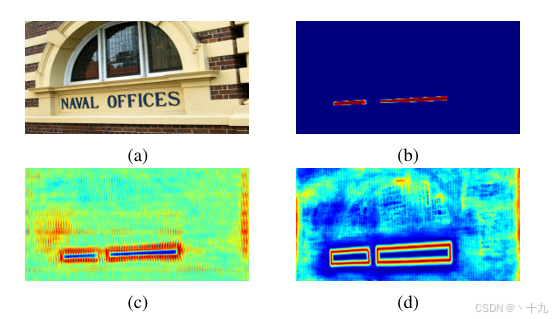
所以我们对于阈值图进行的是边界的监督,这对于后面对于训练数据的处理的理解也很重要。
(5)训练数据处理
由图片中文本区域所对应的矩形框坐标,是如何得到P、T、B呢?首先对于原图片进行尺寸变换,变换为模型输入的标准尺寸 640×640×3 对应的标注好的文本框也随比例进行缩放。然后得到输出图像image和标签contour。根据这个变换后的标签contou来计算P1和T1,P1对应下面图片中的蓝色框包含的区域,T1对应于下面的绿色和蓝色之间的区域,红黄色框为标签contour,B1由P1和T1根据DB算法计算得到,由此便得到了标签P1、T1、B1。如何由标签contour计算得到P1和T1呢?
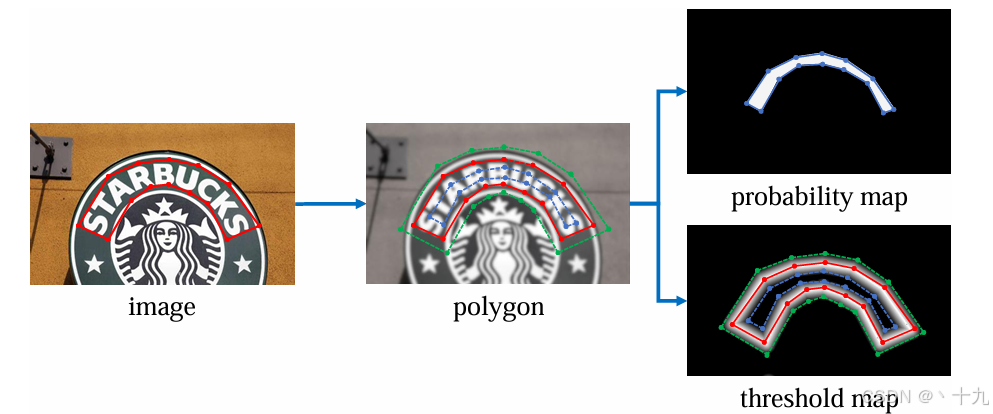
对于概率图P的label的生成:
基于PSEnet的启发,参考PSE网络,使用Vatti clipping算法,将原始的多边形文字区域G(红线区域)收缩到Gs(蓝线区域),收缩的偏移量D从原始多边形的周长和面积按照如下公式计算:
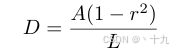
A是原始区域的面积,L是原始区域的周长,r是收缩系数,论文中依经验设置为r=0.4,实际情况按照自己的数据进行设置。最后生成的标签为:
整个蓝线区域内为文字区域,即标签为
1
,蓝线区域外为非文字区域,即标签为
0
。
整个蓝线区域内为文字区域,即标签为1,蓝线区域外为非文字区域,即标签为0。
整个蓝线区域内为文字区域,即标签为1,蓝线区域外为非文字区域,即标签为0。
对于阈值图T的label的生成:
通过类似的过程,为阈值图生成标签。首先将原始的多边形文字区域G(红线区域)扩张到Gd(绿线区域),收缩偏移量D同概率图中的D。将收缩框Gs(蓝线)和扩张框Gd(绿线)之间的区域 视为文本区域的边界,计算这个区域内每个像素点到原始图像边界G(红线)的归一化距离(最近线段的距离)。
计算完之后可以发现,扩张框绿线上的像素点和收缩框蓝线上的像素点到红线的归一化距离的值是最大的,并且文字红线上的像素点的值最小,为0。呈现出以红线为基准,向蓝线和绿线方向的值逐渐变大。
所以再对计算完的这些值进行归一化,也就是除以偏移量D,此时Gs(蓝线)和Gd(绿线区域)上的值变为1,再用1减去这些值最后得到红线上的值为1,Gs(蓝线)和Gd(绿线区域)线上的值为0。呈现出以红线为基准,向Gs和Gd方向的值逐渐变小。
此时Gs(蓝线)和Gd(绿线区域)区域内的值取值范围为[0,1],此时非文字Gs(蓝线)和Gd(绿线区域)区域之外的取值也是0。我们再次全图进行归一化,取值为(0, 1),比如0.2, 0.8, 0.4等等,这些数值也就是阈值图T最终的标签。需要注意的是,经过最后的归一化,文字区域也就是Gs(蓝线)内的区域,也会存在标签,论文中设置的是0.3,而靠近红线附近出最大为0.7。这就对应上边的对于阈值图进行的是边界的监督。蓝线到绿线之间的区域相当于阈值图的边界,这和概率图的区域内二值化并不相同!
此时,标签就已经生成。
(6)损失函数
有了前向传播的输出,有了标签,就可以计算损失了,损失函数为概率图的损失
L
s
L_s
Ls、二值化图的损失
L
b
L_b
Lb和阈值图的损失
L
t
L_t
Lt 的和:
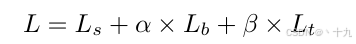
α和β分别设置为1和10,因为的
L
t
L_t
Lt 结果会影响到
L
b
L_b
Lb的结果,所以β设置为10。
L
s
L_s
Ls采用BCE Loss,
L
b
L_b
Lb采用Dice Loss,
L
t
L_t
Lt使用Gd中预测值和标签间的L1距离。
BCE Loss上文已经提到,这里就不做赘述,下面介绍一下Diceloss,:
Diceloss是目标检测中常用的损失函数,Dice loss 来自文章VNet(V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation),旨在应对语义分割中正负样本强烈不平衡的场景。dice coefficient定义如下:
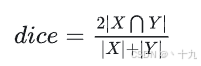
∣
X
⋂
Y
∣
| X \bigcap Y |
∣X⋂Y∣代表标签与输出的交集的像素点的数量,
∣
X
∣
|X|
∣X∣和
∣
Y
∣
|Y|
∣Y∣ 分别代表标签与输出的像素点数量
Diceloss公式:
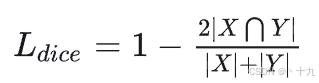
Gd中预测值和标签间的L1距离:
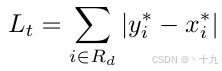
R
d
R_d
Rd是Gd区域内的像素,注意是Gd区域内的所有像素点都要算,不仅仅是Gd和Gs区域内的;
y
∗
y^*
y∗ 是阈值图的标签,
x
∗
x^*
x∗ 是模型对于阈值图的生成。
2.推理阶段
在推理时,采用概率图或近似二值图便可计算出文本框,为了方便,作者选择了概率图,这部分也是读者比较有疑问的地方,为什么不用阈值图呢,应该在训练阶段,阈值图参与监督训练,效果已经达到了。论文中根据概率图P计算得到文本框的步骤
可分为三个方面:
(1)使用固定阈值(0.2)对概率图(或近似二值图)进行二值化,得到二值图;
(2)从二值图中得到连通区域(收缩的文字区域);
(3)将收缩文字区域按Vatti clipping算法的偏移系数D’进行扩张得到最终文本框,D’的计算公式如下:
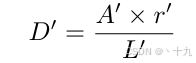
A
′
A'
A′、
L
′
L'
L′是收缩的文字区域的面积、周长,论文中,
r
′
r'
r′依经验设置为1.5(对应收缩比例r=0.4)。
至此,DBnet模型介绍完毕!读者可以参考源码来看此文章。
参考
手把手教你学DBNet
Real-time Scene Text Detection with Differentiable Binarization

















 3261
3261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









