






VSLAM学习2(适合小白学习)
尺度不确定性
对极几何存在的问题:根据对极约束求解得到的相机旋转运动R是准确的,平移运动t 是不具备真实尺度的。
初始化的纯旋转问题
从 E 分解到 R, t 的过程中,如果相机发生的是纯旋转,导致 t 为零,那么,得到的 E 也将为零,这将导致我们无从求解 R。不过,此时我们可以依靠 H 求取旋转,但仅有旋转时,我们无法用三角测量估计特征点的空间位置(这将在下文提到),于是,另一个 结论是,单目初始化不能只有纯旋转,必须要有一定程度的平移。如果没有平移,单目将无法初始化。在实践当中,如果初始化时平移太小,会使得位姿求解与三角化结果不稳定, 从而导致失败。相对的,如果把相机左右移动而不是原地旋转,就容易让单目 SLAM 初始化。因而有经验的 SLAM 研究人员,在单目 SLAM 情况下,经常选择让相机进行左右平 移以顺利地进行初始化。
三角化(三角测量)
之前,我们使用对极几何约束估计了相机运动。在得到运动之后,下一步我们需要用相机的运动估计特征点的空间位置。在单目 SLAM 中,仅通过单张图像无法获得像素的深度信息,我们需要通过三角测量(Triangulation)(或三角化)的方法来估计地图点的深度。
为什么要三角测量呢?
如果一直用对级几何求两帧之间的位姿的话,这样求得的两帧之间的t的尺度每一次都不固定,所以要先用三角测量算出一个深度,把尺度固定。三角化之后 就可以把地图和相机固定在一个尺度下,但是这个尺度还是不确定的。
三角测量是指,通过在两处观察同一个点的夹角,确定该点的距离。
三角测量(Triangulation)又叫三角化,是根据前后两帧图像中匹配到的特征点像素坐标以及两帧之间的相机运动R、t ,计算特征点三维空间坐标的一种算法。直观来讲,当有两个相对位置已知的相机同时拍摄到同一物体时,如何根据两幅图像中的信息估计出物体的实际位姿,即通过三角化获得二维图像上对应点的三维结构(3D坐标),这正是三角测量要解决的问题。
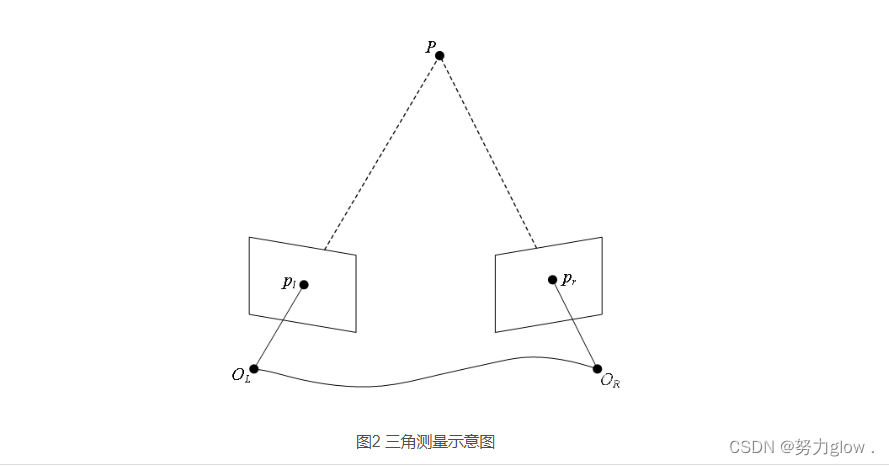
可以看出三角化的图和之前介绍的对极约束非常相似,但应该注意其中的区别。
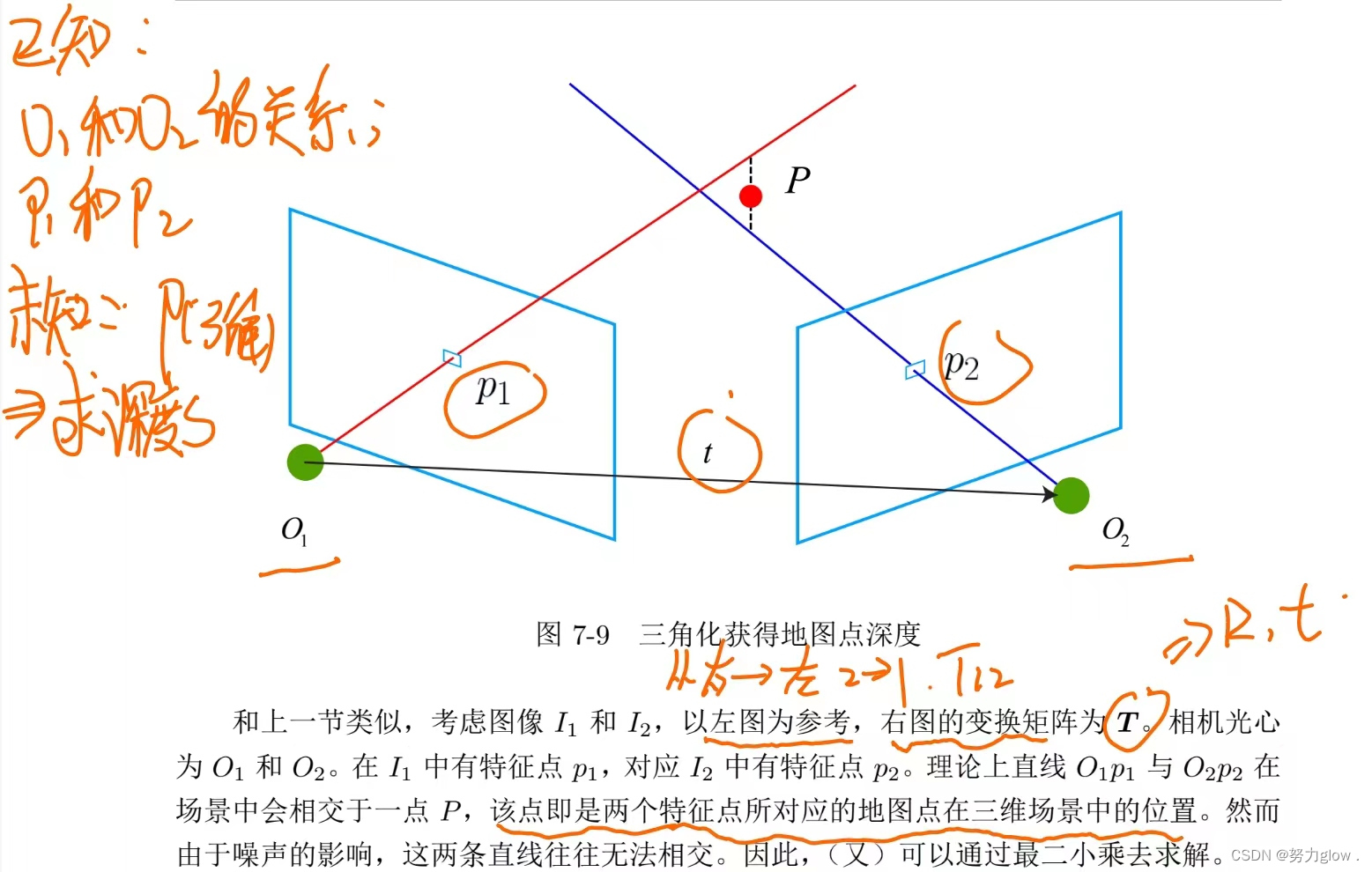

关于三角测量,还有一个必须注意的地方。 三角测量是由平移得到的,有平移才会有对极几何中的三角形,才谈的上三角测量。因 此,纯旋转是无法使用三角测量的,因为对极约束将永远满足。在平移存在的情况下,我 们还要关心三角测量的不确定性,这会引出一个三角测量的矛盾。
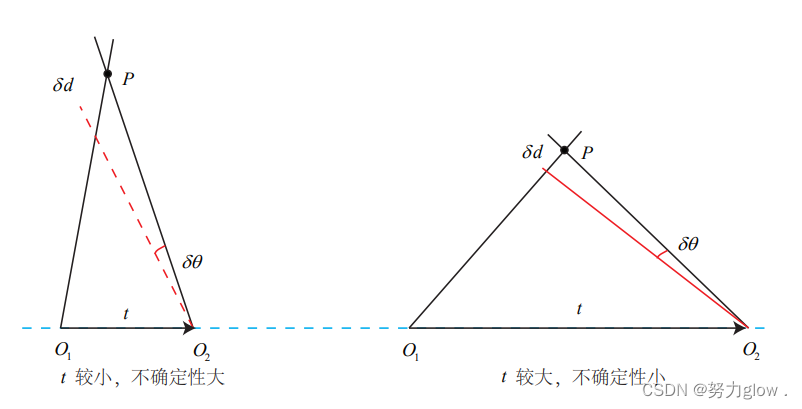
如上图所示,当平移很小时,像素上的不确定性将导致较大的深度不确定性。也就 是说,如果特征点运动一个像素 δx,使得视线角变化了一个角度 δθ,那么测量到深度值 将有 δd 的变化。从几何关系可以看到,当 t 较大时,δd 将明显变小,这说明平移较大时, 在同样的相机分辨率下,三角化测量将更精确。对该过程的定量分析可以使用正弦定理得 到,但我们这里先考虑定性分析。
因此,要增加三角化的精度,
-
其一是提高特征点的提取精度,也就是提高图像分辨率 ——但这会导致图像变大,提高计算成本。
-
另一方式是使平移量增大。但是,平移量增大会导致图像的外观发生明显的变化,比如箱子原先被挡住的侧面显示出来了,比如反射光 发生变化了,等等。外观变化会使得特征提取与匹配变得困难。总而言之,在增大平移,会导致匹配失效;而平移太小,则三角化精度不够——这就是三角化的矛盾。
三角化还存在一些问题:
- 例如相机前进时虽然有位移,但由于图像中心的点没有视差而无法三角化。(比如距离太远了,相机拍到的特征点就是几乎不动的)。
- R、T很小是或者相机移动过小可能导致两点趋近平行甚至发散:平行表现方式:行列式越近零两点关系越接近平行。越平行解得深度的质量越差;深度解出值为负表示两点关系发散。
讲一下三角化的代码:
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/calib3d/calib3d.hpp>
// #include "extra.h" // used in opencv2
using namespace std;
using namespace cv;
//函数声明 重点需要四个函数
//特征匹配(求取两帧图像中的特征点并进行特征点匹配)
void find_feature_matches (
const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches );
//2d-2d求变换矩阵R,t 为啥是2d呢,因为只有2d是不知道特征点的3d信息的,才需要三角测量
void pose_estimation_2d2d (
const std::vector<KeyPoint>& keypoints_1,
const std::vector<KeyPoint>& keypoints_2,
const std::vector< DMatch >& matches,
Mat& R, Mat& t );
//三角化(三角测量)
void triangulation (
const vector<KeyPoint>& keypoint_1,
const vector<KeyPoint>& keypoint_2,
const std::vector< DMatch >& matches,
const Mat& R, const Mat& t,
vector<Point3d>& points
);
// 像素坐标转相机归一化坐标
// 第一个参数为像素点p,p=(u,v),第二个参数是内参矩阵
Point2f pixel2cam( const Point2d& p, const Mat& K );
int main ( int argc, char** argv )
{
if ( argc != 3 )
{
cout<<"usage: triangulation img1 img2"<<endl;
return 1;
}
//-- 读取图像
Mat img_1 = imread ( argv[1], CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );
vector<KeyPoint> keypoints_1, keypoints_2;
vector<DMatch> matches;
//这里调用的是特征点匹配的函数,找到两个特征点之间的匹配关系,用于2D-2D
find_feature_matches ( img_1, img_2, keypoints_1, keypoints_2, matches );
cout<<"一共找到了"<<matches.size() <<"组匹配点"<<endl;
//-- 估计两张图像间运动
//这里可以看到是在三角化之前使用了对极约束计算出两张图像间的运动,也就是R,t
//因为三角化是需要已知R,t的。
Mat R,t;
pose_estimation_2d2d ( keypoints_1, keypoints_2, matches, R, t );
//-- 三角化
//再求得了R,t后,再求三维点坐标
vector<Point3d> points;
triangulation( keypoints_1, keypoints_2, matches, R, t, points );
//-- 验证三角化点与特征点的重投影关系
//其实这个地方是打印了每个空间点在两个相机坐标系的投影坐标和像素坐标,相当于是P的投影位置与看到的特征点位置。
//由于误差的存在,它们之间会有差异。
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
for ( int i=0; i<matches.size(); i++ )
{
// 将第一帧像素坐标转化为相机归一化坐标
Point2d pt1_cam = pixel2cam( keypoints_1[ matches[i].queryIdx ].pt, K );
// 将points(x, y, z)3D坐标转化为,第一帧相机归一化坐标
Point2d pt1_cam_3d(
points[i].x/points[i].z,
points[i].y/points[i].z
);
cout<<"point in the first camera frame: "<<pt1_cam<<endl;
cout<<"point projected from 3D "<<pt1_cam_3d<<", d="<<points[i].z<<endl;
// 第二个图
//将第二帧像素坐标转化为相机归一化坐标
Point2f pt2_cam = pixel2cam( keypoints_2[ matches[i].trainIdx ].pt, K );
//以上只作为对比
// 真正的重投影过程是下面这句:
// 通过方程x2 = R x1 + t 对第一帧3D坐标进行重投影,得到第二帧3D坐标
Mat pt2_trans = R*( Mat_<double>(3,1) << points[i].x, points[i].y, points[i].z ) + t;
//通过上面计算得到的第二帧3D点,除以z得到第二帧相机归一化坐标
pt2_trans /= pt2_trans.at<double>(2,0);
cout<<"point in the second camera frame: "<<pt2_cam<<endl;
//除以其深度值来计算归一化坐标(根据结果也能看出)
cout<<"point reprojected from second frame: "<<pt2_trans.t()<<endl;
cout<<endl;
}
return 0;
}
void find_feature_matches ( const Mat& img_1, const Mat& img_2,
std::vector<KeyPoint>& keypoints_1,
std::vector<KeyPoint>& keypoints_2,
std::vector< DMatch >& matches )
{
//-- 初始化
Mat descriptors_1, descriptors_2;
// used in OpenCV3
Ptr<FeatureDetector> detector = ORB::create();
Ptr<DescriptorExtractor> descriptor = ORB::create();
// use this if you are in OpenCV2
// Ptr<FeatureDetector> detector = FeatureDetector::create ( "ORB" );
// Ptr<DescriptorExtractor> descriptor = DescriptorExtractor::create ( "ORB" );
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create("BruteForce-Hamming");
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect ( img_1,keypoints_1 );
detector->detect ( img_2,keypoints_2 );
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute ( img_1, keypoints_1, descriptors_1 );
descriptor->compute ( img_2, keypoints_2, descriptors_2 );
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<DMatch> match;
// BFMatcher matcher ( NORM_HAMMING );
matcher->match ( descriptors_1, descriptors_2, match );
//-- 第四步:匹配点对筛选
double min_dist=10000, max_dist=0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for ( int i = 0; i < descriptors_1.rows; i++ )
{
double dist = match[i].distance;
if ( dist < min_dist ) min_dist = dist;
if ( dist > max_dist ) max_dist = dist;
}
printf ( "-- Max dist : %f \n", max_dist );
printf ( "-- Min dist : %f \n", min_dist );
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for ( int i = 0; i < descriptors_1.rows; i++ )
{
if ( match[i].distance <= max ( 2*min_dist, 30.0 ) )
{
matches.push_back ( match[i] );
}
}
}
void pose_estimation_2d2d (
const std::vector<KeyPoint>& keypoints_1,
const std::vector<KeyPoint>& keypoints_2,
const std::vector< DMatch >& matches,
Mat& R, Mat& t )
{
// 相机内参,TUM Freiburg2
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
//-- 把匹配点转换为vector<Point2f>的形式
vector<Point2f> points1;
vector<Point2f> points2;
for ( int i = 0; i < ( int ) matches.size(); i++ )
{
//pixel2cam(这不是opencv提供的),用来将像素坐标通过相机内参转化为归一化成像平面坐标
points1.push_back ( keypoints_1[matches[i].queryIdx].pt );
points2.push_back ( keypoints_2[matches[i].trainIdx].pt );
}
//-- 计算基础矩阵
Mat fundamental_matrix;
fundamental_matrix = findFundamentalMat ( points1, points2, CV_FM_8POINT );
cout<<"fundamental_matrix is "<<endl<< fundamental_matrix<<endl;
//-- 计算本质矩阵
Point2d principal_point ( 325.1, 249.7 ); //相机主点, TUM dataset标定值
int focal_length = 521; //相机焦距, TUM dataset标定值
Mat essential_matrix;
essential_matrix = findEssentialMat ( points1, points2, focal_length, principal_point );
cout<<"essential_matrix is "<<endl<< essential_matrix<<endl;
//-- 计算单应矩阵
Mat homography_matrix;
homography_matrix = findHomography ( points1, points2, RANSAC, 3 );
cout<<"homography_matrix is "<<endl<<homography_matrix<<endl;
//-- 从本质矩阵中恢复旋转和平移信息.
recoverPose ( essential_matrix, points1, points2, R, t, focal_length, principal_point );
cout<<"R is "<<endl<<R<<endl;
cout<<"t is "<<endl<<t<<endl;
}
void triangulation (
const vector< KeyPoint >& keypoint_1,
const vector< KeyPoint >& keypoint_2,
const std::vector< DMatch >& matches,
const Mat& R, const Mat& t,
vector< Point3d >& points )
{
//为啥T1是单位矩阵呢?
//我们以第一帧图像为参考,估计第二帧图像到第一帧图像的运动 也就T12
Mat T1 = (Mat_<float> (3,4) <<
1,0,0,0,
0,1,0,0,
0,0,1,0);
Mat T2 = (Mat_<float> (3,4) <<
R.at<double>(0,0), R.at<double>(0,1), R.at<double>(0,2), t.at<double>(0,0),
R.at<double>(1,0), R.at<double>(1,1), R.at<double>(1,2), t.at<double>(1,0),
R.at<double>(2,0), R.at<double>(2,1), R.at<double>(2,2), t.at<double>(2,0)
);
//内参已知
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
vector<Point2f> pts_1, pts_2;
for ( DMatch m:matches )
{
// 将像素坐标转换至相机坐标(准确来说是 将两帧图向中匹配好的特征点的像素坐标转换为相机归一化坐标)
//push_back()在vector尾部加入数据
pts_1.push_back ( pixel2cam( keypoint_1[m.queryIdx].pt, K) );
pts_2.push_back ( pixel2cam( keypoint_2[m.trainIdx].pt, K) );
}
// cv::triangulatePoints 函数接受的参数是两个相机位姿和特征点在两个相机坐标系下的坐标,输出三角化后的特征点的3D坐标。
// 3D世界坐标,也可能是第一帧相机坐标下的3D,不太确定,因为第一帧的时候,相机坐标系和世界坐标系重合。(考虑一下)
// 但需要注意的是,输出的3D坐标是齐次坐标,共四个维度,因此需要将前三个维度除以第四个维度以得到非齐次坐标xyz。
Mat pts_4d;
cv::triangulatePoints( T1, T2, pts_1, pts_2, pts_4d );
// 转换成非齐次坐标
for ( int i=0; i<pts_4d.cols; i++ )
{
Mat x = pts_4d.col(i);
x /= x.at<float>(3,0); // 归一化
//三个维度
Point3d p (
x.at<float>(0,0),
x.at<float>(1,0),
x.at<float>(2,0)
);
points.push_back( p );
}
}
//pixel2cam(意思是pixel像素 to camera相机)该函数的功能是完成两幅图像中匹配特征点的像素坐标到相机坐标的转换。
//最终的结果是得到一个2d的相机坐标(x,y),该坐标存储在pts_1与pts_2中。
Point2f pixel2cam ( const Point2d& p, const Mat& K )
{
return Point2f
(
( p.x - K.at<double>(0,2) ) / K.at<double>(0,0),
( p.y - K.at<double>(1,2) ) / K.at<double>(1,1)
);
}
以下是某一特征点的信息:
point in the first camera frame: [0.0844072, -0.0734976]
point projected from 3D [0.0843702, -0.0743606], d=14.9895
point in the second camera frame: [0.0431343, -0.0459876]
point reprojected from second frame: [0.04312769812378599, -0.04515455276163744, 1]
可以看到,误差的量级大约在小数点后第三位。可以看到,三角化特征点的距离大约 为 15。但由于尺度不确定性,我们并不知道这里的 15 究竟是多少米。
3D-2D PnP
已知3D点的空间位置和相机上的投影点,求相机的旋转和平移(外参)也就是R和t
3D:上一帧的相机坐标系下的3D点;
2D:两帧图片的匹配点信息,像素坐标。
解法:代数的解法/优化的解法
代数的:
-
DLT 直接线性变换
-
P3P 三对点估计位姿
-
EPnP/UPnP/…
优化的:Bundle Adjustment
下面介绍几种方法
DLT 直接线性变换




这里有个疑惑啊,高博在视频里讲解说:

“需要将t组成的矩阵投影SO(3)” 这里t是平移向量,[R|t]组成的变换矩阵,虽然与SE(3)中的变换矩阵T不同,但是个人认为这个地方含有旋转和平移,应该是重投影到SE(3)。
P3P 的原理:为了求解 PnP,利用了三角形相似性质,求解投影 点 a, b, c 在相机坐标系下的 3D 坐标,最后把问题转换成一个 3D 到 3D 的位姿估计问题。 而带有匹配信息的 3D-3D 位姿求解非常容易,所以这种思路是非常有效的。其 他的一些方法,例如 EPnP,亦采用了这种思路。然而,P3P 也存在着一些问题:
- P3P 只利用三个点的信息。当给定的配对点多于 3 组时,难以利用更多的信息。
- 如果 3D 点或 2D 点受噪声影响,或者存在误匹配,则算法失效。
EPnP、UPnP :它们利用更多的信息,而 且用迭代的方式对相机位姿进行优化,以尽可能地消除噪声的影响。不过,相对于 P3P 来 说,原理会更加复杂一些。
具体推理过程就不具体细说了,在 SLAM 当中,通常的做法是先使用 P3P/EPnP 等方法估计相机位姿,然后构建最 小二乘优化问题对估计值进行调整(Bundle Adjustment)。
BA
由于数据有噪声,往往一些线性的关系没法完美成立,所以考虑非线性优化。
PnP的优化解法:Bundle Adjustment
除了使用线性方法之外,我们可以把 PnP 问题构建成一个定义于李代数上的非线性 最小二乘问题。前面说的线性方法,往往是先求相机位姿,再求空间点位置,而非线性优化则是把它们都看成优化变量,放在一起优化。这是 一种非常通用的求解方式,我们可以用它对 PnP 或 ICP 给出的结果进行优化。在 PnP 中, 这个 Bundle Adjustment 问题,是一个最小化重投影误差(Reprojection error)的问 题。


注意: 为啥只取前3维呢?因为exp (ξ ∧) Pi 结果是 4 × 1 的,而它左侧的 K 是 3 × 3 的,所以必须把 exp (ξ ∧) Pi 的前三维取出来,变 成三维的非齐次坐标。(根据前面的公式)


于是,我们推导了观测相机方程关于相机位姿与特征点的两个导数矩阵。它们十分重 要,能够在优化过程中提供重要的梯度方向,指导优化的迭代。
用 OpenCV 提供的 EPnP 求 解 PnP 问题,然后通过 g2o 对结果进行优化。由于我们引入了新的深度信息导致t有误差。 不过,由于相机采集的深度图本身会有一些误差,所以这里的 3D 点也不是准确的。我 们会希望把位姿 ξ 和所有三维特征点 P 同时优化。
/*
g2o提供 VertexSE3Expmap(李代数位姿)、VertexSBAPointXYZ(空间点位置)和 EdgeProjectXYZ2UV(投影方程边)这三个类
*/
/*
我们首先声明了 g2o 图优化,配置优化求解器和梯度下降方法,然后根据估计到的特征点,将位姿和空间点放到图中。最后调用优化函数进行求解
*/
void bundleAdjustment (
const vector< Point3f > points_3d,
const vector< Point2f > points_2d,
const Mat& K,
Mat& R, Mat& t )
{
// 初始化g2o
typedef g2o::BlockSolver< g2o::BlockSolverTraits<6,3> > Block; // pose 维度为 6, landmark 维度为 3
Block::LinearSolverType* linearSolver = new g2o::LinearSolverCSparse<Block::PoseMatrixType>(); // 线性方程求解器
Block* solver_ptr = new Block ( linearSolver ); // 矩阵块求解器
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg ( solver_ptr );
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm ( solver );
// vertex
//李代数位姿(相机的位姿)
g2o::VertexSE3Expmap* pose = new g2o::VertexSE3Expmap(); // camera pose
Eigen::Matrix3d R_mat;
//
R_mat <<
R.at<double> ( 0,0 ), R.at<double> ( 0,1 ), R.at<double> ( 0,2 ),
R.at<double> ( 1,0 ), R.at<double> ( 1,1 ), R.at<double> ( 1,2 ),
R.at<double> ( 2,0 ), R.at<double> ( 2,1 ), R.at<double> ( 2,2 );
pose->setId ( 0 );
pose->setEstimate ( g2o::SE3Quat (
R_mat,
Eigen::Vector3d ( t.at<double> ( 0,0 ), t.at<double> ( 1,0 ), t.at<double> ( 2,0 ) )
) );
optimizer.addVertex ( pose );
int index = 1;
for ( const Point3f p:points_3d ) // landmarks
{
//空间点位置(3D)
g2o::VertexSBAPointXYZ* point = new g2o::VertexSBAPointXYZ();
point->setId ( index++ );
point->setEstimate ( Eigen::Vector3d ( p.x, p.y, p.z ) );
point->setMarginalized ( true ); // g2o 中必须设置 marg 参见第十讲内容
optimizer.addVertex ( point );
}
//该函数中的camera是要求用户设置的,在配置SparseOptimizer的时候传入相机参数,
// parameter: camera intrinsics
g2o::CameraParameters* camera = new g2o::CameraParameters (
K.at<double> ( 0,0 ), Eigen::Vector2d ( K.at<double> ( 0,2 ), K.at<double> ( 1,2 ) ), 0
);
camera->setId ( 0 );
optimizer.addParameter ( camera );
// edges
index = 1;
for ( const Point2f p:points_2d )
{
//表示投影方程的边
g2o::EdgeProjectXYZ2UV* edge = new g2o::EdgeProjectXYZ2UV();
edge->setId ( index );
edge->setVertex ( 0, dynamic_cast<g2o::VertexSBAPointXYZ*> ( optimizer.vertex ( index ) ) );
edge->setVertex ( 1, pose );
edge->setMeasurement ( Eigen::Vector2d ( p.x, p.y ) );
edge->setParameterId ( 0,0 );
edge->setInformation ( Eigen::Matrix2d::Identity() );
optimizer.addEdge ( edge );
index++;
}
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
optimizer.setVerbose ( true );
optimizer.initializeOptimization();//初始化
optimizer.optimize ( 100 );//迭代100次
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>> ( t2-t1 );
cout<<"optimization costs time: "<<time_used.count() <<" seconds."<<endl;
cout<<endl<<"after optimization:"<<endl;
cout<<"T="<<endl<<Eigen::Isometry3d ( pose->estimate() ).matrix() <<endl;
}
结果:

迭代 11 轮后,LM 发现优化目标函数接近不变,于是停止了优化。我们输出了最后得 到位姿变换矩阵 T,对比之前直接做 PnP 的结果,大约在小数点后第三位发生了一些变 化。这主要是由于我们同时优化了特征点和相机位姿导致的。
Bundle Adjustment 是一种通用的做法。它可以不限于两个图像。我们完全可以放入 多个图像匹配到的位姿和空间点进行迭代优化,甚至可以把整个 SLAM 过程放进来。那种做法规模较大,主要在后端使用。在前端,我们通常考虑局部相机位姿和特征点的小型 Bundle Adjustment 问题,希望实时对它进行求解和优化
ICP 3D-3D
假设我们有一组配对好的 3D 点(比如我 们对两个 RGB-D 图像进行了匹配):
P = {p1, . . . , pn}, P ′ = {p ′ 1 , . . . , p ′ n},
现在,想要找一个欧氏变换 R, t,
使得: ∀i, pi = Rp′ i + t.
这个问题可以用迭代最近点(Iterative Closest Point, ICP)求解。3D-3D 位姿估计问题中,并没有出现相机模型,也就是说,仅考虑两组 3D 点之间的变换时,和相机并没有关系。因此,在激光 SLAM 中也会碰到 ICP,不过由于激光数据特征 不够丰富,我们无从知道两个点集之间的匹配关系,只能认为距离最近的两个点为同一个, 所以这个方法称为迭代最近点。而在视觉中,特征点为我们提供了较好的匹配关系,所以 整个问题就变得更简单了。在 RGB-D SLAM 中,可以用这种方式估计相机位姿。 ICP 指代匹配好的两组点间运动估计问题。 和 PnP 类似,ICP 的求解也分为两种方式:利用线性代数的求解(主要是 SVD),以 及利用非线性优化方式的求解(类似于 Bundle Adjustment)。下面分别来介绍它们。
SVD





BA
求解 ICP 的另一种方式是使用非线性优化,以迭代的方式去找最优值。该方法和我们前面讲的 PnP 非常相似。以李代数表达位姿时,目标函数可以写成:(最小重投影误差)
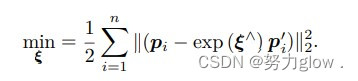
单个误差项关于位姿导数(矩阵)已经在前面推导过了,使用李代数扰动模型即可:

于是,在非线性优化中只需不断迭代,我们就能找到极小值。而且,可以证明 ICP 问题存在唯一解或无穷多解(极端情况下)的情况。
无穷多解:点都在一条线上,旋转绕着线转。
在唯一解的情况下,只要我们能找到极小值解,那么 这个极小值就是全局最优值——因此不会遇到局部极小而非全局最小的情况。这也意味着 ICP 求解可以任意选定初始值。这是已经匹配点时求解 ICP 的一大好处。
需要说明的是,我们这里讲的 ICP,是指已经由图像特征给定了匹配的情况下,进行 位姿估计的问题。在匹配已知的情况下,这个最小二乘问题实际上具有解析解(用SVD当初普通矩阵求), 所以并没有必要进行迭代优化。所以ICP 的研究者们往往更加关心匹配未知的情况。不过,在 RGB-D SLAM 中,由于一个像素的深度数据可能测量不到,所以我们可以混合着使用 PnP 和 ICP 优化:
- 对于深度已知的特征点,用建模它们的 3D-3D 误差
- 对于深度未知的特征 点,则建模 3D-2D 的重投影误差。于是,可以将所有的误差放在同一个问题中考虑,使得求解更加方便。
这里只看一下SVD的部分
void pose_estimation_3d3d (
const vector<Point3f>& pts1,
const vector<Point3f>& pts2,
Mat& R, Mat& t
)
{
Point3f p1, p2; // center of mass
int N = pts1.size();
//求质心
for ( int i=0; i<N; i++ )
{
p1 += pts1[i];
p2 += pts2[i];
}
p1 = Point3f( Vec3f(p1) / N);
p2 = Point3f( Vec3f(p2) / N);
//去质心
vector<Point3f> q1 ( N ), q2 ( N ); // remove the center
for ( int i=0; i<N; i++ )
{
q1[i] = pts1[i] - p1;
q2[i] = pts2[i] - p2;
}
// compute q1*q2^T
//根据公式 计算R,t矩阵
Eigen::Matrix3d W = Eigen::Matrix3d::Zero();
for ( int i=0; i<N; i++ )
{
W += Eigen::Vector3d ( q1[i].x, q1[i].y, q1[i].z ) * Eigen::Vector3d ( q2[i].x, q2[i].y, q2[i].z ).transpose();
}
cout<<"W="<<W<<endl;
// SVD on W
Eigen::JacobiSVD<Eigen::Matrix3d> svd ( W, Eigen::ComputeFullU|Eigen::ComputeFullV );
Eigen::Matrix3d U = svd.matrixU();
Eigen::Matrix3d V = svd.matrixV();
if (U.determinant() * V.determinant() < 0)
{
for (int x = 0; x < 3; ++x)
{
U(x, 2) *= -1;
}
}
cout<<"U="<<U<<endl;
cout<<"V="<<V<<endl;
Eigen::Matrix3d R_ = U* ( V.transpose() );
Eigen::Vector3d t_ = Eigen::Vector3d ( p1.x, p1.y, p1.z ) - R_ * Eigen::Vector3d ( p2.x, p2.y, p2.z );
// convert to cv::Mat
R = ( Mat_<double> ( 3,3 ) <<
R_ ( 0,0 ), R_ ( 0,1 ), R_ ( 0,2 ),
R_ ( 1,0 ), R_ ( 1,1 ), R_ ( 1,2 ),
R_ ( 2,0 ), R_ ( 2,1 ), R_ ( 2,2 )
);
t = ( Mat_<double> ( 3,1 ) << t_ ( 0,0 ), t_ ( 1,0 ), t_ ( 2,0 ) );
}
非线性优化来计算 ICP。我们依然使用李代数来表达相机位姿。与 SVD 思路不同的地方在于,在优化中我们不仅考虑相机的位姿,同时会优化 3D 点的空间 位置。对我们来说,RGB-D 相机每次可以观测到路标点的三维位置,从而产生一个 3D 观 测数据。不过,由于 g2o/sba 中没有提供 3D 到 3D 的边,而我们又想使用 g2o/sba 中李 代数实现的位姿节点,所以最好的方式是自定义一种这样的边,并向 g2o 提供解析求导方 式。
//g2o edge
class EdgeProjectXYZRGBDPoseOnly : public g2o::BaseBinaryEdge<3, Eigen::Vector3d,g2o::VertexSBAPointXYZ, g2o::VertexSE3Expmap>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
EdgeProjectXYZRGBDPoseOnly( ) {}
virtual void computeError()
{
const g2o::VertexSBAPointXYZ * point = dynamic_cast< const g2o::VertexSBAPointXYZ *> ( _vertices[0] );
const g2o::VertexSE3Expmap * pose = dynamic_cast<const g2o::VertexSE3Expmap*> ( _vertices[1] );
// measurement is p, point is p'
//pose->estimate().map( _point );中用estimate()估计一个值后,然后用映射函数 就是旋转加平移 将其_point映射到另一个相机坐标系下去
//观测值 - 映射值 因为我们做的试验是3D-3D 所以这里把第一帧的3D坐标当做测量值,然后把第二帧坐标映射到第一帧坐标系中
_error = _measurement - pose->estimate().map( point->estimate() );
}
//表示线性化 误差函数 就是要计算雅克比矩阵
virtual void linearizeOplus()override final //这里override 表示override覆盖基类的同名同参函数, final表示派生类的某个函数不能覆盖这个函数
{
g2o::VertexSE3Expmap* pose = dynamic_cast<g2o::VertexSE3Expmap *> (_vertices[1]);
g2o::VertexSBAPointXYZ * point = dynamic_cast< g2o::VertexSBAPointXYZ * > (_vertices[0] );
g2o::SE3Quat T(pose->estimate());
Eigen::Vector3d xyz_trans = T.map( point->estimate() );//映射到第二帧相机坐标系下的坐标值
double x = xyz_trans[0]; //第一帧到第二帧坐标系下变换后的坐标值
double y = xyz_trans[1];
double z = xyz_trans[2];
//关于空间点的雅克比矩阵-R
_jacobianOplusXi = -T.rotation().toRotationMatrix();
//3x6的关于优化变量的雅克比矩阵 公式
_jacobianOplusXj(0,0) = 0;
_jacobianOplusXj(0,1) = -z;
_jacobianOplusXj(0,2) = y;
_jacobianOplusXj(0,3) = -1;
_jacobianOplusXj(0,4) = 0;
_jacobianOplusXj(0,5) = 0;
_jacobianOplusXj(1,0) = z;
_jacobianOplusXj(1,1) = 0;
_jacobianOplusXj(1,2) = -x;
_jacobianOplusXj(1,3) = 0;
_jacobianOplusXj(1,4) = -1;
_jacobianOplusXj(1,5) = 0;
_jacobianOplusXj(2,0) = -y;
_jacobianOplusXj(2,1) = x;
_jacobianOplusXj(2,2) = 0;
_jacobianOplusXj(2,3) = 0;
_jacobianOplusXj(2,4) = 0;
_jacobianOplusXj(2,5) = -1;
}
bool read ( istream& in ) {}
bool write ( ostream& out ) const {}
};
这是一个一元边,写法类似于前面提到的 g2o::EdgeSE3ProjectXYZ,不过观测量从 2 维变成了 3 维,内部没有相机模型,并且只关联到一个节点。注意这里雅可比矩阵 的书写,它必须与我们前面的推导一致。雅可比矩阵给出了关于相机位姿的导数,是一个 3 × 6 的矩阵。
需要说明的是,在本例的 ICP 中,我们使用了在两个图都有深度读数的特征点。然而, 事实上,只要其中一个图深度确定,我们就能用类似于 PnP 的误差方式,把它们也加到优化中来。
视觉里程计2(光流法与直接法)
直接法是视觉里程计另一主要分支,它与特征点法有很大不同。虽然它还没有成为现 在 VO 中的主流,但经过近几年的发展,直接法在一定程度上已经能和特征点法平分秋色。
回顾一下特征点估计的步骤:
特征点法流程:
1.在图像中提取特征点并计算特征描述
2.在不同图像中寻找特征匹配
3.利用匹配点信息计算相机位姿
尽管特征点法在视觉里程计中占据主流地位,但是它至少有以下几个缺点:
- 关键点的提取与描述子的计算非常耗时。实践当中,SIFT 目前在 CPU 上是无法实 时计算的,而 ORB 也需要近 20 毫秒的计算。如果整个 SLAM 以 30 毫秒/帧的速 度运行,那么一大半时间都花在计算特征点上。
- 使用特征点时,忽略了除特征点以外的所有信息。一张图像有几十万个像素,而特征 点只有几百个。只使用特征点丢弃了大部分可能有用的图像信息。
- 相机有时会运动到特征缺失的地方,往往这些地方没有明显的纹理信息。例如,有时 我们会面对一堵白墙,或者一个空荡荡的走廓。这些场景下特征点数量会明显减少, 我们可能找不到足够的匹配点来计算相机运动。
不使用特征匹配的思路:
通过其他方式寻找配对点:光流(本质不是特征匹配,而是跟踪)
不需要配对点:直接法
光流法





注解:
-
可以看成最小化像素误差的非线性优化
-
每次使用了Taylor一阶近似,在离优化点较远时效果不佳,往往需要迭代多次
-
运动较大时要使用金字塔
-
可以用于跟踪图像中的稀疏关键点的运动轨迹
-
得到配对点后,后续计算与特征法VO中相同(PnP,ICP)
-
按方法可分为正向/反向+平移/组合的方式
对第一张图像提取 FAST 角点,然后用 LK 光流跟踪它们,并画在图中
LK光流法的步骤:
1.对第一帧提取FAST特征点存到keypoints中
2.对其他帧用LK跟踪特征点
3.更新keypoints列表,从prev_keypoints到next_keypoints
4.画出 keypoints圆圈
#include <iostream>
#include<fstream>//fstream是对文件操作的头文件
#include <list>
#include <vector>
#include <chrono>//与时间有关的库
using namespace std;
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/video/tracking.hpp>
//光流法需要include<opencv2/video/tracking.hpp>,用到列表,所以要include<list><vector>
int main( int argc, char** argv )
{
if ( argc != 2 )//启动条件,判断程序是否打开一个文件夹
{
cout<<"usage: useLK path_to_dataset"<<endl;
return 1;
}
string path_to_dataset = argv[1];//获取命令行输入的文件名,也就是图像的存储路径,格式保存为string
string associate_file = path_to_dataset + "/associate.txt";//拼接,形成文件地址用于获取associate文件地址
ifstream fin( associate_file );//打开associate_file下的txt文件,以fin的方式打开,如果找不到文件则不会创建相关度的文件夹
string rgb_file, depth_file, time_rgb, time_depth;//因为associate文件的每一行分别是time_color,color,time_depth,depth.所以定义这4个路径,方便之后读取深度图和彩色图。
list< cv::Point2f > keypoints; // 因为要删除跟踪失败的点,使用list
cv::Mat color, depth, last_color;
for ( int index=0; index<100; index++ )
{
//读入颜色和深度图像
fin>>time_rgb>>rgb_file>>time_depth>>depth_file;
color = cv::imread( path_to_dataset+"/"+rgb_file );
depth = cv::imread( path_to_dataset+"/"+depth_file, -1 );
if (index ==0 )
{
// 对第一帧提取 FAST 特征点
vector<cv::KeyPoint> kps;
cv::Ptr<cv::FastFeatureDetector> detector = cv::FastFeatureDetector::create();
detector->detect( color, kps );//从color图提取特征点
for ( auto kp:kps )//该语句是auto循环,作用是把kps的值从前往后遍历并且赋值给kp,相当于完成了kp=kps
keypoints.push_back( kp.pt );//keypoints存储的是kp的坐标,list类型
last_color = color;
continue;
}
if ( color.data==nullptr || depth.data==nullptr )//如果color.data或者depth.date有一个为空指针,则continue进入下一次循环。
continue;
//
// 对其他帧用LK跟踪特征点
vector<cv::Point2f> next_keypoints; //定义了两个存储Point2f类的容器next_keypoints与prev_keypoints
vector<cv::Point2f> prev_keypoints;//分别用来存储当前帧(下一帧)通过光流跟踪得到的特征点的像素坐标
for ( auto kp:keypoints )//遍历第一帧提取出的特征
prev_keypoints.push_back(kp);//加入前一帧特征
vector<unsigned char> status;
vector<float> error;
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
//一个是next_keypoints,一个是prev_keypoints.一个表示光流法追踪的帧的特征点,一个表示之前帧检测到的特征点。
cv::calcOpticalFlowPyrLK( last_color, color, prev_keypoints, next_keypoints, status, error );//光流计算函数 (这里面会有一个图像金字塔,会记录每一个keypoint的估计结果 是对还是错)
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>( t2-t1 );
cout<<"LK Flow use time:"<<time_used.count()<<" seconds."<<endl;
// 把跟丢的点删掉
int i=0;
for ( auto iter=keypoints.begin(); iter!=keypoints.end(); i++)
{
if ( status[i] == 0 )
{
iter = keypoints.erase(iter);
continue;
}
*iter = next_keypoints[i];
iter++;
}
cout<<"tracked keypoints: "<<keypoints.size()<<endl;
if (keypoints.size() == 0)
{
cout<<"all keypoints are lost."<<endl;
break;
}
// 画出 keypoints 画圈圈 用于显示追踪结果
cv::Mat img_show = color.clone();
for ( auto kp:keypoints )
cv::circle(img_show, kp, 10, cv::Scalar(0, 240, 0), 1);
cv::imshow("corners", img_show);
cv::waitKey(0);
last_color = color;
}
return 0;
}

LK 光流跟踪能够直接得到特征点的对应关系。这个对应关系就像是描述子的 匹配,但实际上我们大多数时候只会碰到特征点跟丢的情况,而不太会遇到误匹配,这应该是光流相对于描述子的一点优势。
us[i] == 0 )
{
iter = keypoints.erase(iter);
continue;
}
*iter = next_keypoints[i];
iter++;
}
cout<<"tracked keypoints: "<<keypoints.size()<<endl;
if (keypoints.size() == 0)
{
cout<<"all keypoints are lost."<<endl;
break;
}
// 画出 keypoints 画圈圈 用于显示追踪结果
cv::Mat img_show = color.clone();
for ( auto kp:keypoints )
cv::circle(img_show, kp, 10, cv::Scalar(0, 240, 0), 1);
cv::imshow("corners", img_show);
cv::waitKey(0);
last_color = color;
}
return 0;
}
[外链图片转存中...(img-Dl9NhIzA-1713819552324)].assets/光流5.jpg)
LK 光流跟踪能够直接得到特征点的对应关系。这个对应关系就像是描述子的 匹配,但实际上我们大多数时候只会碰到特征点跟丢的情况,而不太会遇到误匹配,这应该是光流相对于描述子的一点优势。
但是,匹配描述子的方法在相机运动较大时仍能成功, 而光流必须要求相机运动是微小的。从这方面来说,光流的鲁棒性比描述子差一些。 最后,我们可以通过光流跟踪的特征点,用 PnP、ICP 或对极几何来估计相机运动, 这些方法在上一章中都讲过。总而言之,光流法可以加速基于特征点的视觉里程计算法,避免计算和匹配描述子的过程,但要求相机运动较慢(或采集频率较高)。















 3601
3601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









