






VSLAM学习记录3——总结VO部分并完成从0到1手写前端里程计VO
范数理解
我们都知道,函数与几何图形往往是有对应关系的,这个很好想象,特别是在三维以下的空间内,函数是几何图像的数学概括,而几何图像是函数的高度形象化,比如一个函数对应几何空间上若干点组成的图形。 但当函数与几何超出三维空间时,就难以获得较好的想象,于是就有了映射的概念,映射表达的就是一个集合通过某种关系转为另外一个集合。通常数学书是先说映射,然后再讨论函数,这是因为函数是映射的一个特例。 为了更好的在数学上表达这种映射关系,(这里特指线性关系)于是就引进了矩阵。这里的矩阵就是表征上述空间映射的线性关系。而通过向量来表示上述映射中所说的这个集合,而我们通常所说的基,就是这个集合的最一般关系。于是,我们可以这样理解,一个集合(向量),通过一种映射关系(矩阵),得到另外一个集合(另外一个向量)。
那么向量的范数表示这个原有集合的大小。
矩阵的范数表示这个变化过程的大小的一个度量。
简单说:
0范数表示向量中非零元素的个数(即为其稀疏度)。
1范数表示为:绝对值之和。
2范数则指模,即向量的大小(长度)
直接法


直接法根据像素的亮度信息来估计相机运动,不需要知道点之间的对应关系,而是通过最小化光度误差来求得。
回忆特征点法中,由于我们通过匹配描述子,知道了 p1, p2 的像素位置,所以可以计算重投影的位置(PnP中 BA——>最小重投影误差)。但在直接法中,由于没有特征匹配,我们无从知道哪一个 p2 与 p1 对应 着同一个点。直接法的思路是根据当前相机的位姿估计值,来寻找 p2 的位置。**但若相机位姿不够好,p2 的外观和 p1 会有明显差别。于是,为了减小这个差别,我们优化相机的位姿,来寻找与 p1 更相似的 p2。**这同样可以通过解一个优化问题,但此时最小化的不是 重投影误差,而是光度误差(Photometric Error),也就是 P 的两个像的亮度误差。


使用李代数解决求导问题的思路分为两种:
1、用李代数表示姿态,然后根据李代数加法对李代数求导。
2、对李群左乘或右乘微小扰动,然后对扰动求导,称为左扰动和右扰动模型。
对于第一种方法可以理解,求得的导数就是某函数关于李代数的导数。但是,对于第二种说法,一个函数对李群扰动进行求导得到的是什么呢?求得的导数有什么用呢?
比如一个观测方程的误差函数记作J,那么对于第一种方法,用J对李代数求导,然后不断迭代下降,可以通过不断改变李代数来最小化J,从而得到最合适的李代数,也就是位姿。
- 在使用高斯牛顿下降法优化的过程中需要求解增量方程,该过程会涉及到误差函数对ΔX求导。
把高斯牛顿法应用到SLAM中,用来优化观测方程的误差函数,变换矩阵SE(3)作为不断更新的量,越来越接近实际值,从而使误差函数不断减小。而这个过程中要求解增量方程中的ΔX就是SE(3)的扰动量!!求解过程中会计算误差函数对此扰动量的求导。也就用到了扰动模型!
- 为什么广泛使用扰动模型?
相比于直接对姿态求导,姿态的扰动为小量。我们对小量进行泰勒展开后,二阶以上的项都可以忽略(因为实在是太小了),只保留一阶导数,这样做的好处是线性化程度更高(相比于直接对姿态求导),泰克展开的拟合也更精确。而在BA优化的迭代求解中,要不断计算雅克比(一阶偏导数矩阵),如果我们把扰动作为状态量,梯度的计算会更精确,收敛也会更快。


小结:
从上面是推导可以看到,直接法的雅可比项有一个图像梯度因子
- 因此,在图像梯度不明显的地方,对相机运动估计的贡献就小
根据使用的图像信息不同(P的来源),可分为:
-
稀疏直接法:只处理稀疏角点或关键点
P 来自于稀疏关键点,我们称之为稀疏直接法。通常我们使用数百个至上千个关键 点,并且像 L-K 光流那样,假设它周围像素也是不变的。这种稀疏直接法不必计算 描述子,并且只使用数百个像素,因此速度最快,但只能计算稀疏的重构。
-
稠密直接法:使用所有像素
P 为所有像素,称为稠密直接法。稠密重构需要计算所有像素(一般几十万至几百万 个),因此多数不能在现有的 CPU 上实时计算,需要 GPU 的加速。但是,如前面 所讨论的,梯度不明显的点,在运动估计中不会有太大贡献,在重构时也会难以估计 位置。
-
半稠密直接法:使用部分梯度明显的像素
P 来自部分像素。我们看到式(8.16)中,如果像素梯度为零,整一项雅可比就为零, 不会对计算运动增量有任何贡献。因此,可以考虑只使用带有梯度的像素点,舍弃像 素梯度不明显的地方。这称之为半稠密(Semi-Dense)的直接法,可以重构一个半稠 密结构。
从稀疏到稠密重构,都可以用直接法来计算。它们的计算量是逐渐增长的。 稀疏方法可以快速地求解相机位姿,而稠密方法可以建立完整地图。具体使用哪种方法,需要视机器人的应用环境而定。特别地,在低端的计算平台上,稀疏直接法可以做到非常快 速的效果,适用于实时性较高且计算资源有限的场合
实践
为了保持程序简单,我们使用 RGB-D 数据而非单目数据,这样可 以省略掉单目的深度恢复部分。基于特征点的深度恢复已经介绍过了(三角测量)。所以我们来考虑 RGB-D 上的稀疏直接法 VO。 由于求解直接法最后等价于求解一个优化问题,因此我们可以使用 g2o 或 Ceres 这些 优化库帮助我们求解。
在使用 g2o 之前,需要把直接法抽象成一个图优化问题。显然,直接法是由以下顶点和边组成的:
- 优化变量为一个相机位姿,因此需要一个位姿顶点。由于我们在推导中使用了李代 数,故程序中使用李代数表达的 SE(3) 位姿顶点。(初始位姿)
- 误差项为单个像素的光度误差。由于整个优化过程中 I1(p1) 保持不变,我们可以把 它当成一个固定的预设值,然后调整相机位姿,使 I2(p2) 接近这个值。于是,这种 边只连接一个顶点,为一元边。由于 g2o 中本身没有计算光度误差的边,我们需要 自己定义一种新的边。
直接法图优化问题是由一个相机位姿顶点与许多条一元边组成的。 如果使用稀疏的直接法,那我们大约会有几百至几千条这样的边;稠密直接法则会有几十万条边。优化问题对应的线性方程是计算李代数增量,本身规模不大(6×6),所以主要的计算时间会花费在每条边的误差与雅可比的计算上。
稀疏直接法
#include <iostream>
#include <fstream>
#include <list>
#include <vector>
#include <chrono>
#include <ctime>
#include <climits>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <g2o/core/base_unary_edge.h>
#include <g2o/core/block_solver.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
#include <g2o/solvers/dense/linear_solver_dense.h>
#include <g2o/core/robust_kernel.h>
#include <g2o/types/sba/types_six_dof_expmap.h>
using namespace std;
using namespace g2o;
/********************************************
* 本节演示了RGBD上的稀疏直接法
********************************************/
//这里定义了一个结构体Measurement,用来方便存储每次测量得到的值。
//同时定义了结构体的构造函数:其内部有两个成员变量,分别为三维向量pos_world与浮点数grayscale,
//用来分别存储某个特征点的相机坐标与灰度值。这里其实将Measurement定义为一个class的结果也是一样的。
// 一次测量的值,包括一个世界坐标系下三维点与一个灰度值
struct Measurement
{
Measurement ( Eigen::Vector3d p, float g ) : pos_world ( p ), grayscale ( g ) {}
Eigen::Vector3d pos_world; //三维世界坐标
float grayscale; //h灰度值
};
//这里定义了两个内联函数project2Dto3D与project3Dto2D,分别返回一个三维坐标与一个二维坐标,
//用于进行相机坐标与像素坐标的转化。这里使用内联函数是为了提高程序的运行效率。
inline Eigen::Vector3d project2Dto3D ( int x, int y, int d, float fx, float fy, float cx, float cy, float scale )
{
float zz = float ( d ) /scale;
float xx = zz* ( x-cx ) /fx;
float yy = zz* ( y-cy ) /fy;
return Eigen::Vector3d ( xx, yy, zz );
}
inline Eigen::Vector2d project3Dto2D ( float x, float y, float z, float fx, float fy, float cx, float cy )
{
float u = fx*x/z+cx;
float v = fy*y/z+cy;
return Eigen::Vector2d ( u,v );
}
// 直接法估计位姿
// 输入:测量值(空间点的灰度),新的灰度图,相机内参; 输出:相机位姿
// 返回:true为成功,false失败
//这个函数声明则是本程序的重点:poseEstimationDirect,即用来使用直接法进行位姿估计。
//传入的参数有一个存储Measurement类变量的容器,一个指向Mat类的指针,一个3×3的矩阵,和一个4×4的矩阵,
//分别存储了特征点的空间位置及灰度信息、当前帧的图像、相机内参、解算出的位姿。
bool poseEstimationDirect ( const vector<Measurement>& measurements, cv::Mat* gray, Eigen::Matrix3f& intrinsics, Eigen::Isometry3d& Tcw );
// project a 3d point into an image plane, the error is photometric error
// an unary edge with one vertex SE3Expmap (the pose of camera)
//这里定义了一个边,继承自BaseUnaryEdge,在模板参数中填入测量值的维度、类型,以及连接此边的顶点。
//同时其内部定义了两个虚函数computeError与linearizeOplus,分别用来计算误差与雅可比矩阵。
//在定义完边之后,便可直接在g2o中使用此类型的边进行优化。
class EdgeSE3ProjectDirect: public BaseUnaryEdge< 1, double, VertexSE3Expmap>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
EdgeSE3ProjectDirect() {}
//构造函数
EdgeSE3ProjectDirect ( Eigen::Vector3d point, float fx, float fy, float cx, float cy, cv::Mat* image )
: x_world_ ( point ), fx_ ( fx ), fy_ ( fy ), cx_ ( cx ), cy_ ( cy ), image_ ( image )
{}
virtual void computeError()
{
const VertexSE3Expmap* v =static_cast<const VertexSE3Expmap*> ( _vertices[0] );
Eigen::Vector3d x_local = v->estimate().map ( x_world_ );
float x = x_local[0]*fx_/x_local[2] + cx_;
float y = x_local[1]*fy_/x_local[2] + cy_;
// check x,y is in the image
if ( x-4<0 || ( x+4 ) >image_->cols || ( y-4 ) <0 || ( y+4 ) >image_->rows )
{
_error ( 0,0 ) = 0.0;
this->setLevel ( 1 );
}
else
{
// 注意我们在程序中的误差计算里,使用了 I2(p2) − I1(p1) 的形式,因此前面的负号可以省去,只需把像素梯度乘以像素到李代数的梯度即可。
_error ( 0,0 ) = getPixelValue ( x,y ) - _measurement;
}
}
// plus in manifold
virtual void linearizeOplus( )
{
if ( level() == 1 )
{
_jacobianOplusXi = Eigen::Matrix<double, 1, 6>::Zero();
return;
}
VertexSE3Expmap* vtx = static_cast<VertexSE3Expmap*> ( _vertices[0] );
Eigen::Vector3d xyz_trans = vtx->estimate().map ( x_world_ ); // q in book
double x = xyz_trans[0];
double y = xyz_trans[1];
double invz = 1.0/xyz_trans[2];
double invz_2 = invz*invz;
float u = x*fx_*invz + cx_;
float v = y*fy_*invz + cy_;
// jacobian from se3 to u,v
// NOTE that in g2o the Lie algebra is (\omega, \epsilon), where \omega is so(3) and \epsilon the translation
Eigen::Matrix<double, 2, 6> jacobian_uv_ksai;
jacobian_uv_ksai ( 0,0 ) = - x*y*invz_2 *fx_;
jacobian_uv_ksai ( 0,1 ) = ( 1+ ( x*x*invz_2 ) ) *fx_;
jacobian_uv_ksai ( 0,2 ) = - y*invz *fx_;
jacobian_uv_ksai ( 0,3 ) = invz *fx_;
jacobian_uv_ksai ( 0,4 ) = 0;
jacobian_uv_ksai ( 0,5 ) = -x*invz_2 *fx_;
jacobian_uv_ksai ( 1,0 ) = - ( 1+y*y*invz_2 ) *fy_;
jacobian_uv_ksai ( 1,1 ) = x*y*invz_2 *fy_;
jacobian_uv_ksai ( 1,2 ) = x*invz *fy_;
jacobian_uv_ksai ( 1,3 ) = 0;
jacobian_uv_ksai ( 1,4 ) = invz *fy_;
jacobian_uv_ksai ( 1,5 ) = -y*invz_2 *fy_;
Eigen::Matrix<double, 1, 2> jacobian_pixel_uv;
jacobian_pixel_uv ( 0,0 ) = ( getPixelValue ( u+1,v )-getPixelValue ( u-1,v ) ) /2;
jacobian_pixel_uv ( 0,1 ) = ( getPixelValue ( u,v+1 )-getPixelValue ( u,v-1 ) ) /2;
_jacobianOplusXi = jacobian_pixel_uv*jacobian_uv_ksai;
}
// dummy read and write functions because we don't care...
virtual bool read ( std::istream& in ) {}
virtual bool write ( std::ostream& out ) const {}
protected:
//相机位姿是用浮点数表示的,投影到像素坐标也是浮点形式。为了更精细地计算像素亮度,我们要对图像进行插值。我们这里采用了简单的双线性插值,也可以使用更复杂的插值方式,但计算代价可能会变高一些。
// get a gray scale value from reference image (bilinear interpolated)
//在我们迭代的dx,dy不是整数时,如何获取像素灰度值?采用双线性插值的方法
//灰度值函数是对图像进行双线性插值得到的,下面是具体实现
inline float getPixelValue ( float x, float y )
{
//image_为Mat*类型,图像指针,所以调用data时用->符号,
//data为图像矩阵首地址,支持数组形式访问,data[]就是访问到像素的值了,此处为像素的灰度值,类型为uchar
//data[]中括号的式子有点复杂,总的意思就是y行乘上每行内存数,定位到行,然后在加上x,定位到像素
//image_->data[int(y)*image_->step + int(x)]这一步读到了x,y处的灰度值,类型为uchar,
//但是后面由于线性插值,需要定位这个像素的位置,而不是他的灰度值,所以取其地址,记住它的位置,后面使用
uchar* data = & image_->data[ int ( y ) * image_->step + int ( x ) ];
//由于x,y这里有可能带小数,但是像素位置肯定是整数,所以,问题来了,(1.2, 4.5)像素坐标处的灰度值为多少呢?OK,线性插值!
//说一下floor(),std中的cmath函数。向下取整,返回不大于x的整数。例floor(4.9)=4
//xx和yy,就是取到小数部分。例:x=4.9的话,xx=x-floor(x)就为0.9。y同理
float xx = x - floor ( x );
float yy = y - floor ( y );
return float (
( 1-xx ) * ( 1-yy ) * data[0] +
xx* ( 1-yy ) * data[1] +
( 1-xx ) *yy*data[ image_->step ] +
xx*yy*data[image_->step+1]
);
}
public:
Eigen::Vector3d x_world_; // 3D point in world frame
float cx_=0, cy_=0, fx_=0, fy_=0; // Camera intrinsics
cv::Mat* image_=nullptr; // reference image
};
int main ( int argc, char** argv )
{
//输入的参数依然为data文件夹的存储路径,argc的判别值为2。
if ( argc != 2 )
{
cout<<"usage: useLK path_to_dataset"<<endl;
return 1;
}
//利用系统时间,近似随机地生成随机数种子。
srand ( ( unsigned int ) time ( 0 ) );
string path_to_dataset = argv[1];
string associate_file = path_to_dataset + "/associate.txt";
ifstream fin ( associate_file );
string rgb_file, depth_file, time_rgb, time_depth;
cv::Mat color, depth, gray;
//这里就是那个测量值数组,应该就是一堆灰度值
vector<Measurement> measurements;
// 相机内参
float cx = 325.5;
float cy = 253.5;
float fx = 518.0;
float fy = 519.0;
//这里设置了单位换算比例,RGBD相机出来的单位是毫米,而三维世界空间点坐标单位是米
float depth_scale = 1000.0;
Eigen::Matrix3f K;
K<<fx,0.f,cx,0.f,fy,cy,0.f,0.f,1.0f;
Eigen::Isometry3d Tcw = Eigen::Isometry3d::Identity();
//这里的prev_color就是指第一帧,因为整个程序中,只在第一帧中对它赋值了,之后再也没动过
//也就是还是整个过程的参考帧就只有第一帧,而不是循环流动用当前帧的上一帧做参考帧
cv::Mat prev_color;
// 我们以第一个图像为参考,对后续图像和参考图像做直接法
for ( int index=0; index<10; index++ )
{
cout<<"*********** loop "<<index<<" ************"<<endl;
fin>>time_rgb>>rgb_file>>time_depth>>depth_file;
color = cv::imread ( path_to_dataset+"/"+rgb_file );
depth = cv::imread ( path_to_dataset+"/"+depth_file, -1 );
if ( color.data==nullptr || depth.data==nullptr )
continue;
//调用OpenCV内置的图像颜色空间转换函数cvtColor将RGB图像color转为灰度图gray,
// 在之后的直接法求取位姿中使用灰度图作为每一帧图像输入。
cv::cvtColor ( color, gray, cv::COLOR_BGR2GRAY );
if ( index ==0 )
{
// 对第一帧提取FAST特征点
vector<cv::KeyPoint> keypoints;
cv::Ptr<cv::FastFeatureDetector> detector = cv::FastFeatureDetector::create();
detector->detect ( color, keypoints );
// 去掉邻近边缘处的点(半稠密不需要这一块)
/***
这里进行了几次判断,分别判断首帧特征点的像素坐标是否在图像边缘20像素的范围内,以及特征点所查询到的的深度值是否为零。
去掉不符合标准的特征点后,调用project2Dto3D计算特征点的3d坐标,
并查询该特征点像素坐标所对应的深度信息,最后一并存入容器measurements中。
进而,使用计算好的特征点深度信息与灰度值信息,调用poseEstimationDirect函数进行直接法的位姿求取。
求取得到相机位姿变换矩阵Tcw后将其进行输出展示,并利用其进行计算特征点在当前帧中的位置,
最后进行圈画并以图片的形式进行展示。
***/
for ( auto kp:keypoints )
{
// 去掉邻近边缘处的点
//判断首帧特征点的像素坐标是否在图像边缘20像素的范围内
if ( kp.pt.x < 20 || kp.pt.y < 20 || ( kp.pt.x+20 ) >color.cols || ( kp.pt.y+20 ) >color.rows )
continue;
ushort d = depth.ptr<ushort> ( cvRound ( kp.pt.y ) ) [ cvRound ( kp.pt.x ) ];
//特征点所查询到的的深度值是否为零
if ( d==0 )
continue;
Eigen::Vector3d p3d = project2Dto3D ( kp.pt.x, kp.pt.y, d, fx, fy, cx, cy, depth_scale );
float grayscale = float ( gray.ptr<uchar> ( cvRound ( kp.pt.y ) ) [ cvRound ( kp.pt.x ) ] );
measurements.push_back ( Measurement ( p3d, grayscale ) );
}
prev_color = color.clone();
continue;
}
// 使用直接法计算相机运动
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
//调用poseEstimationDirect函数进行直接法的位姿求取
poseEstimationDirect ( measurements, &gray, K, Tcw );
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>> ( t2-t1 );
cout<<"direct method costs time: "<<time_used.count() <<" seconds."<<endl;
cout<<"Tcw="<<Tcw.matrix() <<endl;
// plot the feature points
cv::Mat img_show ( color.rows*2, color.cols, CV_8UC3 );
prev_color.copyTo ( img_show ( cv::Rect ( 0,0,color.cols, color.rows ) ) );
color.copyTo ( img_show ( cv::Rect ( 0,color.rows,color.cols, color.rows ) ) );
//这些代码便是将每一帧图像与第一帧进行拼接,并将两帧图像中的特征点进行圈画及连线。
for ( Measurement m:measurements )
{
// 这是为了适当减少所圈画的特征点的个数,即只取五分之一的特征点进行展示
if ( rand() > RAND_MAX/5 )
continue;
Eigen::Vector3d p = m.pos_world;
Eigen::Vector2d pixel_prev = project3Dto2D ( p ( 0,0 ), p ( 1,0 ), p ( 2,0 ), fx, fy, cx, cy );
Eigen::Vector3d p2 = Tcw*m.pos_world;
Eigen::Vector2d pixel_now = project3Dto2D ( p2 ( 0,0 ), p2 ( 1,0 ), p2 ( 2,0 ), fx, fy, cx, cy );
if ( pixel_now(0,0)<0 || pixel_now(0,0)>=color.cols || pixel_now(1,0)<0 || pixel_now(1,0)>=color.rows )
continue;
float b = 255*float ( rand() ) /RAND_MAX;
float g = 255*float ( rand() ) /RAND_MAX;
float r = 255*float ( rand() ) /RAND_MAX;
cv::circle ( img_show, cv::Point2d ( pixel_prev ( 0,0 ), pixel_prev ( 1,0 ) ), 8, cv::Scalar ( b,g,r ), 2 );
cv::circle ( img_show, cv::Point2d ( pixel_now ( 0,0 ), pixel_now ( 1,0 ) +color.rows ), 8, cv::Scalar ( b,g,r ), 2 );
cv::line ( img_show, cv::Point2d ( pixel_prev ( 0,0 ), pixel_prev ( 1,0 ) ), cv::Point2d ( pixel_now ( 0,0 ), pixel_now ( 1,0 ) +color.rows ), cv::Scalar ( b,g,r ), 1 );
}
cv::imshow ( "result", img_show );
cv::waitKey ( 0 );
}
return 0;
}
bool poseEstimationDirect ( const vector< Measurement >& measurements, cv::Mat* gray, Eigen::Matrix3f& K, Eigen::Isometry3d& Tcw )
{
// 初始化g2o
typedef g2o::BlockSolver<g2o::BlockSolverTraits<6,1>> DirectBlock; // 求解的向量是6*1的 灰度值是一维,李代数是6维
DirectBlock::LinearSolverType* linearSolver = new g2o::LinearSolverDense< DirectBlock::PoseMatrixType > ();
DirectBlock* solver_ptr = new DirectBlock ( linearSolver );
// g2o::OptimizationAlgorithmGaussNewton* solver = new g2o::OptimizationAlgorithmGaussNewton( solver_ptr ); // G-N
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg ( solver_ptr ); // L-M
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm ( solver );
optimizer.setVerbose( true );
g2o::VertexSE3Expmap* pose = new g2o::VertexSE3Expmap();
pose->setEstimate ( g2o::SE3Quat ( Tcw.rotation(), Tcw.translation() ) );
pose->setId ( 0 );
optimizer.addVertex ( pose );
// 添加边
int id=1;
for ( Measurement m: measurements )
{
EdgeSE3ProjectDirect* edge = new EdgeSE3ProjectDirect (
m.pos_world,
K ( 0,0 ), K ( 1,1 ), K ( 0,2 ), K ( 1,2 ), gray
);
edge->setVertex ( 0, pose );
edge->setMeasurement ( m.grayscale );
edge->setInformation ( Eigen::Matrix<double,1,1>::Identity() );
edge->setId ( id++ );
optimizer.addEdge ( edge );
}
cout<<"edges in graph: "<<optimizer.edges().size() <<endl;
optimizer.initializeOptimization();
optimizer.optimize ( 30 );
Tcw = pose->estimate();
}
半稠密
/********************************************
* 本节演示了RGBD上的半稠密直接法
********************************************/
//这里的prev_color就是指第一帧,因为整个程序中,只在第一帧中对它赋值了,之后再也没动过
//也就是还是整个过程的参考帧就只有第一帧,而不是循环流动用当前帧的上一帧做参考帧
cv::Mat prev_color;
// 我们以第一个图像为参考,对后续图像和参考图像做直接法
for ( int index=0; index<10; index++ )
{
cout<<"*********** loop "<<index<<" ************"<<endl;
fin>>time_rgb>>rgb_file>>time_depth>>depth_file;
color = cv::imread ( path_to_dataset+"/"+rgb_file );
depth = cv::imread ( path_to_dataset+"/"+depth_file, -1 );
if ( color.data==nullptr || depth.data==nullptr )
continue;
//调用OpenCV内置的图像颜色空间转换函数cvtColor将RGB图像color转为灰度图gray,在之后的直接法求取位姿中使用灰度图作为每一帧图像输入。
cv::cvtColor ( color, gray, cv::COLOR_BGR2GRAY );
if ( index ==0 )
{
// select the pixels with high gradiants
// 对第一帧提取FAST特征点
for ( int x=10; x<gray.cols-10; x++ )
for ( int y=10; y<gray.rows-10; y++ )
{
//灰度值与像素值的关系: 如果对于一张本身就是灰度图像(8位灰度图像)来说,他的像素值就是它的灰度值,如果是一张彩色图像,则它的灰度值需要经过函数映射来得到。
//灰度图像是由纯黑和纯白来过渡得到的,在黑色中加入白色就得到灰色,纯黑和纯白按不同的比例来混合就得到不同的灰度值。
//R=G=B=255为白色,R=G=B=0为黑色,R=G=B=小于255的某个整数时,此时就为某个灰度值。
//这里就是梯度向量delta,可以看一下,
//它是以(x,y)像素右减左像素灰度差为x方向梯度值,
// 以(x,y)像素下减上像素灰度差为y方向梯度值。
//发现(x,y)处的像素梯度跟(x,y)处的灰度值没啥关系,只跟它的上下左右的像素有关
Eigen::Vector2d delta (
gray.ptr<uchar>(y)[x+1] - gray.ptr<uchar>(y)[x-1],
gray.ptr<uchar>(y+1)[x] - gray.ptr<uchar>(y-1)[x]
);
//如果模长小于50,即任务就是梯度不明显,continue掉,其他的就开始对应深度和空间点,往measurements中push了
//说白了跟稀疏的比就是在第一帧中多取了一些点而已。稠密的就是不用说了,所有点全push进measurements
if ( delta.norm() < 50 )
continue;
ushort d = depth.ptr<ushort> (y)[x];
if ( d==0 )
continue;
Eigen::Vector3d p3d = project2Dto3D ( x, y, d, fx, fy, cx, cy, depth_scale );
float grayscale = float ( gray.ptr<uchar> (y) [x] );
measurements.push_back ( Measurement ( p3d, grayscale ) );
}
prev_color = color.clone();
cout<<"add total "<<measurements.size()<<" measurements."<<endl;
continue;
}
直接法的讨论
相比于特征点法,直接法完全依靠优化来求解相机位姿。从式(8.16)中可以看到,像 素梯度引导着优化的方向。如果我们想要得到正确的优化结果,就必须保证大部分像素梯 度能够把优化引导到正确的方向。
举例:
假设对于参考图像,我们 测量到一个灰度值为 229 的像素。并且,由于我们知道它的深度,可以推断出空间点 P 的 位置(图 8-6 中在 I1 中测量到的灰度)
此时我们又得到了一张新的图像,需要估计它的相机位姿。这个位姿是由一个初值不 断地优化迭代得到的。假设我们的初值比较差,在这个初值下,空间点 P 投影后的像素灰度值是 126。于是,这个像素的误差为 229 − 126 = 103。为了减小这个误差,我们希望微调相机的位姿,使像素更亮一些。 怎么知道往哪里微调,像素会更亮呢?这就需要用到局部的像素梯度。我们在图像中 发现,沿 u 轴往前走一步,该处的灰度值变成了 123,即减去了 3。同样地,沿 v 轴往前 走一步,灰度值减 18,变成 108。在这个像素周围,我们看到梯度是 [−3, −18],为了提高 亮度,会建议优化算法微调相机,使 P 的像往左上方移动。在这个过程中,我们用像 素的局部梯度近似了它附近的灰度分布,不过请注意真实图像并不是光滑的,所以这个梯度在远处就不成立了。
但是,优化算法不能只听这个像素的一面之词,还需要听取其他像素的建议。综合听 取了许多像素的意见之后,优化算法选择了一个和我们建议的方向偏离不远的地方,计算出一个更新量 exp(ξ ∧)(扰动模型)。加上更新量后,图像从 I2 移动到了 I ′ 2,像素的投影位置也变到了 一个更亮的地方。我们看到,通过这次更新,误差变小了。在理想情况下,我们期望误差会不断下降,最后收敛。
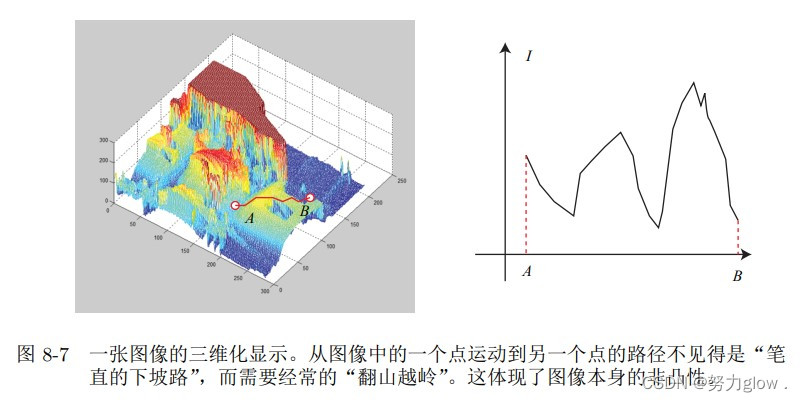
**但是实际是不是这样呢?**我们是否真的只要沿着梯度方向走,就能走到一个最优值?注意到,直接法的梯度是直接由图像梯度确定的,因此我们必须保证沿着图像梯度走时,灰度误差会不断下降。然而,图像通常是一个很强烈的非凸函数,如图 8-7 所示。实际当中, 如果我们沿着图像梯度前进,很容易由于图像本身的非凸性(或噪声)落进一个局部极小值中,无法继续优化。只有当相机运动很小,图像中的梯度不会有很强的非凸性时,直接 法才能成立。 在例程中,我们只计算了单个像素的差异,并且这个差异是由灰度直接相减得到的。 然而,单个像素没有什么区分性,周围很可能有好多像素和它的亮度差不多。所以,我们有时会使用小的图像块(patch),并且使用更复杂的差异度量方式,例如归一化相关性 (Normalized Cross Correlation,NCC)等。(上述的代码实现里用的是误差的平方和)
直接法优缺点总结
优点如下:
- 可以省去计算特征点、描述子的时间。
- 只要求有像素梯度即可,无须特征点。因此,直接法可以在特征缺失的场合下使用。 比较极端的例子是只有渐变的一张图像。它可能无法提取角点类特征,但可以用直接 法估计它的运动。
- 可以构建半稠密乃至稠密的地图,这是特征点法无法做到的。
另一方面,它的缺点也很明显:
- 非凸性——直接法完全依靠梯度搜索,降低目标函数来计算相机位姿。其目标函数中 需要取像素点的灰度值,而图像是强烈非凸的函数。这使得优化算法容易进入极小, 只在运动很小时直接法才能成功。
- 单个像素没有区分度。找一个和他像的实在太多了!——于是我们要么计算图像块, 要么计算复杂的相关性。由于每个像素对改变相机运动的“意见”不一致。只能少数 服从多数,以数量代替质量。
- 灰度值不变是很强的假设。如果相机是自动曝光的,当它调整曝光参数时,会使得图像整体变亮或变暗。光照变化时亦会出现这种情况。特征点法对光照具有一定的容忍 性,而直接法由于计算灰度间的差异,整体灰度变化会破坏灰度不变假设,使算法失败。针对这一点,目前的直接法开始使用更细致的光度模型标定相机,以便在曝光时间变化时也能让直接法工作。
到此视觉里程计前端VO结束了
VSLAM(2022.10.2)
简单设计并实现VO
(从0到1搭建)
确定程序的框架
视觉里程计分单目、双目、RGB-D 三大类。单目视觉相对复杂,而 RGB-D 最为简单,没有初始化,也没有尺度问题。为了方便做实验,将使用数据集而非实际的 RGB-D 相机。
在编写一个小规模的库时,我们通常会建立一些文件夹,把源代码、头文件、文档、测试数据、配置文件、日志等等分类存放, 这样会显得很有条理。
- bin 用来存放可执行的二进制;
- include/myslam 存放 slam 模块的头文件,主要是.h。这种做法的理由是,当你把包 含目录设到 include 时,在引用自己的头文件时,需要写 include ”myslam/xxx.h”, 这样不容易和别的库混淆。
- src 存放源代码文件,主要是 cpp;
- test 存放测试用的文件,也是 cpp
- lib 存放编译好的库文件;
- config 存放配置文件;
- cmake_modules 第三方库的 cmake 文件,在使用 g2o 之类的库中会用到它。
确定基本数据结构
这好比构成房屋的一个个的柱子和砖块。那么,在一个 SLAM 程序中,有哪些结构是最基本的呢?我们抽象出几条基本概念:
-
帧:一个帧是相机采集到的图像单位。它主要包含一个图像(RGB-D 情形下是一对图像——>通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。)。此外,还有特征点、位姿、内参等信息。 在视觉 SLAM 中我们会谈论关键帧(Key-frame)。由于相机采集的数据很多,存储 所有的数据显然是不现实的。不然的话,如果相机放在桌上不动,程序的内存占用也 会越来越高最后导致无法接受。通常的做法是把某些我们认为更重要的帧保存起来, 并认为相机轨迹就可以用这些关键帧来描述。
-
路标:路标点即图像中的特征点。当相机运动之后,还能估计它们的 3D 位置。 通常,会把路标点放在一个地图当中,并将新来的帧与地图中的路标点进行匹配,估 计相机位姿。 帧的位姿与路标的位置估计相当于一个局部的 SLAM 问题。
除此之外,我们还需要一 些工具,让程序写起来更流畅。
例如:
- 配置文件:在写程序中你会经常遇到各种各样的参数,比如相机的内参、特征点的数 量、匹配时选择的比例等等。你可以把这些数写在程序中,但那不是一个好习惯。你 会经常修改这些参数,但每次修改后都要重新编译一遍程序。当它们数量越来越多 时,修改就变得越来越困难。所以,更好的方式是在外部定义一个配置文件,程序运 行时读取该配置文件中的参数值。这样,每次只要修改配置文件内容就行了,不必对 程序本身做任何修改。
- 坐标变换:你会经常需要在坐标系间进行坐标变换。例如世界坐标到相机坐标、相机 坐标到归一化相机坐标、归一化相机坐标到像素坐标等等。定义一个类把这些操作都 放在一起将更方便些。
所以下面我们就来定义帧、路标这几个概念,在 C++ 中都以类来表示。我们尽量保证 一个类有单独的头文件和源文件,避免把许多个类放在同一个文件中。然后,把函数声明 放在头文件,实现放在源文件里(除非函数很短,也可以写在头文件中)。在过程较为复杂的算法中,我们会把它分解成若干步骤,例如特征提取和匹配应该分别在不同的函数中实现,这样,当我们想修改算法流程时,就不需要修改整 个运行流程,只需调整局部的处理方式即可。
我们开始一共写五个类:Frame 为帧,Camera 为相机模型,MapPoint 为特征点/路标点,Map 管理特征点,Config 提供配置参数。
common_include.h
(只是一些常用头文件,省略)
camera.h
Camera 类存储相机的内参和外参,并完成相机坐标系、像素坐标系、和世界坐标系 之间的坐标变换。当然,在世界坐标系中需要一个相机的(变动的)外参,我们以参数 的形式传入
//ifndef 宏定义: 防止头文件重复引用的 。如果没有这个宏,在两处引用此头文件时将出现类的重复定义。
// #ifdef #define #endif
#ifndef CAMERA_H
#define CAMERA_H
//把一些常用的头文件放在一个 common_include.h 文件中,这样就可以避免每次书写一个很长的一串 include。
#include "myslam/common_include.h"
//用命名空间 namespace myslam 将类定义包裹起来,
//命名空间可以防止我们不小心定义出别的库里同名的函数,也是一种比较安全和规范的做法.
namespace myslam
{
// Pinhole RGBD camera model
class Camera
{
public:
//这是关于typedef的用法,定义新类型,在Camera类中不占据内存,只是定义了一个新类型,封装在了类中,便于使用。
//在里程计中,会构建比较多的类,也就有相应的封在类中的类型,在初始化新类的时候调用该类型即可,使用方便。
//shared_ptr是一种智能指针(smart pointer),作用如同指针,但会记录有多少个shared_ptrs共同指向一个对象。这便是所谓的引用计数(reference counting)。
//每个智能指针离开之间的作用域之后,计数器就会递减。一旦最后一个这样的指针被销毁,也就是一旦某个对象的引用计数变为0,这个对象会被自动删除。
typedef std::shared_ptr<Camera> Ptr;
//相机内参 depth_scale_:深度比例(对后面获取某点的深度进行一个比例缩放)
float fx_, fy_, cx_, cy_, depth_scale_; // Camera intrinsics
Camera();
//c++ 函数后面加一个冒号的含义: 冒号后面跟的是赋值,这种写法是C++的特性
//构造函数后加冒号是初始化表达式
Camera ( float fx, float fy, float cx, float cy, float depth_scale=0 ) :
fx_ ( fx ), fy_ ( fy ), cx_ ( cx ), cy_ ( cy ), depth_scale_ ( depth_scale )
{}
// coordinate transform: world, camera, pixel
//用 Sophus::SE3 来表达相机的位姿
//p_w是世界坐标系坐标,p_c是相机坐标系的坐标,T_w_c是相机外参(R与t),p_p是像素坐标系坐标。
//pixel2world的实现是能过两步实现的: pixel -> camera ,进而 camera -> world ,反之, world2pixel 也一样。
Vector3d world2camera( const Vector3d& p_w, const SE3& T_c_w );
Vector3d camera2world( const Vector3d& p_c, const SE3& T_c_w );
Vector2d camera2pixel( const Vector3d& p_c );
Vector3d pixel2camera( const Vector2d& p_p, double depth=1 );
Vector3d pixel2world ( const Vector2d& p_p, const SE3& T_c_w, double depth=1 );
Vector2d world2pixel ( const Vector3d& p_w, const SE3& T_c_w );
};
}
#endif // CAMERA_H
camera.cpp
#include "myslam/camera.h"
namespace myslam
{
Camera::Camera()
{
}
//世界to相机:w_to_c变换矩阵乘世界坐标系的点位
Vector3d Camera::world2camera ( const Vector3d& p_w, const SE3& T_c_w )
{
return T_c_w*p_w;
}
//相机to世界:c_to_w变换矩阵乘相机坐标系的点位置
Vector3d Camera::camera2world ( const Vector3d& p_c, const SE3& T_c_w )
{
return T_c_w.inverse() *p_c;
}
//相机to坐标系:书中公式5.5,p_c虽然是3*1矩阵,但如下输出没问题,和p_c(n)一样
Vector2d Camera::camera2pixel ( const Vector3d& p_c )
{
return Vector2d (
fx_ * p_c ( 0,0 ) / p_c ( 2,0 ) + cx_,
fy_ * p_c ( 1,0 ) / p_c ( 2,0 ) + cy_
);
}
//和上面相反
Vector3d Camera::pixel2camera ( const Vector2d& p_p, double depth )
{
return Vector3d (
( p_p ( 0,0 )-cx_ ) *depth/fx_,
( p_p ( 1,0 )-cy_ ) *depth/fy_,
depth
);
}
//pixel2world的实现是能过两步实现的: pixel -> camera ,进而 camera -> world ,反之, world2pixel 也一样。
Vector2d Camera::world2pixel ( const Vector3d& p_w, const SE3& T_c_w )
{
return camera2pixel ( world2camera ( p_w, T_c_w ) );
}
//p_p是像素坐标系坐标
Vector3d Camera::pixel2world ( const Vector2d& p_p, const SE3& T_c_w, double depth )
{
return camera2world ( pixel2camera ( p_p, depth ), T_c_w );
}
}
frame.h
这里的 Frame 类只提供基本的 数据存储和接口。
#ifndef FRAME_H
#define FRAME_H
#include "myslam/common_include.h"
#include "myslam/camera.h"
namespace myslam
{
// forward declare 前向声明
/* 1. 前向声明的类不能定义对象。
2. 可以用于定义指向这个类型的指针和引用。
2. 用于申明使用该类型作为形参或返回类型的函数。*/
class MapPoint;
//Frame 类只提供基本的数据存储和接口
class Frame
{
public:
typedef std::shared_ptr<Frame> Ptr;
unsigned long id_; // ID id of this frame
double time_stamp_; // 时间戳 when it is recorded
SE3 T_c_w_; // 位姿 transform from world to camera
Camera::Ptr camera_; // 相机 Pinhole RGBD Camera model
Mat color_, depth_; //彩色图和深度图 color and depth image
public: // data members
Frame();
Frame( long id, double time_stamp=0, SE3 T_c_w=SE3(), Camera::Ptr camera=nullptr, Mat color=Mat(), Mat depth=Mat() );
~Frame();
// factory function 创建 Frame
//静态函数 从实现来看就是调用了默认构造函数创建了个空白帧对象,唯一赋值的参数就是给id_赋了个值 (具体见实现的cpp)
static Frame::Ptr createFrame();
// find the depth in depth map 在color图寻找给定点对应的深度
double findDepth( const cv::KeyPoint& kp );
// Get Camera Center 获取相机光心
Vector3d getCamCenter() const;
// check if a point is in this frame 判断某个点是否在帧内
bool isInFrame( const Vector3d& pt_world );
};
}
#endif // FRAME_H
frame.cpp
#include "myslam/frame.h"
namespace myslam
{
Frame::Frame()
: id_(-1), time_stamp_(-1), camera_(nullptr)
{
}
Frame::Frame ( long id, double time_stamp, SE3 T_c_w, Camera::Ptr camera, Mat color, Mat depth )
: id_(id), time_stamp_(time_stamp), T_c_w_(T_c_w), camera_(camera), color_(color), depth_(depth)
{
}
Frame::~Frame()
{
}
Frame::Ptr Frame::createFrame()
{
//这里注意下,由factory_id++一个数去构造Frame对象时,调用的是默认构造函数,由于默认构造函数全都有默认值,所以就是按坑填,先填第一个id_,
//所以也就是相当于创建了一个只有ID号的空白帧。
static long factory_id = 0;
return Frame::Ptr( new Frame(factory_id++) );
}
//注意看这个函数参数类型是cv::KeyPoint&,所以也就是color图已经检测出keypoint了,需要去寻找depth
double Frame::findDepth ( const cv::KeyPoint& kp )
{
//cvRound()对一个 float 型的数进行四舍五入
int x = cvRound(kp.pt.x);
int y = cvRound(kp.pt.y);
//这个还是.ptr模板函数定位像素值的方法,记住用法
//这里的 depth_.ptr(y)[x] 就是指向depth _ 的第y 行的第x个数据,数据类型为无符号的短整型。
ushort d = depth_.ptr<ushort>(y)[x];
if ( d!=0 )
{
//读取的深度除以相机的深度比例尺得到这个点在彩色图当中的深度
return double(d)/camera_->depth_scale_;
}
else //为0的情况呢?这是实际中有可能遇到的坑。因为rgbd相机极有可能某个点没采集到深度值
{
// check the nearby points
//找最近的四个点 也就是上下左右 找到他们的深度计算然后返回
int dx[4] = {-1,0,1,0};
int dy[4] = {0,-1,0,1};
for ( int i=0; i<4; i++ )
{
d = depth_.ptr<ushort>( y+dy[i] )[x+dx[i]];
if ( d!=0 )
{
return double(d)/camera_->depth_scale_;
}
}
}
return -1.0; //如果还没有,就返回-1.0,表示访问失败
}
//取相机光心的话,这里注意!.translation()是取平移部分!不是取转置!!T_c_w_.inverse()求出来的平移部分就是R^(-1)*(-t),也就是相机坐标系下的(0,0,0)在世界坐标系下的坐标,也就是相机光心的世界坐标!
Vector3d Frame::getCamCenter() const
{
return T_c_w_.inverse().translation();
}
bool Frame::isInFrame ( const Vector3d& pt_world )
{
Vector3d p_cam = camera_->world2camera( pt_world, T_c_w_ );
if ( p_cam(2,0)<0 ) //小于0直接return false
return false;
Vector2d pixel = camera_->world2pixel( pt_world, T_c_w_ ); //世界坐标to像素坐标
return pixel(0,0)>0 && pixel(1,0)>0 //xy值都大于0并且小于color图的行列 则在帧内
&& pixel(0,0)<color_.cols
&& pixel(1,0)<color_.rows;
}
}
mappoint.h
MapPoint 表示路标点(特征点)。我们将估计它的世界坐标,并且我们会拿当前帧提取到的特征点与地图中的路标点匹配,来估计相机的运动,因此还需要存储它对应的描述子。此外, 我们会记录一个点被观测到的次数和被匹配到的次数,作为评价它的好坏程度的指标。
namespace myslam
{
//前向声明
class Frame;
class MapPoint
{
public:
typedef shared_ptr<MapPoint> Ptr;
unsigned long id_; // ID
Vector3d pos_; // 坐标
Vector3d norm_; // 归一化后的,代表了方向
Mat descriptor_; // 描述子
int observed_times_; // 被观测的次数
int correct_times_; // 被正确匹配的次数
MapPoint();
MapPoint( long id, Vector3d position, Vector3d norm );
// factory function 创建一个空白帧对象(创建特征点)
static MapPoint::Ptr createMapPoint();
};
}
#endif // MAPPOINT_H
mappoint.cpp
内容简单省略
map.h
Map 类管理着所有的路标点,并负责添加新路标、删除不好的路标等工作。VO 的匹配过程只需要和 Map 打交道即可。
#include "myslam/common_include.h"
#include "myslam/frame.h"
#include "myslam/mappoint.h"
namespace myslam
{
class Map
{
public:
typedef shared_ptr<Map> Ptr;
unordered_map<unsigned long, MapPoint::Ptr > map_points_; // 所有特征点
unordered_map<unsigned long, Frame::Ptr > keyframes_; // 所有关键帧
Map() {}
void insertKeyFrame( Frame::Ptr frame );
void insertMapPoint( MapPoint::Ptr map_point );
};
}
#endif // MAP_H
map.cpp
#include "myslam/map.h"
namespace myslam
{
void Map::insertKeyFrame ( Frame::Ptr frame )
{
cout<<"Key frame size = "<<keyframes_.size()<<endl;
//可能是这个意思,我还在思考。。原理上应该是关键帧里没有,那么插入
//根据帧的id去找这个帧的位置(序号)看是否与关键帧最后一位相等
if ( keyframes_.find(frame->id_) == keyframes_.end() )
{
//如果相等,则以pair形式插入该帧,该pair包括id和frame
//make_pair:无需写出类别, 就可以生成一个pair对象
//直观一点:std::make_pair(42, '@'); 而不必费力写成:std::pair<int, char>(42, '@')
keyframes_.insert( make_pair(frame->id_, frame) );
}
else
{
keyframes_[ frame->id_ ] = frame;
}
}
void Map::insertMapPoint ( MapPoint::Ptr map_point )
{
//地图点的插入 与上面思路一样
if ( map_points_.find(map_point->id_) == map_points_.end() )
{
map_points_.insert( make_pair(map_point->id_, map_point) );
}
else
{
map_points_[map_point->id_] = map_point;
}
}
}
config.h
Config 类负责参数文件的读取,并在程序任意地方都可随时提供参数的值。
config.cpp
(主要是读一些参数 内参啊之类的 不重要 省略)
至此,我们定义了 SLAM 程序的基本数据结构,书写了若干个基本类。这好比是造房子的砖头和水泥。
特征提取与匹配
下面我们来实现 VO,先来考虑特征点法。它 VO任务是,根据输入的图像,计算相 机运动和特征点位置。前面我们都讨论的是在两两帧间的位姿估计,然而我们将发现仅凭两帧的估计是不够的。我们会把特征点缓存成一个小地图,计算当前帧与地图之间的位置关系。但那样程序会复杂一些,所以,先暂时从两两帧间的运动估计出发。
两两帧的视觉里程计
如果像前面讲的一样,只关心两个帧之间的运动估计,并且不优化特征点的位置。然 而把估得的位姿“串”起来,也能得到一条运动轨迹。这种方式可以看成两两帧间的,无结构的 VO,实现起来最为简单,但是效果不佳。但是我们现在就是从简单入手,感受一下。

在这种 VO 里,我们定义了参考帧(Reference)和当前帧(Current)这两个概念。以参考帧为坐标系,我们把当前帧与它进行特 征匹配,并估计运动关系。假设参考帧相对世界坐标的变换矩阵为 Trw,当前帧与世界坐 标系间为 Tcw,则待估计的运动与这两个帧的变换矩阵构成左乘关系:
Tcr, s.t. Tcw = TcrTrw.
在 t − 1 到 t 时刻,我们以 t − 1 为参考,求取 t 时刻的运动。这可以通过特征点匹 配、光流或直接法得到,但这里我们只关心运动,不关心结构。换句话说,只要通过特征点成功求出了运动,我们就不再需要这帧的特征点了。这种做法当然会有缺陷,但是忽略掉数量庞大的特征点可以节省许多的计算量。然后,在 t 到 t + 1 时刻,我们又以 t 时刻 为参考帧,考虑 t 到 t + 1 间的运动关系。如此往复,就得到了一条运动轨迹。
在匹配特征点的方式中,最重要的参考帧与当前帧之间 的特征匹配关系,它的流程可归纳如下:
- 对新来的当前帧,提取关键点和描述子。
- 如果系统未初始化,以该帧为参考帧,根据深度图计算关键点的 3D 位置,返回 1。
- 估计参考帧与当前帧间的运动。
- 判断上述估计是否成功。
- 若成功,把当前帧作为新的参考帧,回 1。
- 若失败,计连续丢失帧数。当连续丢失超过一定帧数,置 VO 状态为丢失,算法 结束。若未超过,返回 1。
下面是实现
visual_odometry.h
namespace myslam
{
class VisualOdometry
{
public:
typedef shared_ptr<VisualOdometry> Ptr;
//定义枚举来表征VO状态,分别为:初始化、正常、丢失
enum VOState {
INITIALIZING=-1,
OK=0,
LOST
};
//这里为两两帧VO所用到的参考帧和当前帧。还有VO状态和整个地图。
VOState state_; // 当前VO状态
Map::Ptr map_; // 地图
Frame::Ptr ref_; // 参考帧
Frame::Ptr curr_; // 当前帧
//这里是两帧匹配需要的:keypoints,descriptors,matches
cv::Ptr<cv::ORB> orb_; // orb的检测与计算
vector<cv::Point3f> pts_3d_ref_; // 参考帧的3D点
vector<cv::KeyPoint> keypoints_curr_; // 当前帧的特征点
Mat descriptors_curr_; // 当前帧的描述子
Mat descriptors_ref_; // 参考帧的描述子
vector<cv::DMatch> feature_matches_; //特征匹配
//这里是匹配结果T,还有内点数和丢失数
SE3 T_c_r_estimated_; // 当前帧的估计位姿
int num_inliers_; // 好的特征点数量
int num_lost_; // 丢失数
// 参数
int num_of_features_; // 特征点数量
double scale_factor_; // 图像金字塔
int level_pyramid_; // 图像金字塔的层数
float match_ratio_; // 选择好的匹配的系数(匹配关系)
int max_num_lost_; // 持续丢失数量的最大值
int min_inliers_; // 最小内点数
//用于判定是否为关键帧的标准,就是规定一定幅度的旋转和平移,大于这个幅度就归为关键帧
double key_frame_min_rot; // 两个关键帧之间的最小旋转
double key_frame_min_trans; // 两个关键帧之间的最小平移
public: // functions
VisualOdometry();
~VisualOdometry();
//这个函数为核心处理函数,将帧添加进来,然后处理
bool addFrame( Frame::Ptr frame ); // 增加新的帧
protected:
// 内部处理函数(内点),用于特征匹配
void extractKeyPoints(); //提取特征点
void computeDescriptors(); //计算描述子
void featureMatching(); //特征匹配
void poseEstimationPnP(); //pnp位姿估计
void setRef3DPoints(); // 设置参考帧的3D点
//这里是关键帧的一些功能函数
void addKeyFrame(); //增加关键帧
bool checkEstimatedPose(); //根据内点(inlier)的数量及运动的大小做一个简单的检测:认为内点不可太少,而运动不可能过大。
bool checkKeyFrame(); //检查关键帧
};
}
visual_odometry.cpp
namespace myslam
{
//默认构造函数,提供默认值、读取配置参数
VisualOdometry::VisualOdometry() :
state_ ( INITIALIZING ), ref_ ( nullptr ), curr_ ( nullptr ), map_ ( new Map ), num_lost_ ( 0 ), num_inliers_ ( 0 )
{
num_of_features_ = Config::get<int> ( "number_of_features" );
scale_factor_ = Config::get<double> ( "scale_factor" );
level_pyramid_ = Config::get<int> ( "level_pyramid" );
match_ratio_ = Config::get<float> ( "match_ratio" );
max_num_lost_ = Config::get<float> ( "max_num_lost" );
min_inliers_ = Config::get<int> ( "min_inliers" );
key_frame_min_rot = Config::get<double> ( "keyframe_rotation" );
key_frame_min_trans = Config::get<double> ( "keyframe_translation" );
//这个create(),之前用的时候,都是用的默认值,所以没有任何参数,这里传入了一些参数,
orb_ = cv::ORB::create ( num_of_features_, scale_factor_, level_pyramid_ );
}
VisualOdometry::~VisualOdometry()
{
}
//最核心的函数:添加帧,参数即为新的一帧,根据VO当前状态选择是进行初始化还是计算T
bool VisualOdometry::addFrame ( Frame::Ptr frame )
{
//根据VO状态来进行不同处理
switch ( state_ )
{
//第一帧,则进行初始化
case INITIALIZING:
{
//更改状态为OK
state_ = OK;
//因为是初始化,所以当前帧和参考帧都是这个第一帧
curr_ = ref_ = frame;
//将此帧插入地图
map_->insertKeyFrame ( frame );
// 从这一帧中提取特征点
extractKeyPoints();
//计算描述子
computeDescriptors();
// compute the 3d position of features in ref frame
//这里提取出的特征点姚形成3D坐标,所以要调用set函数去求关键点的深度
setRef3DPoints();
break;
}
//如果VO状态为正常,则匹配并调用PnP()计算T
case OK:
{
curr_ = frame;
extractKeyPoints();
computeDescriptors();
featureMatching();
//位姿估计
poseEstimationPnP();
//根据位姿估计的结果进行检验
if ( checkEstimatedPose() == true ) // a good estimation
{
//如果是一个好的估计(检查内点和运动之后),计算当前位姿
curr_->T_c_w_ = T_c_r_estimated_ * ref_->T_c_w_; // T_c_w = T_c_r*T_r_w
//把当前帧赋值给参考帧,接下来,它将作为下一帧的参考帧
ref_ = curr_;
//补全参考帧的深度值,求参考帧的3D点
setRef3DPoints();
num_lost_ = 0;
//再检验是否为关键帧,是的话就加入关键帧(两帧之间的旋转和平移)
if ( checkKeyFrame() == true ) // is a key-frame
{
addKeyFrame();
}
}
else // 否则就是坏的估计(原因有很多)
{
//坏的估计则将丢失数+1
num_lost_++;
//判断是否大于这个最大丢失数,如果是,则切换VO状态为lost
if ( num_lost_ > max_num_lost_ )
{
state_ = LOST;
}
return false;
}
break;
}
case LOST:
{
cout<<"vo has lost."<<endl;
break;
}
}
return true;
}
//提取特征点
void VisualOdometry::extractKeyPoints()
{
orb_->detect ( curr_->color_, keypoints_curr_ );
}
//计算描述子
void VisualOdometry::computeDescriptors()
{
orb_->compute ( curr_->color_, keypoints_curr_, descriptors_curr_ );
}
//特征匹配
void VisualOdometry::featureMatching()
{
// 匹配参考帧和当前帧的描述子 使用暴力匹配
vector<cv::DMatch> matches;
cv::BFMatcher matcher ( cv::NORM_HAMMING );
matcher.match ( descriptors_ref_, descriptors_curr_, matches );
//寻找最小距离
//总之这的作用就是找到matches数组中最小的距离,然后赋值给min_dis
//std::min_element 用于寻找范围内的最小元素
float min_dis = std::min_element (
matches.begin(), matches.end(),
[] ( const cv::DMatch& m1, const cv::DMatch& m2 )
{
return m1.distance < m2.distance;
} )->distance;
//根据最小距离,对matches数组进行刷选,只有小于最小距离匹配比率或者小于30的才能push_back进数组。
//最终得到筛选过的,距离控制在一定范围内的可靠匹配
feature_matches_.clear();
for ( cv::DMatch& m : matches )
{
if ( m.distance < max<float> ( min_dis*match_ratio_, 30.0 ) )
{
feature_matches_.push_back(m);
}
}
cout<<"good matches: "<<feature_matches_.size()<<endl;
}
//新的帧来的时候,是一个2D数据,因为PNP需要的是参考帧的3D,当前帧的2D。
//所以在当前帧迭代为参考帧时,有个工作就是加上depth数据。也就是设置参考帧的3D点。
void VisualOdometry::setRef3DPoints()
{
// select the features with depth measurements
//3D点数组先清空,后面重新装入
pts_3d_ref_.clear();
//参考帧的描述子也是构建一个空Mat
descriptors_ref_ = Mat();
//对当前的特征点数组进行遍历
for ( size_t i=0; i<keypoints_curr_.size(); i++ )
{
//找到对应的深度数据赋值给d
double d = ref_->findDepth(keypoints_curr_[i]);
//如果大于0,则正确,进行构造
if ( d > 0)
{
//由像素坐标求得相机下的3D坐标
Vector3d p_cam = ref_->camera_->pixel2camera(
Vector2d(keypoints_curr_[i].pt.x, keypoints_curr_[i].pt.y), d
);
//坐标是列向量,所以按行push_back近参考帧的3D点
pts_3d_ref_.push_back( cv::Point3f( p_cam(0,0), p_cam(1,0), p_cam(2,0) ));
//参考帧描述子这里就按照当前帧描述子按行push_back。算出来的Mat类型的描述子,读取时需要遍历行。
descriptors_ref_.push_back(descriptors_curr_.row(i));
}
}
}
//核心:用PnP估计位姿
void VisualOdometry::poseEstimationPnP()
{
// 3D 2D
vector<cv::Point3f> pts3d;
vector<cv::Point2f> pts2d;
for ( cv::DMatch m:feature_matches_ )
{
//pts_3d_ref_本来就是3dpoint数组,所以直接定位索引就是3d点了
pts3d.push_back( pts_3d_ref_[m.queryIdx] );
//而这里keypoints_curr_是keypoint数组,所以定位索引后类型是keypoint,还需一步.pt获取关键点像素坐标。
pts2d.push_back( keypoints_curr_[m.trainIdx].pt );
}
//构造内参矩阵K
Mat K = ( cv::Mat_<double>(3,3)<<
ref_->camera_->fx_, 0, ref_->camera_->cx_,
0, ref_->camera_->fy_, ref_->camera_->cy_,
0,0,1
);
//旋转向量,平移向量,内点数组
Mat rvec, tvec, inliers;
//整个核心就是用这个cv::solvePnPRansac()去求解两帧之间的位姿变化
cv::solvePnPRansac( pts3d, pts2d, K, Mat(), rvec, tvec, false, 100, 4.0, 0.99, inliers );
//内点数量为内点行数,所以为列存储。
num_inliers_ = inliers.rows;
cout<<"pnp inliers: "<<num_inliers_<<endl;
//根据旋转和平移构造出当前帧相对于参考帧的T,这样一个T计算完成了。循环计算就能得到轨迹。
T_c_r_estimated_ = SE3(
SO3(rvec.at<double>(0,0), rvec.at<double>(1,0), rvec.at<double>(2,0)),
Vector3d( tvec.at<double>(0,0), tvec.at<double>(1,0), tvec.at<double>(2,0))
);
}
//简单的位姿检验函数 分为两点:内点不能过少,运动不能过大
bool VisualOdometry::checkEstimatedPose()
{
//这里简单的做一下位姿估计判断,主要有两个,一就是匹配点太少的话,直接false,
// 或者变换向量模长太大的话,也直接false
if ( num_inliers_ < min_inliers_ )
{
cout<<"reject because inlier is too small: "<<num_inliers_<<endl;
return false;
}
//将变换矩阵取log操作得到变换向量。
Sophus::Vector6d d = T_c_r_estimated_.log();
//根据变换向量的模长来判断运动的大小。过大的话返回false
if ( d.norm() > 5.0 )
{
cout<<"reject because motion is too large: "<<d.norm()<<endl;
return false;
}
//如果让面两项都没return,说明内点量不少,运动也没过大,是一个好的位姿估计,return true
return true;
}
bool VisualOdometry::checkKeyFrame()
{
//说一下这个是否为关键帧的判断,也很简单,
//关键帧并不是之前理解的轨迹比较长了,隔一段选取一个,
//而还是每一帧的T都判断一下,比较大就说明为关键帧,说明在这一帧中,要么平移比较大,要么拐弯导致旋转比较大,所以添加,
//如果在运动上一直就是小运动,运动多久都不会添加为关键帧。
//另外上方的判断T计算错误也是运动过大,但是量级不一样,判断计算错误是要大于5,
//而关键帧,在配置文件中看只需要0.1就定义为关键帧了,所以0.1到5的差距,导致这两个函数并不冲突
Sophus::Vector6d d = T_c_r_estimated_.log();
Vector3d trans = d.head<3>();
Vector3d rot = d.tail<3>();
if ( rot.norm() >key_frame_min_rot || trans.norm() >key_frame_min_trans )
return true;
return false;
}
void VisualOdometry::addKeyFrame()
{
//关键帧添加,直接调用insertKeyFrame()将当前帧插入就好了。
cout<<"adding a key-frame"<<endl;
map_->insertKeyFrame ( curr_ );
}
}
测试程序run_vo
int main ( int argc, char** argv )
{
//terminal运行时需要添加参数文件命令行,这里加一步判断
//运行:bin/run_vo config/default.yaml
if ( argc != 2 )
{
cout<<"usage: run_vo parameter_file"<<endl;
return 1;
}
//读取参数文件并设置
myslam::Config::setParameterFile ( argv[1] );
//构造VO,类型就是在VisualOdometry类中定义的指向自身类型的指针,然后用New开辟内存
myslam::VisualOdometry::Ptr vo ( new myslam::VisualOdometry );
//读取数据集文件地址
string dataset_dir = myslam::Config::get<string> ( "dataset_dir" );
cout<<"dataset: "<<dataset_dir<<endl;
//读取数据文件中的associate.txt文件
ifstream fin ( dataset_dir+"/associate.txt" );
//没读取成功则输出
if ( !fin )
{
cout<<"please generate the associate file called associate.txt!"<<endl;
return 1;
}
//定义图片名数组和时间戳数组,用于存放associate.txt文件中所示的时间戳对齐的RGB图像和depth图像
vector<string> rgb_files, depth_files;
vector<double> rgb_times, depth_times;
//循环读取直至文件的末尾
while ( !fin.eof() )
{
string rgb_time, rgb_file, depth_time, depth_file;
fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
//push.back()进各个数组 atof是讲一个单字节字符串转换成一个浮点数
rgb_times.push_back ( atof ( rgb_time.c_str() ) );
depth_times.push_back ( atof ( depth_time.c_str() ) );
rgb_files.push_back ( dataset_dir+"/"+rgb_file );
depth_files.push_back ( dataset_dir+"/"+depth_file );
//.good()返回是否读取到文件末尾,文件末尾处此函数会返回false。所以跳出循环
if ( fin.good() == false )
break;
}
//创建相机
myslam::Camera::Ptr camera ( new myslam::Camera );
// visualization可视化
//可视化内容,用到opencv中的viz模块
//1. 创建一个可视化窗口,参数为窗口名称
cv::viz::Viz3d vis("Visual Odometry");
//2. 这里是创建了两个做坐标系,以widget部件类型存在 一个是世界坐标系,一个是相机坐标系
//构造参数就是坐标系的长度
cv::viz::WCoordinateSystem world_coor(1.0), camera_coor(0.5);
//这里设置坐标系部件属性,然后添加到视图窗口上去
//首先利用setRenderingProperty()函数设置渲染属性,
// 第一个参数是个枚举,对应要渲染的属性这里是线宽,后面是属性值
world_coor.setRenderingProperty(cv::viz::LINE_WIDTH, 2.0);
camera_coor.setRenderingProperty(cv::viz::LINE_WIDTH, 1.0);
//显示在窗口中 "动的坐标系"
vis.showWidget( "World", world_coor );
vis.showWidget( "Camera", camera_coor );
/**
至此,窗口中已经显示了全部需要显示的东西,就是两个坐标系:世界坐标系,相机坐标系。
世界坐标系就是写死不动的了,所以后面也没有再提起过世界坐标系。需要做的就是计算出各个帧的相机坐标系位置
后续的核心就是下面的for循环,在循环中,不断的给相机坐标系设置新的pose,然后达到动画的效果。
**/
//3. 设置视角。这步是非必要步骤,进行设置有利于观察,
//不设置也会有默认视角,就是可能比较别扭。而且开始后拖动鼠标,也可以改变观察视角。
//构建三个3D点,这里其实就是构造makeCameraPose()函数需要的三个向量:
//相机位置坐标、相机焦点坐标、相机y轴朝向
//蓝色-Z,红色-X,绿色-Y
cv::Point3d cam_pos( 0, -1.0, -1.0 ), cam_focal_point(0,0,0), cam_y_dir(0,1,0);
//由这三个参数,用makeCameraPose()函数构造Affine3d类型的相机位姿,这里其实是视角位姿,也就是程序开始时处在什么视角看
cv::Affine3d cam_pose = cv::viz::makeCameraPose( cam_pos, cam_focal_point, cam_y_dir );
//用setViewerPose()设置观看视角
vis.setViewerPose( cam_pose );
//输出RGB图像信息,共读到多少文件数
cout<<"read total "<<rgb_files.size() <<" entries"<<endl;
//因为整个可视化要呈现动态更新,所以用for
for ( int i=0; i<rgb_files.size(); i++ )
{
//读取图像
Mat color = cv::imread ( rgb_files[i] );
Mat depth = cv::imread ( depth_files[i], -1 );
if ( color.data==nullptr || depth.data==nullptr )
break;
//创建帧
myslam::Frame::Ptr pFrame = myslam::Frame::createFrame();
pFrame->camera_ = camera;
pFrame->color_ = color;
pFrame->depth_ = depth;
pFrame->time_stamp_ = rgb_times[i];
//这里加个每帧的运算时间,看看实时性
boost::timer timer;
//这里加个每帧的运算时间,看看实时性
vo->addFrame ( pFrame );
cout<<"VO costs time: "<<timer.elapsed()<<endl;
//VO丢失
if ( vo->state_ == myslam::VisualOdometry::LOST )
break;
//这里要说一下,可视化窗口中动的是相机坐标系,所以本质上是求取相机坐标系下的点在世界坐标系下的坐标,
//Pw=Twc*Pc
SE3 Tcw = pFrame->T_c_w_.inverse();
// show the map and the camera pose
//用Twc构造Affine3d类型的pose所需要的旋转矩阵和平移矩阵
//这里为啥要构造成Affine3d类型呢,因为在上面第3步我们需要构造视角位姿(大概是这么个用法 在viz中显示)
/**
* 构造位姿: cv::Affine3d M(旋转矩阵,平移向量);
*/
cv::Affine3d M(
cv::Affine3d::Mat3(
Tcw.rotation_matrix()(0,0), Tcw.rotation_matrix()(0,1), Tcw.rotation_matrix()(0,2),
Tcw.rotation_matrix()(1,0), Tcw.rotation_matrix()(1,1), Tcw.rotation_matrix()(1,2),
Tcw.rotation_matrix()(2,0), Tcw.rotation_matrix()(2,1), Tcw.rotation_matrix()(2,2)
),
cv::Affine3d::Vec3(
Tcw.translation()(0,0), Tcw.translation()(1,0), Tcw.translation()(2,0)
)
);
//两个窗口同时显示,一个是图像
cv::imshow("image", color );
cv::waitKey(1);
//一个是viz中对应的坐标系变换
vis.setWidgetPose( "Camera", M);
vis.spinOnce(1, false);
}
return 0;
}
总结
至此,我们实现了一个简单的两两帧间的视觉里程计,然而不管从速度还是精度上来 说,它的效果都不理想。似乎这种看似简单的思路并不能得到很好的结果。
我们来考虑一 下有哪几种可能的原因:
-
在位姿估计时,我们使用了 RANSAC 求出的 PnP 解。由于 RANSAC 只采用少数 几个随机点来计算 PnP,虽然能够确定 inlier,但该方法容易受噪声影响。在 3D-2D 点存在噪声的情形下,我们要用 RANSAC 的解作为初值,再用非线性优化求一个最 优值。下一节将说明这种做法是优于现在的做法的。
-
由于现在的 VO 是无结构的,特征点的 3D 位置被当作真值来估计运动。但实际上, RGB-D 的深度图必定带有一定的误差,特别是那些深度过近或过远的地方。并且,由 于特征点往往位于物体的边缘处,那些地方的深度测量值通常是不准确的。所以现在 的做法不够精确,我们需要把特征点也放在一起优化。
-
只考虑参考帧/当前帧的方式,一方面使得位姿估计过于依赖参考帧。如果参考帧质 量太差,比如出现严重遮挡、光照变化的情况下,跟踪容易会丢失。并且,当参考帧 位姿估计不准时,还会出现明显的漂移。另一方面,仅使用两帧数据显然没有充分地 利用所有的信息。更自然的方式是比较当前帧和地图,而不是比较当前帧和参考帧。 于是,我们要关心如何把当前帧与地图进行匹配,以及如何优化地图点的问题。
-
由于输出了各步骤的运行时间,我们可以对计算量有一个大概的了解,特征点的提取和匹配占据了绝大多数的计算时间,而看似复杂的 PnP 优 化,计算量与之相比基本可以忽略。因此,如何提高特征提取、匹配算法的速度,将是特征点方法的一个重要的主题。一种可预见的方式是使用直接法/光流,可有效地避开繁重的特征计算工作。
cv::Affine3d::Mat3(
Tcw.rotation_matrix()(0,0), Tcw.rotation_matrix()(0,1), Tcw.rotation_matrix()(0,2),
Tcw.rotation_matrix()(1,0), Tcw.rotation_matrix()(1,1), Tcw.rotation_matrix()(1,2),
Tcw.rotation_matrix()(2,0), Tcw.rotation_matrix()(2,1), Tcw.rotation_matrix()(2,2)
),
cv::Affine3d::Vec3(
Tcw.translation()(0,0), Tcw.translation()(1,0), Tcw.translation()(2,0)
)
);//两个窗口同时显示,一个是图像 cv::imshow("image", color ); cv::waitKey(1); //一个是viz中对应的坐标系变换 vis.setWidgetPose( "Camera", M); vis.spinOnce(1, false);}
return 0;
}
## 总结
至此,我们实现了一个简单的两两帧间的视觉里程计,然而不管从速度还是精度上来 说,它的效果都不理想。似乎这种看似简单的思路并不能得到很好的结果。
我们来考虑一 下有哪几种可能的原因:
1. 在位姿估计时,我们使用了 RANSAC 求出的 PnP 解。由于 RANSAC 只采用少数 几个随机点来计算 PnP,虽然能够确定 inlier,但该方法容易受噪声影响。在 3D-2D 点存在噪声的情形下,我们要用 RANSAC 的解作为初值,再用非线性优化求一个最 优值。下一节将说明这种做法是优于现在的做法的。
2. 由于现在的 VO 是无结构的,特征点的 3D 位置被当作真值来估计运动。但实际上, RGB-D 的深度图必定带有一定的误差,特别是那些深度过近或过远的地方。并且,由 于特征点往往位于物体的边缘处,那些地方的深度测量值通常是不准确的。所以现在 的做法不够精确,我们需要把特征点也放在一起优化。
3. 只考虑参考帧/当前帧的方式,一方面使得位姿估计过于依赖参考帧。如果参考帧质 量太差,比如出现严重遮挡、光照变化的情况下,跟踪容易会丢失。并且,当参考帧 位姿估计不准时,还会出现明显的漂移。另一方面,仅使用两帧数据显然没有充分地 利用所有的信息。更自然的方式是比较当前帧和地图,而不是比较当前帧和参考帧。 于是,我们要关心如何把当前帧与地图进行匹配,以及如何优化地图点的问题。
4. 由于输出了各步骤的运行时间,我们可以对计算量有一个大概的了解,特征点的提取和匹配占据了绝大多数的计算时间,而看似复杂的 PnP 优 化,计算量与之相比基本可以忽略。因此,如何提高特征提取、匹配算法的速度,将是特征点方法的一个重要的主题。一种可预见的方式是使用直接法/光流,可有效地避开繁重的特征计算工作。















 2042
2042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









