








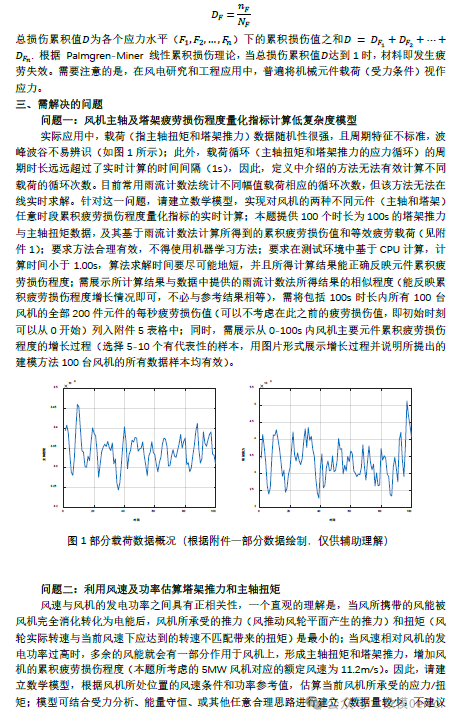







2024华为杯A题参考论文代码![]() https://download.csdn.net/download/qq_52590045/89779433
https://download.csdn.net/download/qq_52590045/89779433






总领这个题,是属于数据挖掘和数据优化类型的题目,对于数据的要求非常高,数据的精确度和有效性能够直接决定磁心损耗的评价的准确度,所以在进行问题的建模时,首先需要对数据进行数据预处理。
数据预处理的步骤为:数据清洗、数据归一化等等。
数据清洗是数据处理中的重要环节,由于数据源头不一,直接导致数据质量参差不齐,因此必须要做好数据清洗。
去重:移除重复的样本,确保数据多样性
去噪:过滤掉无意义的数据,如广告,拼写错误,噪声图像等
统一格式:确保所有数据采用一致的编码格式(如UTF-8),并且统一时间,日前等标准格式;
数据修复:修正数据中的错误,如拼写,补全等。
数据归一化的方法:
数据归一化是数据预处理中的一个重要步骤,它对于提高机器学习模型的性能、加速训练过程以及改善数据分布特性具有重要意义。以下是关于数据归一化的意义和方法的详细解答:
数据归一化的意义
消除尺度差异:不同特征可能具有不同的尺度和范围,这可能导致某些特征在模型训练中起主导作用,而其他特征的影响被忽略。归一化可以消除特征之间的尺度差异,确保每个特征对模型的贡献相对平等。
-
加速模型收敛:在训练深度神经网络等模型时,数据的归一化可以加速模型的收敛。这是因为在归一化后,模型的参数更新更加稳定,训练过程更容易找到损失函数的最优解。
-
提高模型精度:对于某些算法,如K近邻算法(KNN)和神经网络,特征的尺度对模型的性能有显著影响。归一化可以帮助这些算法更准确地捕捉特征之间的关系,从而提高模型的精度。
-
防止数值问题:在某些计算过程中,如使用梯度下降算法时,如果特征的尺度差异很大,可能会导致数值不稳定或梯度消失/爆炸的问题。归一化有助于避免这类数值问题。
-
提高模型稳定性:归一化可以提高算法的稳定性,使得算法对于不同的数据集或数据子集具有更一致的性能。
数据归一化的方法
数据归一化有多种方法,以下是几种常用的方法:
Min-Max归一化(最小-最大规范化)----常用
方法描述:也称为线性归一化,通过将数据缩放到[0, 1]区间内,实现数据的归一化。
-
公式:
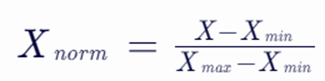
其中,X 是原始数据,Xmin 和 Xmax 分别是数据集中的最小值和最大值,Xnorm 是归一化后的数据。
-
优点:简单直观,易于实现。
-
缺点:对极端值非常敏感,如果数据集中存在离群值,可能会影响归一化效果。
-
Z-Score归一化(标准化)---(本文推荐应用)
-
方法描述:将数据转换为均值为0,标准差为1的正态分布(也称为标准正态分布或高斯分布)。
-
公式:
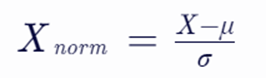
其中ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











