







A 题 支路车流量推测问题
问题 1 分析
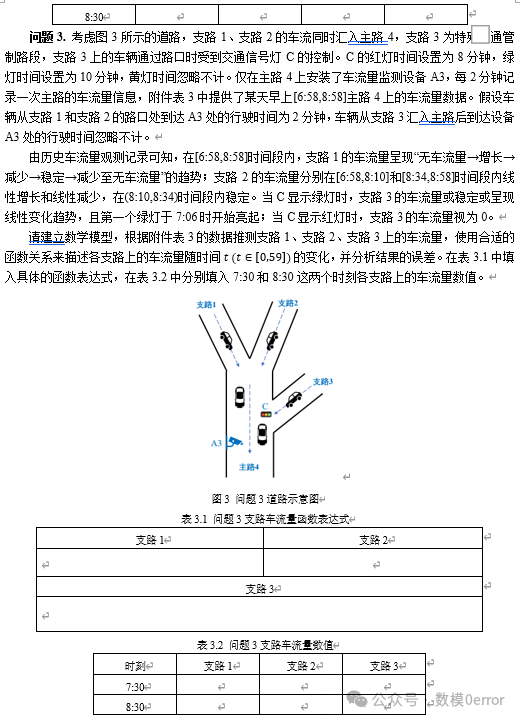
问题1的核心任务是根据主路3的车流量数据推测支路1和支路2的车流量。在实际交通流量监测中,往往只有主路设有车流量监测设备,而支路的车流量却未必能直接获取。在这种情况下,我们需要通过已有的主路车流量数据和支路的历史车流量变化趋势,来推测各支路的车流量。具体来说,问题1设定在一个Y型道路中,支路1和支路2的车流量汇入主路3,并且已知在6:58到8:58这个时间段内主路车流量的变化趋势。支路1的车流量呈现线性增长,而支路2的车流量呈现先增长后减少的趋势,这一规律需要通过合适的数学模型来表达。
对于支路1,由于车流量呈现线性增长趋势,我们可以使用线性回归模型来进行建模,从而描述车流量随时间的变化。支路2的车流量变化则更为复杂,呈现出先增加后减少的趋势,因此我们需要使用分段线性函数或二次函数等模型来捕捉其变化的特点。由于主路的车流量是各支路车流量的总和,因此我们可以通过约束条件将主路车流量与各支路车流量的关系结合起来。在建模过程中,我们需要综合考虑历史车流量数据,设计合理的数学模型来推测各支路的车流量,并确保模型推测结果与实际观测数据之间的误差最小。此外,误差分析也是本题的关键,通过与实际观测数据的对比,可以评估模型的准确性,并对模型进行必要的优化,以提高预测精度。
解题思路:
支路1和支路2车流量推测模型
1.1 问题分析与建模目标
问题1的核心任务是通过主路3的车流量数据推测支路1和支路2的车流量。主路车流量的监测是通过安装在主路上的设备A1进行的,设备每2分钟记录一次车流量数据。然而,问题的挑战在于支路1和支路2上并未安装监测设备,因此,我们必须依赖于主路车流量数据和支路车流量的历史趋势进行推测。已知在时间段[6:58, 8:58]内,支路1的车流量呈线性增长,而支路2的车流量则呈现先增长后减少的趋势。
为了将主路车流量与支路车流量建立联系,我们可以借助数学建模的手段。首先,主路车流量是所有汇入主路的支路车流量的总和,因此,支路1和支路2的车流量应当和主路车流量之间存在一定的函数关系。基于这一点,支路车流量的推测需要从主路车流量的总和出发,结合支路车流量的历史规律,设计适当的数学模型。由于问题1中的支路车流量呈现一定的规律性,支路1和支路2的车流量分别是线性增长和先增长后减少,我们可以通过构建线性函数和分段线性函数来描述这两条支路的车流量变化趋势。基于这些要求,我们的建模目标不仅仅是推测支路车流量的大小,还需要保证模型与实际情况高度一致,同时控制模型的复杂度,避免过拟合或欠拟合。
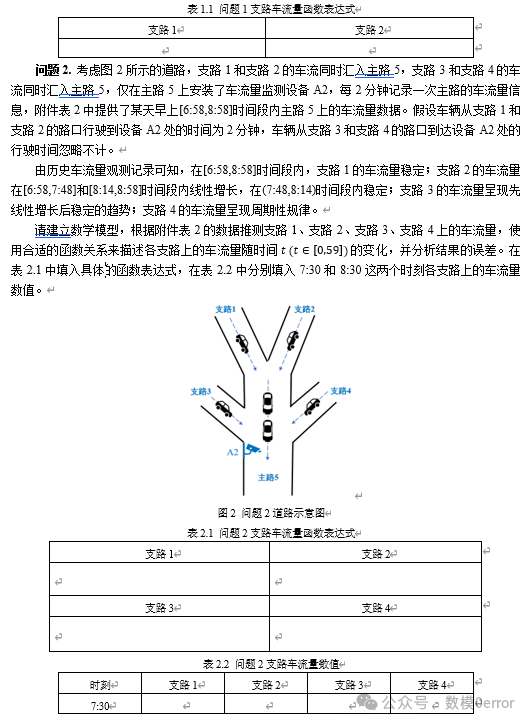
问题 2 分析
问题2比问题1更为复杂,涉及的支路数量从两条增加到四条,且车流量变化趋势更加多样。我们依然需要根据主路5的车流量数据来推测支路1到支路4的车流量,但此问题的复杂性在于支路2至支路4的车流量变化规律不再是简单的线性增长或减少。支路2的车流量在两个时段内呈现线性增长,而在中间时段则保持稳定,支路3的车流量呈现先增长后稳定的趋势,支路4的车流量呈现周期性规律。因此,我们不仅需要考虑各支路车流量的变化规律,还要考虑支路间车流量的相互关系。
在建模时,支路1的车流量相对简单,可以假设其车流量稳定或者呈线性增长,而支路2到支路4的车流量需要采用更复杂的模型来拟合。例如,支路2的车流量可以用分段线性函数来描述,支路3的车流量可以通过线性增长后趋于稳定的函数来建模,而支路4的周期性车流量可以通过周期函数来建模。由于主路车流量是所有支路车流量的总和,推测支路车流量时必须合理分配主路车流量。我们可以通过加权平均法或者回归分析等方法来推测支路车流量。问题2的难点不仅在于函数模型的选择,还在于如何通过历史数据推测不同支路的车流量,同时保持各支路车流量推测结果的一致性和合理性。为了验证模型的有效性,误差分析仍然是一个不可忽视的环节,尤其是在支路车流量的变化趋势较为复杂时,模型的准确性直接影响到推测结果的可靠性。
解题思路:
支路1到支路4车流量推测模型
2.1 问题分析与建模目标
在问题2中,我们的主要任务是根据主路5的车流量数据推测支路1到支路4的车流量。交通流量监测通常只在主路上进行,而支路的车流量则是通过推测来得出的。这对于交通流量管理、信号灯优化、以及交通规划等都具有重要的意义。具体来说,本问题给定了主路5的车流量数据,并且为各支路提供了车流量的变化规律。支路1的车流量保持稳定,支路2的车流量在增长段后保持稳定,支路3的车流量先增长后趋于稳定,而支路4的车流量则呈现周期性变化。
要解决这个问题,我们首先需要深入理解每个支路车流量的变化模式,并将这些变化通过数学模型来表达。对于稳定车流量的支路1,可以用常数模型来描述;对于呈现分段线性增长和稳定的支路2,我们可以使用分段线性函数;而对于呈现周期性变化的支路4,则需要使用周期函数如正弦或余弦函数。通过这些模型,我们将能够推测各个支路的车流量,并与实际数据进行对比和优化。
为了提升模型的准确性和鲁棒性,我们不仅需要设计合适的数学模型,还要结合智能优化算法来进行参数估计,特别是在支路车流量的变化规律复杂或难以直接捕捉的情况下。传统的最小二乘法可能不足以捕捉这种复杂的关系,尤其是支路车流量在变化时存在非线性和多种类型的趋势。因此,引入更高级的智能优化算法,如粒子群优化(PSO)或深度学习(例如神经网络),将有助于提高预测准确度。
2.2 数学建模框架
根据问题的描述,我们首先需要建立一个关于主路车流量和支路车流量的数学关系。设主路车流量为 Qmain(t) ,支路1到支路4的车流量分别为 、、和Q1(t)、Q2(t)、Q3(t)和Q4(t) ,我们有以下公式描述它们之间的关系:
![]()
接下来,我们需要为每一个支路车流量设计适合的模型,依据支路车流量的变化规律:
- 支路1的车流量模型
:支路1车流量在给定时间段内是稳定的,可以使用常数模型来表示:
![]()
其中, c1 表示支路1的稳定车流量。该模型假设支路1的车流量没有变化,维持一个固定的值。
- 支路2的车流量模型
:支路2车流量呈现先线性增长后稳定的变化,因此需要使用分段线性函数来描述:
......
import pandas as pdfile_path = './excels/附件(Attachment).xlsx'try:data = pd.read_excel(file_path, sheet_name=0)except Exception as e:error_message = str(e)if 'data' in locals():preview = data.head()loaded_successfully = Trueelse:preview = error_messageloaded_successfully = Falseloaded_successfully, preview##########import numpy as npfrom scipy.stats import linregressmain_road_data = data['主路3的车流量 (Traffic flow on the Main road 3)'].astype(float)slope_branch_1, intercept_branch_1, _, _, _ = linregress(range(len(main_road_data)), main_road_data)branch_1_growth_rate = slope_branch_1............
问题2
import numpy as npimport pandas as pdfrom scipy.optimize import curve_fit# 读取数据excel_file = pd.ExcelFile('附件(Attachment).xlsx')df = excel_file.parse('表2 (Table 2)')t = df['时间 t (Time t)'].valuesy = df['主路5的车流量 (Traffic flow on the Main road 5)'].values# 定义支路1车流量函数def branch1(t, a):return np.full_like(t, a)# 定义支路2车流量函数def branch2(t, b1, c1, d, e1, f1):x2 = np.zeros_like(t)mask1 = (t >= 0) & (t <= 24)mask2 = (t > 24) & (t < 37)mask3 = (t >= 37) & (t <= 59)x2[mask1] = b1 + c1 * t[mask1]x2[mask2] = dx2[mask3] = e1 + f1 * (t[mask3] - 37)return x2# 定义支路3车流量函数def branch3(t, b2, c2, g):x3 = np.zeros_like(t)mask1 = (t >= 0) & (t < 30)mask2 = (t >= 30) & (t <= 59)x3[mask1] = b2 + c2 * t[mask1]x3[mask2] = greturn x3# 定义支路4车流量函数def branch4(t, A, phi, k):omega = np.pi / 30return A * np.sin(omega * t + phi)+k# 定义总车流量函数def total_traffic(t, a, b1, c1, d, e1, f1, b2, c2, g, A, phi, k):x1 = branch1(t, a)x2 = branch2(t, b1, c1, d, e1, f1)x3 = branch3(t, b2, c2, g)x4 = branch4(t, A, phi, k)y_pred = np.where(t >= 2, x1[t - 2]+x2[t - 2]+x3[t].....................




↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓


















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











