







2.3语音信号特征提取
- 基本流程:
语音活动检测样本—》向量特征提取—》冗余信息压缩—》神经网络分类器识别
-
常用语音特征类型:
-
梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)
-
梅尔滤波器组系数(Mel filter bank,FBank,又称 log-Mel)
-
和线性预测系数(Linear Prediction Coefficient,LPC)
-
-
FBank、MFCC步骤:
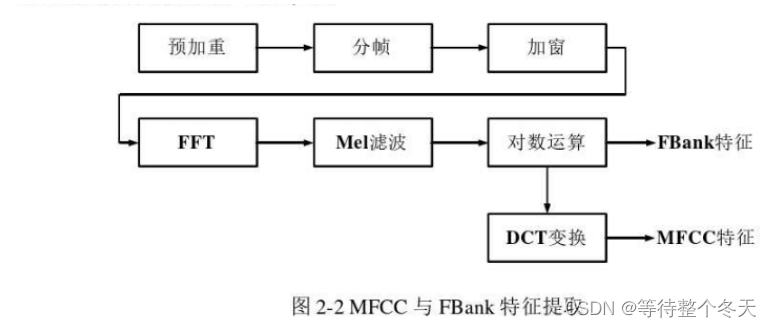
FBank特征相邻滤波器组有重叠,特征间相关性高、保留的信息更多,神经网络可以更好利用这些相关性
2.3.1预加重
空气是语音信号的载体,会传播和损耗声波的能量。声源尺寸一定,频率越高,损耗越大
通过预加重补偿高频分量损失,提升信号高频分量。时域关系如下式:
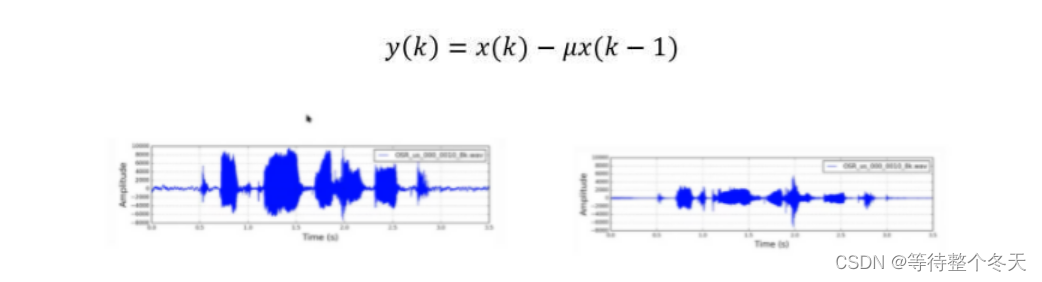
即信号通过一个高通滤波器:
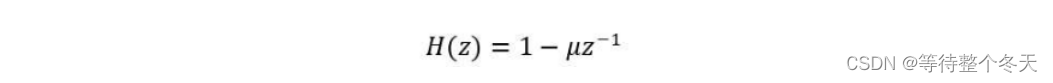
u:预加重系数(0.9,1)
x(k):第k个采样点
y(k):预加重处理后第k个输出
时域处理本质:差分运算
2.3.2分帧
-
why?
FFT要求输入信号时平稳的
宏观上语音是不平稳的:说话人口型变化,信号特征就变了
微观上短时间内,说话相对稳定
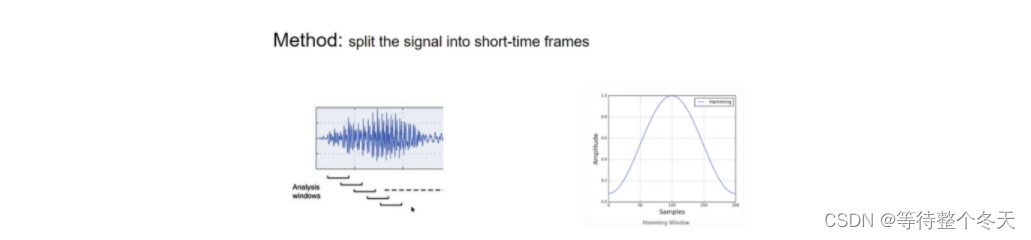
语音信号短时平稳,对语音进行短时分帧(frame),以满足FFT平稳条件
-
how?
一般取20-50ms一帧
采取一定**重叠(1/2,2/3)**增加帧与帧之间的连续性:无重叠会导致频率变换后特征参数突变
2.3.3加窗
深入浅出的理解频谱泄露:对信号在时域加窗后,频域则是卷积,频谱会多出除信号主瓣外的旁瓣
语音分帧后,需要在时域乘以窗函数以增加帧左端和右端的连续性,减少频谱泄露,使窗口两端不会急剧变化而平滑过渡到0,从而使截出的语音波形帧缓慢降为0,减小语音帧的截断效应。若使用矩形窗容易产生较严重的频谱泄露现象,通常用汉宁窗、汉明窗
2.3.4傅里叶变换
频域能量分布可以更好观察语音特性,每帧经过DFT得到频谱
2.3.5Mel滤波
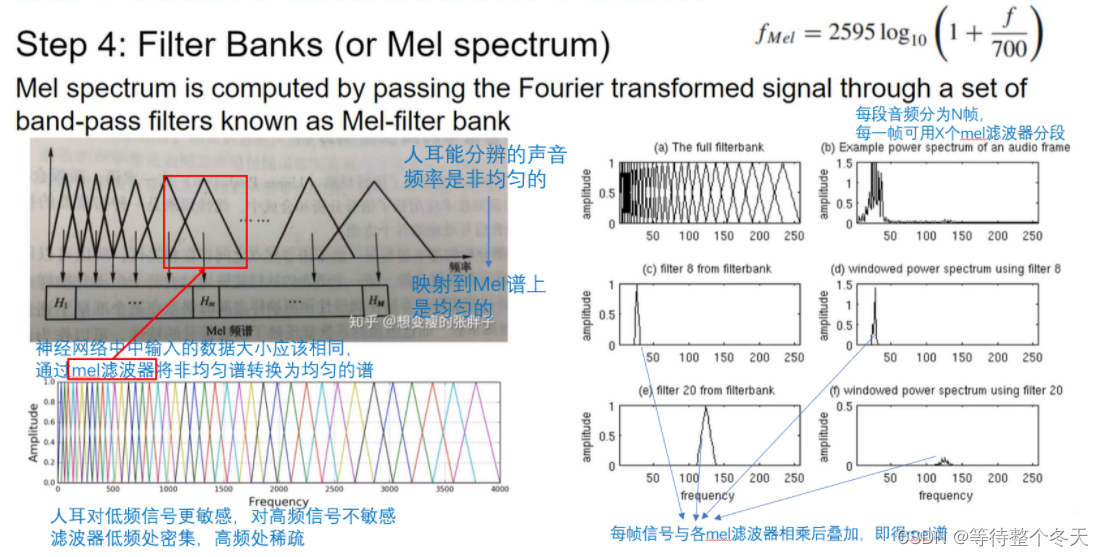
FFT得到的频谱特征是线性分布的,不符合人耳对真实语音信号的感知
人耳对低频声音更敏感,会更集中于关注某些特定频点,类似于一种滤波器组,即Mel滤波器组
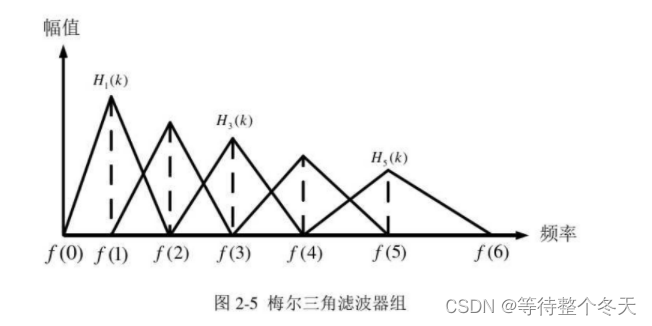
梅尔滤波器组使用了对数变换将傅里叶变换得到的线性频谱映射到基于听觉感知的 Mel 非线性频谱中,在Mel频域内,人对音调的感知度为线性关系
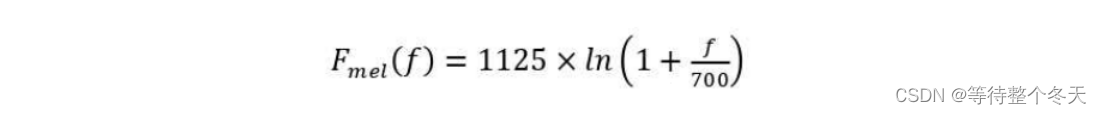
在梅尔滤波器构建完成后,要得到梅尔倒谱能量,还需要对傅里叶变换后的频率谱执行 Mel 滤波运算,以计算每阶滤波器的能量和总能量值。同时,由于人耳对音量的感知也不是线性的,因此还需要对能量取对数以得到最后输出的 FBank 特征
- pytorch中函数

- sample_rate:信号采样率
- n_fft:fft点数
- win_length:帧长度,以16k采样率为例,400即25ms
- hop_length:每帧平移长度,决定overlap(重叠)是多少,160即为10ms,1s钟则可分为100帧
- f_min,f_max:进行mel变换的频域上下限
- n_mels:mel滤波器个数,决定输出的维度
参考资料
[1]刘青松. 基于神经网络的低功耗语音关键词唤醒硬件设计[D].电子科技大学,2023.DOI:10.27005/d.cnki.gdzku.2022.003514.
[2]可能叫做小黑. 2. 加载数据!“如何训练一个声纹识别模型:从原理到实践”,第二章:训练数据的格式与加载方法[EB/OL]. [2023.10.30]. https://www.bilibili.com/video/BV19q4y137i4/?spm_id_from=333.999.0.0&vd_source=a7949f48ad3098f6c26f5b0dfda80b0d.


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











