







大师兄的数据分析学习笔记(二十五):聚类(一) - 简书 (jianshu.com)
一、监督学习和无监督学习
- 分类和回归都属于监督学习,监督学习的特点是有标注。
- 所谓标注也就是数据的特征,不管是分类还是回归都是通过标注进行区分数据。
- 而无监督学习没有标注,所以无监督学习的目的就是给数据加上标注。
- 进行标注的原则是,加过标注后的数据应该尽可能相似,而不同标注内的数据应该尽可能不同。
- 由于目的不同,方法不同,标注数据的方式也不同,所以会有多种算法用于实现标注。
- 在无监督学习中,常用的两种方法是聚类和关联规则。
二、关于聚类
- 聚类是将集合分成类似的对象组成的多个类的过程。
- 在聚类中,常用四种算法:
- 基于切割的K-means聚类算法。
- 基于层次的聚类算法。
- 基于密度的DBSCAN聚类算法。
- 基于图的Split聚类算法。
三、K-means算法

- K-means算法的思路是:所有类都有一个中心,属于一个类的点到它的中心的距离比其它类离中心更新。
- 这样就会牵扯到两个问题:
- 如何定义中心:取数据各维度的均值。
- 如何衡量距离:欧式距离方法
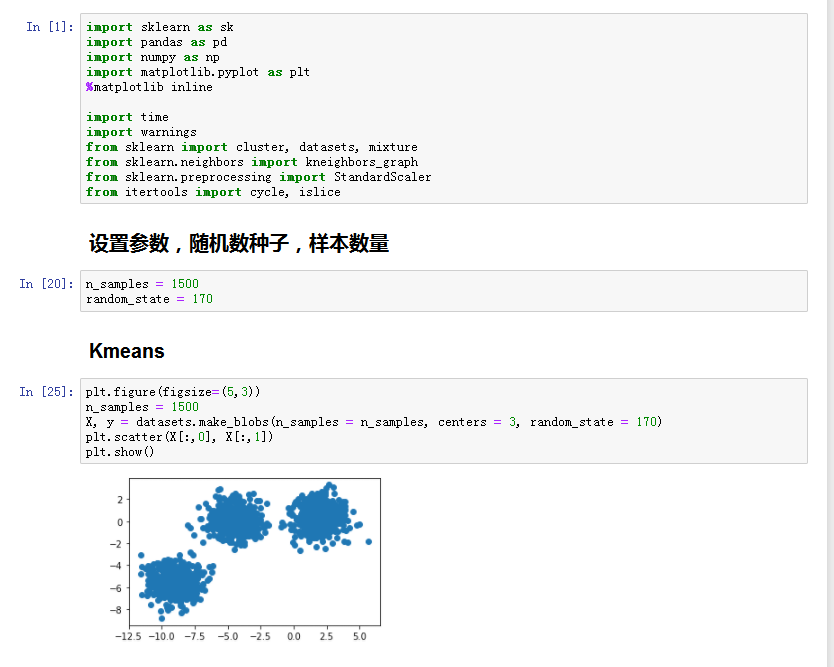
- K指确定分类的数目,means指不断取均值,算法:
从n个样本中随机选取k个作为初始化的质心;
对每个样本测量其到每个质心的距离,并把它归到最近的质心的类;
重新计算已经得到的各个类的质心;
- 迭代2-3直到新的质心与原质心相等或小于指定阈值。
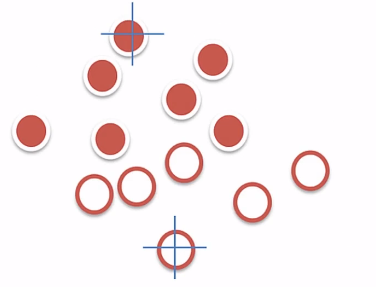

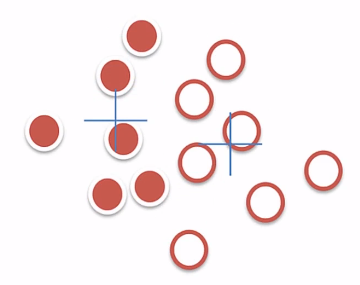
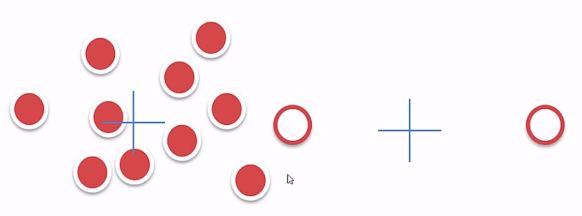
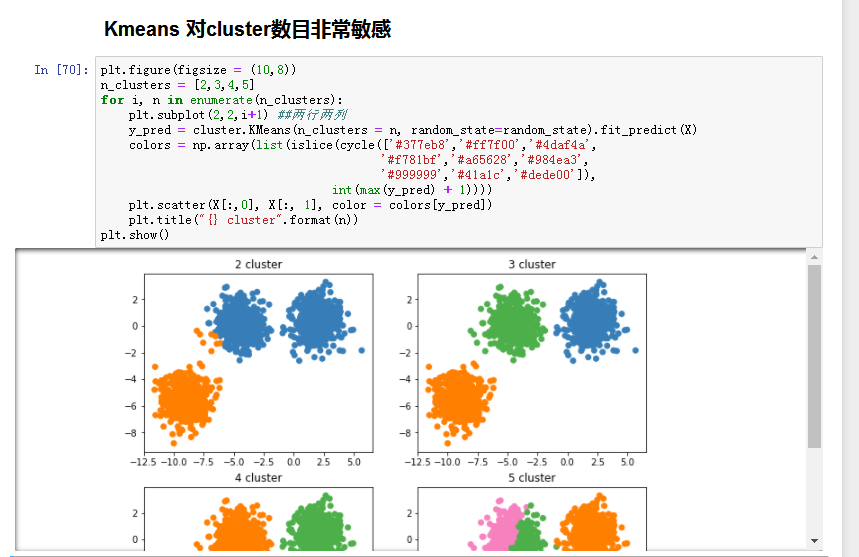
- K-means算法的问题:
- 初始质心位置可能会影响最终聚类的结果。
解决:多次尝试,取最稳定的结果。- 个别离群值会影响整理聚类的效果。
解決:将取质心换成取中点(转换为K-Medoids算法)- 必须要指定K
解决:借鉴其它衡量因子辅助(如轮廓系数)
KNN(K-Nearest Neighbor)介绍
Wikipedia上的 KNN词条 中有一个比较经典的图如下:
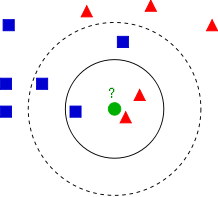
KNN的算法过程是是这样的:
从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
(参考 酷壳的 K Nearest Neighbor 算法 )https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。
KNN是一种memory-based learning,也叫instance-based learning,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。
具体是每次来一个未知的样本点,就在附近找K个最近的点进行投票。
再举一个例子,Locally weighted regression (LWR)也是一种 memory-based 方法,如下图所示的数据集。
用任何一条直线来模拟这个数据集都是不行的,因为这个数据集看起来不像是一条直线。但是每个局部范围内的数据点,可以认为在一条直线上。每次来了一个位置样本x,我们在X轴上以该数据样本为中心,左右各找几个点,把这几个样本点进行线性回归,算出一条局部的直线,然后把位置样本x代入这条直线,就算出了对应的y,完成了一次线性回归。
也就是每次来一个数据点,都要训练一条局部直线,也即训练一次,就用一次。
LWR和KNN是不是很像?都是为位置数据量身定制,在局部进行训练。
K-Means介绍
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。(a)刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的。(b)假设数据集可以分为两类,令K=2,随机在坐标上选两个点,作为两个类的中心点。(c-f)演示了聚类的两种迭代。先划分,把每个数据样本划分到最近的中心点那一簇;划分完后,更新每个簇的中心,即把该簇的所有数据点的坐标加起来去平均值。这样不断进行”划分—更新—划分—更新”,直到每个簇的中心不在移动为止。(图文来自Andrew ng的机器学习公开课)。
推荐关于K-Means的两篇博文, K-Means 算法 _ 酷壳 , 漫谈 Clustering (1)_ k-means pluskid 。
KNN和K-Means的区别
KNN与K-Means的区别 - dy9776 - 博客园 (cnblogs.com)
| KNN | K-Means |
| 1.KNN是分类算法 2.监督学习 3.喂给它的数据集是带label的数据,已经是完全正确的数据 | 1.K-Means是聚类算法 2.非监督学习 3.喂给它的数据集是无label的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序 |
| 没有明显的前期训练过程,属于memory-based learning | 有明显的前期训练过程 |
| K的含义:来了一个样本x,要给它分类,即求出它的y,就从数据集中,在x附近找离它最近的K个数据点,这K个数据点,类别c占的个数最多,就把x的label设为c | K的含义:K是人工固定好的数字,假设数据集合可以分为K个簇,由于是依靠人工定好,需要一点先验知识 |
| 相似点:都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。 | |
无监督学习(Unsupervised learning):训练样本的标记信息是未知的,目标是为了揭露训练样本的内在属性,结构和信息,为进一步的数据挖掘提供基础。
· 聚类(clustering)
· 降维(dimensionality reduction)
· 异常检测(outlier detection)
· 推荐系统(recommendation system)
监督学习(supervised learning):训练样本带有信息标记,利用已有的训练样本信息学习数据的规律预测未知的新样本标签
· 回归分析(regression)
· 分类(classification)
聚类:物以类聚。按照某一个特定的标准(比如距离),把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不再同一个簇内的数据对象的差异性也尽可能的大。
簇(或类cluster):子集合。最大化簇内的相似性;最小化簇与簇之间的相似性。
聚类可以作为一个单独过程,用于寻找数据内在分布结构,也可以作为其他学习任务前驱过程。
聚类和分类的区别:聚类是无监督学习任务,不知道真实的样本标记,只把相似度搞得样本聚合在一起;分类是监督学习任务,利用已知的样本标记训练学习器预测未知样本的类别。
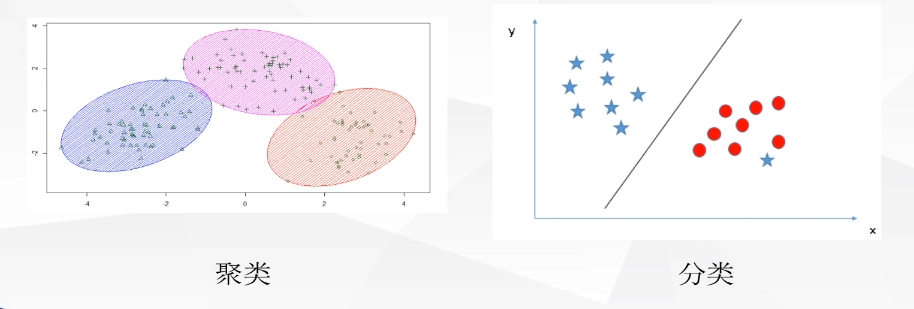
聚类相似度度量:几何距离
几种距离度量方法:
· 欧式距离(Euclidean distance):p=2的Minkowski距离,
· Minkowoski距离:
· 曼哈顿距离(Manhattan distance):p=1的Minkowski距离
· 夹角余弦:
` 相关系数(Pearson correlation coefficient):,等式右面的x其实是(x方向的均值),y其实是(y方向的均值),简书对于这个表达式很不友好,所以在此说明一下。
聚类类别:
· 基于划分的聚类(partitioning based clustering):k均值(K-means), Mean shift
· 层次聚类(hierarchical clustering):Agglomerative clustering, BIRCH
· 密度聚类(density based clustering):DBSCAN
· 基于模型的聚类(model based clustering):高斯混合模型(GMM)
· Affinity propagation
· Spectral clustering
聚类原理:
划分聚类(partition based clustering):给定包含N个点的数据集,划分法将构造K个分组;每个分组代表一个聚类,这里每个分组至少包含一个数据点,每个数据点属于且只属于一个分组;对于给定的K值,算法先给出一个初始化的分组方法,然后通过反复迭代的的方法改变分组,知道准则函数收敛。
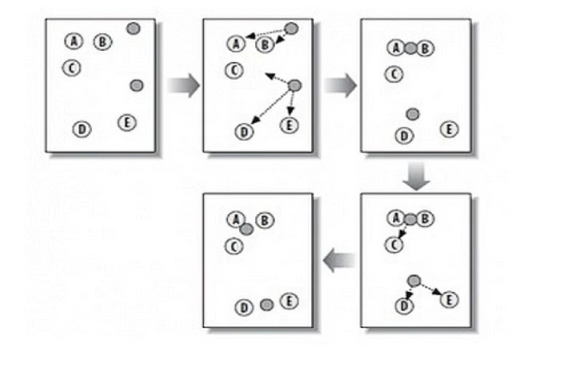
k-mean原理图
K均值算法(Kmeans):
` 给定样本集:D={,....}, k均值算法针对聚类所得簇:C={,... }
` 最小化平方差:,其中: 簇的质心,上面的2代表平方,下面的2代表范数2.
具体的K均值算法过程:
1. 随机选择K个对子女给,每个对象出事地代表了一个簇的质心,即选择K个初始质心;2. 对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;3. 重新计算每个簇的平均值。这个过程不断重复,直到准则函数(误差的平方和SSE作为全局的目标函数)收敛,直到质心不发生明显的变化。
初始质心优化:Kmeans++:
输入:样本集D={,...} 聚类簇的数量K
选取初始质心的过程:
1. 随机从m个样本点中选择一个样本作为第一个簇的质心C1;2. 计算所有的样本点到质心C1的距离:;3. 从每个点的概率分布 中随机选取一个点作为第二个质心C2。离C1越远的点,被选择的概率越大;4. 重新计算所有样本点到质心的距离;5. 重复上述过程,直到初始的K个质心被选择完成 ;按照Kmeans的算法步骤完成聚类。
输出:C= {,...}
K均值算法(Kmean)的优缺点:
优点:1. 简单直观,抑郁理解实现;2. 复杂度相对比较低,在K不是很大的情况下,Kmeans的计算时间相对很短;3. Kmean会产生紧密度比较高的簇,反映了簇内样本围绕质心的紧密程度的一种算法。
缺点:1. 很难预测到准确的簇的数目;2. 对初始值设置很敏感(Kmeans++);3. Kmeans主要发现圆形或者球形簇,对不同形状和密度的簇效果不好;4. Kmeans对噪声和离群值非常敏感(Kmeadians对噪声和离群值不敏感)
层次聚类(hierarchical clustering):
· 主要在不同层次对数据集进行逐层分解,直到满足某种条件为止;
· 先计算样本之间的距离。每次将距离最近的点合并到同一个类,然后再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成一个类。
· 自底向上(bottom-up)和自顶向下(top-down)两种方法:
top-down: 一开始每个个体都是一个初始的类,然后根据类与类之间的链接(linkage)寻找同类,最后形成一个最终的簇
bottom-up:一开始所有样本都属于一个大类,然后根据类与类之间的链接排除异己,打到聚类的目的。
类与类距离的计算方法:
最短距离法,最长距离法,中间距离法,平均距离法
最小距离:
最大距离:
平均距离:
单链接(single-linkage):根据最小距离算法
全连接(complete-linkage):根据最大距离算法
均链接(average-linkage):根据平均距离算法
凝聚层次聚类具体算法流程:
1. 给定样本集,决定聚类簇距离度量函数以及聚类簇数目k;2. 将每个样本看作一类,计算两两之间的距离;3. 将距离最小的两个类合并成一个心类;4.重新计算心类与所有类之间的距离;5. 重复(3-4),知道达到所需要的簇的数目
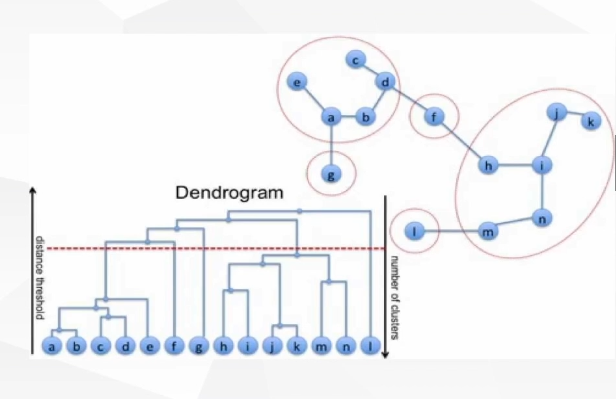
层次聚类的优缺点:
优点:1.可以得到任意形状的簇,没有Kmeans对形状上的限制;2. 可以发现类之间的层次关系;3.不要制定簇的数目
缺点:1. 通常来说,计算复杂度高(很多merge/split);2.噪声对层次聚类也会产生很大影响;3.不适合打样本的聚类
密度聚类(density based clustering):
` 基于密度的 方法的特点是不依赖于距离,而是依赖于密度,从而客服k均值只能发现“球形”聚簇的缺点
· 核心思想:只要一个区域中点的密度大于某个阈值,就把它加到与之相近的聚类中去
· 密度算法从样本密度的角度来考察样本的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果
· 对噪声和离群值的处理有效
· 经典算法:DBSCAN(density based spatial clutering of applications with noise)
DBSCAN 基于近邻域(neighborhood)参数()刻画样本分布的 紧密程度的一种算法。
基本概念:
· 样本集: D={}
` 阈值:
· :对样本点的包括样本集中与距离不大于的样本
· 核心对象(core object):如果的至少包含MinPts个样本,那么就是一个核心对象,
假设MinPts=3,虚线标识为
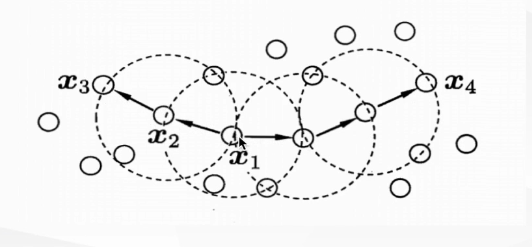
·密度直达(directly density-reachable):如果位于的中,并且是和新对象,那么由密度直达
· 密度可达(density-reachable):对,如果存在一串样本点p1,p2.....pn = ,pn = ,且由
` 密度直达,则称由密度可达
· 密度相连:存在样本集合中一点o,如果和均由O密度可达,那么和密度相连
上图中:是核心对象,那么从出发,由密度直达;由密度可达;与密度相连。
DBSCAN算法的过程:
1. 首先根据邻域参数()确定样本集合D中所有的核心对象,存在集合P中。加入集合P的条件为有不少于MinPts的样本数。
2. 然后从核心对象集合P中任意选取一个核心对象作为初始点,找出其密度可达的样本生成聚类簇,构成第一个聚类簇C1。
3. 将C1内多有核心对象从P中去除,再从更新后的核心对象集合任意选取下一个种子样本。
4. 重复(2-3),直到核心对象被全部选择完,也就是P为空集。
聚类算法总结:
基于划分的聚类:K均值(kmeans),kmeans++
层次聚类:Agglomerative聚类
密度聚类:DBSCAN
基于模型 的聚类:高斯混合模型(GMM),这篇博客里咩有介绍
虽然稀里糊涂,但是先跟下来再说吧:

















 4909
4909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











