







目录
1、采用空洞卷积,在感受视野不变的情况,降低了参数量,保证了运行速度。
摘要
领域:语义分割
数据集:PASCAL VOC-2012
性能:IOU 71.6%
目前存在问题
1、DCNN下采样导致分辨力不够
2、空间不变性 这是分类的优点 但是缺乏语义的位置信息
解决方案
1、采用空洞卷积,在感受视野不变的情况,降低了参数量,保证了运行速度。
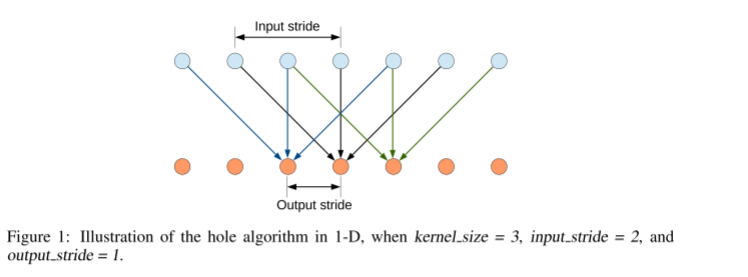
在图像的原始分辨率采用池化层导致在上采样时空间信息稀疏,因此,可以通过2或4的采样率的空洞卷积对特征图做采样扩大感受野,缩小步幅,能够使得特征图更为稠密。因此,作者将VGG16的最后两层的最大池化层使用带填充的空洞卷积替代。
2、引入CRF处理,在深度网络之后添加全连接的CRF
针对图像最终的边界分割不清晰、不准确问题,作者使用CRF对图像进行处理,CRF实质是一个概率模型,数学味道比较浓重。全连接的CRF模型使用的能量函数为: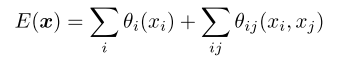
xi是标签,P(xi)是概率
一元项:![]() 基于CNN的预测分数图
基于CNN的预测分数图
二元项:![]() 考虑像素之间的关系
考虑像素之间的关系
xi≠xj 时 μ=1
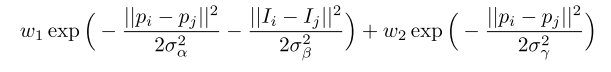
k为高斯核取决于f feature
w为权重
p为位置
I为颜色
DenseCRF的优化目标,即为调整输入x(每个像素的label)使能量函数最小化。但由于是全连接,直接计算的话计算量简直爆炸,所以采用平均场近似的方法进行计算.
后续用CRF偏少为什么现在做分割都不用CRF后处理了呢? - 知乎
网络结构
DCNN+CRF串联结构
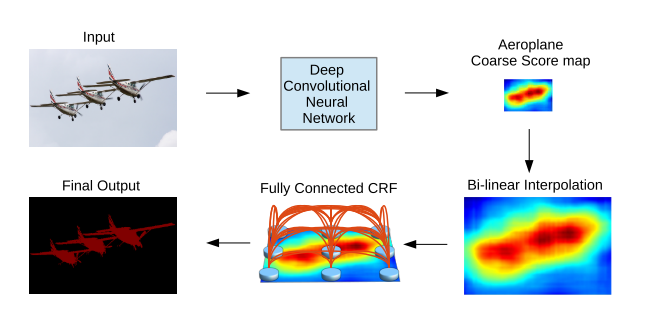
DCNN部分修改VGG,下图为VGG16原始基础
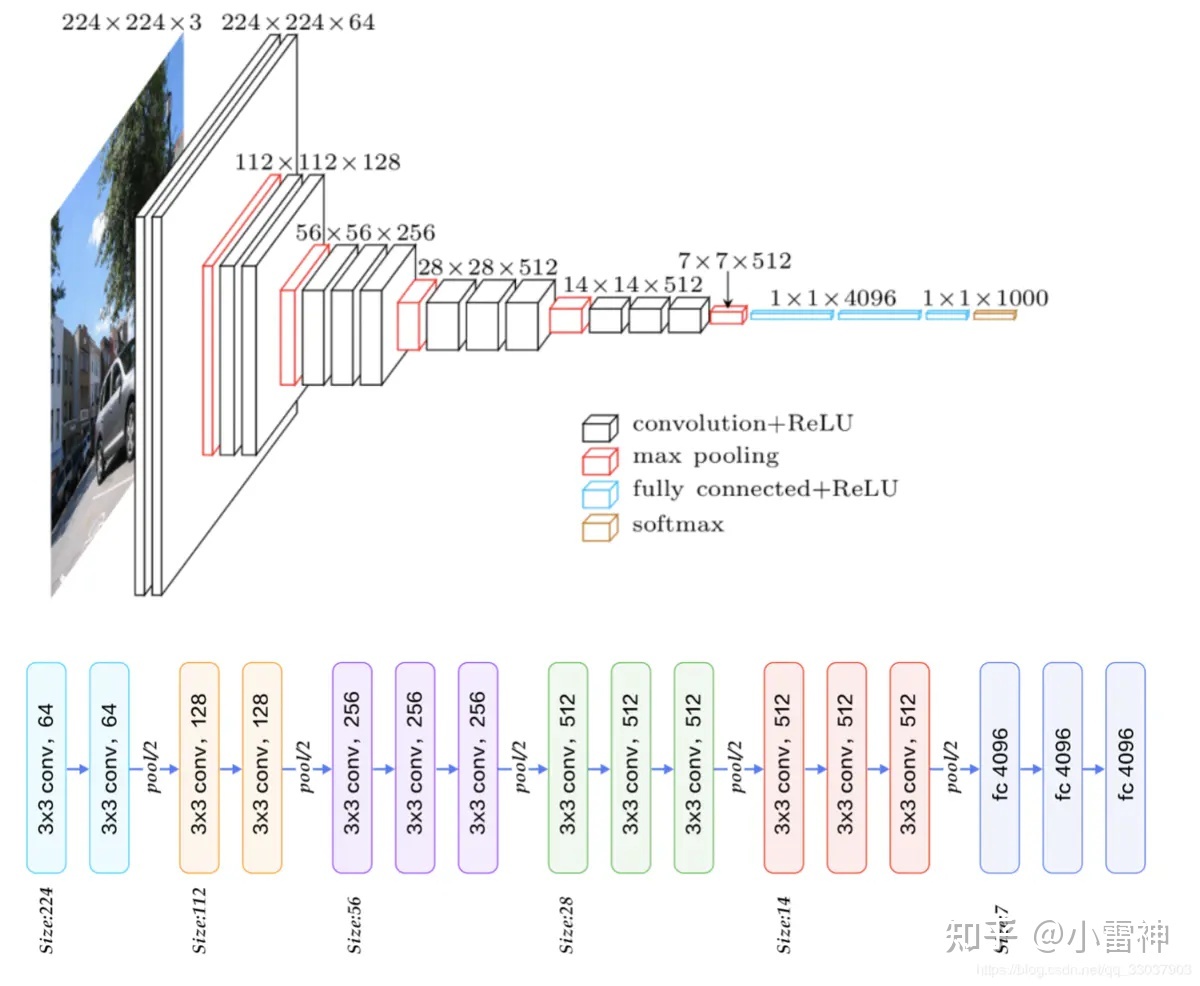
- 把全连接层(fc6、fc7、fc8)改成卷积层 (分割任务)
- 把最后两个池化层(pool4、pool5)的步长2改为1(保证feature的分辨率)
- 把最后三个卷积层(conv5_1、conv5_2、conv5_3)的dilate rate 设置为2,且第一个全连接层的dilate rate设置为4(保持感受野)
- 把最后一个全连接层fc8的通道数从1000改为21(类别数)

作者也考虑到了多尺度问题,所以在VGG16的基础上,在输入图像的前四个最大池化层的输出后面添加两层MLP——第一层为128个3x3卷积核,第二层为128个1x1卷积核。将它们拼接到网络的最后一层的特征图(类似于跳跃结构),前4个的128输出+最后输出的128,总共得到了5x128=640个通道。此处处理多尺度的方法将前面的浅层的信息拼接到深层,在精度上有一点的提升.
实验结果:


创新点:
1、空洞卷积
2、CRF
3、多尺度
参考链接:
Deeplab v1: Semantic image segmentation with deep convolutional nets and fully connected CRFS - 知乎















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









