







来源:IROS 2019
链接:https://ieeexplore.ieee.org/document/8967704
0、摘要
可靠、准确的定位和映射是大多数自动驾驶系统的关键组成部分。除了映射环境的几何信息外,语义在实现智能导航行为方面也起着重要作用。在大多数现实环境中,由于移动对象引起的动态变换,这个任务特别复杂,这可能会破坏建图或定位。在本文中,我们提出了最近发表的基于表面的建图方法的扩展,利用三维激光距离扫描,通过整合语义信息来促进建图过程。利用全卷积神经网络高效提取语义信息,并在激光距离数据的球面投影上进行渲染。这种计算的语义分割结果是整个扫描的逐点标签,允许我们用标记的冲浪建立一个语义丰富的地图。这种语义映射使我们能够可靠地过滤运动物体,但也通过语义约束改善投影扫描匹配。我们对KITTI数据集中具有挑战性的高速公路序列进行了实验评估,其中包含很少的静态结构和大量的移动车辆,与纯几何的、最先进的方法相比,我们的语义SLAM方法具有优势。
I. INTRODUCTION
准确的定位和对未知环境的可靠建图是大多数自动驾驶汽车的基础。这类系统通常在高度动态的环境中运行,这使得生成一致的地图变得更加困难。此外,需要关于映射区域的语义信息来实现智能导航行为。例如,一辆自动驾驶汽车必须能够可靠地找到一个合法停车的位置,或者在乘客可能安全出口的地方靠边停车——即使是在从未见过的位置,因此没有准确地绘制出来。
在这项工作中,我们提出了一种新的同时定位和建图(SLAM)方法,能够通过使用三维激光距离扫描生成这种语义地图。我们的方法利用了现代激光雷达SLAM管道[2]的思想,并结合了由全卷积神经网络(FCN)[21]生成的语义分割获得的语义信息。这使我们能够生成高质量的语义地图,同时改进地图的几何形状和里程计的质量。
FCN为激光范围扫描的每个点提供类别标签。我们首先使用球面投影对点云进行高效处理。然后将二维球面投影上的分类结果反投影到三维点云上。然而,反向投影引入了伪影,我们通过两个步骤的侵蚀过程来减少伪影,然后是基于深度的语义标签的洪水填充。然后将语义标签集成到基于面元表示的地图表示中,并利用它来更好地将新的观察结果注册到已经构建的地图中。在更新地图时,我们进一步通过检查新观察和世界模型之间的语义一致性来使用语义过滤移动物体。通过这种方式,我们减少了将动态对象集成到地图中的风险。图1显示了我们的语义图表示的一个例子。语义类由Milioto等人的FCN生成,该FCN由Behley等人使用SemanticKITTI数据集进行训练。
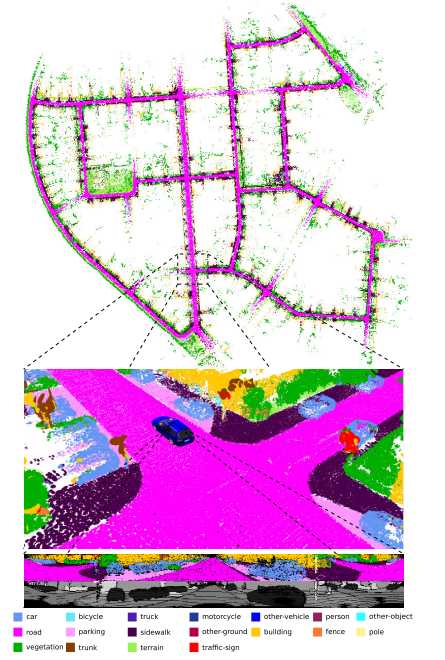
本文的主要贡献是将语义集成到基于面元地图表示中,以及利用这些语义标签过滤动态对象的方法。总而言之,我们声称我们(i)能够准确地映射环境,特别是在有大量移动物体的情况下,我们(ii)能够比在一般环境(包括城市,农村和高速公路场景)中简单地删除可能移动的物体的相同映射系统实现更好的性能。我们在KITTI[11]的挑战性序列上实验评估了我们的方法,并显示了我们的语义冲浪映射方法(称为suma++)与纯粹基于几何冲浪的映射和基于类标签去除所有潜在移动对象的映射相比的优越性能。我们的方法的源代码可在:GitHub - PRBonn/semantic_suma: SuMa++: Efficient LiDAR-based Semantic SLAM (Chen et al IROS 2019)
II. RELATED WORK
里程估计和 SLAM 是机器人技术中的经典主题,多篇概述文章 [6]、[7]、[28] 涵盖了大量的科学工作。在这里,我们主要关注基于学习方法和动态场景的语义SLAM的相关工作。
受深度学习和用于场景理解的卷积神经网络 (CNN) 进步的推动,出现了许多使用相机 [5]、[31]、相机 + IMU 数据 [4]、立体相机 [10] 来利用这些信息的语义 SLAM 技术。 ]、[15]、[18]、[33]、[38] 或 RGB-D 传感器 [3]、[19]、[20]、[26]、[27]、[30]、[39] 。这些方法大多数仅应用于室内,并使用对象检测器或相机图像的语义分割。相比之下,我们仅使用激光距离数据,并利用对激光雷达扫描生成的深度图像进行语义分割的信息。
还存在大量解决定位和映射变化环境的文献,例如通过过滤移动对象[14]、考虑匹配中的残差[22]或通过利用序列信息[34]。为了实现户外大规模语义SLAM,还可以将3D LiDAR传感器与RGB相机相结合。严等人。 [37]将 2D 图像和 3D 点关联起来以改进检测移动对象的分割。 Wang 和 Kim [35] 使用 KITTI 数据集 [11] 中的图像和 3D 点云来联合估计道路布局,并通过应用相对位置先验从语义上分割城市场景。郑等人。 [12]、[13]还提出了一种基于多模态传感器的语义 3D 映射系统,以在大规模环境以及具有功能很少。梁等人。 [17] 提出了一种新颖的 3D 物体检测器,可以利用 LiDAR 和相机数据来执行准确的物体定位。所有这些方法都侧重于将 3D LiDAR 和相机结合起来,以改进对象检测、语义分割或 3D 重建。
Parkison 等人最近的工作。 [23]通过直接将基于图像的语义信息纳入两个点云之间相对变换的估计中,开发了一种点云配准算法。 Zaganidis 等人的后续工作。 [40]实现了LiDAR与图像结合和仅LiDAR的语义3D点云配准。这两种方法都使用语义信息来改进姿态估计,但由于处理时间长,它们不能用于在线操作。
与本文提出的方法最相似的是 Sun 等人 [29] 和 Dub´e 等人 [9],仅使用单个 LiDAR 传感器即可实现语义 SLAM。孙等人。[29]提出了一种语义映射方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4016
4016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









