





论文标题:RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
0、摘要
现有的策略学习方法主要采用以任务为中心的范式,因此需要以端到端方式收集任务数据。因此,学习策略在处理新任务时往往失败。此外,对于具有多个阶段的复杂任务,由于端到端学习,很难对错误进行定位。为了应对这些挑战,我们提出了RoboMatrix,这是一个以技能为中心的分层框架,用于可扩展的任务规划和执行。我们首先介绍了一种新的以技能为中心的范式,从不同的复杂任务中提取常见的元技能。这允许通过以技能为中心的方法捕获具体化的演示,通过结合学习到的元技能来完成开放世界的任务。为了充分利用元技能,我们进一步开发了一个分层框架,将复杂的机器人任务解耦为三个相互关联的层:(1)高级模块化调度层;(2)中级技能层;(3)底层硬件层。实验结果表明,我们的以技能为中心的分层框架在新对象、场景、任务和实施例中取得了显著的泛化性能。该框架为开放环境下的机器人任务规划和执行提供了一种新颖的解决方案。我们的软件和硬件可在https://github.com/WayneMao/RoboMatrix上获得。
1、引言
移动操作是嵌入式人工智能中的一个重要课题,近年来取得了很大的进展。它主要关注智能机器人如何进行感知、任务规划以及与物理环境的交互。许多策略,如模仿学习[7,58,60]和强化学习方法[16,49,56],在过去几年中被提出用于移动操作。近年来,随着视觉语言模型(VLMs)的发展[29,30],一些研究提出了将视觉编码器与大型语言模型相结合的视觉语言-动作(VLA)模型,用于操作[3,27,63]和导航[45,59,61,62]中的动作预测。这些VLA模型使用给定的摄像机视频执行端到端学习,以及模仿学习[7,58,60]和强化学习方法[16,49,56]等核心方法,在过去几年中被提出用于移动操作。近年来,随着视觉语言模型(VLMs)的发展[29,30],一些研究提出了将视觉编码器与大型语言模型相结合的视觉语言-动作(VLA)模型,用于操作[3,27,63]和导航[45,59,61,62]中的动作预测。这些VLA模型使用给定的摄像机视频和相应的动作执行端到端学习。
基于VLA的操作策略主要遵循以任务为中心的范式学习,如图1(a)所示。它要求以一次性的方式收集演示以及相应的操作。对于给定的任务,以任务为中心的范式将整个任务视为一项技能。任务策略以端到端方式学习,并且严重依赖于整个任务数据。这种范式有以下几个缺点:
- (1)数据收集效率低。许多复杂的任务往往涉及多个阶段,一次演示需要很长时间。
- (2)对新任务的泛化程度低。由于新任务未包含在训练数据中,因此无法生成新的动作序列。
- (3)推理错误难以定位。由于端到端学习的黑箱,很难区分错误发生在哪个阶段。
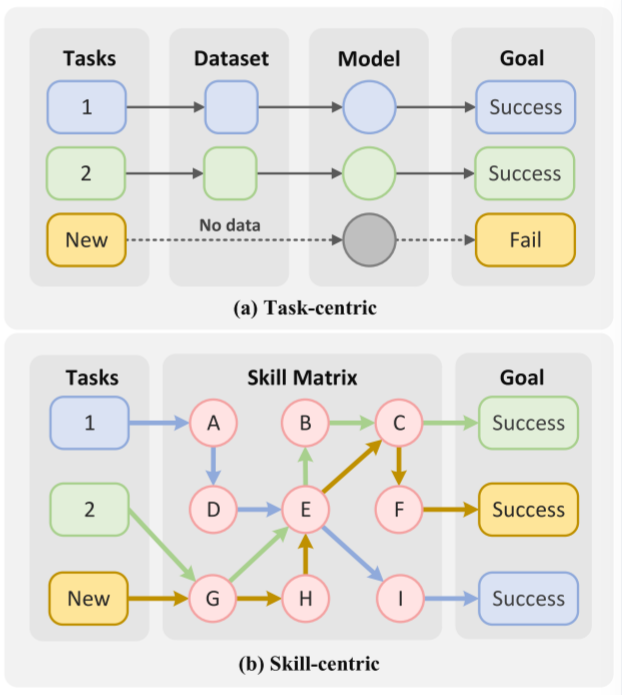
在本文中,我们提出了一个以技能为中心的分层框架,称为RoboMatrix。为了解决任务中心学习框架中存在的问题,我们引入了所谓的技能中心范式(见图(b))。在此范式中,我们从不同的复杂任务中提取出常见的元技能(meta-skills)来构建技能矩阵(skill matrix)。这些元技能通过一个统一的VLA模型和几个混合模型来学习。通过这种方式,不同的开放世界任务可以通过构建的技能矩阵中的动态路由来完成。为了实现任务的动态分解和为新任务安排技能,RoboMatrix采用了分层框架。它分为三层:调度层、技能层和硬件层。
- 调度层采用通用大型语言模型对任务进行分解,选择合适的技能模型。
- 技能层由元技能模型组成,如上所述。
- 硬件层包括物理机器人和通信系统,便于与高层模块无缝集成。
与以任务为中心的范例相比,我们在robommatrix中以技能为中心的方法提供了增强的可解释性,从而使其更容易识别和定位系统错误。当特定技能表现不佳时,我们的方法只需要收集该技能的数据,而以任务为中心的方法则需要收集整个任务的数据。通过组合不同的技能,我们的框架在开放世界场景中实现了卓越的泛化。RoboMatrix的分层结构使大型语言模型能够高效地进行任务分解和技能规划。综上所述,我们的贡献可以总结如下:
- 一个以技能为中心的分层框架,用于开放世界场景中可扩展的机器人任务规划和执行。
- 一种新的统一的移动操作VLA模型,能够同时进行机器人的运动和操作。
- 我们的框架展示了对新对象、场景、任务和实施例的伟大概括。
2. Related Works
2.1. Task Planning
长期以来,解决长期任务一直是机器人研究的中心焦点。行为树已被广泛应用于有限任务集内的状态切换[33,36]。然而,它们的有效性受到固定控制流的限制,使得它们对动态环境的适应性较差。[31]利用神经网络进行高级子任务选择来处理复杂和可变的任务,但这些方法在处理开放世界场景中需要推理的任务时仍然面临挑战。
随着大型语言模型的快速发展,在开放世界环境中处理长期复杂任务已经成为可能。许多研究使用大型语言模型作为高级任务规划器,将语言指令翻译成机器人的可执行子任务[2,17,20,47,48]。一些研究利用大型语言模型来分解任务并生成完成子任务的代码[28,34]。此外,许多研究结合了多模态基础模型,利用场景理解和语言推理能力来解决长期复杂任务[12,19,24]。
2.2. Task-centric and Skill-centric
以任务为中心的方法旨在提高特定任务的性能,通常需要收集特定任务的数据或设计专门的方法[4,8,14,22]。这个过程通常是耗时且费力的,在将这些方法推广到其他任务时提出了挑战。另一方面,利用大型语言模型的高级任务规划能力,可以定义多个子任务来完成各种复杂任务[10,18,52]。尽管如此,每个子任务都需要特定的数据或方法来实现。当任务超出预定义集合时,整体执行可能会失败。
相反,以技能为中心的方法强调开发可在不同任务中重用的通用技能[15,44]。通过组合各种元技能,可以灵活地完成广泛的任务,而不需要特定于任务的数据收集或重新设计。在本文中,我们着重于获取元技能和建立技能数据库,以完成各种任务。
2.3. LLM-driven research in Embodied AI
最近在大型语言模型方面的进展已经在具身智能方面显示出有希望的结果。直接利用ChatGPT构建agent进行任务分解和规划。多模态大型模型,如,整合了视觉、语言和其他模态信息,以增强机器人对环境的理解和与环境的交互。这些模型利用大规模数据集的预训练能力和特定任务数据的微调能力,在各种具体的人工智能任务中实现最先进的性能。另一方面,VisionLanguageAction (VLA)模型则更进一步,将视觉和语言信息直接与机器人的动作决策相结合。
3. Methods
3.1. Overview
在这项工作中,我们提出了robommatrix,一个以技能为中心的分层框架。我们将首先介绍以技能为中心(参见第3.2节)。然后,我们的技能模型,包括视觉-语言-行动和混合模型,将分别在3.3节中描述。最后阐述了由模块化调度层、技能层和硬件层组成的RoboMatrix总体框架(参见3.4节)。
3.2. Skill-centric Pipeline
在开放世界中,任务的无限多样性使得为每个单独的任务收集数据变得不切实际。每当建立新任务时,收集特定于任务的数据是一项资源密集型且耗时的工作。随着开放世界中各种各样的任务的出现,一个自然的问题出现了:在不同的任务之间是否存在不变的元素?这个问题将我们带到了元技能的概念。
3.2.1. Meta-skills
事实上,不同的任务倾向于共享共同的元技能,而元技能的集合仍然是有限的和可枚举的。如图2所示,我们演示了构建以技能为中心的管道的过程。虽然不同的机器人执行各种各样的任务,但它们通常具有相似的共同操作,例如移动,操纵和抓取。这些相似的技能被聚合成单一的元技能。
为了获得元技能,我们通常根据特定的技能对任务数据进行分割,然后将类似的技能分组,将它们定义为元技能。例如,在移动方面,机器人具有移动到盒子、抽屉或其他物体的能力。这些技能被整合到一个单一的元技能中,即“移动到目标”。
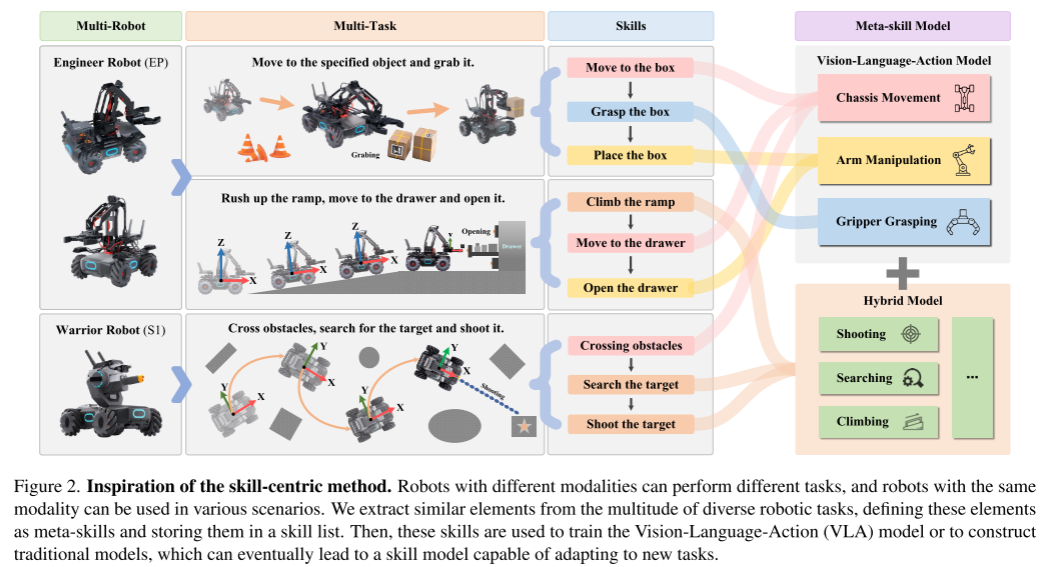
3.2.2. Skill Database
我们主要关注的是在技能水平上扩展数据库。在初始阶段,我们平等地收集所有技能的一些演示。将收集到的技能数据进行清理和重组,形成统一的技能数据库。基于现有的数据库,我们训练技能模型,然后在真实的机器人上进行测试,以评估它们的表现。在测试期间,我们识别并记录表现不佳的技能。在接下来的阶段,我们只收集表现不佳的技能的数据,以提高他们的表现。将新收集的技能数据整合到数据库中,迭代地对技能模型进行再训练。训练、测试和数据回忆的循环使我们能够产生大量高质量的技能数据。与以任务为中心的方法相比,我们以技能为中心的方法能够更有效地收集数据,并且需要更少的数据。
3.3. Skill Models
根据不同技能的特点,技能模型主要包括基于vla的和混合模型。如图3所示,VLA模型主要侧重于运动和操作,混合模型主要用于射击、搜索和攀爬。
3.3.1. Vision-Language-Action Model(运动和操作)
我们的VLA技能模型建立在基于LLaMA2[50]训练的纯解码大型语言模型 Vicuna 1.5[38]上。视觉编码器使用CLIP-Large[42],输入大小为336×336px,然后是两个线性层用于视觉嵌入投影。整个模型将图像和技能提示作为输入,并产生离散的动作。为了保持大型语言模型输出更高的稳定性,我们将连续动作投影到discrete bins。在对收集到的多机器人数据进行综合统计分析后,我们将离散箱的最优数量设置为256个。值得注意的是,虽然RT-2[63]选择覆盖256个低频使用的标记,但我们添加了256个特殊标记以避免破坏原始词汇表。我们的离散动作被划分为7个维度,每个维度包含256 bins,由下式表示:
![]()
其中,代表停止信号,用于确定单个技能操作是否完成。∆X,∆Y,∆θyaw分别表示真实地平面上X-Y位置和旋转角度的差值。∆µpos和∆νpos为夹持器末端执行器位姿,φ为夹持器的二进制状态。(疑问:∆µpos和∆νpos为夹持器末端执行器位姿,位姿一般是六自由度,看图片应该是机械臂末端没有自由度,只有俯仰角、偏航角)
Alignment Training
为了实现多模态对齐,我们利用了来自LLaVA 1.5[29]的预训练视觉嵌入投影。对于机器人领域的对齐,我们冻结了视觉编码器,同时解冻了投影和大型语言模型。然后,我们使用web数据的多模态文本-图像对和我们的粗糙图像对数据集执行共同微调。
Supervised Fine-tuning
我们利用来自精细注释技能数据的技能数据库中的大约60K视觉动作指令调优数据。在模型训练期间,我们解冻了所有参数,包括视觉编码器。
3.3.2. Hybrid Model (射击、搜索和攀爬)
对于非结构化环境中的任务,例如对象操作和抓取,基于llm的模型的显著泛化能力允许处理来自组件的不确定性,例如对象放置、方向和类别,以及环境中的其他不可预测因素。另一方面,当任务在机器人状态和控制目标具有高度确定性的特定环境中执行时,现有的传统模型能够获得更好的控制性能。例如,我们的射击技巧采用了混合方法,将比例导数(PD)控制与开放世界探测器YOLOWorld[6]相结合。PD控制用于云台调整,而YOLOWorld探测器协助瞄准。机器人调用适当的传统技能模型,并根据自己的传感器数据最小化单个控制变量的误差。攀爬和搜索技能也使用混合方法,将PD控制与传感器相结合。附录提供了有关混合模型的更多细节。
3.4. RoboMatrix Framework
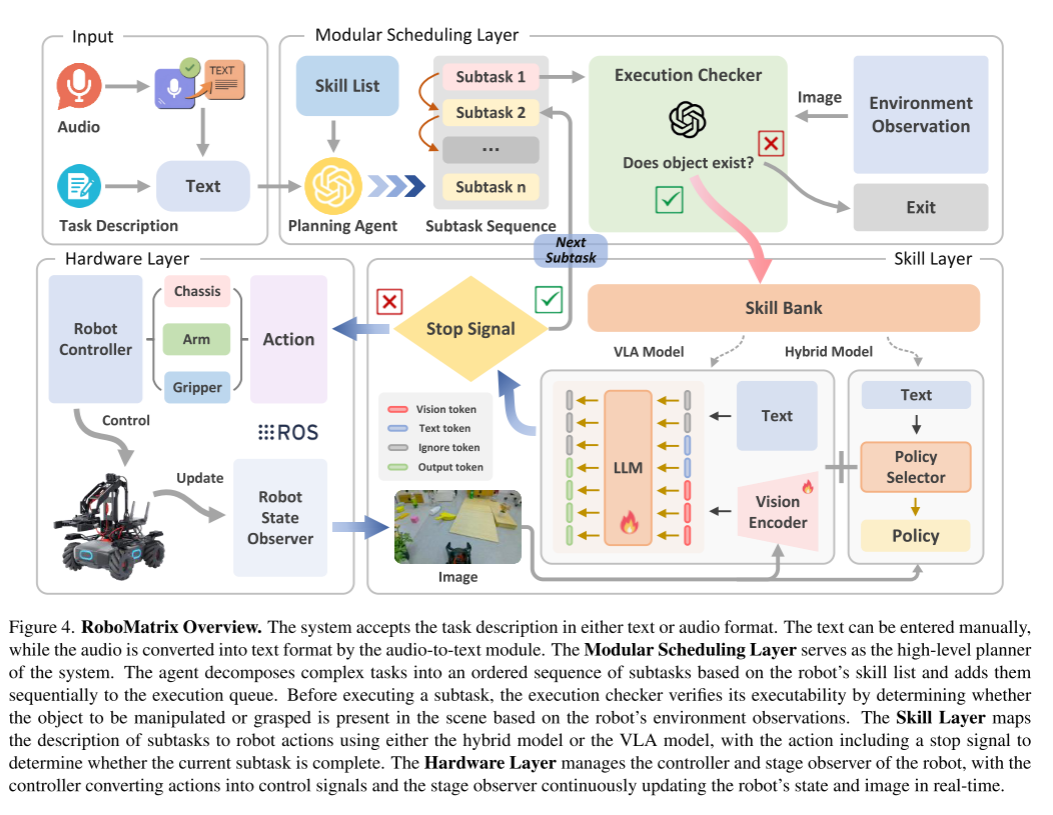
3.4.1. Modular Scheduling Layer
模块化调度层将复杂任务分解为子任务序列,并根据技能模型的观察和反馈对其执行进行调度,以保证整个任务序列的正确高效执行。
Task-Planning Agent
我们开发了一个基于生成式预训练变压器(GPT)[1]和LangChain[37]的任务规划代理。在开放世界中,代理通过文本或音频到文本的方式接收任务描述。模块化调度层包含一个技能列表,该技能列表存储各种元技能的提示集合(参见图3)。规划代理根据任务描述和元技能列表生成要按顺序执行的子任务序列。如果在任务分解过程中产生了新的技能,它们将被手工细化并添加到元技能列表中,以便将来重用。
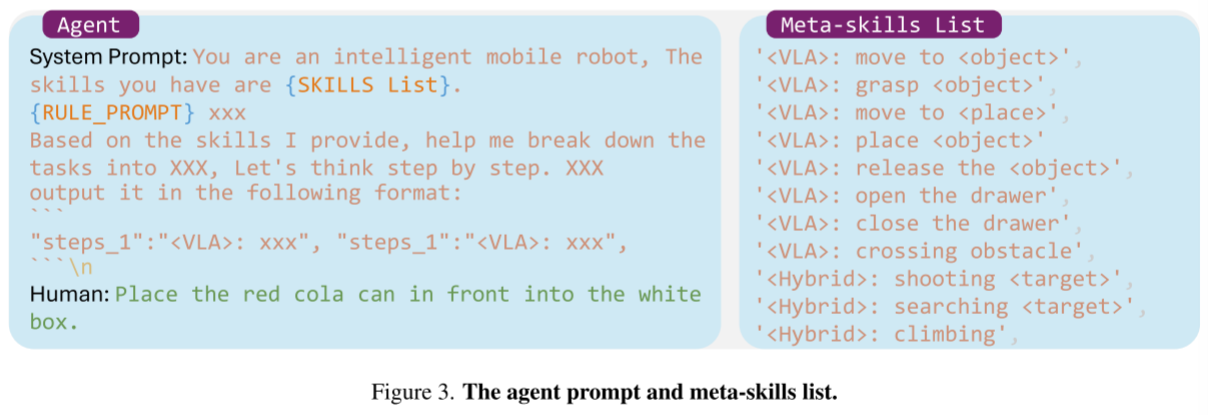 Execution Checker
Execution Checker
考虑一个子任务,“移动到红色可乐罐”;检查器首先提取对象名称“红色可乐罐”。然后将对象名称和图像发送给开放词汇对象检测器(OVOD) -Grounding DINO v1.5[43]进行检测。一旦在图像中检测到对象,就会提示技能层。否则会导致进程中断。因此,执行检查器确保每个子任务在当前条件下是可执行的,从而提高任务执行的整体效率和成功率。
3.4.2. Skill Layer
技能层为机器人提供各种可执行的技能。参见3.3节了解更多细节。
3.4.3. Hardware Layer
硬件层基于数据分发服务(DDS)进行设计,DDS是多个机器人并行执行实时任务的基础。DDS的分散特性允许机器人在自己模块内的节点之间或多个机器人之间建立直接通信,而不依赖于主节点。有了这样的通信功能,所有机器人都连接到同一个局域网(LAN),而技能VLA模型的推理任务则在基于云的服务器上执行。因此,机器人和服务器之间的通信机制类似于客户机-服务器模式,机器人充当客户机。具体来说,机器人需要通过特定协议将观测数据(如图像)发送到云服务器,并请求相应的动作响应。此外,控制器采用类似于发布者-订阅者模型的机制,通过将动作值转换为机器人模块的控制信号来管理机器人。这些信号根据主题直接映射到机器人上。
4. Experiments
4.1. Implementation Details
Robot Configuration
我们使用大疆RoboMaster系列机器人作为RoboMatrix的物理平台。不同模式的机器人可以通过特定的网络通信协议连接到一台计算机上,从而允许RoboMatrix同时控制多个机器人。我们在机器人操作系统2 (ROS2)[32]框架内重新组织了RoboMaster的开源API,使技能模型的分布式控制和高效调度更加灵活。控制模式可以通过改变控制信号源的映射来切换,既可以通过Xbox控制器进行远程操作,也可以通过技能模型进行自主控制。
Dataset and Annotation
我们从大约5000集高质量的人类长期任务演示中提取了八项技能的数据,以适当的比例使用基于规则和手动注释。图5说明了我们VLA模型的八项元技能。每项技能都可以独立执行,也可以组合起来执行长期任务。我们确保每个技能的数据在各个维度上的多样性和全面性,包括对象类别、外观、位置、机器人初始状态和场景复杂性。原始数据中来自机器人状态观测的噪声被过滤,以确保在数据的所有维度上均匀分布。此外,我们将这5k集汇编成一个完整的数据集。从完整的数据集中,我们选择了5种不同技能的200集来创建一个迷你数据集。除非特别说明,所有消融实验默认在迷你数据集上进行。
 Data Augmentation
Data Augmentation
我们对每个技能的停止帧进行数据增强,以保证停止信号输出的稳定性。这些停止帧被复制以在整体技能数据中获得适当的比例。
Training and Inference
VLA技能模型的训练使用8个A100 gpu, 80GB内存,批量大小为96个。在推理过程中,VLA模型在单个A100 GPU上运行。为了促进有效的部署,我们实现了一个远程VLA推理服务器,可以实现实时动作预测,允许机器人在不依赖本地计算资源的情况下进行控制。在所有训练阶段,VLA模型以1 epoch进行训练。此外,对于对齐和SFT训练,我们使用学习率为25 -5和预热比为0.01,遵循LLaVA-1.5[29]配置。
4.2. Performance on Meta-skills
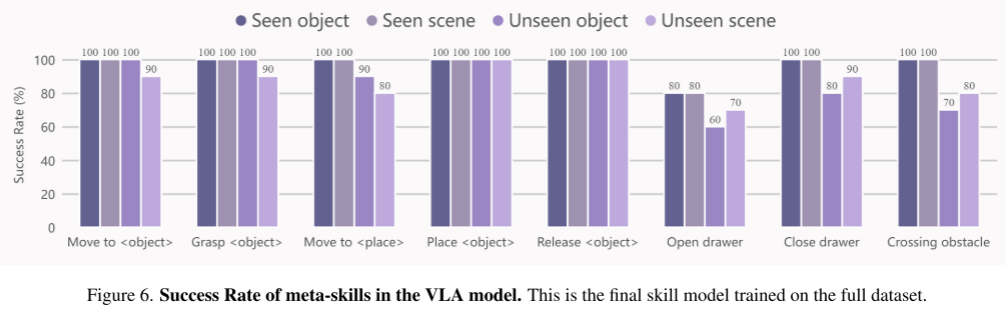
我们使用VLA模型对八项元技能进行了综合评估(见图5)。除非另有说明,本文中所有实验默认为10次测试。如图6的条形图所示,看到的物体和看到的场景的结果表明我们的技能模型具有很强的性能。在不可见物体和不可见场景上的出色表现进一步验证了我们的技能模型的泛化能力。与应用于可见场景的技能相比,应用于未见场景的技能表现出轻微的性能下降。然而,对于“释放<对象>”和“放置<对象>”技能,我们的VLA模型展示的性能水平与所见场景中的对应对象相当。
4.3. Performance on Task-level Generalization
我们选择“将粉色立方体放入白色盒子”作为基本任务来评估不同泛化水平的VLA性能(见图)。
Evaluation Protocol
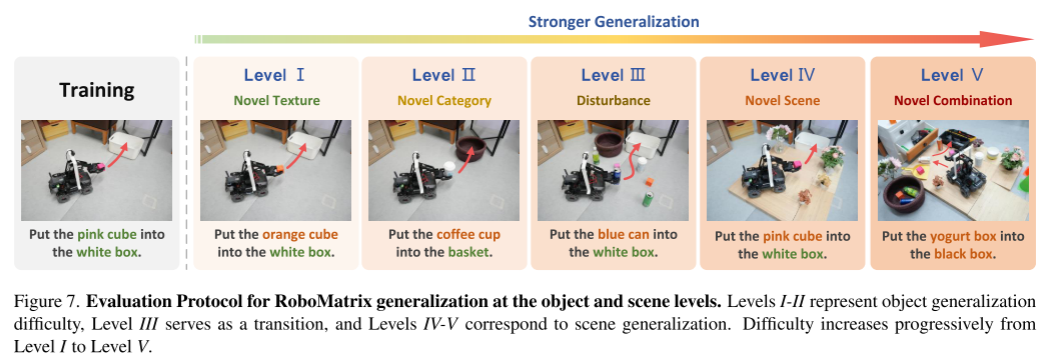
在VIMA[24]的基础上,我们引入了一个5级泛化评估协议,如图7所示。由于开放世界环境中评估的复杂性,我们的指标主要评估对象和场景泛化。I-II级表示难;Level III作为过渡,Level IV-V对应场景概化。难度从I级逐渐增加到v级。IV-V级主要评估对象泛化,并根据对象识别的难度来区分它们。III-V级侧重于场景概化,其差异主要取决于场景的复杂性。
 Object and Scene Generalization
Object and Scene Generalization
在表1中,我们给出了以任务为中心和以技能为中心的VLA模型在迷你和完整数据集上的泛化性能比较。对于简单的关卡,我们以技能为中心的方法略优于以任务为中心的方法,而对于更具挑战性的关卡,我们以技能为中心的方法明显优于以任务为中心的方法。这些结果表明,以技能为中心的方法在处理困难和长期任务时具有明显的优势。

Task and Embodiment Generalization
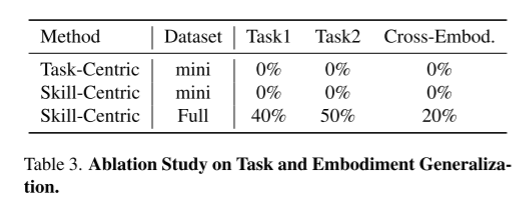
如图8所示,我们进一步在任务和实施层面验证了以技能为中心的方法的泛化能力。我们对两种类型的长视界任务进行了实验,每种任务都需要在控制场景和要操作的对象时执行十种元技能。此外,我们将EP机器人训练的模型直接部署到S1机器人上进行越障和射击任务。尽管任务很复杂,但我们以技能为中心的方法在任务1和任务2上分别取得了40%和50%的成功率,如表3所示。此外,我们的方法在转移到新机器人上时达到了20%的成功率。

Mode Size
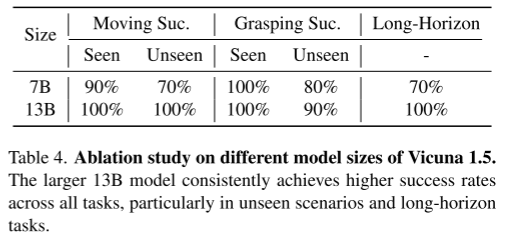
在大型语言模型领域,增加模型参数通常意味着更强的泛化和理解能力。表4表明,这一原则也适用于VLA模型。除了模型大小之外,所有其他实验设置,包括对齐训练和监督微调(SFT),在模型之间保持相同。较大的13B模型始终在所有任务中实现更高的成功率,特别是在需要长期规划的未知场景和任务中。
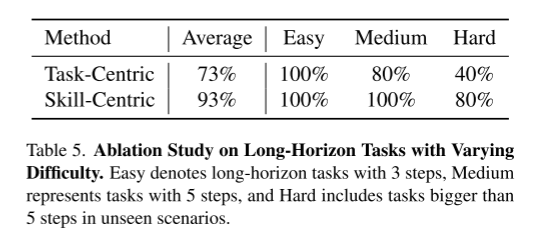
Long-Horizon
表5给出了不同难度水平的远景任务的消融研究。一般来说,随着任务范围的增加,难度水平也会提高。对于简单的任务,以任务为中心和以技能为中心的方法的成功率是相当的。然而,对于中长期任务,以技能为中心的方法比以任务为中心的方法表现好20%,而在较困难的任务中,这一差距进一步扩大到40%。因此,我们以技能为中心的方法的优势随着任务范围的增加而变得更加明显。
5. Conclusion
在这项工作中,我们提出了一个以技能为中心的分层框架,用于开放世界环境中可扩展的机器人任务规划和执行,解决了复杂场景中对适应性和高效机器人控制的需求。我们框架的一个关键创新是专门为运动和操作设计的统一视觉语言动作(VLA)模型,它集成了运动和操作输出,以实现多功能机器人动作。此外,我们的框架展示了跨多个维度的鲁棒的泛化,包括对象、场景、任务和多机器人泛化,强调了其适应性和各种应用的潜力。总的来说,这些贡献代表了可扩展和可推广的机器人自主性的实质性进步。
6. Hardware Platform
本节将介绍RoboMatrix的硬件平台,如图9所示。

6.1. RoboMaster Robot
我们使用大疆RoboMaster系列机器人作为硬件平台,包括工程机器人(EP)和战士机器人(S1)。这两种形式的机器人有一些共同的组件,包括移动底盘、单目RGB摄像头、音频模块和控制器。此外,每个机器人都配备了一套独特的组件来执行特定的任务,例如S1机器人的目标射击能力和EP机器人的目标抓取能力。
底盘。移动底盘配备Mecanum车轮,提供全方位的机动性。这种配置支持解耦的平移运动和原地旋转。内置的惯性测量单元(IMU)可以实时计算机器人相对于参考坐标系的位置和方向,更新频率高达50赫兹。
摄像头和音频模块。单目RGB相机可以捕获分辨率为1280 × 720像素和30 FPS的视频流。音频模块能够捕获环境音频并播放预先录制的声音。值得注意的是,我们调整了EP机器人上的摄像机位置,以稳定其视点(120°)。音频模块接收命令的最佳范围为2m以内。
万向节和爆破枪。这些是S1机器人独有的部件。爆炸装置安装在一个2度的自由框架上,允许沿俯仰角和偏航角旋转。它的瞄准镜与相机对齐,它能够以高达26米/秒的初始速度发射子弹。
机械臂和抓手。这些都是EP机器人独有的部件。该夹持器安装在2自由度的机械臂上,由于机械臂独特的连杆机构设计,使得夹持器始终保持水平运动。机械臂的正运动学和逆运动学易于计算。夹持器的动作是二元的,只包括打开和关闭。
控制器。通过使用指定的应用软件将控制器连接到局域网,同一网络内的计算机可以通过官方软件开发工具包(SDK)控制机器人,包括控制机器人的各个模块和从其各种传感器中检索数据。控制信号的延迟取决于网络质量,通常在100毫秒左右。值得注意的是,一台计算机可以扫描网络中的所有机器人,并用特定的序列号控制机器人。
6.2. Teleoperation
我们使用操纵杆对机器人进行远程操作,并将操纵杆的控制信号映射到机器人的控制系统。
机器人独立模块。来自操纵杆的输入映射到底盘的平移速度矢量,通过按钮添加旋转速度。然后将目标速度计算到电机速度中以控制底盘的运动。
机器人专用模块。无论是EP机器人还是S1机器人,具体模块的控制都可以抽象为对二自由度机构的控制以及末端执行器的动作指令。来自一组帽开关的输入映射到机器人手臂末端执行器位置或框架方向的变化。同时,一个按钮的输入被映射到夹持器的打开和关闭,以及爆能枪的发射。
7. Hybrid Model
在本节中,我们将介绍混合模型在robommatrix中的实现细节,如图10所示。
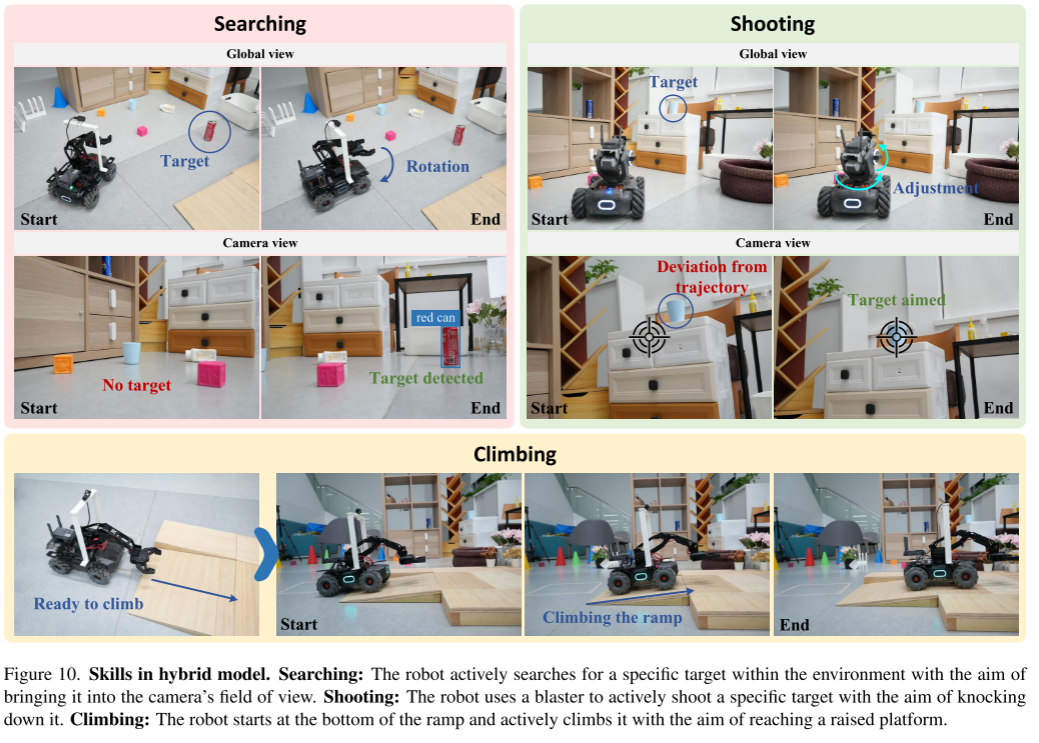 混合模式技能。
混合模式技能。
- 搜索:机器人在环境中主动搜索特定目标,目的是将其带入相机的视野。
- 射击:机器人使用爆炸枪主动射击一个特定的目标,目的是击倒它。
- 攀爬:机器人从坡道底部开始主动攀爬,目标是到达一个凸起的平台
7.1. Searching
机器人在环境中主动搜索特定目标,目的是将其带入相机的视野。
调整EP机器人上的摄像头角度需要改变整个底盘的位置或方向,因为摄像头是固定在机器人上的。因此,仅控制底盘就足以修改相机的视点。另一方面,由于S1机器人上的摄像机安装在一个云台上,因此可以通过控制云台来调整视点。通过将机器人的运动控制模式设置为“云台引导”,底盘可以跟随云台的运动,从而实现相机和机器人基座之间的同步运动。
设置合适的角速度来控制底盘或云台的旋转。当机器人执行一个完整的360度扫描时,它以一个定义的频率捕获环境的图像。该图像以及目标的名称由轻量级开放词汇对象检测器(YOLO-World)处理,以确定指定的对象是否存在于机器人当前的视场中。当机器人发现目标时,它就停止旋转。
7.2. Shooting
机器人使用爆能枪主动射击一个特定的目标,目的是击倒它。
由于爆能枪的准星与相机的中心对齐,所以有必要控制万向架的运动,以确保目标物体位于相机视场的中心。该过程类似于视觉伺服控制策略,其中控制器可以基于比例导数(PD)控制构建。
利用YOLO-World检测器在一定频率下获得当前图像中目标的边界框。根据边界框中心与图像中心之间的相对位置计算云台的控制信号,机器人继续调整云台,直到位置差落在可接受的公差范围内。考虑到重力的影响,根据传感器(红外距离传感器)的距离信息调整爆震枪的准星,使其略高于目标物体。
7.3. Climbing
机器人从坡道底部开始,主动爬上坡道,目的是到达一个凸起的平台。在机器人底盘与坡道对齐的情况下,根据坡道的坡度分配合理的速度值,控制机器人在坡道上的运动,防止机器人滑倒。坡道的坡度可以使用机器人内置的传感器(惯性测量单元)来计算,该传感器与机器人的姿态(俯仰角)相对应。当机器人到达平台时,由俯仰角为零指示机器人停止移动。
8. Additional Experiment Details
8.1. More Details on Experiment Setting
训练。我们利用8个A100 gpu进行大约180小时的对齐训练。预训练数据范围更广,但质量较低,有助于模型学习各种策略并从错误中恢复。在监督微调(SFT)阶段,我们在相同的环境下训练了大约30个小时。SFT数据更加集中,使用高质量的人工注释数据来教模型如何通过以技能为中心的策略完成任务。
8.2. More Details on Dataset
人类注释。为了获得用于监督微调(SFT)阶段的高质量、以技能为中心的数据,我们使用了许多注释器来标记这些数据。虽然这些注释者最初缺乏相关经验,但通过专家主导的训练,他们很快就掌握了必要的注释技能。对于收集到的技能视频,注释者从开始和结束删除无效片段,丢弃执行不良的数据的整个片段。此外,他们为每个有效的技能视频分配一个特定的技能名称。
绝对位置和相对位置。在数据编码方法上,我们实验了绝对位置和相对位置两种方法。我们发现,使用绝对位置编码时,机器人很难成功执行任务,并且模型容易过度拟合数据,失去泛化能力。因此,我们对所有数据都采用相对位置法。
区间预测。在现实世界的实验中,我们发现当使用当前帧图像作为输入,当前帧动作作为监督时,训练好的模型预测的动作变化很小,导致机器人运动缓慢。我们假设这可能与模型预测的小幅度的动作变化有关。我们尝试使用当前帧图像作为输入,未来帧动作作为监督。最终,我们发现使用SFT提前10帧的动作可以产生最佳的机器人运动性能,确保机器人既不会移动得太慢也不会太快,否则可能导致不精确的操作。使用未来框架动作使模型能够学习更多的前瞻性规划和决策能力,从而平滑和改进机器人的运动。
8.3. More Details on RoboMatrix-ROS
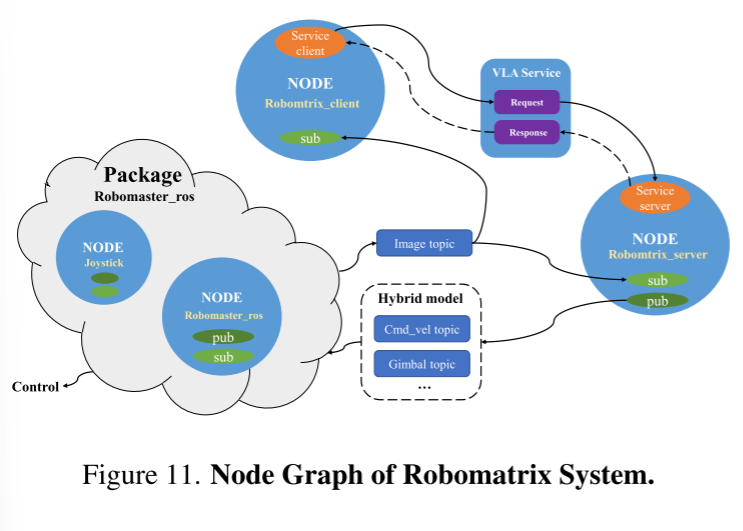
整个系统采用ROS框架进行管理,实现更加模块化和高效的通信和控制。它分为四个节点,如图11所示。robomaster ros包包括基本控制节点和远程操作节点。它发布传感器主题并接收底盘和框架的控制主题,以实现VLA模型或混合模型。系统内的任务规划和管理使用ROS服务机制执行。robommatrix客户端节点负责任务规划和调用特定的VLA技能。使用自定义请求发送详细的任务和提示。VLA技能的实现在robommatrix服务器节点中执行,该节点接收技能名称和命令,执行子任务,并返回执行结果。然后,robommatrix客户端节点接收这些结果并发送下一个子任务或继续规划和管理下一任务。
9. More Experiments
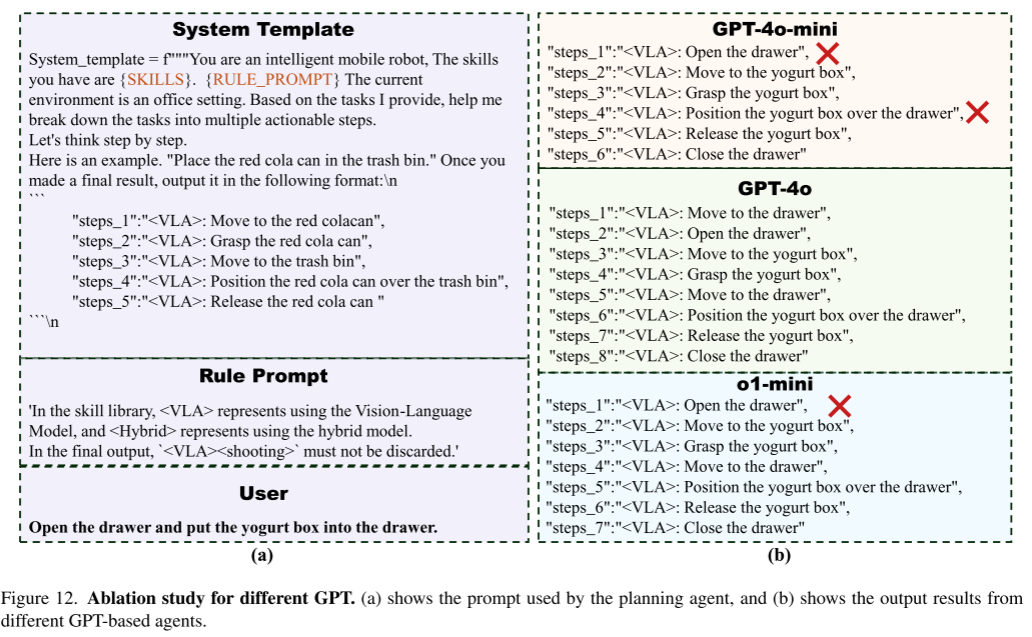
如图12(a)所示,规划代理中使用的提示符包括“User”下的示例任务描述。图 (b)为agent使用不同GPT模型作为基础模型时的输出结果。从图中可以看出,gpt - 40 -mini和01 -mini跳过了“移动到抽屉”这一步,直接执行了“打开抽屉”。在此任务分解场景中,o1-mini的性能优于gpt - 40 -mini,但低于gpt - 40。总体而言,gpt - 40的实验结果一致 更接近我们的期望。
10. Additional Visualizations
10.1. Assets

对象。图13显示了数据采集过程中使用的可见对象和实验过程中使用的不可见对象。场景。在数据采集过程中,只向场景中添加了相关的物体和少量的干扰物。在实验中,我们通过改变场景中物体的类型、数量和相对位置来创造看不见的场景。
10.2. Long-horizon Tasks
在长期任务中,以技能为中心的robommatrix比以任务为中心的方法具有显著的优势。它可以通过重用现有的技能来完成任务,而不需要收集大量的额外数据。我们在三个人工设计的长期任务中验证了robommatrix的能力,展示了我们在论文中提到的四个级别的泛化。
任务1:穿过前面的障碍物,把红色的罐子放进白色的盒子里。如图14所示,EP机器人需要先通过障碍物到达主场景,然后接近并抓住红色罐子。最后,它必须把红色的罐子运到白色的盒子里,并把它放在里面。即使障碍物发生了变化,场景中增加了干扰,要抓住的物体发生了变化,或者它们的位置发生了变化,机器人仍然可以成功地完成任务。

任务2:爬上坡道,把绿色罐头放进抽屉里。如图15所示,EP机器人首先爬上坡道到达平台,然后拿起绿色罐子,最后将其放入打开的抽屉中。值得注意的是,场景中的盆栽植物不会干扰任务的执行。此外,即使需要将物体放入看不见的黑色工具箱中,机器人也能成功完成任务。

任务3:打开抽屉,把紫色的立方体放进抽屉,然后关上抽屉。如图图所示,EP机器人在场景中首先打开闭合的抽屉,然后将紫色块放在里面的抽屉旁边,最后关闭抽屉。即使在抽屉旁边增加了干扰,机器人仍然可以在没有任何干扰的情况下完成任务。

小结:
- 前提假设任务是多种元技能组合而成,元技能有8种,想要实现真正的开放世界开放任务几乎是不可能的,但是仍可以学习有限的元技能,组合出多种任务。
- 原技能的训练是VLA,通过后续的动作作为监督,当不同机械臂是否通用需要考虑,同时标注和训练成本其实不小,A100*8*200h +。
- cross obstacle作为元技能,searching作为混合技能,不知道是否有显示构建地图,SLAM或者语义地图,当大范围机器人如何仅靠单目实现轨迹规划。
- 混合模型像是RM的工作,应该是打比赛的产出,如射击、爬坡,麦轮等。
- 整体可行性比较高,很多设置可供参考,但是数据集 没有统一的标准,定量结果其实有很大程度的人类主观难度分类,10次实验算成功率其实偏差较大,这应该是目前具身的共同问题,尤其是异构机器人如何统一标准判断。没有评价指标,后续同赛道发论文应该比较困难。
- 实验表明,任务分解大模型的选择也比较重要,不同模型在给定skill list其实也很难准确的给出子任务序列(gpt-mini)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









