







- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
1.PIPELINE 流水线指令(Functions, loops)
7.INTERFACE(Function,parameters)
一、常用术语
1.LUT 或 SICE
LUT 或 SICE是构成了 FPGA 的区域。它的数量有限,当它用完时,意味着设计太大。
2.BRAM 或 Block RAM
FPGA中的内存。
3.Latency延迟
1.设计产生结果所需的时钟周期数。
2.循环的延迟是一次迭代所需的时钟周期数。
4.Initiation Interval (or II, or Interval间隔)
在接受新数据之前必须执行的时钟周期数。这与延迟不同!如果函数是流水线的,许多数据项会同时流过它。延迟是一个数据项被推入后弹出的时间,而时间间隔决定了数据可以被推入的速率。
循环的间隔是可以开始循环迭代的最大速率,以时钟周期为单位。
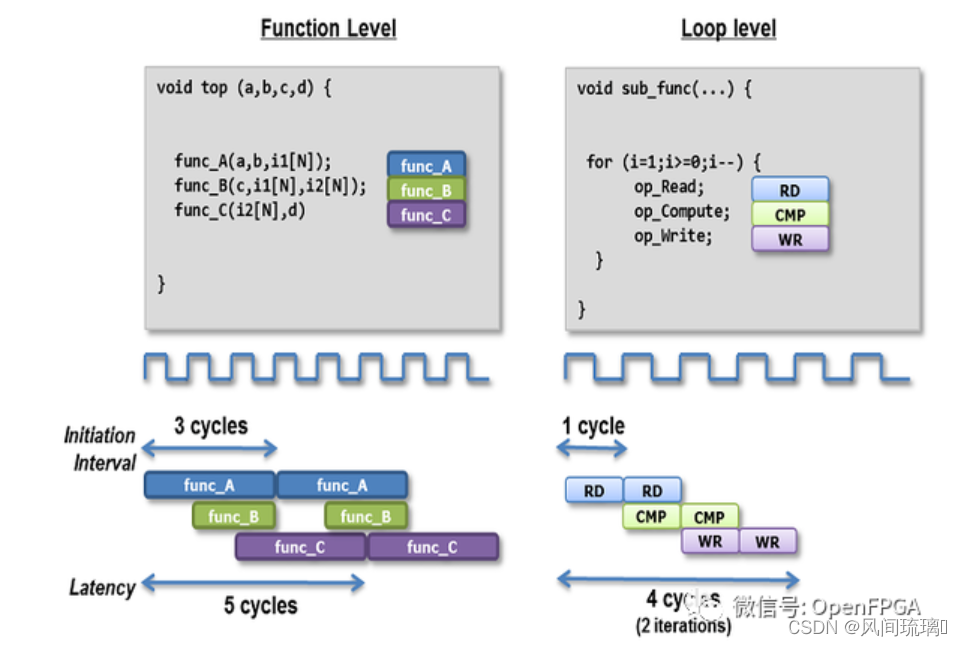
上图中,左边是函数右边是循环,左边的时间间隔(接收新数据之前)是3个时钟周期,右边循环的间隔则是一个时钟周期;对于左边的延迟是这个函数产生结果的时钟周期数,是func_C运行完毕产生的周期数,为5个时钟周期,右边循环的延迟是一次迭代所需的时钟数,是4个时钟周期。
二、常用指令
使用范围:
Functions - 函数
loops - 循环
Various - 所有都适合
Arrays - 数组
parameters - 参数
1.PIPELINE 流水线指令(Functions, loops)
说明:使输入更频繁地传递给函数或循环。流水线后的函数或循环可以每 N 个时钟周期处理一次新入,其中 N 是启动间隔(Initiation Interval)。'II' 默认为 1,是 HLS 应针对的启动间隔(即尝试将新数据项输入管道的速度应该多快)。
流水打拍允许并发执行操作,以缩短函数或循环的启动时间间隔 (II): 每个执行步骤无需等待完成所有操作后再开始下一项操作。流水打拍适用于函数和循环。下图显示了通过函数流水打拍实现的吞吐量提升。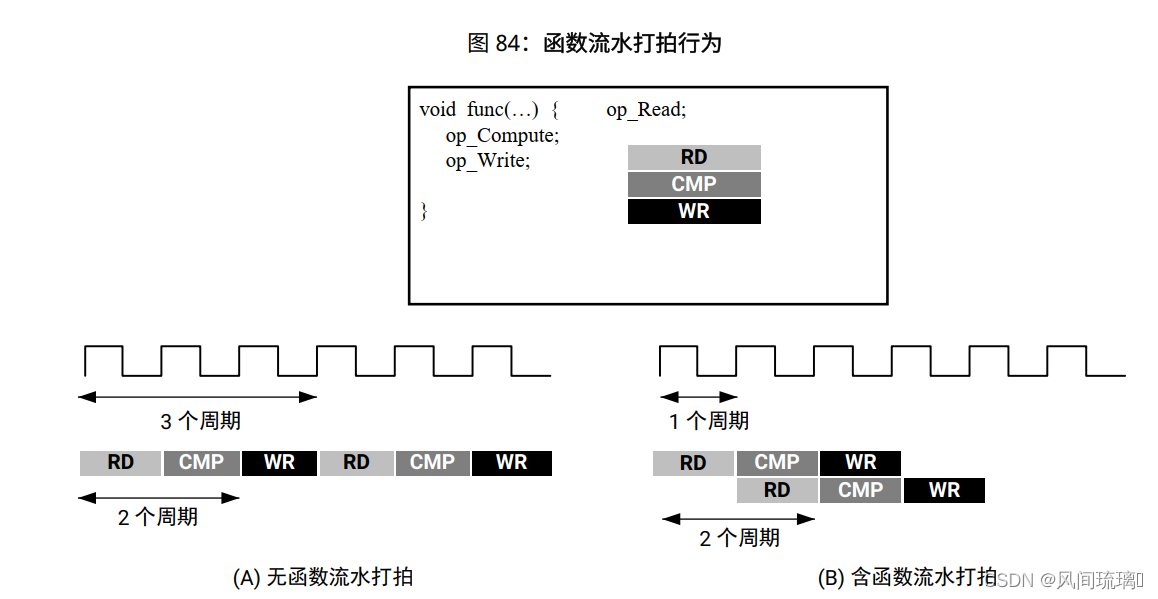
如果不使用流水打拍, 上述示例中的函数将每隔 3 个时钟周期读取一次输入, 并在 2 个时钟周期后输出值。该函数启动时间间隔 (II) 为 3, 时延为 3。使用流水打拍后, 对于此示例, 每个周期都会读取 1 次新输入 (II=1), 且不更改输出时延。
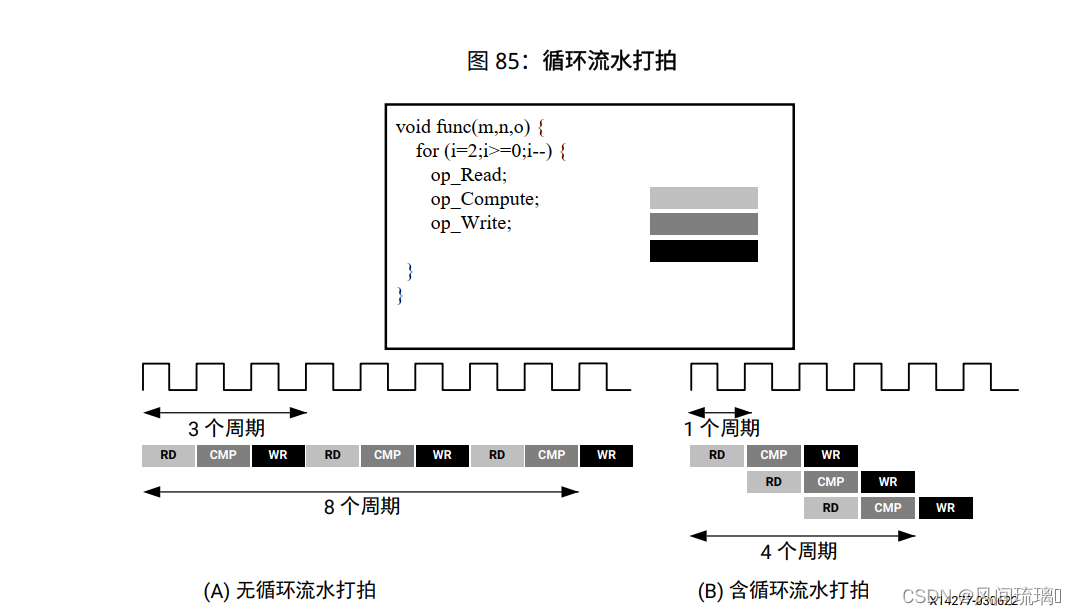
循环流水打拍支持以重叠方式来实现循环中的操作。在下图中, (A) 显示了默认顺序操作, 每次输入读操作间存在 3 个时钟周期 (II=3), 需要经过 8 个时钟周期才会执行最后一次输出写操作。
在 (B) 所示的循环的流水打拍版本中, 每个周期都会读取一次新输入样本 (II=1), 仅需 4 个时钟周期后即可写入最终输出, 在使用相同硬件资源的前提下显著改善 II 和时延。
流水打拍函数或循环每 <N> 个时钟周期即可处理新输入, 其中 <N> 是该循环或函数的 II。如果 II 为 1, 则表示每个时钟周期都处理新输入。可通过为编译指示使用 II 选项来指定启动时间间隔。
语法:将 C 语言源代码中的编译指示置于函数或循环的主体内
#pragma HLS pipeline II=<int> off rewind style=<value>II=<int>: 指定期望的流水线启动时间间隔。 HLS 工具会尝试满足此请求。根据数据依赖关系, 实际结果的启动时间间隔可能更大。
off: 可选关键字。关闭特定循环或函数的流水线。当使用 config_compile -pipeline_loops 对循环进行全局流水打拍时, 可使用该选项来为特定循环禁用流水打拍。
rewind: 可选关键字。支持回绕, 这样即可支持持续性循环流水打拍, 但在循环执行结束与下一次执行开始之间没有暂停。仅当顶层函数内只有一个循环(或完美循环嵌套) 时, 回绕才有效。循环前的代码段:
• 被视为初始化
• 在流水线中仅执行一次
• 无法包含任何条件操作符 (if-else)
仅针对流水打拍循环才支持此功能,针对流水打拍函数不支持。
style=<stp | frp | flp>: 指定要用于指定的函数或循环的流水线类型。流水线类型包括:
①stp: 停止流水线。仅当输入数据可用时才运行, 否则停滞。这是默认设置, 也是 Vitis HLS 用于循环和函数流水打拍的流水线类型。无需可刷新流水线时, 请使用此类型。例如, 没有导致停滞的性能或死锁问题时即可用。
②flp: 该选项将流水线定义为可刷新流水线,此类型的流水线通常耗用更多资源和/或可
能 II 较大, 因为无法在流水线迭代间共享资源。
③frp: 自由运行的可刷新流水线。即使输入数据不可用也可运行。如果由于流水线控制信号扇出减少而导致需要更好的时序, 或者如果需要提升性能以免死锁, 则可使用此类型。但此流水线风格可能功耗更大, 因为即使没有数据也会对流水线寄存器进行计时。
示例:func 函数按启动时间间隔 1 来进行流水打拍
void func { a, b, c, d} {
#pragma HLS pipeline II=1
...
}已流水打拍的函数与已流水打拍的循环之间行为存在差异:
对于函数, 流水线将永久运行, 永不终止
对于循环, 流水线将持续执行直至循环的所有迭代完成为止
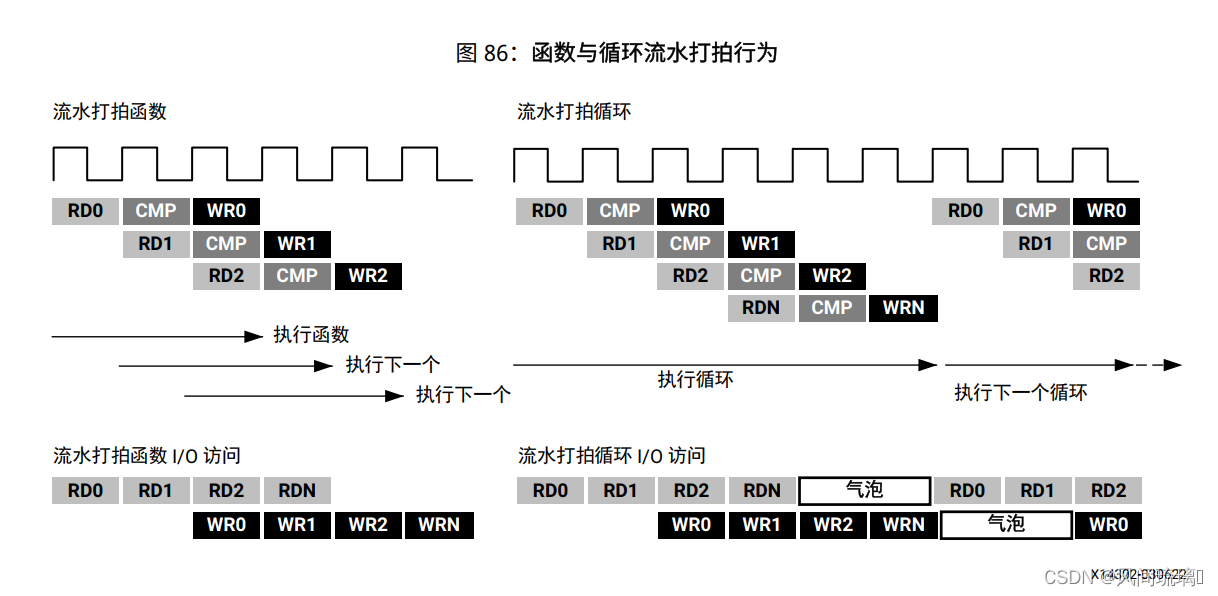
行为差异会影响流水线输入和输出的处理方式。如上图所示, 已流水打拍的函数将持续读取新输入和写入新输出。由于循环必须首先完成循环中的所有操作, 然后才能启动下一次循环, 已流水打拍的循环会导致数据串流中出现“气泡” ,即当循环完成执行最终迭代后不读取任何新输入的时间点, 以及当循环开始新循环迭代时不写入新输出的时间点。
2.UNROLL(loops)
说明:创建循环的因子副本,让其并行执行(如果满足数据流依赖性)。但是会浪费资源,以资源换取速度。尽可能将程序展开以提高速度。展开循环以创建多个独立操作而非单个操作集。UNROLL 编译指示会通过在 RTL 设计中创建循环主体的多个副本来变换循环, 从而允许部分或全部循环迭代并行发生。
展开循环以改善流水打拍,默认情况下, 在 Vitis HLS 中循环保持处于收起状态。这些收起的循环会生成硬件资源, 供循环的每次迭代使用。虽然这样可创建资源节约型块, 但有时可能导致性能瓶颈。循环的迭代执行次数由循环归纳变量来指定。迭代次数也可能受到循环主体内的逻辑影响,可使用 UNROLL 编译指示展开循环以便增加数据访问和吞吐量。
UNROLL 编译指示支持将循环完全展开或部分展开。完全展开循环会在 RTL 内为每个循环迭代创建一份循环主体副本, 因此整个循环可并发运行。部分展开循环允许指定因子 N 以创建 N 份循环主体副本, 并相应减少循环迭代。
下面示例假定阵列 a[i]、 b[i] 和 c[i] 均已映射到块RAM。此示例显示只需直接应用循环展开即可同时创建大量不同实现。
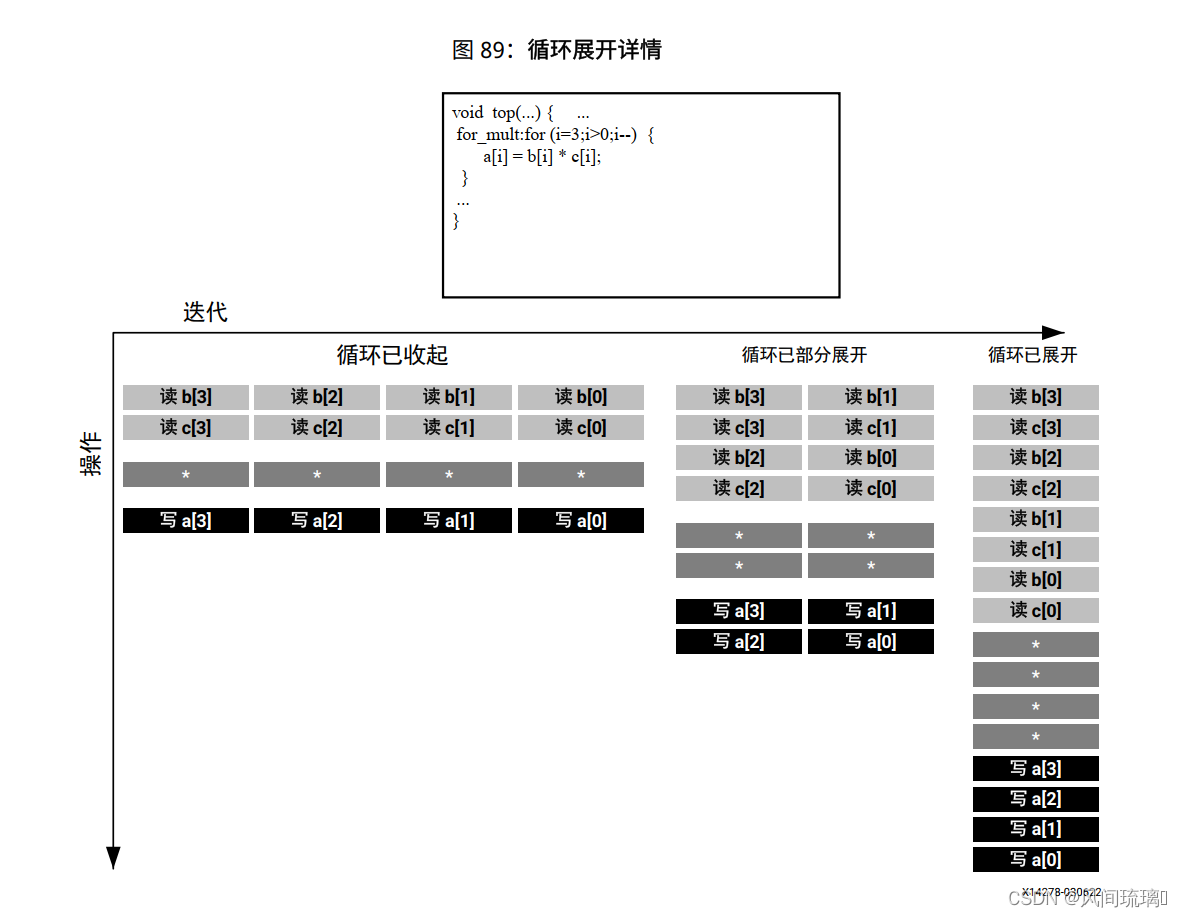
循环已收起: 当循环已收起时, 每次迭代都在单独的时钟周期内执行。此实现需耗时 4 个时钟周期, 只需 1 个乘法器并且每个块 RAM 均可为单端口块 RAM。
循环已部分展开: 在此示例中, 循环已按因子 2 部分展开。此实现需 2 个乘法器和双端口 RAM 以支持在同一个时钟周期内读取或写入每个 RAM。但此实现只需 2 个时钟周期即可完成: 相比于循环的收起版本, 启动时间间隔和时延均减半。
部分循环展开不要求 N 为最大循环迭代计数的整数因子。 Vitis HLS 工具会添加出口检查以确保部分展开的循环的功能与原始循环相同。给定以下代码:
for(int i = 0; i < X; i++) {
pragma HLS unroll factor=2
a[i] = b[i] + c[i];
}按因子 2 展开的循环可将代码有效变换为如下所示代码, 其中 break 构造函数用于确保功能保持不变, 并且循环会在相应的点退出:
for(int i = 0; i < X; i += 2) {
a[i] = b[i] + c[i];
if (i+1 >= X) break;
a[i+1] = b[i+1] + c[i+1];
}循环已展开: 在完全展开的版本中, 可在单一时钟周期内执行所有循环操作。但此实现需 4 个乘法器。更重要的是, 此实现需在同一个时钟周期内执行 4 次读操作和 4 次写操作的功能。由于块 RAM 最多仅有 2 个端口, 因此此实现需对阵列进行分区。
要执行循环展开, 可向设计中的每个循环应用 UNROLL 指令。也可向函数应用 UNROLL 指令,以展开函数作用域内的所有循环。
如果循环已完全展开, 那么只要数据依赖关系和资源允许, 即可并行执行所有操作。如果某一循环迭代中的操作需要上一次循环的结果, 则这两次迭代无法并行执行, 但一旦数据可用即可立即执行。完全展开并完全最优化的循环通常涉及循环主体中的多个逻辑副本。
语法:将 C 语言源代码中的编译指示置于要展开的循环主体内。
#pragma HLS unroll factor=<N> region skip_exit_checkfactor=<N>: 指定非零整数, 表示已请求部分展开。循环主体将重复指定次数, 迭代信息将进行相应的调整。如不指定 factor=, 则循环将完全展开。
skip_exit_check: 可选关键字, 仅当使用 factor= 指定部分展开时才适用。根据循环迭代计数为已知还是未知来判断是否消除出口检查:
①“Fixed bounds”
如果迭代计数为因数的倍数, 则不执行出口条件检查。如果迭代计数并非因数的整数倍, 则该工具将执行以下操作:○ 阻止展开。
○ 发出警告, 称必须执行出口检查后才能继续。②Variable bounds
移除出口条件检查。必须确保:○ 变量边界为因数的整数倍。
○ 实际上无需出口检查。
示例1:在 foo 函数内完全展开 loop_1。将编译指示置于 loop_1 主体内
loop_1: for(int i = 0; i < N; i++) {
#pragma HLS unroll
a[i] = b[i] + c[i];
}示例2:此示例指定展开因子为 4, 以部分展开 foo 函数的 loop_2, 并移除出口检查。
void foo (...) {
int8 array1[M];
int12 array2[N];
...
loop_2: for(i=0;i<M;i++) {
#pragma HLS unroll skip_exit_check factor=4
array1[i] = ...;
array2[i] = ...;
...
}
...
}3.ALLOCATION(Various)
说明:指定相应限制, 以便对已实现的内核中的资源分配加以限制。 ALLOCATION 编译指示或指令可限制用于实现特定函数、循环或运算的 RTL 实例和硬件资源的数量。 ALLOCATION 编译指示是在代码的函数、循环或区域主体内部指定的。
如果 C 语言代码包含函数 foo_sub 的 4 个实例, 那么 ALLOCATION 编译指示可确保最终 RTL 中仅有foo_sub 的 1 个实例。 C 语言函数的全部 4 个实例都是使用相同 RTL 块来实现的。这样即可减少函数所使用的资源量, 但由于共享这些资源, 故而对性能会产生负面影响。C 语言代码中的运算(例如, 加法、乘法、阵列读取和写入) 均可通过 ALLOCATION 编译指示来加以限制
显式限制运算符的数量以减小某些情况下所需的面积: Vitis HLS 的默认操作是首先最大限度提升性能。限制设计中的运算符数量是一项减小设计面积的实用技巧: 它通过强制共享运算来减小面积。但是这可能导致性能下降。
语法:将编译指示置于函数、循环或区域的主体内适用的位置。
#pragma HLS allocation <type> instances=<list> limit=<value>以下实参顺序至关重要。 <type> 作为运算或函数必须位于 allocation 关键字之后
<type>: 可指定以下任一类型:
① function: 指定分配适用于 instances= 列表中的函数。该函数可以是原始 C 语言或 C++ 语言代码中的任意函数, 但满足下列任一类型的函数除外:
• 由 pragma HLS inline 或 set_directive_inline 命令内联的函数
• 由 Vitis HLS 工具自动内联的函数。
②operation: 指定分配适用于 instances= 列表中的运算。
instances=<list>: 指定来自 C 代码的函数名称或运算符。
limit=<value>: (可选) 指定要在内核中使用的实例的限制。
示例1:在设计中具有函数 foo 的多个实例的情况下, 此示例用于将硬件内核的 RTL 中的 foo 实例数量限制为 2。
#pragma HLS allocation function instances=foo limit=2示例2:将函数 my_func 的实现中使用的乘法器运算数量限制为 1。此限制不适用于超出 my_func 范围的任意乘法器或者可能位于 my_func 的子函数内的乘法器
void my_func(data_t angle) {
#pragma HLS allocation operation instances=mul limit=1
...
}4.ARRAY_PARTITIO(Arrays)
说明:将一个大数组拆分为多个较小的数组。并提供下列特性:
①生成包含多个小型存储器或多个寄存器(而不是一个大型存储器) 的 RTL。
②有效增加存储器读写端口数量。
③可能改善设计吞吐量。
④需要更多存储器实例或寄存器
语法:将 C 语言源代码中的编译指示置于定义阵列变量的函数边界内。
#pragma HLS array_partition variable=<name> type=<type> factor=<int> dim=<int>variable=<name>: 必要实参, 用于指定要分区的阵列变量。
type=<type>: (可选) 指定分区类型。默认类型为 complete。支持以下类型:
①cyclic: 循环分区会通过交织来自原始阵列的元素来创建更小的阵列。该阵列按循环进行分区, 具体方式是在每个新阵列中放入一个元素, 然后回到第一个阵列以重复该循环直至阵列完全完成分区为止。如果使用factor=3:
• 向第 1 个新阵列分配元素 0。
• 向第 2 个新阵列分配元素 1。
• 向第 3 个新阵列分配元素 2。
• 向第 4 个新阵列分配元素 3。②block: 块分区会从原始阵列的连续块创建更小阵列。这样可将阵列有效分区为 N 个相等的块, 其中 N 为factor= 实参定义的整数。
③complete: 完全分区可将阵列分解为多个独立元素。对于一维阵列, 这对应于将存储器解析为独立寄存器,这是默认 <type>。
factor=<int>: 指定要创建的更小的阵列数量,对于 complete 型分区, 不指定该因子。对于 block 和 cyclic 型分区, 需指定 factor。
dim=<int>: 指定要分区的多维阵列的维度。针对含 <N> 维的阵列, 指定范围介于 0 到 <N> 之间的整数:
①如果使用 0 值, 则使用指定的类型和因子选项对多维阵列的所有维度进行分区。
②任意非零值均表示只对指定维度进行分区。例如, 如果使用的值为 1, 则仅对第 1 个维度进行分区。
示例1:使用 block 分区将 13 个元素的阵列 AB[13] 分区为 4 个阵列:
#pragma HLS array_partition variable=AB type=block factor=4由于 4 不是 13 的整数因子, 因此:其中 3 个新阵列各含 3 个元素,另 1 个阵列则包含 4 个元素 (AB[9:12])。
示例2:此示例分区将二维阵列 AB[6][4] 的维度 2 分区为 2 个维度为 [6][2] 的新阵列:
#pragma HLS array_partition variable=AB type=block factor=2 dim=2示例3:此示例将二维 in_local 阵列的第二个维度分区为各独立元素。
int in_local[MAX_SIZE][MAX_DIM];
#pragma HLS ARRAY_PARTITION variable=in_local type=complete dim=25.DATAFLOW(Functions)
说明:DATAFLOW 编译指示启用任务级流水打拍, 允许函数和循环在其操作过程中重叠, 增加 RTL 实现的并发度, 并增加设计的整体吞吐量。
在 C 语言描述中, 所有操作均按顺序执行。如无限制资源的任何指令(如 pragma HLS allocation), 则 Vitis HLS 工具会尝试最大限度减小时延并提高并发。但是, 数据依赖关系可能对此施加限制。
在访问阵列的函数或循环必须先完成对阵列的所有读写访问后才能完成操作。这样会阻止下一个使用该数据的函数或循环开始操作。DATAFLOW 最优化支持函数或循环中的操作在前一个函数或循环尚未完成其所有操作时就开始操作。
数据流最优化适用于一组顺序任务(例如, 函数和/或循环), 如下图所示。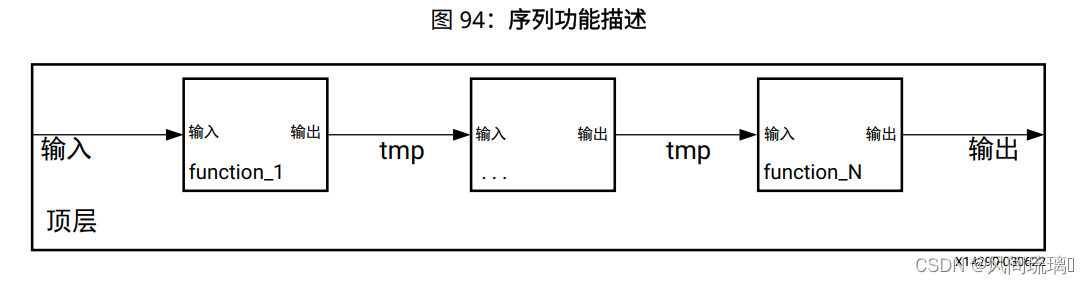
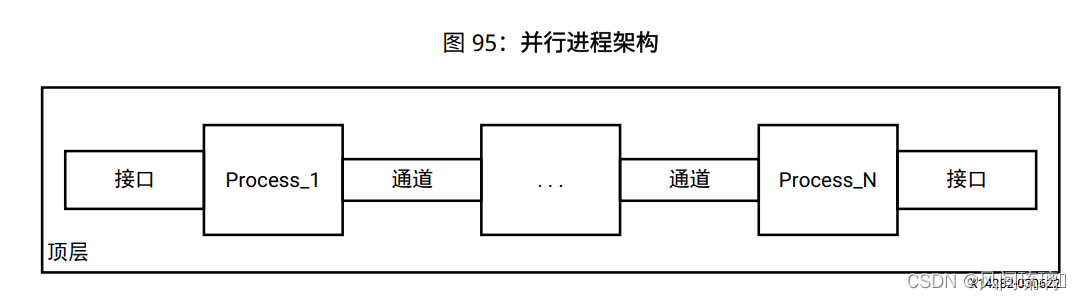
通过使用这一系列顺序任务, 数据流最优化可以创建并发进程架构, 如下所示。数据流最优化是可用于改进设计吞吐量和时延的强大方法。
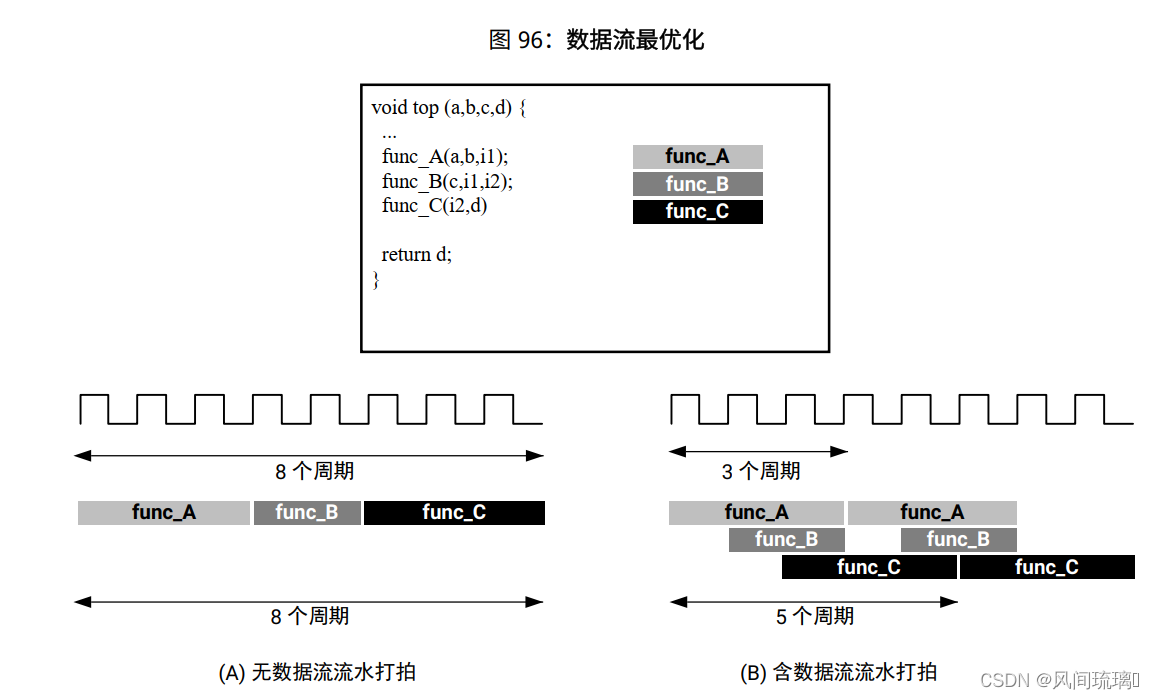
下图显示了数据流最优化允许重叠执行任务的方式, 由此可提升总体设计吞吐量并降低时延。 (A) 表示无数据流最优化的情况。实现需经历 8 个周期后, func_A 才能处理新输入, 还需要 8
个周期后 func_C 才能写入输出。(B) 表示应用数据流最优化的情况。 func_A 每隔 3 个时钟周期即可开始处理新输入(启动时间间隔更低), 只需 5 个时钟即可输出最终值(时延更短) 。
这种类型的并行化势必伴随着硬件开销。将某个特定区域(函数主体或循环主体) 识别为要应用数据流最优化的区域时, Vitis HLS 会分析此函数主体或循环主体, 并创建独立通道以对数据流进行建模, 用于将每项任务的结果存储在数据流区域中。
这些通道对于标量变量可能是简单的 FIFO,对于阵列类非标量变量, 可能是乒乓(PIPO) 缓冲器。其中每个通道还都包含用于指示 FIFO 缓冲器或乒乓缓冲器已满或已空的信号。这些信号表示完全数据驱动的握手接口。
通过采用独立 FIFO 缓冲器和/或乒乓缓冲器, Vitis HLS 可使每项任务按其自己的步调执行, 吞吐量仅受输入和输出缓冲器的可用性限制。由此产生的任务交织式执行比正常流水打拍实现效果更好, 但导致增加 FIFO 或块 RAM 寄存器(用于乒乓缓冲器) 成本, 如下图所示。
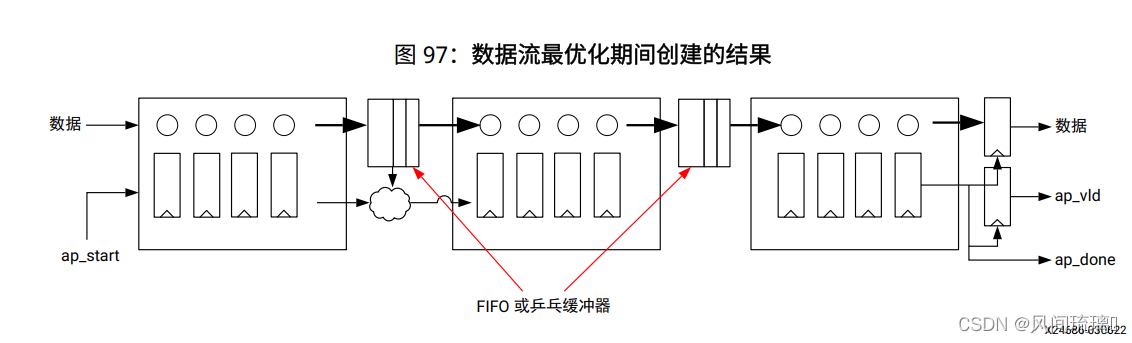
语法:将 C 语言源代码中的编译指示置于区域、函数或循环的边界内。
#pragma HLS dataflow [disable_start_propagation]disable_start_propagation: (可选) 禁用起始 FIFO 的创建, 起始 FIFO 用于向内部进程传输起始令牌。此类 FIFO 有时可能会成为性能瓶颈
示例:在 wr_loop_j 循环内指定 DATAFLOW 最优化。
wr_loop_j: for (int j = 0; j < TILE_PER_ROW; ++j) {
#pragma HLS DATAFLOW
wr_buf_loop_m: for (int m = 0; m < TILE_HEIGHT; ++m) {
wr_buf_loop_n: for (int n = 0; n < TILE_WIDTH; ++n) {
#pragma HLS PIPELINE
// should burst TILE_WIDTH in WORD beat
outFifo >> tile[m][n];
}
}
wr_loop_m: for (int m = 0; m < TILE_HEIGHT; ++m) {
wr_loop_n: for (int n = 0; n < TILE_WIDTH; ++n) {
#pragma HLS PIPELINE
outx[TILE_HEIGHT*TILE_PER_ROW*TILE_WIDTH*i
+TILE_PER_ROW*TILE_WIDTH*m+TILE_WIDTH*j+n] = tile[m][n];
}
}
6.INLINE(Functions)
说明:移除层级中作为独立实体的函数。完成内联后, 函数将消隐到调用函数内, 不再显示为 RTL 中的层级的独立层次。该指令不是将函数视为单个硬件单元,而是在每次调用 HLS 时将函数内联。这是以硬件为代价增加了潜在的并行性。如果 'recursive' 为真,则内联函数调用的所有函数也被视为标有 INLINE。
根据指定 INLINE 编译指示的方式, 该编译指示应用到的范围与定义该编译指示的范围会有所不同:
• INLINE: 如不指定实参, 那么该编译指示表示, 指定该编译指示的函数应向上内联到任意调用函数内。
• INLINE OFF: 该编译指示表示, 指定该编译指示的函数不应向上内联到任意调用函数内。这表示禁用特定函数的内联操作, 此类特定函数原本可能自动内联或者在递归过程中内联。
• INLINE RECURSIVE: 表示将该编译指示应用于它分配到的函数主体。它向下应用, 以递归方式内联该函数的内容。
默认情况下, 内联只能在函数层级的下一级上执行, 而不能对子函数执行。但 recursive 选项允许指定穿过层级的多个层次进行内联。
语法:将 C 语言源代码中的编译指示置于函数或代码区域的主体内。
#pragma HLS inline <recursive | off>recursive: 默认情况下, 仅执行一级函数内联, 并且不内联指定函数内部的函数。 recursive 选项会在指定函数或区域内按递归方式内联所有函数。
off: 禁用函数内联以防止指定函数发生内联。如果在函数中指定 recursive, 该选项会阻止调用的特定函数进行内联, 同时所有其它函数均可进行内联。
示例1:以下示例用于对 func_top 主体内部的所有函数执行内联, 以递归方式向下内联穿越整个函数层级, 但 func_sub 函数不执行内联。递归编译指示置于 func_top 函数内。用于禁用内联的编译指示则置于 func_sub 函数内:
func_sub (p, q) {
#pragma HLS inline off
int q1 = q + 10;
func(p1,q);// foo_3
...
}
void func_top { a, b, c, d} {
#pragma HLS inline recursive
...
func(a,b);//func_1
func(a,c);//func_2
func_sub(a,d);
...
}示例2:将 copy_output 函数内联到调用 copy_output 的任意函数或区域内。
void copy_output(int *out, int out_lcl[OSize * OSize], int output) {
#pragma HLS INLINE
// Calculate each work_item's result update location
int stride = output * OSize * OSize;
// Work_item updates output filter/image in DDR
writeOut: for(int itr = 0; itr < OSize * OSize; itr++) {
#pragma HLS PIPELINE
out[stride + itr] = out_lcl[itr];
}7.INTERFACE(Function,parameters)
说明:在 C/C++ 代码中, 通过正式的函数实参即可立即执行所有输入和输出操作。在 RTL 设计中,这些输入和输出操作必须通过设计接口中的端口来执行, 并且通常使用特定输入/输出 (I/O) 协议来进行操作。INTERFACE 编译指示可指定在接口综合期间如何根据函数定义创建 RTL 端口。
语法:将编译指示布局在函数边界内。
#pragma HLS interface mode=<mode> port=<name> bundle=<string> \
register register_mode=<mode> depth=<int> offset=<string> latency=<value>\
clock=<string> name=<string> storage_type=<value>\
num_read_outstanding=<int> num_write_outstanding=<int> \
max_read_burst_length=<int> max_write_burst_length=<int>mode=<mode>: 指定函数所使用的函数实参的接口协议模式或者块级控制协议。可指定以下任一模式:
ap_none: 无协议。此接口为数据端口
ap_stable: 无协议。此接口为数据端口。 HLS 工具假定数据端口复位后始终处于稳定状态, 这样即可支持内部最优化移除不必要的寄存器
ap_vld: 用于实现含关联 valid 端口的数据端口, 以指示何时数据有效且可供读取或写入
ap_ack: 用于实现含关联 acknowledge 端口的数据端口, 以确认数据已读取或写入。
ap_hs: 用于实现含关联 valid 端口和 acknowledge 端口的数据端口, 提供两路握手以指示数据有效且可供读取和写入, 并确认数据已读取或写入。
ap_ovld: 用于实现含关联 valid 端口的输出数据端口, 以指示何时数据有效且可供读取或写入
ap_fifo: 使用含关联低电平有效 FIFO empty 端口和 full 端口的数据输入和输出端口来实现含标准 FIFO接口的端口。
ap_memory: 用于实现阵列实参(作为标准 RAM 接口) 。如果在 Vivado IP integrator 中使用 RTL 设计, 存储器接口会显示为离散端口
bram: 用于实现阵列实参(作为标准 RAM 接口) 。如果在 IP integrator 中使用 RTL 设计, 存储器接口会显示为单端口。
axis: 用于实现所有端口(作为 AXI4-Stream 接口)
s_axilite: 用于实现所有端口(作为 AXI4-Lite 接口) 。 HLS 工具会在“Export RTL” (导出 RTL) 进程期间生成一组关联的 C 语言驱动程序文件。m_axi: 用于实现所有端口(作为 AXI4 接口) 。可使用 config_interface 命令来指定 32 位(默认) 地址端口或 64 位地址端口, 并控制任何地址偏移。
ap_ctrl_chain: 实现一组块级控制端口以启动 (start) 设计操作、继续执行 (continue) 操作, 以及指示设计何时处于 idle、 done 和 ready 状态, 以便处理新输入数据。ap_ctrl_chain 接口模式类似于 ap_ctrl_hs, 但可提供额外的 ap_continue 输入信号以应用反压。赛灵思建议使用 ap_ctrl_chain 块级 I/O 协议将 HLS 工具块链接在一起。ap_ctrl_chain 是默认块级 I/O 协议。
ap_ctrl_hs: 实现一组块级控制端口以启动 (start) 设计操作, 并指示设计何时处于 idle、 done 和 ready状态, 以便处理新输入数据。
ap_ctrl_none: 无块级 I/O 协议。使用 ap_ctrl_none 模式可阻止使用 C/RTL 协同仿真功能来验证设计。
port=<name>: 用于指定 INTERFACE 编译指示所应用到的函数实参或函数返回的名称。块级 I/O 协议(ap_ctrl_none、 ap_ctrl_hs 或 ap_ctrl_chain) 可分配到端口, 以供函数return 值使用。
bundle=<string>: 默认情况下, HLS 工具会将函数实参与兼容选项组合或捆绑到 RTL 中的接口端口内。所有AXI4-Lite (s_axilite) 接口都会尽可能捆绑到 AXI4-Lite 端口内。默认指定为 AXI4 (m_axi) 接口的所有函数实参也都会捆绑到单一 AXI4 端口内。含兼容选项(mode、 offset 和 bundle) 的所有接口端口都组合到单一接口端口内。端口名称自动衍生自模式与捆绑的组合, 或者可通过 -name 来指定名称。
register: 此可选关键字可用于寄存信号和任何相关协议信号, 并导致保持直至至少完成函数执行的最后一个周期为止。该选项适用于以下接口模式:
• s_axilite
• ap_fifo
• ap_none
• ap_hs• ap_ack
• ap_vld
• ap_ovld
• ap_stable
depth=<int>: 指定供测试激励文件处理的最大采样数。此设置用于指示 HLS 工具为 RTL 协同仿真所创建的验证适配器中所需 FIFO 的最大大小。虽然 depth 选项通常为可选, 但对于 m_axi 接口, 它是必需选项, 用于确定为适配器分配的资源量
offset=<string>: 为指定端口控制 AXI4-Lite (s_axilite) 和 AXI4 存储器映射 (m_axi) 接口中的地址偏移。
①在 s_axilite 接口中, <string> 用于指定寄存器映射中的地址。
②在 m_axi 接口中, 该选项会覆盖 config_interface -m_axi_offset 选项所指定的全局选项, 并且<string> 指定为:○ off: 不生成偏移端口。
○ direct: 生成标量输入偏移端口。
○ slave: 生成偏移端口并自动将其映射到 AXI4-Lite 从接口。这是默认偏移。
clock=<name>: (可选) 仅限针对接口模式 s_axilite 才会指定该选项。它可定义要用于该接口的时钟信号。默认情况下, AXI4-Lite 接口时钟与系统时钟为相同时钟。该选项用于为 AXI4-Lite (s_axilite) 接口指定独立时钟。
name=<string>: 指定将在生成的 RTL 中使用的端口的名称
latency=<value>: 当 mode 设为 m_axi 时, 该选项指定期望的 AXI4 接口的时延, 允许设计发起总线请求的时间比执行期望的读取或写入操作早数个周期(时延) 。如果该值太低, 设计将过早达成就绪状态, 可能停滞并等待总线; 如果该值太高, 则可能授予总线访问权时, 总线仍处于停滞状态并等待设计发起访问。
示例1:两个函数实参都是使用 AXI4-Stream 接口来实现的:
void example(int A[50], int B[50]) {
//Set the HLS native interface types
#pragma HLS INTERFACE mode=axis port=A
#pragma HLS INTERFACE mode=axis port=B
int i;
for(i = 0; i < 50; i++){
B[i] = A[i] + 5;
}
}示例2:闭块级 I/O 协议, 并分配至函数返回值:
#pragma HLS interface mode=ap_ctrl_none port=return指定函数实参 InData 以使用 ap_vld 接口, 并指示应寄存输入:
#pragma HLS interface mode=ap_vld register port=InData8.LATENCY(Functions, loops)
说明:指定最小时延值或最大时延值, 用于完成函数、循环和区域。
①Latency(时延) : 生成输出所需的时钟周期数。
②函数时延: 函数计算并返回所有输出值所需的时钟周期数。
③循环时延: 执行所有循环迭代的周期数。
Vitis HLS 始终尝试将设计中的时延最小化。指定 LATENCY 编译指示时, 工具行为如下所示:
• 当时延大于最小值时或者小于最大值时: 满足约束,不再执行进一步最优化。
• 当时延小于最小值时: 如果 HLS 工具可以实现小于最小指定值的时延, 那么它可将时延扩展至指定值, 这样可能增加共享。
• 当时延大于最大值时: 如果 HLS 工具无法调度到最大限值范围内, 那么它会尽力实现指定约束。如果仍无法满足最大时延, 则会发出警告, 并以超出最大限值前提下可实现的最小时延来生成设计。
HLS 通常会尝试在综合时实现最小延迟。如果使用此指令指定更大的最小延迟,HLS 将“pad out”函数或循环并减慢一切。这有助于资源共享(减少资源),并且对于创建延迟很有用。如果 HLS 无法达到要求的延迟,它将发出警告。
语法:在代码的函数、循环或区域的边界内必须对时延加以管理的位置处布局该编译指示。
#pragma HLS latency min=<int> max=<int>min=<int>: (可选) 指定代码的函数、循环或区域的最小时延。
max=<int>: (可选) 指定代码的函数、循环或区域的最大时延。
虽然最小值和最大值均描述为可选, 但必须至少指定二者之一。
示例1:指定 foo 函数采用最小时延值 4 和最大时延值 8。
int foo(char x, char a, char b, char c) {
#pragma HLS latency min=4 max=8
char y;
y = x*a+b+c;
return y
}示例2:loop_1 指定为采用最大时延 12。将编译指示置于循环主体内
void foo (num_samples, ...) {
int i;
...
loop_1: for(i=0;i< num_samples;i++) {
#pragma HLS latency max=12
...
result = a + b;
}
}9.LOOP_FLATTEN(loops)
说明:允许把嵌套循环平铺为已改善时延的单一循环层级。将嵌套循环展平为单个循环,应用于最里面的循环。如果成功,将生成更快的硬件代码。
在 RTL 实现中, 从外层循环移至内层循环需要一个时钟周期, 从内层循环移至外层循环同样如此。将嵌套循环平铺即可将其作为单一循环来加以最优化。这样可节省时钟周期, 从而进一步对循环主体逻辑进行最优化。
将 LOOP_FLATTEN 编译指示应用于循环层级的最内层循环的循环主体。仅限完美循环和半完美循环才能以此方式进行平铺:
①完美循环嵌套:
• 仅限最内层循环才包含循环主体内容。
• 在循环语句之间不指定任何逻辑。
• 所有循环边界均为常量。②半完美循环嵌套:
• 仅限最内层循环才包含循环主体内容。
• 在循环语句之间不指定任何逻辑。
• 最外层的循环边界可采用变量。③非完美循环嵌套:
当内层循环具有变量边界或者循环主体未完全包含在内层循环内时, 请尝试重构代码或者将循环主体中的循环展开以创建完美循环嵌套。
语法:将 C 语言源代码中的编译指示置于嵌套循环的边界内。
#pragma HLS loop_flatten off
off: 可选关键字。此关键字可防止发生循环平铺, 它可防止对某些循环进行平铺, 同时对指定位置的所有其它循环执行平铺。
示例1:将 foo 函数中的 loop_1 及循环层级中位于其上层的所有(完美或半完美) 循环平铺为单一循环,将编译指示置于loop_1 主体内。
void foo (num_samples, ...) {
int i;
...
loop_1: for(i=0;i< num_samples;i++) {
#pragma HLS loop_flatten
...
result = a + b;
}
}
10.LOOP_TRIPCOUNT(loops)
说明:将该编译指示手动应用于循环, 用于指定循环执行的迭代总数。如果循环具有可变的循环边界,HLS 将不知道它需要多少次迭代。这意味着它无法为设计延迟提供明确的值。这允许我们为设计指定循环的最小、平均和最大行程计数(迭代次数)。这只会影响报告,不会影响硬件代码生成。
Vitis HLS 工具会报告每个循环的总时延, 即执行循环的所有迭代的时钟周期数。因此, 循环时延即为循环迭代次数(或循环次数) 的函数。循环次数可为常量值。它取决于循环表达式(例如, x < y) 中使用的变量值或循环内使用的控制语句。在某些情况下, HLS 工具无法判定循环次数, 因此时延未知。
在此类情况下, 用于判定循环次数的变量可能是:
①输入实参
②采用动态运算计算所得的变量
如果循环时延未知或者无法计算, 那么 LOOP_TRIPCOUNT 编译指示会要求指定循环迭代次数的最小、最大和平均值。
语法:将 C 语言源代码中的编译指示置于循环的主体内。
#pragma HLS loop_tripcount min=<int> max=<int> avg=<int>• max= <int>: 指定循环迭代次数的最大值。
• min=<int>: 指定循环迭代次数的最小值。
• avg=<int>: 指定循环迭代次数的平均值。
示例:函数 foo 中的 loop_1 的最小循环次数指定为 12, 最大循环次数则为 16:
void foo (num_samples, ...) {
int i;
...
loop_1: for(i=0;i< num_samples;i++) {
#pragma HLS loop_tripcount min=12 max=16
...
result = a + b;
}
}















 2852
2852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











