







abstract
步态识别是一种很有前景的生物识别技术,旨在通过行走模式识别目标主体。大多数现有的基于外观的方法都专注于从步态轮廓中学习有区别的时空表示。然而,这些方法较少关注探索身份因素和身份标签之间的因果关系,这往往误导模型学习易受身份无关因素影响的步态表示。、
在本文中,我们将导致模型在不同外部条件下泛化能力下降的原因归因于与身份无关的因素。我们将身份因素、身份无关因素和身份标签之间的因果关系定义为结构因果模型 (SCM)。据此,我们提出了一种新的步态识别框架GaitSCM来学习协变量不变covariate invariant步态表示,该框架主要由特征提取模块、特征解纠缠模块和后门调整三个部分组成。具体来说,我们设计了一个关于不同身体部位运动模式的特征提取器来学习细粒度的步态运动特征,然后提出了一个双分支特征解耦模块,借助分类混淆损失来解开身份特征和身份无关的特征。为了减轻身份无关因素的负面影响,我们开发了一种后门调整策略来消除身份和身份无关特征之间的虚假关联,这进一步促进了所提出的框架生成更强大的身份表示。在两个公共数据集上进行的大量实验验证了我们的方法的有效性。在CASIA-B和OU-MVLP数据集上,平均Rank-1分别达到93.2%和90.4%,验证了GaitSCM的优越性
introduction
在过去的几十年中,步态识别因其在视频监控中的巨大应用潜力而引起了广泛的研究关注。与面部、指纹和虹膜等其他生物识别技术相比,步态信息可以在距离摄像头较远的地方捕获,而无需行人的配合。尽管基于卷积神经网络(cnn)的步态识别方法已经取得了很大的进步,但仍然存在许多由各种外部条件引起的挑战,例如观察点viewing points,服装和携带条件。这些外在因素对人体的轮廓有很大的影响。如图1所示,步态轮廓随着外界因素的变化变化很大,尤其是在不同视点下。最近,随着深度学习的蓬勃发展,许多基于CNN的方法被提出来处理这个问题。部分作品采用视点转换模型来抑制因观看变化引起的主体内差异,同时放大主体间差异。而不是在隐式和中逐步执行视图转换数据空间,多任务生成对抗网络 (MGAN) 假设视图变化的步态图像位于低维流形上。沿着这个流形移动的步态样本可以在保持其身份的同时实现不同视角之间的转换。基于这一假设,MGAN 通过对抗训练从周期能量图像 (PEI) 中提取判别步态特征。提出了一种两两空间变压器网络(PSTN) 来减少由视图差异引起的不良特征错位,该网络由两两空间变压器(PST)和随后的识别网络(RN)组成。PSTN 将不同视图的成对输入转换为它们的中间视图,用于处理大失真。然后,将转换后的匹配对输入 RN 以计算相异分数。与上述方法相比,已经开发了一些判别表示学习框架来从各种外部条件下的轮廓中提取步态特征表示。GaitSet 将步态视为无序集,同时学习空间和时间信息,拉格朗日量利用拉格朗日方程分析了人类行走过程,意识到时间维度的二阶信息对于步态识别是必要的。它相应地设计了一个二阶运动提取器,从高级特征图和视图嵌入模块中提取步态特征,以缩小视点变化引起的差异。GaitAMR (gait 聚合多特征表示) 提出了一种多尺度特征提取器 (MSFE) 来提取多尺度时空特征,其三个方面包括帧级、短程和长程特征。随后,采用自适应时间聚合建模聚合多尺度时空特征,选取最优视图特征作为补充信息,提高视图的稳定性。将时空特征和视图特征融合进行步态识别。OpenGait 构建了一个可扩展的步态识别框架,并提出了一个强大的基线模型 GaitBase,该模型采用了类似 ResNet 的 2D 卷积主干。
这些工作中的大多数都致力于学习身份类和步态特征之间的稳健映射,这些特征对身份无关因素是不变的。然而,这些方法很少对身份特征与干扰因素之间的关系进行建模,这往往使学习到的特征对外部变化敏感。
为了解决这个问题,一些工作基于解纠缠表示学习(DRL)试图消除身份无关特征对识别的负面影响。提出了一种基于自动编码器的GaitNet (Zhang et al., 2020b),将姿态和视觉外观特征与RGB帧解耦。交叉重建损失用于重建视频帧,目的是从外观特征中去除姿势变化。此外,步态相似性损失旨在通过减少同一被试在不同条件下的姿态差异,将外观信息与姿态特征分离。虽然这两种损失可以在一定程度上帮助缓解外观特征的影响,但输入RGB图像不可避免地会引入冗余颜色和纹理信息。为了克服这一问题,提出了一种基于身份和协变量特征的解纠缠网络(ICDNet) (Li et al., 2020),将身份特征从协变量特征中分离出来,基于编码器-解码器框架执行两个重构任务。一种是从身份和协变量特征重构输入GEI,另一种是在没有来自身份特征和零填充特征向量的协变量的情况下恢复输入GEI。虽然GEI随时间编码平均轮廓,没有考虑不必要的颜色和纹理信息,但它不能有效地描述人体运动的动态过程。此外,大多数基于DRL的步态识别方法只以蛮力的方式解耦恒等因子和协变量,没有探索不同变量之间的内在相关性。因此,这些方法无法合理分析身份因素如何确定身份标签以及外部条件如何影响识别,我们的工作的主要目标不仅是为了获得更好的识别性能,而且是对干扰因素如何从因果的角度影响网络模型。为此,我们将因果分析引入到步态识别中,并采用结构因果模型(SCM) (Pearl et al., 2000)来描述身份因素、协变量(即摄像机观看点、服装和携带条件)和身份标签之间的相关性。理想的步态识别模型应该能够捕获身份特征和标签之间的真实因果关系。不幸的是,传统的相关性 往往无法做到这一点,因为与身份无关的因素对确定身份标签有影响,并导致身份和身份无关的因素之间的虚假相关性。因此,为了获得身份特征和标签之间的真实因果关系,我们采用因果干预 来替换似然。我们使用后门调整策略来计算 푡 , 这是一个有用的工具来处理混杂因素,而不需要理想的数据集。
基于上述考虑,我们开发了一种新的步态识别框架GaitSCM,该框架由特征提取模块和配备因果干预的特征解纠缠模块组成。特征提取器中的全局和局部特征学习策略利用人体运动上不同身体部位运动模式的先验知识,旨在挖掘细粒度的步态信息。在特征提取模块之后,我们设计了一种新的双分支特征解耦模块,并伴随着分类混淆损失来解开身份和身份无关的特征。为了进一步增强身份特征的代表性能力,我们采用因果推理来消除身份因素与身份无关因素之间的虚假相关性,其中提出了一种后门调整策略来近似介入分布,并追求身份特定因素和身份标签之间的真实因果关系标签。主要贡献总结如下:
• 我们是一个将因果分析引入步态识别以提高身份表示的鲁棒性的人。我们采用SCM来描述外部干扰因素、身份因素和标签之第间的因果关系,揭示了身份与身份无关因素之间的虚假关系,对模型泛化产生负面影响。
•我们提出了一种新的因果表示学习框架GaitSCM来校准虚假关系。设计了一种考虑行为特征先验知识的特征提取器来提取全局和局部步态特征。然后,通过特征解耦模块分离身份和身份无关因素,协变量的影响被因果干预所推动
•我们在两个广泛使用的公共数据集上进行了广泛的实验。对比实验和消融研究的结果表明了所提出框架的优越性和有效性。
2.相关工作
现有的步态识别方法大致可以分为两类,包括基于模型和基于外观的方法。在本节中,我们首先讨论现有的步态识别方法。然后,我们介绍了一些具有代表性的工作,将因果推理应用于许多计算机视觉相关任务。步态识别基于模型的方法试图基于姿态信息建立不同身体部位的二维/3D人体结构和模型行走模式,然后捕获静态和动态步态信息进行个体识别。早期的方法 可以大致分为,在这一类别中,这些方法通常使用一些简化的物理模型,如动态摆模型和棒模型,来描述行走模式并分析运动参数。最近,许多基于模型的方法随着人体姿态估计的进展,越来越多的研究关注。PoseGait 直接利用人体姿态作为步态特征,设计了一些基于三维姿态估计的手工特征,如骨骼长度、关节角度和关节运动。提出了一种多分支ResGCN网络(Teepe et al., 2022),该网络由图卷积网络(GCNs)和残差网络组成,从关节、骨骼和运动三个分支捕获步态特征。这些方法不易受到许多变化的影响,例如相机观察点和服装条件。然而,基于模型的方法在很大程度上依赖于人体姿态估计的质量,需要更多的计算。
2.1. Gait recognition
基于模型的方法不同,基于外观的方法 直接从步态图像中学习特征表示,不需要显式建模身体骨架。由于 CNN 强大的特征表示能力,基于外观的方法取得了巨大的突破,成为主流。基于外观的方法有两个主要行。基于模板的方法从步态序列中提取轮廓特征,并将获得的特征序列压缩为步态模板。步态能量图像 (GEI) (Han and Bhanu, 2005) 被提出来描述显着的形状变化并表征行走模式。然而,特征模板的融合过程可能会导致时间信息的损失。为了捕捉更多的运动信息,一些作品直接从轮廓序列而不是步态模板中学习步态表示
为了解决现实世界场景中外部变化带来的挑战,GaitPart (Fan et al., 2020) 设计了一个微动作捕捉模块 (MCM),通过捕获局部微运动和序列级变化来产生有区别的步态特征。此外,焦点卷积(FConv)用于将人体分成几个部分并利用细粒度的空间信息,但它只关注详细的局部信息而忽略了局部区域之间的关系。为了克服这个问题,GaitGL (Lin et al., 2021) 扩展了分区思想,并提出了一个全局和局部特征提取器 (GLFE) 来整合不同级别的特征。
然而,这些现有方法存在两个常见问题。首先,它们通常将人体分成几个统一的部分,而忽略了不同的身体部位对行人运动模式的贡献不相等的事实。其次,他们没有明确地从时空步态表示中去除与身份无关的特征,导致学习到的步态特征容易受到外部干扰因素的影响。因此,我们设计了一种不等分区策略,基于身体结构的先验知识(即上半部分、中间部分和下半部分)来关注各个部分的不同运动模式。为了合理分析和探索身份无关因素对步态识别的影响,我们设计了一种特征解耦网络和因果干预策略来分离干扰因素,降低它们对识别性能的影响,
2.2. 计算机视觉因果推理
是一种统计工具,它可以使学习模型能够发现隐藏的因果联系。它已成功应用于心理学、经济学和社会学。近年来,研究人员试图将因果推理引入机器学习和计算机视觉领域。因果推理和机器学习的结合已经在几个上下文中进行了研究,包括小样本学习、对抗性学习和强化学习。此外,一些作品将因果推理应用于一些计算机视觉任务,例如语义分割、人员重新识别 (Re-ID) (Zhang et al., 2022)、视觉基础 、视觉情感识别 (Chen et al., 2022a) 和长尾分类 (LT) 为传统的 CV 任务提供了新的视角,并取得了有希望的结果。受因果关系在提高模型泛化方面的能力的启发,在这里我们探讨了因果关系在步态识别中的应用,以抵抗不同观看点、服装和携带条件的副作用。
3.1. 用于步态识别的SCM
我们用SCM展示了身份因素、身份无关因素和身份标签之间的因果关系。如图2所示,节点x和c分别表示特定于身份的因素和与身份无关的因素。并且 y 表示身份标签。箭头表示直接的因果影响。所提出的用于步态识别因果关系的SCM如图2所示。SCM背后的基本原理如下:
𝑪→𝑿,𝑪→𝒀。在本文中,外部因素,如服装,相机视点和携带条件,被认为是混杂因素。箭头𝐶→𝑋表示身体轮廓受到外部因素的影响,这是一种虚假相关性。其原因是人体的骨架结构和行走姿势不随视角的变化而变化。此外,服装和携带状态对行走姿势影响不大。箭头𝐶→𝑌表示混杂因素对识别结果的影响。如图2所示,同一受试者在不同条件下的轮廓图像差异较大。因此,直接从轮廓中学习的步态表示既包含身份特征又包含协变量信息,这可能会破坏模型的泛化性。
𝑿→𝒀。身份因素𝑋直接决定了身份标签𝑌,这表明特定的体型和行走方式是识别主体的关键。
3.2. 后门调整
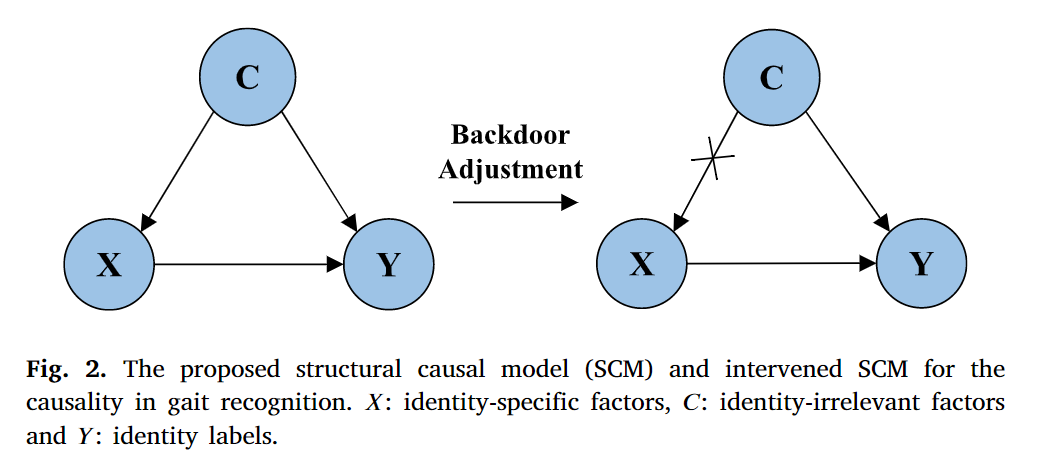
以前大多数基于外观的方法都建立了关系relationship(𝑌|𝑋),如图2(左)所示。这些模型不能建立𝑋和𝑌之间的因果关系causality,因为因果关系(𝑋→𝑌)和假相关(𝑋→𝑌)都会影响似然值(𝑌|𝑋)。去追求对于身份因素与身份标签之间的因果关系,我们用因果干预变量(𝑌|𝑑𝑜(𝑋))替代了(𝑌|𝑋),以消除假相关系数𝐶→𝑋,如图2(右)所示。具体来说,我们首先将其分成几部分,分别为:𝐶 = {𝑐1, 𝑐2, … , 𝑐|𝐶|},,其中|𝐶|表示混杂因素的类数。每个𝑐𝑗都是一个混杂因素,分别对应于观看点、服装、携带条件。然后,我们可以应用后门调整(Glymour et al., 2016)来近似取值(𝑌|𝑑𝑜(𝑋))。实现定义如下:
𝑃 (𝑌 |𝑑𝑜(𝑋 = 𝑥𝑖)) =∑𝑃 (𝑌 |𝑋 = 𝑥𝑖, 𝐶 = 𝑐𝑗 )𝑃 (𝐶 = 𝑐𝑗 )
3.3. The GaitSCM framework
在本节中,我们提出了一种新的步态识别框架GaitSCM来实现步态识别的因果干预,该框架主要由三个关键部分组成,包括特征提取模块、特征解缠模块、后门调整模块。GaitSCM的概述如图3所示
3.3.1. Feature extraction module
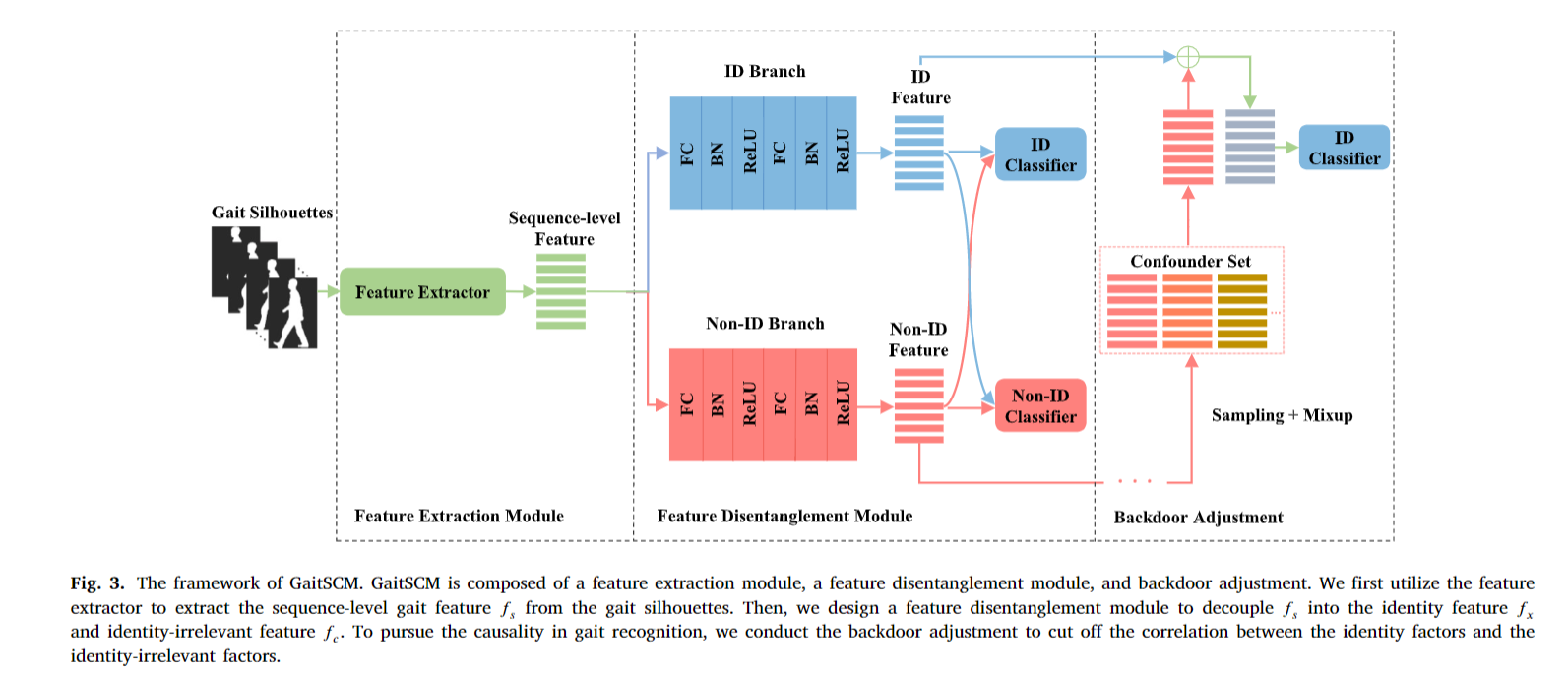
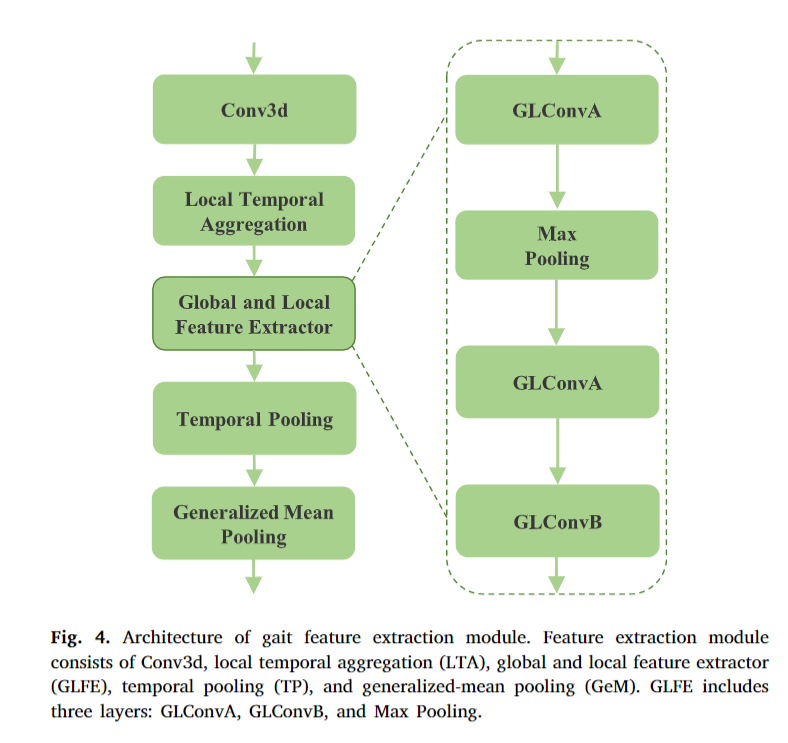
我们设计了GaitGL (Lin et al., 2021)的改进变体作为本文的特征提取模块。如图3所示,将输入的步态数据输入到特征提取器中,得到序列级步态特征表示。图4显示了特征提取器和全局和局部特征提取器(GLFE)的结构。与GaitGL相比,我们在GLFE中设计了一种新的特征映射划分策略。如图5所示,GaitGL认为人体各部位对步态识别的贡献是相等的,因此将全局特征划分为多个统一维数的局部特征。如图6所示,我们首先根据身体结构将身体分为上、中、下三个部分,因为我们认为不同的身体部位在行走过程中具有不同的运动模式。上肢以头部为主要组成部分,具有整体运动模式,关节较少,不同于肢体灵活复杂的运动。在上半部分,主体之间的差异主要体现在整体层面上的形体和动作变化。相比之下,中下部分包含更多的关节,体现了更多的运动信息,并主导了行人的整体行走模式。基于这一观察,我们认为在中下部进行更详细的分割有利于描绘每个主体的运动特征。此外,如图6所示,我们对中下部进行了两种不同的不均匀细粒度分区,目的是将关节分配到不同的部位,以发现它们对行走模式的综合影响。同时,我们将头部区域视为一个整体。我们相应地为GLConvA和GLConvB设计了不同的实现。在细粒度体分割的基础上,对不同尺度的特征图采用独立的三维卷积。
具体来说,给定一个步态轮廓序列,我们用𝐷={𝑑1,𝑑2,…,𝑑𝑇1}∈R𝐶1×𝑇1×𝐻1×𝑊1,𝑇1步态序列的长度和𝑑𝑡∈R𝐶1×𝐻1×𝑊1。𝐻1和𝑊1是输入图像的高度和宽度。𝐶1是图像通道的数量。首先,将输入的步态序列𝐷送入三维卷积层并进行局部时间聚合(LTA)压缩时间信息;我们将LTA的输出用𝑓𝐿𝑇()表示。这个过程可以描述为:
![![[Pasted image 20240522205152.png]]](https://i-blog.csdnimg.cn/blog_migrate/7d22b93cd37b1fae50662f0db4083c4b.png)
式中𝑓𝐿𝑇变量∈R𝐶2 ×𝑇2 ×𝐻1 ×𝑊1。其中,1×1×1 3×3×3为三维卷积。这个3D卷积的核大小和步幅分别设置为3和1。类似地,我们使用了<s:1> 3×1×1 3×3×3来表示LTA模块。其次,利用GLFE模块提取细粒度运动信息;考虑到不同身体部位的不同运动模式,我们设计了两个不均匀的分区,将输入特征沿高度维度分割为多个局部特征,目的是学习头部、手臂和腿部的运动表征。然后,我们可以得到两组局部特征,并使用元素加法对它们进行整合。
通过元素级加法和级联运算,将全局和局部特征融合分为GLConvA和GLConvB。

3.3.2. Feature disentanglement module
提出了一种基于序列级步态表示的双分支特征解耦模块,用于解耦识别因素和混杂因素。如图3所示,序列级特征𝑓𝑠分别由ID和Non-ID分支映射到两个判别子空间中,提取身份特定因子𝑓≥和身份无关因子𝑓𝑐。每个分支由FC (fully connected layers)、BN (batch normalization)和ReLU组成。这个过程可以表示为:
![![[Pasted image 20240522210103.png]]](https://i-blog.csdnimg.cn/blog_migrate/d91cdf2ee2ed72d24fafba5d3bd3da86.png)
此外,利用交叉熵损失和三重态损失来增强特征识别。我们设计了一个分类混淆损失来促进身份特征和身份无关特征之间的分离。具体来说,我们利用身份交叉熵损失𝐿来激励身份分支学习特定于身份的特征,可以定义为:(8)
![![[Pasted image 20240522210151.png]]](https://i-blog.csdnimg.cn/blog_migrate/55dabb996b9b635a5e12036aa010577f.png)
式中,𝑀为身份标签的个数,其中,𝑑𝑦𝑖𝑑样本的one-hot身份标签。表示. 𝑝𝑖𝑑 𝑖预测分类概率。𝑝𝑖𝑑𝑖通过(9)计算
𝐶𝐼𝐷表明身份标识符。
协变量可以根据行走条件和摄像机视点的组合进行分类,即NM-0◦、BG-72◦和CL-108◦。我们表示与身份无关的交叉熵损失𝐿𝑛𝑜𝑛−𝑑𝑐𝑒,以鼓励与身份无关的分支学习协变量特定的特征。我们有𝐿𝑐𝑒=𝐿𝑖𝑑𝑐𝑒+𝐿𝑛𝑜𝑛−𝑖𝑑𝑐𝑒。然后,我们采用三重损失(Hermans et al., 2017)来提高身份的辨别能力。
给定一个三元组组(𝑓𝑥𝑎,𝑓𝑥𝑞,𝑓𝑥𝑝),在𝑓𝑥𝑎和𝑓𝑥𝑞属于同一人和𝑓𝑥𝑎和𝑓𝑥𝑝属于不同的人,我们假设有𝐾个三元组身份特征{𝑇𝑘|𝑇𝑘=(𝑓𝑘𝑥𝑎,𝑓𝑘𝑥𝑞,𝑓𝑘𝑥𝑝),𝑘= 1,2,…,𝐾}。身份三元组损失可定义为:(10)
![![[Pasted image 20240522210244.png]]](https://i-blog.csdnimg.cn/blog_migrate/66fa01e112077070482fed915397608a.png)
我们还可以为协变量特征定义与身份无关的三元组损失𝐿𝑛𝑜𝑛−𝑖𝑑𝑡𝑟𝑖,然后我们有𝐿𝑡𝑟𝑖=𝐿𝑖𝑑𝑡𝑟𝑖+𝐿𝑛𝑜𝑛−𝑖𝑑𝑡𝑟𝑖。此外,为了从同一性特征中排除协变量信息,我们提出了基于最大熵的分类混淆损失𝐿i𝑑𝑐𝑜𝑛𝑓。从直观上看,特征中涉及的协变量信息越少,特征对协变量的正确识别就越困难。当用于身份无关分类的步态特征对各协变量类的识别概率一致时,表明步态特征中几乎不存在协变量信息。因此,我们可以将𝐿-𝑑𝑐𝑜𝑛𝑓定义为(11)。。。。。
3.3.3 Backdoor adjustment module
对于给定的N个序列样本,我们首先将它们映射成恒等特征和协变量特征。{𝑥𝑖}𝑁𝑖= 1,{𝑐𝑗}𝑁𝑗= 1。接下来,我们提出了后门调整的实施,以减少混淆效应。我们的调整基于以下两个假设:



















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









