







目录
3.1、设置官方配置文件:default.yaml,可自行修改。
0、引言
本文是使用YOLOv11训练自己的数据集,数据集包含COCO数据集的人猫狗数据以及自己制作的人猫狗数据集,类别为0:person、1:cat、2:dog三类,大家可根据自己的数据集类别进行调整。
1、开源代码、模型下载
代码链接:https://github.com/ultralytics/ultralytics
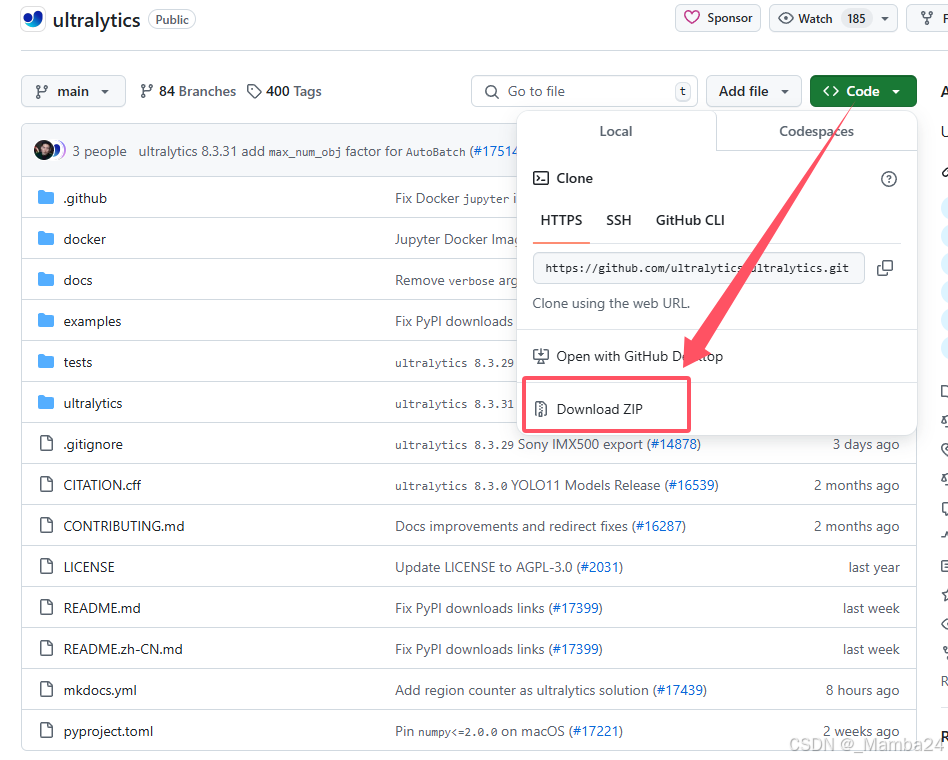
模型下载:
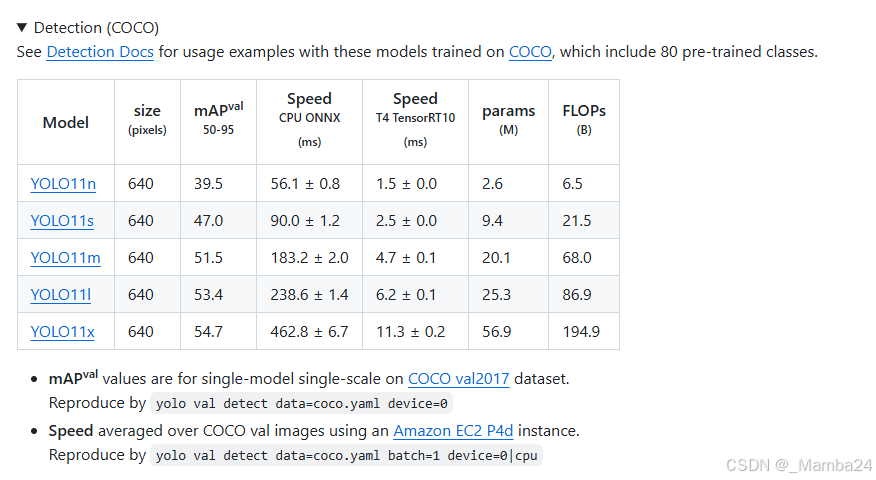
如果下载速度慢:https://download.csdn.net/download/qq_54134410/89921882?spm=1001.2014.3001.5501
2、环境配置
可参考这篇博客:深度学习环境搭建-CSDN博客
打开Anaconda3终端,进入base环境,创建新环境,我这里创建的是p10t12(python3.10,pytorch1.12)
conda create --name p10t12 python==3.10进入到创建的环境
conda activate p10t12安装pytorch:(网络环境比较差时,耗时会比较长)
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116 -i https://pypi.tuna.tsinghua.edu.cn/simple/将下载的代码解压使用pycharm打开,环境选择创建的p10t12。
安装ultralytics、ultralytics集成了yolo的各种包以及模型等,程序中直接调用
pip install ultralytics3、数据集准备
YOLOv11的训练数据集格式与YOLOv8相同
mydata
______images
____________train
_________________001.jpg
____________val
_________________002.jpg
______labels
____________train
_________________001.txt
____________val
_________________002.txt 参照这篇博客的数据集准备即可(根据自己数据集的实际情况来):
YOLOv8-Detect训练CoCo数据集+自己的数据集_yolov8训练coco-CSDN博客
3、设置配置文件
3.1、设置官方配置文件:default.yaml,可自行修改。
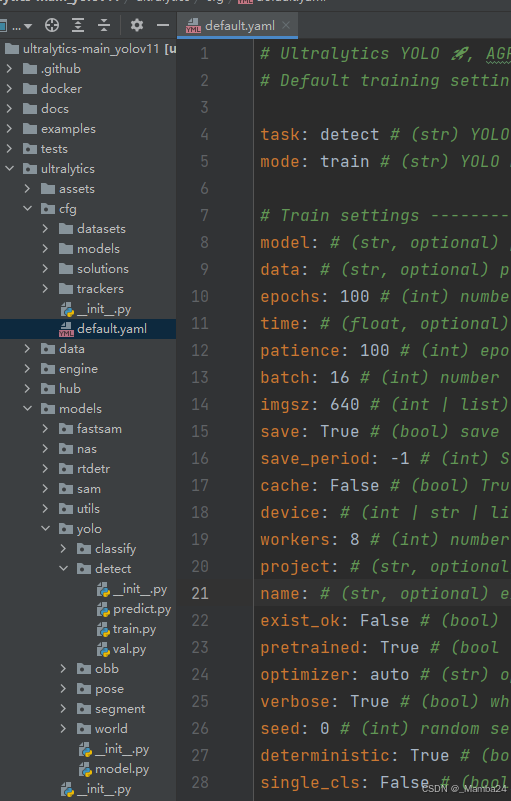
3.2、设置data.yaml
根据自己的数据集位置进行修改和配置。
path: D:\Yolov8\ultralytics-main\datasets\mydata # dataset root dir
train: images/train # train images (relative to 'path') 118287 images
val: images/val # val images (relative to 'path') 5000 images
#test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: person
1: cat
2: dog
nc: 34、进行训练
上述步骤完成后,即可开始训练(我这里采用的是预训练模型yolov11s.pt)。
from ultralytics import YOLO
if __name__ == '__main__':
modelpath = r'D:\Yolov11\ultralytics-main_Yolov11\yolov11-detect\yolo11s.pt'
model = YOLO(modelpath) # load a pretrained model (recommended for training)
name = 'yolov11s_train'
# Train the model
model.train(data='data.yaml', epochs=1000, name=name)训练过程:
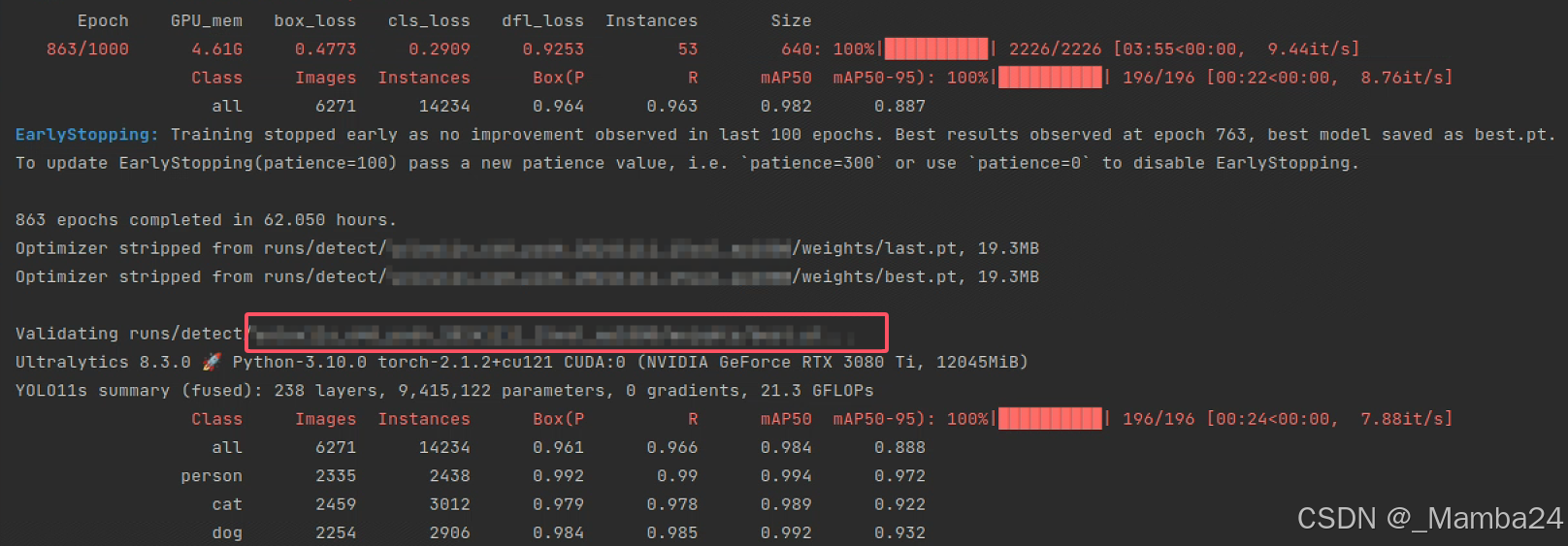
训练完成最后得到两个模型分别是:best.pt、last.pt
5、验证模型
训练进程完毕以后可使用一些验证数据进行模型验证,查看模型的识别效果。
from ultralytics import YOLO
import glob
import os
# Load a model
model = YOLO(r'G:\Yolov11\ultralytics-main_Yolov11\yolov11-detect\yolo11s.pt') # load an official model
# Predict with the model
imgpath = r'G:\Val_set'
imgs = glob.glob(os.path.join(imgpath,'*.jpg'))
for img in imgs:
model.predict(img, save=True)
6、总结
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。
欢迎各位批评指正。



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











