







摘要:

在AD(无人驾驶)和IVs(智能汽车) 已经有了很多研究,但是仍需要一个全面的、前瞻性的总结,然后写了三篇文章来做这个工作,本文是第三篇,主要是智能汽车的预测和规划方面的研究。
一、介绍
以往大多数综述只关注于具体任务,缺乏系统性的总结和对未来研究方向的预测。 本文将自动驾驶分为8个部分:感知、规划、控制、系统设计、通信、高清地图、测试和人类行为,如图一。

本文介绍感知规划控制之间的关系:

本文三个贡献:
1)我们提供了一个更系统、全面和新颖的关键技术发展调查。
2)我们在每个技术部分中介绍了许多部署细节、测试方法和独特的见解。
3)我们对AD和IVs进行了系统的研究,试图成为过去和未来之间的桥梁,本文是我们整个研究的第三部分(第二部分为调查)。
二、感知
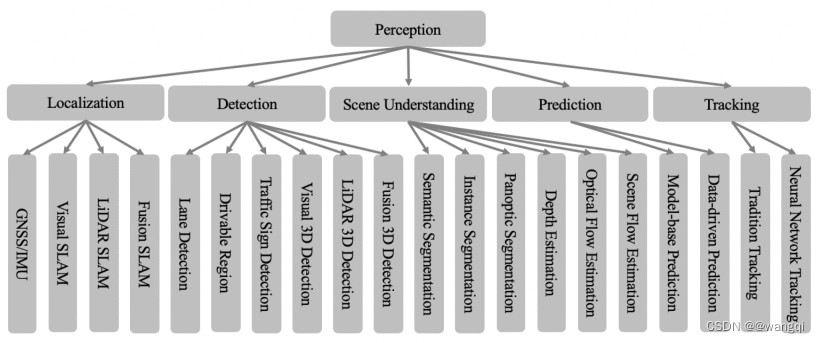
感知分为定位、目标检测、场景理解、目标预测和跟踪,如上图。
1、Localization定位
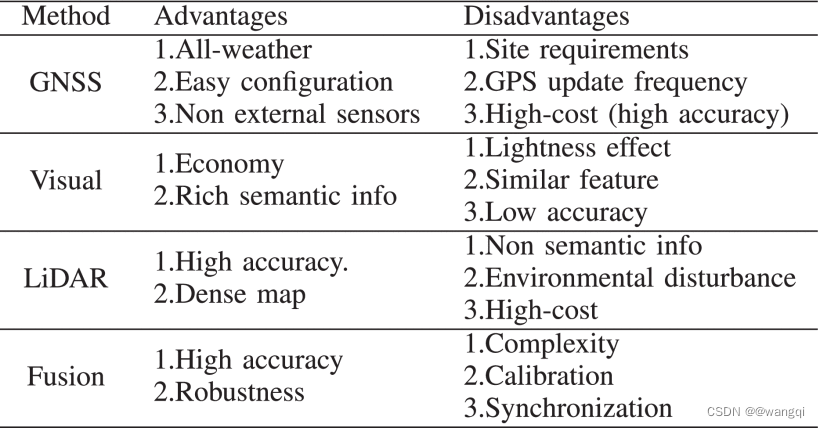
定位是驾驶平台获取自车位置和姿态的技术,是规划和控制的前提。当前定位测略分为四种:1、全球卫星导航系统(GNSS)和惯性测量单元(IMU);2、视觉SLAM( simultaneously localization and mapping,同步定位与地图构建);3、激光SLAM;4、融合SLAM。
(1)GNSS和IMU:GNSS提供三维坐标,速度及时间信息,通过GNSS对低频定位信息进行更新,IMU对动态状态更新,平台可以获得高更新频率的定位信息,虽然GNSS和IMU的融合是全天候的,但是卫星信号会受到城市建筑的干扰。
(2)视觉SLAM:采用摄像机帧的变化来估计自车运动,这类算法按传感器分为三类:1)单目相机;2)多目相机;3)深度相机。具体来说,视觉SLAM算法只需要图像作为输入,这意味着定位系统的成本相对便宜。然而,它们依赖于丰富的特征和轻微的光照变化。此外,优化是视觉定位系统的关键模块,它在考虑全局信息后更新每帧估计,优化方法包括基于滤波器和基于图的方法。
就特征提取讲,视觉SLAM有两种方法:关键点法和光流法。这里就不展开了。
(3)激光SLAM:激光雷达主动探测周围环境,提供三维信息。与视觉SLAM相似,也可以分为二2-D,如Gmapping, Cartographer, Karto;3-D,by sensors or filter-based like Gmapping and optimization-based by the process of optimization.激光SLAM系统具有精度高、地图密集(a dense map)、对光照依赖性弱等优点。然而,没有语义信息和环境干扰是激光SLAM系统面临的两个主要挑战。此外,研究人员必须花费大量时间和精力来维护和维修安装在 IV 上的 LiDAR。
(4)融合SLAM:为了避免但传感器失效和鲁棒性低的问题,研究人员引入了多模态数据融合方法,比如视觉+IMU,激光雷达+IMU,视觉+激光雷达+IMU等等,融合将更新频率更高的IMU数据引入SLAM系统。又分为松融合和紧融合,松融合将来自相机或者雷达的外部数据与来自IMU的内部数据视为两个独立的模块,紧融合设计了单元优化模块来处理融合的数据。融合SLAM解决了单传感器面临的问题,但还是遇到一些问题:校准、同步、复杂处理。
2、Object Detection 目标检测
检测传感器视野中的静态和动态目标。
(1)车道检测
识别车道,辅助驾驶。三个过程:图像处理->车道检测->跟踪。图像预处理的目的是降低计算成本并消除噪声,车道检测和跟踪的方法分为基于计算机视觉和基于学习的方法。
基于CV的方法成本低,易于复制,利用top-hat变换来消除不相关对象,然后利用Hough变换提取边缘像素构建直线。缺点:难以识别曲线。
基于学习的方法可以部署在更多场景,但是需要大量的数据来训练网络。
(2)驾驶区域检测
与车道检测相比,驾驶区域检测增加了障碍物信息,为避障功能和路径规划任务提供了基础信息。也分为基于计算机视觉的方法和基于学习的方法。
当路面不被障碍物遮挡时,可以将驾驶区域检测转换为车道检测。反之,它可以看作是车道检测和二维目标检测的结合。当将驾驶区域检测作为一项独立的任务时,需要将道路像素与目标和非驾驶区域区分开来。
基于学习的驾驶区域检测方法类似于图像分割。对于机器学习算法,可以通过特征提取器和分类header(如支持向量机(SVM)、条件随机场(CRF))来提取RGB颜色、Walsh Hadamard、方向梯度直方图(hog)、局部二值模式(LBP)、Haar、LUV通道等特征,从而获得最终结果。深度神经网络可以取代特征提取器并进行一些改进,如采用大视觉区域卷积核,多层连接,以获得具有竞争力的性能。我们发现,基于学习的驾驶区域检测结果通常是场景理解任务的一个分支,研究人员试图解决一些挑战,包括2D-3D转换,复杂的驾驶区域等。
(3)交通标志检测
交通标志包含大量重要的交通信息,如道路状况、速度限制、驾驶行为限制和其他信息。我们还将其分为基于CV的方法和基于学习的方法。
(4)基于视觉的3D目标检测
分为单目3D检测和立体检测。
(5)基于激光雷达的3D目标检测
从激光雷达捕获的点云数据中识别目标 3D 属性。我们将其分为Voxel-wise 目标检测和点检测。
(6)基于融合的3D目标检测
激光雷达、雷达和摄像头广泛部署在IVs中,用于感知任务,这些类型的传感器的组合可以使车辆坚固耐用,能够全时探测目标。然而,这并不意味着基于聚变的方法将优于使用单个传感器的方法。基于融合的方法的缺点有两个主要原因:1)网络难以填补各种传感器的模态差距;2)系统误差和测量误差(例如来自校准和同步)难以消除,并且会在网络中传播和放大。然后下面给出了一些解决这些问题的研究。
3、Scene Understanding场景理解
在本文中,我们将场景理解定义为每个像素或点的多个输出,而不是每个目标。
(1)分割segmentation
语义分割的目标是将场景划分为几个有意义的部分,通常是通过用语义标记图像中的每个像素(语义分割),同时检测对象并将每个像素与每个对象区分开来(实例分割),或者通过结合语义和实例分割(全景分割)。
(2)深度估计depth estimation
这种类型的任务是在相机平面上呈现深度信息,这是增强基于视觉的 3D 物体检测的有效方法,也是连接 LiDAR 和相机的潜在桥梁。深度估计是测量每个像素相对于相机的距离的任务。深度值是从单目或立体图像中提取的,具有监督(通过深度完成获得的密集地图)、无监督、LiDAR制导或立体计算。
(3)流量估计flow estimation
与分割和深度估计任务类似,流量估计侧重于图像平面,并呈现数据帧期间的像素移动。
4、预测
预测其他车辆或行人的行为方式。
(1)基于模型的方法
这些方法预测智能体的行为,例如变道、左转等。预测车辆行为概率分布的最简单方法之一是自主多模型 (AMM) 算法。该算法计算每个智能体的最大概率轨迹。
(2)数据驱动的方法
由神经网络组成,在感知数据集上训练后,模型对下一个行为进行预测。预测模块有时与感知分离,主要是因为下游规划模块同时接收感知和预测结果。未来的预测研究将集中在广义规则的制定、场景的普遍性和模块的简单性上。
5、跟踪
跟踪问题始于一系列车载传感器数据。根据神经网络是否嵌入到跟踪框架中,我们将它们分为传统方法和神经网络方法。
(1)传统方法
由于计算成本低,基于卡尔曼的方法即使在简单场景中的低规格硬件上也具有快速的响应时间。跟踪问题也可以显示为图搜索问题。与基于卡尔曼的方法相比,基于图的方法最重要的优点是它更适合多跟踪问题。
(2)神经网络方法
神经网络的优势在于,在给定相关且数量充足的训练数据的情况下,能够学习重要且强大的特征。CNN,RNN
三、规划
为自车找到局部跟踪规划。

分为全局路线规划、局部行为规划、局部轨迹规划。全局路线规划提供从起点到终点的道路级路径,局部行为规划决定接下来几秒钟的驾驶动作类型(比如:车辆跟随,避开障碍物绕行,让行,超车),局部轨迹规划根据行为决策生成一个轨迹。
1、全局路径规划
全局路径规划负责在路网中找到最佳的道路水平路径,路网以包含数百万条边和节点的有向图的形式呈现。路径规划器在有向图中搜索连接起始节点和目的节点的最小代价序列。在这里,成本是根据查询时间、预处理复杂性、内存占用或考虑的解决方案鲁棒性来定义的。
2、局部行为/轨迹规划
局部行为规划和局部轨迹规划功能协同工作,沿已识别的全局路线输出局部轨迹。分两种,一种是端到端方式,即开发一个集成系统,接收来自车载传感器的原始数据,并直接输出本地轨迹。另一种方法是顺序实现局部行为规划和局部轨迹规划功能。
(1)端到端
端到端解决方案名义上可以更有效地处理车辆与环境的交互,因为感知和规划模块之间没有外部差距。端到端系统的输入是车载传感器获得的大量原始数据,而输出是局部轨迹。由于输入和输出之间的关系过于复杂,无法总结为完整的规则,因此通常使用机器学习方法,其中大多数分为基于模仿学习和基于强化学习的方法。基于模仿学习的方法是基于训练样本构建神经网络,挑战在于如何收集大量一致的训练样本,以及如何保证学习效率(例如,避免过度拟合)。基于强化学习的方法通过试错操作获得知识,因此较少依赖外部训练样本的质量和数量。
端到端方法仍然不成熟,因此大多数方法都是在模拟中训练/测试的,而不是在现实世界的场景中。最近的研究主要集中在如何提高学习的可解释性、安全性和效率。
(2)顺序规划
与前面提到的端到端解决方案相反,在过去十年中,依次应用局部行为规划和轨迹规划功能是一种常见的传统选择。然而,局部行为规划和轨迹规划之间的界限相当模糊,例如,一些行为规划者所做的不仅仅是识别行为类型。为便于理解,本文不严格区分这两种功能,将相关方法简单地视为轨迹规划方法。
名义上讲,轨迹规划是通过求解一个最有控制问题(OCP)得到,满足各种约束条件,最小化目标函数,求解。
(a)状态网格识别
可以通过搜索、选择、优化、potential minimization的方法实现。搜索:A*、DP,选择:贪心选择,MDP,优化:将OCP离散为一个数学问题,求解进一步可以分为基于梯度和基于非梯度,基于梯度的求解器常用来求解NLP,QP,二次约束的QP,MIP,非梯度的代表是启发式解法(metaheuristics),potential minimization:EB,人工势场法,力平衡模型。
(b)基元生成(Primitive generation)
原始生成通常通过闭式规则、仿真、插值和优化来完成。闭式规则包括Dubins/ReedsShepp曲线、多项式和理论最优控制方法。基于仿真的方法通过前向仿真生成轨迹/路径基元,由于没有DOF,因此运行速度很快[188]。基于插值的方法由样条或参数化多项式表示。基于优化的方法以数值方式求解OCP,以连接两个状态网格。
PVD(路径速度解耦),将3D问题转化为2D问题,加快求解。非PVD的方法,直接求解轨迹,具有提高求解最优性的潜在优点。该研究领域的最新研究包括如何开发适合特定场景/任务的特定规划器,以及如何在不完善的上游/下游模块下规划安全轨迹。















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









