









官方链接:https://github.com/Genesis-Embodied-AI/Genesis
使用的系统:Ubuntu 20.04 [ Linux系统 ]
相关复现链接:Genesis 仿真初体验 [ 基于Linux系统Ubuntu20.04 ]_ubuntu安装genesis-CSDN博客
go2_train.py代码的解读:
import argparse
import os
import pickle
import shutil
from go2_env import Go2Env
from rsl_rl.runners import OnPolicyRunner
import genesis as gs
def get_train_cfg(exp_name, max_iterations):
train_cfg_dict = {
"algorithm": {
"clip_param": 0.2,
"desired_kl": 0.01,
"entropy_coef": 0.01,
"gamma": 0.99,
"lam": 0.95,
"learning_rate": 0.001,
"max_grad_norm": 1.0,
"num_learning_epochs": 5,
"num_mini_batches": 4,
"schedule": "adaptive",
"use_clipped_value_loss": True,
"value_loss_coef": 1.0,
},
"init_member_classes": {},
"policy": {
"activation": "elu",
"actor_hidden_dims": [512, 256, 128],
"critic_hidden_dims": [512, 256, 128],
"init_noise_std": 1.0,
},
"runner": {
"algorithm_class_name": "PPO",
"checkpoint": -1,
"experiment_name": exp_name,
"load_run": -1,
"log_interval": 1,
"max_iterations": max_iterations,
"num_steps_per_env": 24,
"policy_class_name": "ActorCritic",
"record_interval": -1,
"resume": False,
"resume_path": None,
"run_name": "",
"runner_class_name": "runner_class_name",
"save_interval": 100,
},
"runner_class_name": "OnPolicyRunner",
"seed": 1,
}
return train_cfg_dict
def get_cfgs():
env_cfg = {
"num_actions": 12,
# joint/link names
"default_joint_angles": { # [rad]
"FL_hip_joint": 0.0,
"FR_hip_joint": 0.0,
"RL_hip_joint": 0.0,
"RR_hip_joint": 0.0,
"FL_thigh_joint": 0.8,
"FR_thigh_joint": 0.8,
"RL_thigh_joint": 1.0,
"RR_thigh_joint": 1.0,
"FL_calf_joint": -1.5,
"FR_calf_joint": -1.5,
"RL_calf_joint": -1.5,
"RR_calf_joint": -1.5,
},
"dof_names": [
"FR_hip_joint",
"FR_thigh_joint",
"FR_calf_joint",
"FL_hip_joint",
"FL_thigh_joint",
"FL_calf_joint",
"RR_hip_joint",
"RR_thigh_joint",
"RR_calf_joint",
"RL_hip_joint",
"RL_thigh_joint",
"RL_calf_joint",
],
# PD
"kp": 20.0,
"kd": 0.5,
# termination
"termination_if_roll_greater_than": 10, # degree
"termination_if_pitch_greater_than": 10,
# base pose
"base_init_pos": [0.0, 0.0, 0.42],
"base_init_quat": [1.0, 0.0, 0.0, 0.0],
"episode_length_s": 20.0,
"resampling_time_s": 4.0,
"action_scale": 0.25,
"simulate_action_latency": True,
"clip_actions": 100.0,
}
obs_cfg = {
"num_obs": 45,
"obs_scales": {
"lin_vel": 2.0,
"ang_vel": 0.25,
"dof_pos": 1.0,
"dof_vel": 0.05,
},
}
reward_cfg = {
"tracking_sigma": 0.25,
"base_height_target": 0.3,
"feet_height_target": 0.075,
"reward_scales": {
"tracking_lin_vel": 1.0,
"tracking_ang_vel": 0.2,
"lin_vel_z": -1.0,
"base_height": -50.0,
"action_rate": -0.005,
"similar_to_default": -0.1,
},
}
command_cfg = {
"num_commands": 3,
"lin_vel_x_range": [0.5, 0.5],
"lin_vel_y_range": [0, 0],
"ang_vel_range": [0, 0],
}
return env_cfg, obs_cfg, reward_cfg, command_cfg
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-e", "--exp_name", type=str, default="go2-walking")
parser.add_argument("-B", "--num_envs", type=int, default=4096)
parser.add_argument("--max_iterations", type=int, default=100)
args = parser.parse_args()
gs.init(logging_level="warning")
log_dir = f"logs/{args.exp_name}"
env_cfg, obs_cfg, reward_cfg, command_cfg = get_cfgs()
train_cfg = get_train_cfg(args.exp_name, args.max_iterations)
if os.path.exists(log_dir):
shutil.rmtree(log_dir)
os.makedirs(log_dir, exist_ok=True)
env = Go2Env(
num_envs=args.num_envs, env_cfg=env_cfg, obs_cfg=obs_cfg, reward_cfg=reward_cfg, command_cfg=command_cfg
)
runner = OnPolicyRunner(env, train_cfg, log_dir, device="cuda:0")
pickle.dump(
[env_cfg, obs_cfg, reward_cfg, command_cfg, train_cfg],
open(f"{log_dir}/cfgs.pkl", "wb"),
)
runner.learn(num_learning_iterations=args.max_iterations, init_at_random_ep_len=True)
if __name__ == "__main__":
main()
"""
# training
python examples/locomotion/go2_train.py
"""这段代码是一个使用强化学习(PPO算法)训练四足机器人Go2行走的完整实现。以下是对代码的详细解读:
1. 模块导入
-
argparse: 处理命令行参数(如实验名称、并行环境数、训练迭代次数)
-
os/shmutil: 管理日志目录(创建/删除)
-
pickle: 保存实验配置(环境、奖励等参数)
-
go2_env.Go2Env: 自定义机器人仿真环境
-
rsl_rl.runners.OnPolicyRunner: PPO算法的训练运行器
-
genesis: 可能是一个机器人仿真框架(初始化用)
2. 训练配置函数 get_train_cfg
返回PPO算法参数和训练设置:
-
algorithm:
-
PPO超参数:clip范围0.2,目标KL散度0.01,学习率0.001,熵系数0.01
-
优化设置:5个epochs/次更新,4个minibatch,梯度裁剪1.0
-
-
policy:
-
网络结构:Actor-Critic均使用[512,256,128]隐藏层
-
激活函数:ELU(指数线性单元)
-
初始动作噪声:1.0(鼓励探索)
-
-
runner:
-
最大迭代次数100(可命令行覆盖)
-
每环境24步收集一次数据
-
每100次迭代保存模型
-
实验名称和日志路径管理
-
3. 环境配置函数 get_cfgs
返回四个关键配置字典:
a. 环境参数 env_cfg
-
关节控制:
-
默认关节角度(站立姿态)
-
PD控制参数(kp=20.0, kd=0.5)
-
-
终止条件:
-
翻滚/俯仰角超过10度终止episode
-
-
初始化位姿:
-
初始高度0.42米,姿态水平
-
-
延迟与裁剪:
-
模拟动作延迟,动作值裁剪到[-100,100]
-
b. 观测空间 obs_cfg
-
45维观测向量包含:
-
线速度(缩放2x)
-
角速度(缩放0.25x)
-
关节位置/速度(各缩放1x/0.05x)
-
c. 奖励函数 reward_cfg
多目标加权奖励:
-
正向奖励:
-
线速度跟踪(权重1.0)
-
角速度跟踪(0.2)
-
-
惩罚项:
-
垂直方向速度(-1.0)
-
基础高度偏离(-50.0,强惩罚)
-
动作变化率(-0.005)
-
关节偏离默认姿态(-0.1)
-
d. 命令生成 command_cfg
-
生成3维命令(线速度x/y,角速度)
-
此处x速度固定0.5m/s,其他为0(直行)
4. 主函数 main
-
命令行解析:
-
默认实验名"go2-walking"
-
4096个并行环境(极大提升数据效率)
-
最大100次迭代(可扩展)
-
-
初始化:
-
创建/清空日志目录
-
生成所有配置字典
-
-
环境创建:
env = Go2Env(num_envs=4096, ...) # 大规模并行化
-
使用CUDA加速,实现万级环境同步仿真
-
训练运行器:
runner = OnPolicyRunner(env, train_cfg, device="cuda:0")
-
使用PPO算法在GPU上进行策略优化
-
配置保存:
pickle.dump(...) # 保存完整实验配置
-
确保实验可复现
-
启动训练:
runner.learn(max_iterations, init_at_random_ep_len=True)
-
随机初始化episode长度以提升探索
5. 训练执行
通过命令行启动:
python examples/locomotion/go2_train.py
6. 关键算法特性
-
高效并行:
-
4096个环境并行采样,极大提升数据吞吐
-
CUDA加速实现毫秒级环境步进
-
-
奖励工程:
-
基础高度惩罚(-50)确保稳定站立
-
动作平滑惩罚(-0.005)避免抖动
-
默认姿态惩罚引导自然步态
-
-
网络架构:
-
深层网络(3隐藏层)捕捉复杂动力学
-
ELU激活平衡梯度流动与计算效率
-
-
自适应控制:
-
PD参数(kp=20)实现精准关节控制
-
动作延迟模拟真实控制器特性
-
该代码展现了一个工业级四足机器人强化学习训练的典型实现,通过大规模并行化和精细的参数调校,能够高效训练出鲁棒的运动策略。
go2_env.py代码的解读:
import torch
import math
import genesis as gs
from genesis.utils.geom import quat_to_xyz, transform_by_quat, inv_quat, transform_quat_by_quat
def gs_rand_float(lower, upper, shape, device):
return (upper - lower) * torch.rand(size=shape, device=device) + lower
class Go2Env:
def __init__(self, num_envs, env_cfg, obs_cfg, reward_cfg, command_cfg, show_viewer=False, device="cuda"):
self.device = torch.device(device)
self.num_envs = num_envs
self.num_obs = obs_cfg["num_obs"]
self.num_privileged_obs = None
self.num_actions = env_cfg["num_actions"]
self.num_commands = command_cfg["num_commands"]
self.simulate_action_latency = True # there is a 1 step latency on real robot
self.dt = 0.02 # control frequency on real robot is 50hz
self.max_episode_length = math.ceil(env_cfg["episode_length_s"] / self.dt)
self.env_cfg = env_cfg
self.obs_cfg = obs_cfg
self.reward_cfg = reward_cfg
self.command_cfg = command_cfg
self.obs_scales = obs_cfg["obs_scales"]
self.reward_scales = reward_cfg["reward_scales"]
# create scene
self.scene = gs.Scene(
sim_options=gs.options.SimOptions(dt=self.dt, substeps=2),
viewer_options=gs.options.ViewerOptions(
max_FPS=int(0.5 / self.dt),
camera_pos=(2.0, 0.0, 2.5),
camera_lookat=(0.0, 0.0, 0.5),
camera_fov=40,
),
vis_options=gs.options.VisOptions(n_rendered_envs=1),
rigid_options=gs.options.RigidOptions(
dt=self.dt,
constraint_solver=gs.constraint_solver.Newton,
enable_collision=True,
enable_joint_limit=True,
),
show_viewer=show_viewer,
)
# add plain
self.scene.add_entity(gs.morphs.URDF(file="urdf/plane/plane.urdf", fixed=True))
# add robot
self.base_init_pos = torch.tensor(self.env_cfg["base_init_pos"], device=self.device)
self.base_init_quat = torch.tensor(self.env_cfg["base_init_quat"], device=self.device)
self.inv_base_init_quat = inv_quat(self.base_init_quat)
self.robot = self.scene.add_entity(
gs.morphs.URDF(
file="urdf/go2/urdf/go2.urdf",
pos=self.base_init_pos.cpu().numpy(),
quat=self.base_init_quat.cpu().numpy(),
),
)
# build
self.scene.build(n_envs=num_envs)
# names to indices
self.motor_dofs = [self.robot.get_joint(name).dof_idx_local for name in self.env_cfg["dof_names"]]
# PD control parameters
self.robot.set_dofs_kp([self.env_cfg["kp"]] * self.num_actions, self.motor_dofs)
self.robot.set_dofs_kv([self.env_cfg["kd"]] * self.num_actions, self.motor_dofs)
# prepare reward functions and multiply reward scales by dt
self.reward_functions, self.episode_sums = dict(), dict()
for name in self.reward_scales.keys():
self.reward_scales[name] *= self.dt
self.reward_functions[name] = getattr(self, "_reward_" + name)
self.episode_sums[name] = torch.zeros((self.num_envs,), device=self.device, dtype=gs.tc_float)
# initialize buffers
self.base_lin_vel = torch.zeros((self.num_envs, 3), device=self.device, dtype=gs.tc_float)
self.base_ang_vel = torch.zeros((self.num_envs, 3), device=self.device, dtype=gs.tc_float)
self.projected_gravity = torch.zeros((self.num_envs, 3), device=self.device, dtype=gs.tc_float)
self.global_gravity = torch.tensor([0.0, 0.0, -1.0], device=self.device, dtype=gs.tc_float).repeat(
self.num_envs, 1
)
self.obs_buf = torch.zeros((self.num_envs, self.num_obs), device=self.device, dtype=gs.tc_float)
self.rew_buf = torch.zeros((self.num_envs,), device=self.device, dtype=gs.tc_float)
self.reset_buf = torch.ones((self.num_envs,), device=self.device, dtype=gs.tc_int)
self.episode_length_buf = torch.zeros((self.num_envs,), device=self.device, dtype=gs.tc_int)
self.commands = torch.zeros((self.num_envs, self.num_commands), device=self.device, dtype=gs.tc_float)
self.commands_scale = torch.tensor(
[self.obs_scales["lin_vel"], self.obs_scales["lin_vel"], self.obs_scales["ang_vel"]],
device=self.device,
dtype=gs.tc_float,
)
self.actions = torch.zeros((self.num_envs, self.num_actions), device=self.device, dtype=gs.tc_float)
self.last_actions = torch.zeros_like(self.actions)
self.dof_pos = torch.zeros_like(self.actions)
self.dof_vel = torch.zeros_like(self.actions)
self.last_dof_vel = torch.zeros_like(self.actions)
self.base_pos = torch.zeros((self.num_envs, 3), device=self.device, dtype=gs.tc_float)
self.base_quat = torch.zeros((self.num_envs, 4), device=self.device, dtype=gs.tc_float)
self.default_dof_pos = torch.tensor(
[self.env_cfg["default_joint_angles"][name] for name in self.env_cfg["dof_names"]],
device=self.device,
dtype=gs.tc_float,
)
self.extras = dict() # extra information for logging
def _resample_commands(self, envs_idx):
self.commands[envs_idx, 0] = gs_rand_float(*self.command_cfg["lin_vel_x_range"], (len(envs_idx),), self.device)
self.commands[envs_idx, 1] = gs_rand_float(*self.command_cfg["lin_vel_y_range"], (len(envs_idx),), self.device)
self.commands[envs_idx, 2] = gs_rand_float(*self.command_cfg["ang_vel_range"], (len(envs_idx),), self.device)
def step(self, actions):
self.actions = torch.clip(actions, -self.env_cfg["clip_actions"], self.env_cfg["clip_actions"])
exec_actions = self.last_actions if self.simulate_action_latency else self.actions
target_dof_pos = exec_actions * self.env_cfg["action_scale"] + self.default_dof_pos
self.robot.control_dofs_position(target_dof_pos, self.motor_dofs)
self.scene.step()
# update buffers
self.episode_length_buf += 1
self.base_pos[:] = self.robot.get_pos()
self.base_quat[:] = self.robot.get_quat()
self.base_euler = quat_to_xyz(
transform_quat_by_quat(torch.ones_like(self.base_quat) * self.inv_base_init_quat, self.base_quat)
)
inv_base_quat = inv_quat(self.base_quat)
self.base_lin_vel[:] = transform_by_quat(self.robot.get_vel(), inv_base_quat)
self.base_ang_vel[:] = transform_by_quat(self.robot.get_ang(), inv_base_quat)
self.projected_gravity = transform_by_quat(self.global_gravity, inv_base_quat)
self.dof_pos[:] = self.robot.get_dofs_position(self.motor_dofs)
self.dof_vel[:] = self.robot.get_dofs_velocity(self.motor_dofs)
# resample commands
envs_idx = (
(self.episode_length_buf % int(self.env_cfg["resampling_time_s"] / self.dt) == 0)
.nonzero(as_tuple=False)
.flatten()
)
self._resample_commands(envs_idx)
# check termination and reset
self.reset_buf = self.episode_length_buf > self.max_episode_length
self.reset_buf |= torch.abs(self.base_euler[:, 1]) > self.env_cfg["termination_if_pitch_greater_than"]
self.reset_buf |= torch.abs(self.base_euler[:, 0]) > self.env_cfg["termination_if_roll_greater_than"]
time_out_idx = (self.episode_length_buf > self.max_episode_length).nonzero(as_tuple=False).flatten()
self.extras["time_outs"] = torch.zeros_like(self.reset_buf, device=self.device, dtype=gs.tc_float)
self.extras["time_outs"][time_out_idx] = 1.0
self.reset_idx(self.reset_buf.nonzero(as_tuple=False).flatten())
# compute reward
self.rew_buf[:] = 0.0
for name, reward_func in self.reward_functions.items():
rew = reward_func() * self.reward_scales[name]
self.rew_buf += rew
self.episode_sums[name] += rew
# compute observations
self.obs_buf = torch.cat(
[
self.base_ang_vel * self.obs_scales["ang_vel"], # 3
self.projected_gravity, # 3
self.commands * self.commands_scale, # 3
(self.dof_pos - self.default_dof_pos) * self.obs_scales["dof_pos"], # 12
self.dof_vel * self.obs_scales["dof_vel"], # 12
self.actions, # 12
],
axis=-1,
)
self.last_actions[:] = self.actions[:]
self.last_dof_vel[:] = self.dof_vel[:]
return self.obs_buf, None, self.rew_buf, self.reset_buf, self.extras
def get_observations(self):
return self.obs_buf
def get_privileged_observations(self):
return None
def reset_idx(self, envs_idx):
if len(envs_idx) == 0:
return
# reset dofs
self.dof_pos[envs_idx] = self.default_dof_pos
self.dof_vel[envs_idx] = 0.0
self.robot.set_dofs_position(
position=self.dof_pos[envs_idx],
dofs_idx_local=self.motor_dofs,
zero_velocity=True,
envs_idx=envs_idx,
)
# reset base
self.base_pos[envs_idx] = self.base_init_pos
self.base_quat[envs_idx] = self.base_init_quat.reshape(1, -1)
self.robot.set_pos(self.base_pos[envs_idx], zero_velocity=False, envs_idx=envs_idx)
self.robot.set_quat(self.base_quat[envs_idx], zero_velocity=False, envs_idx=envs_idx)
self.base_lin_vel[envs_idx] = 0
self.base_ang_vel[envs_idx] = 0
self.robot.zero_all_dofs_velocity(envs_idx)
# reset buffers
self.last_actions[envs_idx] = 0.0
self.last_dof_vel[envs_idx] = 0.0
self.episode_length_buf[envs_idx] = 0
self.reset_buf[envs_idx] = True
# fill extras
self.extras["episode"] = {}
for key in self.episode_sums.keys():
self.extras["episode"]["rew_" + key] = (
torch.mean(self.episode_sums[key][envs_idx]).item() / self.env_cfg["episode_length_s"]
)
self.episode_sums[key][envs_idx] = 0.0
self._resample_commands(envs_idx)
def reset(self):
self.reset_buf[:] = True
self.reset_idx(torch.arange(self.num_envs, device=self.device))
return self.obs_buf, None
# ------------ reward functions----------------
def _reward_tracking_lin_vel(self):
# Tracking of linear velocity commands (xy axes)
lin_vel_error = torch.sum(torch.square(self.commands[:, :2] - self.base_lin_vel[:, :2]), dim=1)
return torch.exp(-lin_vel_error / self.reward_cfg["tracking_sigma"])
def _reward_tracking_ang_vel(self):
# Tracking of angular velocity commands (yaw)
ang_vel_error = torch.square(self.commands[:, 2] - self.base_ang_vel[:, 2])
return torch.exp(-ang_vel_error / self.reward_cfg["tracking_sigma"])
def _reward_lin_vel_z(self):
# Penalize z axis base linear velocity
return torch.square(self.base_lin_vel[:, 2])
def _reward_action_rate(self):
# Penalize changes in actions
return torch.sum(torch.square(self.last_actions - self.actions), dim=1)
def _reward_similar_to_default(self):
# Penalize joint poses far away from default pose
return torch.sum(torch.abs(self.dof_pos - self.default_dof_pos), dim=1)
def _reward_base_height(self):
# Penalize base height away from target
return torch.square(self.base_pos[:, 2] - self.reward_cfg["base_height_target"])这段代码定义了一个名为Go2Env的类,主要用于模拟一个控制环境,并结合机器人控制与物理仿真。在具体实现中,使用了genesis库来进行仿真,并利用PyTorch对环境进行高效的计算。以下是对代码的详细解释:
导入的库:
- torch:用于深度学习和张量操作。
- math:用于数学计算,主要用于
ceil函数来计算最大回合长度。 - genesis (gs):这是一个用于物理仿真的库,提供了很多操作和方法,例如仿真、物理世界创建等。
- genesis.utils.geom:导入了与几何相关的工具,包括四元数转换(
quat_to_xyz,transform_by_quat,inv_quat,transform_quat_by_quat)。
gs_rand_float函数:
生成一个给定范围内的随机浮动数值。
lower:随机数的下限。upper:随机数的上限。shape:输出的张量形状。device:指定张量所在的设备(如"cuda"或"cpu")。
Go2Env类:
这是一个仿真环境类,包含了用于机器人控制和仿真操作的方法。
__init__方法:
- 参数:
num_envs:环境数量。env_cfg、obs_cfg、reward_cfg、command_cfg:配置字典,包含环境、观察、奖励和指令的相关设置。show_viewer:是否显示可视化界面。device:设备选择,通常为"cuda"或"cpu"。
- 成员变量初始化:
device:设置设备。num_envs:环境数量。num_obs、num_actions、num_commands:分别表示观察的数量、动作的数量和命令的数量。simulate_action_latency:是否模拟动作延迟。dt:仿真步长(控制频率为50Hz,即0.02秒)。max_episode_length:最大回合长度。scene:创建物理仿真场景。robot:添加机器人并设置初始位置和姿态(四元数)。motor_dofs:关节自由度(Degree of Freedom)索引。- PD控制参数:初始化机器人关节的控制增益(
kp和kd)。 - 奖励函数:定义了多个奖励函数,并根据配置进行调整。
step方法:
这个方法执行一个仿真步长的操作,主要任务是:
- 动作执行:将输入的动作(
actions)进行裁剪,按照控制增益设置目标位置,并发送到机器人。 - 物理仿真:调用
self.scene.step()执行仿真步骤。 - 状态更新:更新机器人的位置、速度、关节角度等状态信息。
- 指令重采样:每隔一段时间重新生成指令(通过
_resample_commands方法)。 - 终止检查:判断是否满足重置条件(例如回合超过最大长度,或者机器人倾斜角度超过阈值)。
- 奖励计算:根据定义的奖励函数计算当前回合的奖励。
- 观察计算:组合当前状态信息生成观察值。
reset方法:
重置环境状态,恢复到初始状态,并重新生成观察值。
奖励函数:
奖励函数主要用于训练过程中评估机器人的表现:
_reward_tracking_lin_vel:追踪线性速度命令的奖励。_reward_tracking_ang_vel:追踪角速度命令的奖励。_reward_lin_vel_z:惩罚沿Z轴的线性速度。_reward_action_rate:惩罚动作的变化速度。_reward_similar_to_default:惩罚关节位置偏离默认值的程度。_reward_base_height:惩罚基座高度偏离目标值。
总结:
该代码实现了一个基于物理仿真的控制环境,用于训练机器人在不同任务中优化其动作和表现。通过PyTorch和genesis库的结合,能够高效地进行并行计算和仿真操作。环境包括了机器人控制、奖励设计、观测计算等核心部分,为机器人学习和控制任务提供了基础。
go2_eval.py代码的解读:
import argparse
import os
import pickle
import torch
from go2_env import Go2Env
from rsl_rl.runners import OnPolicyRunner
import genesis as gs
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-e", "--exp_name", type=str, default="go2-walking")
parser.add_argument("--ckpt", type=int, default=100)
args = parser.parse_args()
gs.init()
log_dir = f"logs/{args.exp_name}"
env_cfg, obs_cfg, reward_cfg, command_cfg, train_cfg = pickle.load(open(f"logs/{args.exp_name}/cfgs.pkl", "rb"))
reward_cfg["reward_scales"] = {}
env = Go2Env(
num_envs=1,
env_cfg=env_cfg,
obs_cfg=obs_cfg,
reward_cfg=reward_cfg,
command_cfg=command_cfg,
show_viewer=True,
)
runner = OnPolicyRunner(env, train_cfg, log_dir, device="cuda:0")
resume_path = os.path.join(log_dir, f"model_{args.ckpt}.pt")
runner.load(resume_path)
policy = runner.get_inference_policy(device="cuda:0")
obs, _ = env.reset()
with torch.no_grad():
while True:
actions = policy(obs)
obs, _, rews, dones, infos = env.step(actions)
if __name__ == "__main__":
main()
"""
# evaluation
python examples/locomotion/go2_eval.py -e go2-walking -v --ckpt 100
"""这段代码是一个用于评估和运行Go2机器人环境的脚本。下面是对代码的详细解释:
导入的库:
- argparse:用于命令行参数解析。
- os:提供与操作系统交互的功能,如文件路径处理。
- pickle:用于序列化和反序列化Python对象,通常用于加载保存的模型和配置文件。
- torch:用于深度学习模型的处理,特别是与PyTorch相关的张量操作和计算。
- Go2Env:Go2环境类(前面讨论过),用于创建并控制Go2机器人环境。
- OnPolicyRunner:用于运行强化学习训练的runner(在
rsl_rl.runners模块中)。 - genesis (gs):物理仿真库,用于创建仿真场景。
main()函数:
-
命令行参数解析:
- 使用
argparse解析命令行参数。 -e或--exp_name:实验名称,默认为"go2-walking"。--ckpt:用于指定模型的检查点(默认为100)。
- 使用
-
初始化
genesis:gs.init():初始化genesis仿真环境。
-
加载配置文件:
- 通过
pickle.load加载配置文件cfgs.pkl,包括环境配置(env_cfg)、观察配置(obs_cfg)、奖励配置(reward_cfg)、命令配置(command_cfg)和训练配置(train_cfg)。 reward_cfg["reward_scales"]被重置为空字典,这可能是为了重新设置奖励尺度。
- 通过
-
创建环境:
- 创建一个Go2Env实例,传入环境配置、观察配置、奖励配置、命令配置等,设置环境为1个实例,并启用视图(
show_viewer=True)。
- 创建一个Go2Env实例,传入环境配置、观察配置、奖励配置、命令配置等,设置环境为1个实例,并启用视图(
-
创建强化学习runner:
- 使用
OnPolicyRunner创建一个强化学习的runner,传入环境、训练配置、日志目录和设备(cuda:0表示使用GPU)。
- 使用
-
加载模型:
resume_path:根据传入的检查点(args.ckpt)加载对应的模型文件(model_{args.ckpt}.pt)。- 使用
runner.load(resume_path)加载模型参数。 - 使用
runner.get_inference_policy()获取已加载模型的推理策略,并将设备设置为GPU(cuda:0)。
-
环境重置与推理:
- 调用
env.reset()重置环境并获取初始观察(obs)。 - 在
torch.no_grad()上下文中,禁用梯度计算以加速推理过程。然后进入一个循环,在每个循环中:- 使用推理策略
policy(obs)生成当前观察下的动作(actions)。 - 将生成的动作传递给环境,进行一步仿真(
env.step(actions)),返回新的观察、奖励、结束标志等。
- 使用推理策略
- 调用
if __name__ == "__main__":
确保当脚本直接运行时,调用main()函数。
注释中的评估命令:
python examples/locomotion/go2_eval.py -e go2-walking -v --ckpt 100
- 这条命令是用于运行Go2机器人的评估脚本。
-e go2-walking:指定实验名称为"go2-walking"。-v:表示在评估过程中显示可视化界面。--ckpt 100:加载检查点为100的模型进行评估。
总结:
这个脚本是一个用于Go2机器人环境评估的执行脚本。它首先加载实验配置文件和训练好的模型,然后在环境中运行机器人,并使用该模型的策略进行推理和动作执行。最终,它会在每个环境步长中更新机器人的状态。
补充:强化学习(PPO算法)
最后简单聊一下PPO算法:
强化学习(Reinforcement Learning,RL) 是一种机器学习方法,通过智能体与环境的交互来学习最佳行为策略。智能体在环境中执行动作,根据得到的奖励(或惩罚)更新其策略,从而使得累积的奖励最大化。强化学习常见的算法有值函数方法、策略梯度方法和模型驱动方法,其中Proximal Policy Optimization(PPO) 是一种基于策略梯度的强化学习算法,广泛应用于各种复杂的决策任务中。
1. 强化学习基础概念
在强化学习中,智能体在环境中与外部世界进行交互,基于这些交互的结果来调整其策略。强化学习的核心概念包括:
- 状态(State,s):环境的一个具体情形。
- 动作(Action,a):智能体可以执行的操作。
- 奖励(Reward,r):智能体执行动作后,环境反馈的反馈信号,用于评价动作的好坏。
- 策略(Policy,π):定义智能体在某一状态下采取的动作选择的规则或分布。可以是确定性(直接选择动作)或随机性(基于概率选择动作)。
- 价值函数(Value function,V):衡量在某一状态下,智能体能够期望获得的未来奖励的总和。常用的价值函数有状态价值函数和动作价值函数。
2. PPO(Proximal Policy Optimization)算法简介
PPO 是一种基于策略梯度的方法,是强化学习中的一个重要算法,尤其适用于大规模的强化学习任务。PPO 的设计旨在通过改进传统的策略优化方法,克服一些传统方法的不足,如TRPO(Trust Region Policy Optimization)和A3C(Asynchronous Advantage Actor-Critic)。
2.1 PPO的关键思想
PPO 的核心思想是通过约束策略更新的幅度来防止更新过程中的不稳定性。策略更新时,PPO通过一个“剪切”策略,限制每次更新的变化幅度,从而避免过大步长导致的策略震荡。这样做使得PPO能够在优化中提供更好的稳定性。
2.2 PPO算法的组成
PPO 属于策略梯度算法的一种,基于**演员-评论家(Actor-Critic)**框架。具体来说,PPO 的算法包括两个主要部分:
- Actor(演员):负责选择动作的部分,通常由一个神经网络表示,输出一个概率分布。
- Critic(评论家):评估当前策略的部分,通常是通过计算当前状态的价值函数来衡量智能体的表现。
PPO的主要创新体现在其对策略更新的约束和稳定性控制上,主要通过以下几个步骤实现:
-
目标函数的设计: PPO 通过引入一个裁剪(clipping)函数来限制每次策略更新的幅度。具体来说,PPO设计了一个目标函数,其中包含了一个重要性采样(importance sampling)比率,用于计算旧策略和新策略之间的差异:
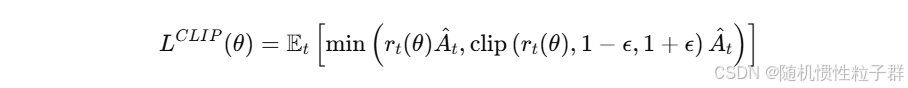
-
其中,r_t (θ) 是当前策略和旧策略的比率,A^t 是优势函数(Advantage Function),ϵ 是一个超参数(通常设为0.1或0.2)。通过这种方式,PPO避免了过大的策略更新,并增强了训练的稳定性。
-
优势函数(Advantage Function): PPO算法使用优势函数来指导策略的更新。优势函数表示某个动作相对于平均水平的表现如何,通常通过**广义优势估计(GAE,Generalized Advantage Estimation)**进行计算,从而减少估计的偏差和方差。
-
裁剪机制: 裁剪机制的引入是PPO的核心创新之一。通过限制更新幅度,防止策略更新时出现过大的变化,确保优化过程不会因为一次大步长更新而导致性能下降。这个约束使得PPO相比其他策略梯度方法更加稳定。
2.3 PPO的优点
- 稳定性:通过引入裁剪机制,PPO避免了策略更新时的过大变化,显著提高了训练的稳定性。
- 高效性:PPO算法对超参数的选择相对不敏感,尤其是在一些复杂任务中,PPO表现出了优越的效率。
- 简单易用:PPO的算法实现相对简单,且能够处理复杂的强化学习任务,因此广泛应用于各类任务中。
3. PPO的工作原理
PPO的主要步骤包括:
- 采样(Collecting Data):在当前策略下与环境进行交互,生成一批状态、动作、奖励和优势信息。
- 计算优势(Compute Advantage):计算每个时间步的优势函数,用于衡量某个动作是否优于平均水平。
- 更新策略(Update Policy):使用策略梯度方法,通过优化PPO目标函数来更新策略。PPO的关键在于限制策略更新的幅度,确保每次更新都是逐步改进而非跳跃性变化。
- 多次迭代:重复上述过程,不断提高策略,直到训练收敛。
总结
PPO(Proximal Policy Optimization)是一个高效且稳定的强化学习算法,通过引入裁剪机制来限制策略更新的幅度,防止过大的更新带来不稳定性,解决了传统策略梯度方法中的一些问题。PPO的设计使得它在多种强化学习任务中表现出色,特别是在复杂、动态的环境中,成为了强化学习领域中的一个非常重要且常用的算法。


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











