






 本文探讨了现有PersonRe-ID方法的问题,尤其是基于ImageNet预训练的局限性。PASS网络提出结合Teacher-Student架构,解决局部和全局信息的关联问题,通过局部位置tokens和区分部分的预训练,提升模型在Personre-identification任务中的性能。DINO和其在Person-REID的应用被分析,随后介绍了PASS的改进和实验结果。
本文探讨了现有PersonRe-ID方法的问题,尤其是基于ImageNet预训练的局限性。PASS网络提出结合Teacher-Student架构,解决局部和全局信息的关联问题,通过局部位置tokens和区分部分的预训练,提升模型在Personre-identification任务中的性能。DINO和其在Person-REID的应用被分析,随后介绍了PASS的改进和实验结果。
最近对Re-ID比较感兴趣,读了一篇关于Re-ID的文章,作为自己学习的一个记录,有说的不正确的地方欢迎大家指正,也希望大家一起共同学习共同进步!!!
原文地址:Zhu K, Guo H, Yan T, et al. Pass: Part-aware self-supervised pre-training for person re-identification[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 198-214.
github:https://github.com/CASIA-IVA-Lab/PASS-reID.
1. Abstract:
提出问题(挖坑):文章一开始直接表明,现有的reid的backone都是直接在imageNet的数据集进行SSL(此处挖个坑,后面讲什么是ssl)的预训练,而ImageNet,是一个主要是以分类任务的数据集不适合Person reid 领域,因此设计了一个PASS这个网络
填坑:这个PASS就是为了解决这个问题的,但是有人问了,那我构造一个关于RE-id的大规模数据集在这个上面预训练就行了呗,还需要其他东西吗
别急,现在就要说说这个SSL了,SSL(self-supervised learning)自监督学习,我们都知道,深度学习可以分为两种方式,有监督和无监督,这个自监督学习就属于无监督学习的一种,自监督学习的一种常见方法就是Teacher-Student网络。
2.what is Teacher-Student?
简单的来说就老师教学生,那么谁是老师,谁是学生呢,较为复杂的网络作为老师,较为简单的网络作为学生,两个输入分别进入教师网络和学生网络,利用教师网络的输出与学生网络的输出去做损失,最终学生网络达到和教师网络相同的效果,就像老师教会了学生知识一样,这时一个较为简单的网络就可以代替就为复杂的网络,因此这个过程也可以成为 知识蒸馏
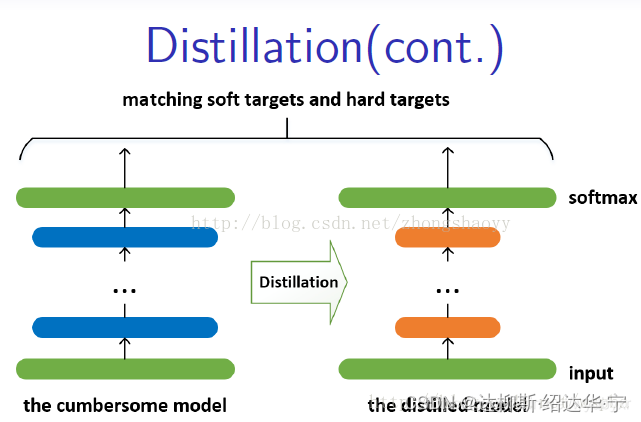
看完这个补充知识,接下来我们书接上文,使用这个教师-学生的思想,我们将局部信息和全局信息联系了起来(怎么联系的?? 下文作者还会讲解的),但是这种联系是有问题的,也就是说会丢失很多细节信息,因此针对于这个问题,作者给出了解决方法:(终于说到正题了)PASS预训练网络模型。
3. Introduction
上文提到了说对person-reid任务来说,缺少一个大规模的数据集,那这个数据集现在有没有人提出呢?已经有了“LUPerson”。同时呢,也证明了在这个LUPerson数据集上进行预训练是优于ImageNet的。除此之外,DINO(一个带有VIT的SSL模型)在这个数据集上取得了SOTA 结果。
好了那就不得不再介绍一下这个DINO是何许人也了
4.DINO
4.1 网络原理
DINO是自监督学习的经典制作,在当时VIT由于他需要很多的计算资源,并需要更多的训练数据。这篇文章就是在研究能否通过SSL来改变这种现状。(他的一大优势在于并非只能在VIT上应用,在CNN上也是可以使用的)
DINO也是采用了Teacher-student的思想,他首先将一张图片裁减为两种尺寸,然后输入到教师-学生网络,最后使用K-NN分类器,取得了很好的效果

4.2 DINO在Person-REID应用
由于DINO的设计是针对图像分类任务的,所以并不适合Person-reid。为什么呢?作者叙述了原因
例如下图,当模型输入一张行人图片时,DINO会在图片上随机裁减,eg裁减为四部分,分别为左上(红衣服左),右上(红衣服右),左下(蓝裤子左),右下(蓝裤子右),接下来将裁减后的部分成为local view进入student网络,同时将原图输入teacher网络,接下来对两个网络的输出进行匹配,这时候问题就来了:红衣服和蓝裤子对应都是相同的一个图,也就是相当于文科生和理科生都由一个老师去教学,那么最后这个学生并没有学会该学会的知识,也就是对于reid识别任务的关键信息没有学到,都被丢弃了。因此来说,DINO对于reid是需要改进的。
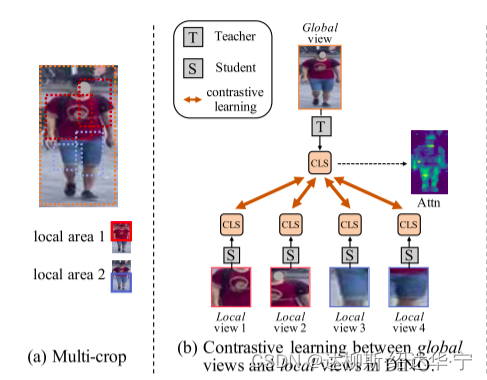
5. 基于DINO的改进——PASS
首先,将输入图片分成几个固定的重叠区域,并在这几个区域中随机裁减出大小不同的local views,同时裁减出比local views更大的view作为global views,然后local views 进入students网络之前,在local views 上添加了一个可学习的[PART]token,用来学习位置信息,也就是关注的部位,(eg裁减的上半身那么增加一个[PART1] token,裁减的下半身添加一个[PART2] token)。另外,在global 中也进行相同的添加part token 操作。
经过这样的操作,学生网络专注于学习对应位置的教师表达,也就是相当于文科生去找文科老师学,理科生去找理科老师学习,那么自然文科生文科利害,理科生理科利害(不排除特殊情况。。。)
在pre-training 阶段,学生网络在教师网络中学会了local的位置表示
在 fine-tune阶段,[PARTS]会添加到input images并自动学习这个特殊区域的表示(老师教会了学生,学生该出山了)
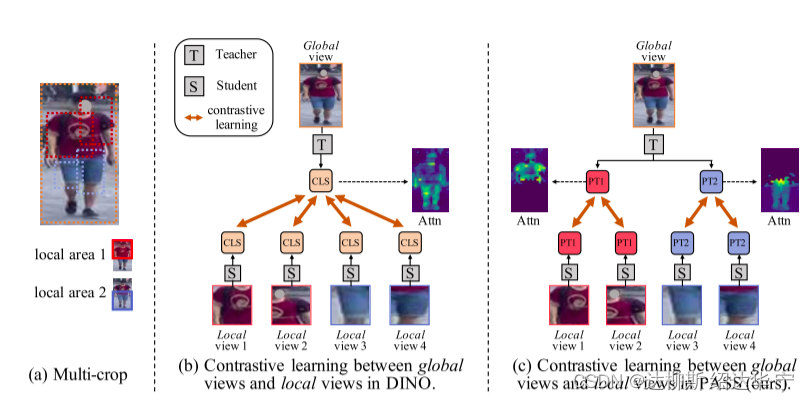
6. 网络图详解
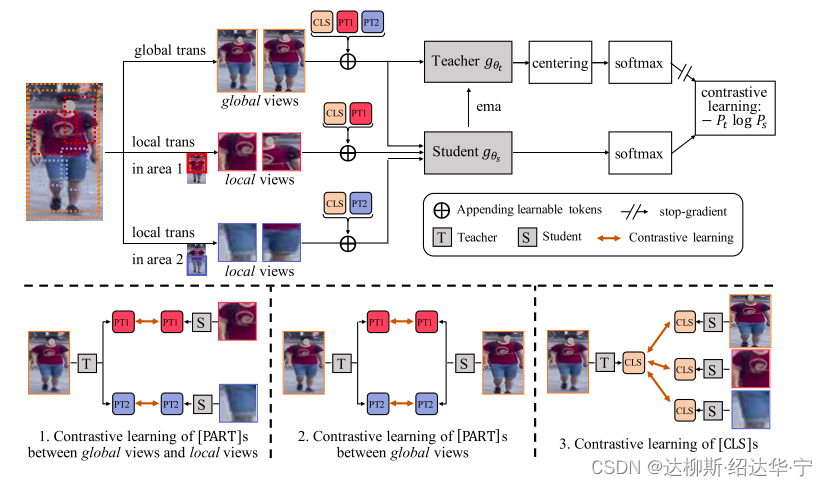
其实大体内容是和上文所述差不多的,这张图是展现的L=2(最简单的分为2部分区域的情况),
接下来看teacher网络的输入,仅仅只有带有[PT1]和[PT2]以及[class]信息的global views;而student网络的输入是分别带有[PT1]和[PT2]以及[CLASS]的local view 和与teacher网络输入相同的global view,其中[PART]作为位置信息,同时添加了[CLASS]作为类别信息。
通过teacher网络和student网络后,共有三种学习方式:
a. 带有[PT1]和[PT2]的global views的teacher网络输出分别和分别带有[PT1]和[PT2]local view 的student网络输出
b. 带有[PT1]和[PT2]的global views的teacher网络输出和带有[PT1]和[PT2]的global views的student网络输出(两者网络输入都是相同的,只不过网络不同)
c. 带有[class]信息的global views的teacher网络输出分别和分别带有[CLASS]的local view的student网络输出
同时Teacher网络的权重更新是由student网络的参数指数移动平均决定的(EMA)。
EMA:![]() 为teacher 参数,
为teacher 参数,![]() 为student的参数,在训练期间,λ遵循从0.996到1的余弦时间表
为student的参数,在训练期间,λ遵循从0.996到1的余弦时间表

每个网络输出预测K维特征,然后通过softmax,最后带有[PART]/[CLS]信息的输出作cross-entropy losses

7.Supervised ReID
pre-trained 的PASS,VIT backone 已经有能力学习到输入图片的全局信息,并且拥有的[PARTs]会提取特定关键位置的特征和[CLS]信息,对输出求mean,然后借用TransReID的baseline,使用cross-entropy loss和triplet loss(很经典的三元组损失),最终将两个损失求和。
![]()

![]()
8. Conclusion
文章最后就是实验结果和消融实验了,同时他也证明了他这个PASS模型在supervised ReID 和 UDA/USL ReID也取得了很好的效果。

















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









