






一、前言
记录一下毕设用到的设计和代码
后来发现资源太大了,放不下,我先找个代码托管平台去
二、ConvNeXt网络介绍
ConvNeXt网络是一种新型的卷积神经网络(CNN)模型,其设计旨在提高图像识别的准确性和效率。它采用了一种全新的网络结构,并引入了一些创新性的技术,使得网络能够学习到更丰富和多样化的特征信息。
ConvNeXt网络的核心思想是通过具有不同尺度和深度的卷积层来捕捉图像中的不同特征。它使用了一种称为“空间金字塔池化”(SPP)的技术来改进传统CNN中的池化层。SPP通过在不同尺度上对输入进行金字塔池化来捕捉不同尺度的特征,并通过结合不同尺度的特征来提高CNN的准确性。此外,ConvNeXt还借鉴了残差网络(ResNet)的思想,通过结合较浅层的特征与较深层的特征来提高网络的性能。
ConvNeXt的网络结构可以分为两个主要部分:特征提取和分类。特征提取部分由一系列卷积层和池化层组成,用于从图像中提取出有用的特征。这些特征随后被送入分类部分,通过一系列全连接层和激活函数进行分类预测。通过多层次的特征提取和分类过程,ConvNeXt能够准确地识别出图像中的对象并完成分类任务。
ConvNeXt的另一个关键特点是对图像中的平移、旋转和缩放等变换具有强大的适应性。它通过引入具有旋转和平移不变性的卷积核,使网络能够更好地应对图像的变化。这使得ConvNeXt在处理不同尺度和角度的图像数据时能够取得更好的效果。ConvNeXt的块结构如下
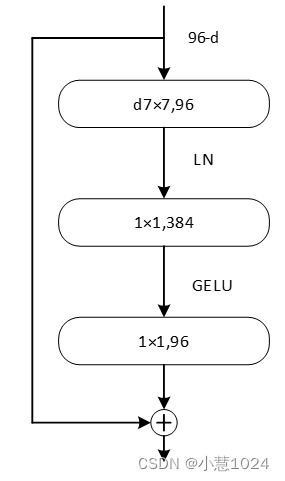
由上图可以看出,激活函数替换成了GELU并减少了激活函数的使用次数,且将最初的通道数由64调整成96,增加卷积核大小,还将批量规范化BN换成了层规范化LN。这些改变使该卷积网络在imagenet上以top-1中取得87.8%的精度。
对于ConvNeXt网络,作者提出了T/S/B/L/XL五个版本,如下图所示:

从上至下模型复杂度不断提高,算力要求也不断提高,C后的数字代表每一层网络的深度,B后面的数字代表卷积堆叠的次数。针对本文设计的系统,由于数据量不多,我们采用ConvNeXt-T版本。
ConvNeXt网络结构如下图所示所示:
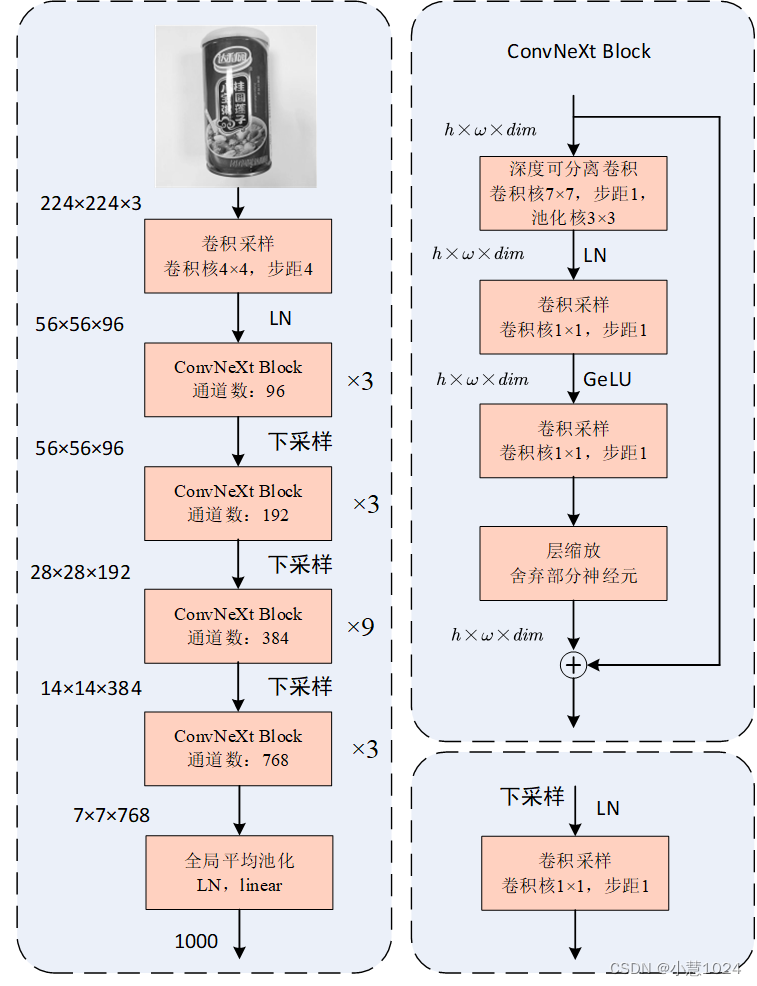
图片输入ConvNeXt神经网络,先进行卷积采样,经过层规范后送入下一层;卷积核4×4,步距4,之后进行4个不同参数的ConvNeXt Block进行卷积,分别堆叠3,3,9,3次,送入下一层之前先进行下采样;最后经过全局平均池化,层规范,线性层后输出结果。ConvNeXt Block步骤分为5步:
- 深度可分离卷积卷积核7×7,步距1,池化核3×3
- 卷积采样,卷积核1×1,步距1,之后使用层规范
- 卷积采样,卷积核1×1,步距1,之后使用GeLU激活
- 层缩放,舍弃部分神经元,防止过拟合和提高训练效率
将输出的结果与输入的结果进行堆叠,以保持信息的原有特征。
三、实验
本实验初期在windows10上搭建实验平台,实验电脑构建ConvNeXt神经网络,并利用电脑GPU进行加速训练。Python编译软件使用的是PyCharm Commumity Edition ,它的作用是编写相关的代码和训练神经网络模型。使用Anaconda来搭建实验环境和管理各个软件包。Anaconda是一个发行的python版本,包含180个学科包和依赖项,是一个一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。在这个实验中,基于Python技术的底层深度学习框架TensorFlo被选择为垃圾回收算法的加速学习平台,具有很强的通用性和可移植性。利用卷积神经网络技术的图像分类与预测过程中,由于其所涉及的参数较多,导致其所需的存储容量远大于传统计算机的CPU,导致其存储容量难以满足如此高的计算要求。GPU在转移和运算速率上比CPU慢,但是GPU在图像处理上表现得很好,因为GPU具有较多的ALU、较大的存储空间、较强的并行能力等优点,能够有效地解决大规模的网络矩阵运算,同时能够通过并行技术来加速算法的运算,缩短算法的训练时间。在下列表格中列出了实验环境软硬件的参数
| 名称 | 相关配置 |
| 操作系统 | Windows(64位) |
| 中央处理器 | AMD Ryzen 7 4800H with Radeon Graphics |
| 内存 | 16GB |
| GPU | NVIDIA GeForce GTX 2060 6GB |
| CuDNN | CuDNN 8.1 |
| CUDA | cudatoolkit 11.2.0 |
| Tensorflow | Tensorflow 2.10 |
| Python | Python 3.9.19 |
在这里要注意python,tensorflow,cudatoolkit版本之间的配合,聚体关系见下表所示,原生 Windows 上的 GPU 支持仅适用于 2.10 或更早版本,从 TF 2.11 开始,Windows 不支持 CUDA 构建。要在 Windows 上使用 TensorFlow GPU,您需要在 WSL2 中构建/安装 TensorFlow,或者使用 tensorflow-cpu 配合 TensorFlow-DirectML-Plugin。
| Version | Python version | Compiler | Build tools | cuDNN | CUDA |
| tensorflow-2.15.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.8 | 12.2 |
| tensorflow-2.14.0 | 3.9-3.11 | Clang 16.0.0 | Bazel 6.1.0 | 8.7 | 11.8 |
| tensorflow-2.13.0 | 3.8-3.11 | Clang 16.0.0 | Bazel 5.3.0 | 8.6 | 11.8 |
| tensorflow-2.12.0 | 3.8-3.11 | GCC 9.3.1 | Bazel 5.3.0 | 8.6 | 11.8 |
| tensorflow-2.11.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.3.0 | 8.1 | 11.2 |
| tensorflow-2.10.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.1.1 | 8.1 | 11.2 |
| tensorflow-2.9.0 | 3.7-3.10 | GCC 9.3.1 | Bazel 5.0.0 | 8.1 | 11.2 |
| tensorflow-2.8.0 | 3.7-3.10 | GCC 7.3.1 | Bazel 4.2.1 | 8.1 | 11.2 |
| tensorflow-2.7.0 | 3.7-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.6.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.5.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.4.0 | 3.6-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 8 | 11 |
| tensorflow-2.3.0 | 3.5-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 7.6 | 10.1 |
| tensorflow-2.2.0 | 3.5-3.8 | GCC 7.3.1 | Bazel 2.0.0 | 7.6 | 10.1 |
| tensorflow-2.1.0 | 2.7, 3.5-3.7 | GCC 7.3.1 | Bazel 0.27.1 | 7.6 | 10.1 |
| tensorflow-2.0.0 | 2.7, 3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10 |
| tensorflow_gpu-1.15.0 | 2.7, 3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10 |
| tensorflow_gpu-1.14.0 | 2.7, 3.3-3.7 | GCC 4.8 | Bazel 0.24.1 | 7.4 | 10 |
| tensorflow_gpu-1.13.1 | 2.7, 3.3-3.7 | GCC 4.8 | Bazel 0.19.2 | 7.4 | 10 |
| tensorflow_gpu-1.12.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.11.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.10.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.9.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.11.0 | 7 | 9 |
| tensorflow_gpu-1.8.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.10.0 | 7 | 9 |
| tensorflow_gpu-1.7.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
| tensorflow_gpu-1.6.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
| tensorflow_gpu-1.5.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.8.0 | 7 | 9 |
| tensorflow_gpu-1.4.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.5.4 | 6 | 8 |
| tensorflow_gpu-1.3.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.5 | 6 | 8 |
| tensorflow_gpu-1.2.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.5 | 5.1 | 8 |
| tensorflow_gpu-1.1.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.2 | 5.1 | 8 |
| tensorflow_gpu-1.0.0 | 2.7, 3.3-3.6 | GCC 4.8 | Bazel 0.4.2 | 5.1 | 8 |
否则因为版本之间不兼容而报错,在下载环境的时候可以使用国内的清华和豆瓣镜像。
在ConvNeXt神经网络中,优化器采用SGD优化器。学习率变化策略采用余弦退火,余弦退火可以帮助模型在训练过程中逐渐降低学习率,这有助于使训练过程更加稳定。在训练初期,使用较大的学习率有助于快速收敛,而在训练后期,逐渐减小学习率有助于更精细地调整模型参数,提高模型的泛化能力。余弦退火是一种有效的学习率变化策略,可以帮助提高模型的训练速度、泛化能力以及避免陷入局部最优点。
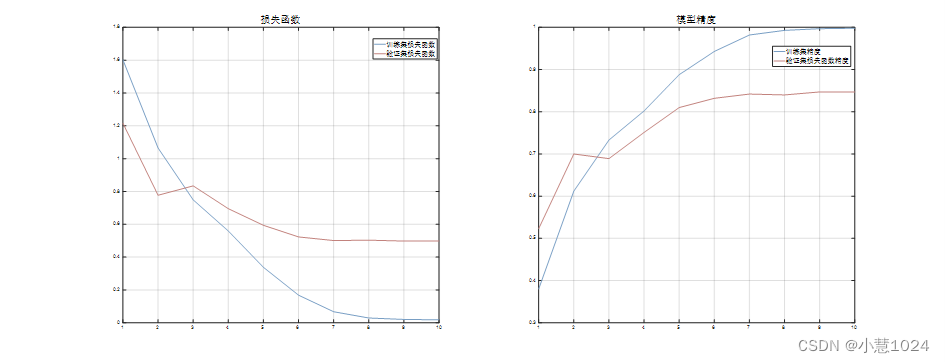
本节主要从每一个迭代模型的损失函数的最小值和准确率来分析模型的性能。由于数据集分为验证集和训练集,所以在我们在这里将两个集合的数据进行对比分析。下图是训练集和验证集的损失函数值和模型精度的图片。
四、图形界面开发
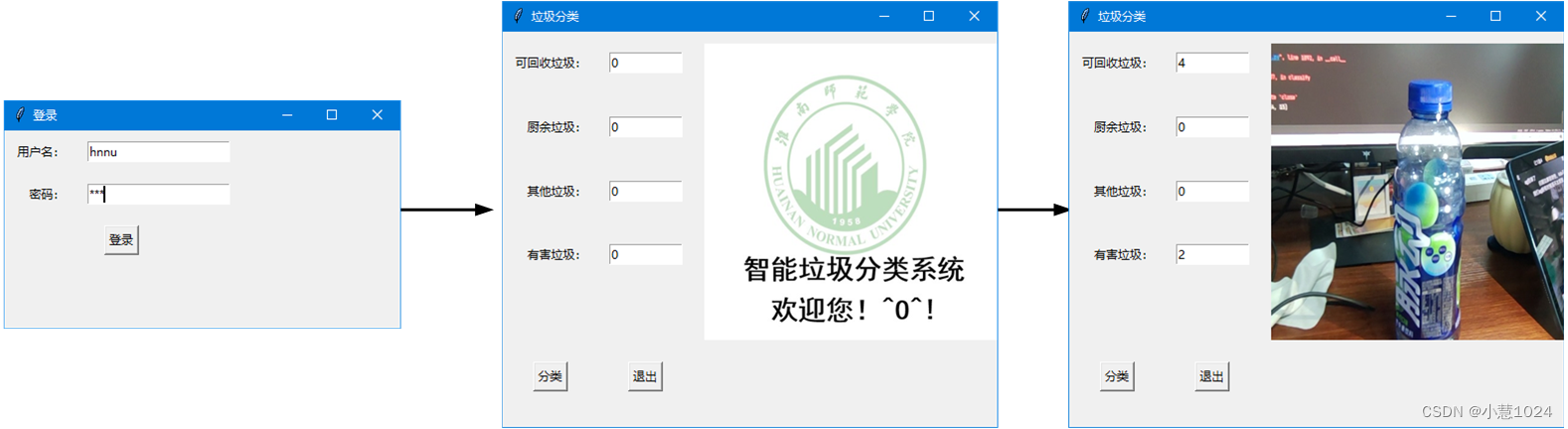
该图形界面主要由使用python库thinter编程,刚运行代码会出现登陆界面,输入正确的账号和密码才能登陆系统,否则系统则会提示密码错误,为提高系统的安全性,在该系统输入密码时密码会自动变成“*”。登陆系统以后会进入分类界面,该界面左下角有分类和退出两个按钮,还有6个文本框,对应安装纸片,玻璃杯,易拉罐,塑料杯,纸,其他垃圾垃圾,刚开始6个文本框后面的数量都为0,而且界面左侧会有欢迎界面。点击分类按钮,分类界面会将摄像头捕捉的垃圾照片更新在界面右侧,并根据ConvNeXt神经网络分类结果更新文本框后面的数量,点击退出按钮,退出系统。该界面。该界面的图片如下图所示:
五、执行机构设计
为保持垃圾分类的准确性与高效率,我们采用两个舵机串联的方式来实现垃圾的投放,即二自由舵机,上位舵机控制物料投放口的倾倒动作,下位舵机控制物料的旋转动作。上下位舵机型号都为DS3115MG,其中上位舵机可以旋转 ,下位舵机可以旋转 ,且驱动电流为0.8~2.8A,驱动电压为6~7.4V。由于物料投放口的常态为水平状态,所以上位舵机的初始状态为 ,即长U型舵机支架处于竖直状态。舵机与垃圾桶箱体依靠底座相连接,由舵机和投放平台组合投料结构如下图所示:

舵机的运动控制由主控板Arduino控制,其型号为Uno。Arduino Uno是一款开源的单板微控制器,它基于 Atmel AVR 微控制器。它具有数字输入/输出引脚、模拟输入/输出引脚、PWM 输出、串口通信、I2C 通信等功能,可以用于各种物联网、机器人、自动化控制等项目。Arduino Uno 的设计简单易用,因此它成为了广泛使用的开发板之一,由于Arduino的允许通过电流为80mA,无法驱动舵机。且舵机运行电流较大,且舵机在启动瞬间和抱死状态会产生较大电流损害主控板,所以我们采用外加一个舵机驱动板。16路舵机驱动模块可驱动16路舵机,舵机供电电压由输入电压决定,可外接5-8.4V,可使用IIC或串口进行控制。板载短路保护、反接保护、单片机稳压电路,大大增加了垃圾分类装置的可靠性。其实物图见下图所示,这个控制板在亚博可以购买。

Arduino中总共包含8种舵机姿态,其中上位舵机的姿态两种,回正和倾倒。而下位舵机由4种姿态,分别如下图所示。其中淡黄色的矩形为物料投放平台,箭头代表下位舵机的运动状态
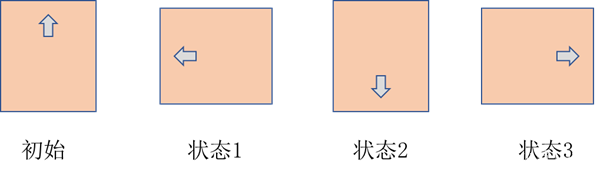
通过这8种姿态就能将不同的垃圾成功投放到对应的垃圾桶中。
视觉算法检测的最终结果会被主控板Jetson通过串口传递给Arduino,所以本垃圾分类装置的基本流程可见下图

机械模型如下图所示:
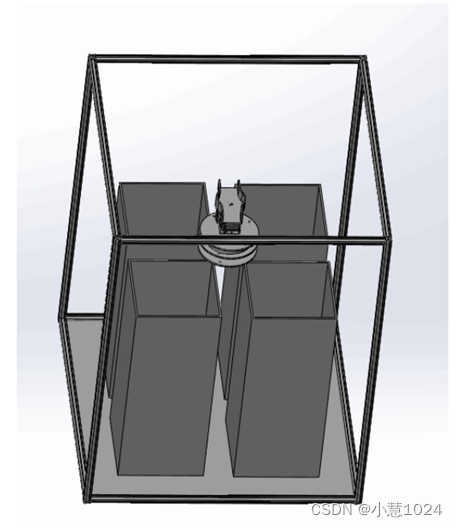
该垃圾分类模型由4个独立的垃圾桶构成,尺寸都为200×200×300mm,其材质分别为亚克力和木板,其厚度为3mm。垃圾分类装置整体尺寸为500×500×600mm,框架由20×20mm的铝方管构成。底板的材质为3mm的亚克力板。整体结构设计合理,空间利用率较为合理。
最后的实物图:

六、实现代码
代码和垃圾图片数据集最终会打包放在文章中
1.视觉环境
absl-py==2.1.0
altgraph==0.17.2
astunparse==1.6.3
cachetools==5.3.3
certifi==2024.2.2
charset-normalizer==3.3.2
colorama==0.4.6
cycler==0.11.0
flatbuffers==24.3.25
fonttools==4.31.2
future==0.18.2
gast==0.4.0
google-auth==2.29.0
google-auth-oauthlib==0.4.6
google-pasta==0.2.0
grpcio==1.62.1
h5py==3.10.0
idna==3.6
importlib_metadata==7.1.0
keras==2.10.0
Keras-Preprocessing==1.1.2
kiwisolver==1.4.2
libclang==18.1.1
Markdown==3.6
MarkupSafe==2.1.5
matplotlib==3.5.1
numpy==1.22.3
oauthlib==3.2.2
opencv-contrib-python==4.6.0.66
opencv-python==4.9.0.80
opt-einsum==3.3.0
packaging==21.3
pefile==2022.5.30
Pillow==9.1.0
protobuf==3.19.6
pyasn1==0.6.0
pyasn1_modules==0.4.0
pyinstaller==5.1
pyinstaller-hooks-contrib==2022.7
pyparsing==3.0.7
pyserial==3.5
python-dateutil==2.8.2
pywin32-ctypes==0.2.0
requests==2.31.0
requests-oauthlib==2.0.0
rsa==4.9
scipy==1.8.0
six==1.16.0
tensorboard==2.10.1
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.1
tensorflow==2.10.0
tensorflow-estimator==2.10.0
tensorflow-intel==2.11.0
tensorflow-io-gcs-filesystem==0.31.0
termcolor==2.4.0
tqdm==4.66.2
typing_extensions==4.11.0
urllib3==2.2.1
Werkzeug==3.0.2
wrapt==1.16.0
wxPython==4.1.1
zipp==3.18.1
环境最终集合在requirements.txt文件中
model.py-----ConvNeXt网络搭建:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, initializers, Model
KERNEL_INITIALIZER = {
"class_name": "TruncatedNormal",
"config": {
"stddev": 0.2
}
}
BIAS_INITIALIZER = "Zeros"
class Block(layers.Layer):
"""
Args:
dim (int): Number of input channels.
drop_rate (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_rate=0., layer_scale_init_value=1e-6, name: str = None):
super().__init__(name=name)
self.layer_scale_init_value = layer_scale_init_value
self.dwconv = layers.DepthwiseConv2D(7,
padding="same",
depthwise_initializer=KERNEL_INITIALIZER,
bias_initializer=BIAS_INITIALIZER,
name="dwconv")
self.norm = layers.LayerNormalization(epsilon=1e-6, name="norm")
self.pwconv1 = layers.Dense(4 * dim,
kernel_initializer=KERNEL_INITIALIZER,
bias_initializer=BIAS_INITIALIZER,
name="pwconv1")
self.act = layers.Activation("gelu")
self.pwconv2 = layers.Dense(dim,
kernel_initializer=KERNEL_INITIALIZER,
bias_initializer=BIAS_INITIALIZER,
name="pwconv2")
self.drop_path = layers.Dropout(drop_rate, noise_shape=(None, 1, 1, 1)) if drop_rate > 0 else None
def build(self, input_shape):
if self.layer_scale_init_value > 0:
self.gamma = self.add_weight(shape=[input_shape[-1]],
initializer=initializers.Constant(self.layer_scale_init_value),
trainable=True,
dtype=tf.float32,
name="gamma")
else:
self.gamma = None
def call(self, x, training=False):
shortcut = x
x = self.dwconv(x)
x = self.norm(x, training=training)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
if self.drop_path is not None:
x = self.drop_path(x, training=training)
return shortcut + x
class Stem(layers.Layer):
def __init__(self, dim, name: str = None):
super().__init__(name=name)
self.conv = layers.Conv2D(dim,
kernel_size=4,
strides=4,
padding="same",
kernel_initializer=KERNEL_INITIALIZER,
bias_initializer=BIAS_INITIALIZER,
name="conv2d")
self.norm = layers.LayerNormalization(epsilon=1e-6, name="norm")
def call(self, x, training=False):
x = self.conv(x)
x = self.norm(x, training=training)
return x
class DownSample(layers.Layer):
def __init__(self, dim, name: str = None):
super().__init__(name=name)
self.norm = layers.LayerNormalization(epsilon=1e-6, name="norm")
self.conv = layers.Conv2D(dim,
kernel_size=2,
strides=2,
padding="same",
kernel_initializer=KERNEL_INITIALIZER,
bias_initializer=BIAS_INITIALIZER,
name="conv2d")
def call(self, x, training=False):
x = self.norm(x, training=training)
x = self.conv(x)
return x
class ConvNeXt(Model):
r""" ConvNeXt
A Tensorflow impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, num_classes: int, depths: list, dims: list, drop_path_rate: float = 0.,
layer_scale_init_value: float = 1e-6):
super().__init__()
self.stem = Stem(dims[0], name="stem")
cur = 0
dp_rates = np.linspace(start=0, stop=drop_path_rate, num=sum(depths))
self.stage1 = [Block(dim=dims[0],
drop_rate=dp_rates[cur + i],
layer_scale_init_value=layer_scale_init_value,
name=f"stage1_block{i}")
for i in range(depths[0])]
cur += depths[0]
self.downsample2 = DownSample(dims[1], name="downsample2")
self.stage2 = [Block(dim=dims[1],
drop_rate=dp_rates[cur + i],
layer_scale_init_value=layer_scale_init_value,
name=f"stage2_block{i}")
for i in range(depths[1])]
cur += depths[1]
self.downsample3 = DownSample(dims[2], name="downsample3")
self.stage3 = [Block(dim=dims[2],
drop_rate=dp_rates[cur + i],
layer_scale_init_value=layer_scale_init_value,
name=f"stage3_block{i}")
for i in range(depths[2])]
cur += depths[2]
self.downsample4 = DownSample(dims[3], name="downsample4")
self.stage4 = [Block(dim=dims[3],
drop_rate=dp_rates[cur + i],
layer_scale_init_value=layer_scale_init_value,
name=f"stage4_block{i}")
for i in range(depths[3])]
self.norm = layers.LayerNormalization(epsilon=1e-6, name="norm")
self.head = layers.Dense(units=num_classes,
kernel_initializer=KERNEL_INITIALIZER,
bias_initializer=BIAS_INITIALIZER,
name="head")
def call(self, x, training=False):
x = self.stem(x, training=training)
for block in self.stage1:
x = block(x, training=training)
x = self.downsample2(x, training=training)
for block in self.stage2:
x = block(x, training=training)
x = self.downsample3(x, training=training)
for block in self.stage3:
x = block(x, training=training)
x = self.downsample4(x, training=training)
for block in self.stage4:
x = block(x, training=training)
x = tf.reduce_mean(x, axis=[1, 2])
x = self.norm(x, training=training)
x = self.head(x)
return x
def convnext_tiny(num_classes: int):
model = ConvNeXt(depths=[3, 3, 9, 3],
dims=[96, 192, 384, 768],
num_classes=num_classes)
return model
def convnext_small(num_classes: int):
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[96, 192, 384, 768],
num_classes=num_classes)
return model
def convnext_base(num_classes: int):
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[128, 256, 512, 1024],
num_classes=num_classes)
return model
def convnext_large(num_classes: int):
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[192, 384, 768, 1536],
num_classes=num_classes)
return model
def convnext_xlarge(num_classes: int):
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[256, 512, 1024, 2048],
num_classes=num_classes)
return modeltrain.py------ConvNeXt网络训练:
注意权重文件提前下载,本文打包数据也包含权重
import os
import re
import sys
import datetime
import tensorflow as tf
from tqdm import tqdm
from model import convnext_tiny as create_model#选用T/S/B/L/XL模型
from utils import generate_ds, cosine_scheduler
#assert tf.version.VERSION >= "2.4.0", "version of tf must greater/equal than 2.4.0"
def main():
data_root = "./data_set/Junk_data_sets" # get data root path
#产生权重文件
if not os.path.exists("./save_weights"):
os.makedirs("./save_weights")
batch_size = 8
epochs = 10
num_classes = 6 # 分类数目
freeze_layers = False
initial_lr = 0.005
weight_decay = 5e-4
#生成并保存日志
log_dir = "./logs/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_writer = tf.summary.create_file_writer(os.path.join(log_dir, "train"))
val_writer = tf.summary.create_file_writer(os.path.join(log_dir, "val"))
# data generator with data augmentation 具有数据增强功能的数据生成器
train_ds, val_ds = generate_ds(data_root, batch_size=batch_size, val_rate=0.2)
# create model
model = create_model(num_classes=num_classes)
model.build((1, 224, 224, 3))
# 下载我提前转好的预训练权重
# 链接: https://pan.baidu.com/s/1MtYJ3FCAkiPwaMRKuyZN1Q 密码: 1cgp
# load weights
pre_weights_path = './convnext_tiny_1k_224.h5'
assert os.path.exists(pre_weights_path), "cannot find {}".format(pre_weights_path)
model.load_weights(pre_weights_path, by_name=True, skip_mismatch=True)
# freeze bottom layers
if freeze_layers:
for layer in model.layers:
if "head" not in layer.name:
layer.trainable = False
else:
print("training {}".format(layer.name))
model.summary()
# custom learning rate scheduler
scheduler = cosine_scheduler(initial_lr, epochs, len(train_ds), train_writer=train_writer)
# using keras low level api for training
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.SGD(learning_rate=initial_lr, momentum=0.9)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
val_loss = tf.keras.metrics.Mean(name='val_loss')
val_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='val_accuracy')
@tf.function
def train_step(train_images, train_labels):
with tf.GradientTape() as tape:
output = model(train_images, training=True)
ce_loss = loss_object(train_labels, output)
# l2 loss
matcher = re.compile(".*(bias|gamma|beta).*")
l2loss = weight_decay * tf.add_n([
tf.nn.l2_loss(v)
for v in model.trainable_variables
if not matcher.match(v.name)
])
loss = ce_loss + l2loss
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(ce_loss)
train_accuracy(train_labels, output)
@tf.function
def val_step(val_images, val_labels):
output = model(val_images, training=False)
loss = loss_object(val_labels, output)
val_loss(loss)
val_accuracy(val_labels, output)
best_val_acc = 0.
for epoch in range(epochs):
train_loss.reset_states() # clear history info
train_accuracy.reset_states() # clear history info
val_loss.reset_states() # clear history info
val_accuracy.reset_states() # clear history info
# train
train_bar = tqdm(train_ds, file=sys.stdout)
for images, labels in train_bar:
# update learning rate
optimizer.learning_rate = next(scheduler)
train_step(images, labels)
# print train process
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}, acc:{:.3f}, lr:{:.5f}".format(
epoch + 1,
epochs,
train_loss.result(),
train_accuracy.result(),
optimizer.learning_rate.numpy()
)
# validate
val_bar = tqdm(val_ds, file=sys.stdout)
for images, labels in val_bar:
val_step(images, labels)
# print val process
val_bar.desc = "valid epoch[{}/{}] loss:{:.3f}, acc:{:.3f}".format(epoch + 1,
epochs,
val_loss.result(),
val_accuracy.result())
# writing training loss and acc
with train_writer.as_default():
tf.summary.scalar("loss", train_loss.result(), epoch)
tf.summary.scalar("accuracy", train_accuracy.result(), epoch)
# writing validation loss and acc
with val_writer.as_default():
tf.summary.scalar("loss", val_loss.result(), epoch)
tf.summary.scalar("accuracy", val_accuracy.result(), epoch)
# only save best weights
if val_accuracy.result() > best_val_acc:
best_val_acc = val_accuracy.result()
save_name = "./save_weights/model.ckpt"
model.save_weights(save_name, save_format="tf")
if __name__ == '__main__':
main()
predict.py-----ConvNeXt网络预测结果
这个函数刚开是比较有用,后期程序不会用到这个程序
import os
import json
import glob
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
from model import convnext_tiny as create_model
def main():
num_classes = 6
im_height = im_width = 224
# load image
#img_path = "D:/pyc_workspace/TF2.11/test/testSun.png"
img_path = "D:/pyc_workspace/TF2.11/data_set/Junk_data_sets/test/testTrash.jpg"
# testGlass.jpg testMetal.jpg testPlastic.jpg testPaper.jpg testTrash.jpg
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
# resize image
img = img.resize((im_width, im_height))
plt.imshow(img)
# read image
img = np.array(img).astype(np.float32)
# preprocess
img = (img / 255. - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img, 0))
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = create_model(num_classes=num_classes)
model.build([1, 224, 224, 3])
weights_path = './save_weights/model.ckpt'
assert len(glob.glob(weights_path+"*")), "cannot find {}".format(weights_path)
model.load_weights(weights_path)
result = np.squeeze(model.predict(img, batch_size=1))
result = tf.keras.layers.Softmax()(result)
predict_class = np.argmax(result)
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_class)],
result[predict_class])
plt.title(print_res)
for i in range(len(result)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
result[i]))
plt.show()
if __name__ == '__main__':
main()cappredict.py
基于predict.py增加了一个函数update_transh_num(num),使用这个库在主程序中完成检测任务。
该函数用于存储分类垃圾的历史,每次启动重置所有垃圾数量为0,垃圾种类为4
每次识别成功将数据写入update_transh_num.txt
"""
time:2024.4.22
author:wisdom
intruduction:
基于predict.py增加了一个函数update_transh_num(num)
该函数用于存储分类垃圾的历史,每次启动重置所有垃圾数量为0,垃圾种类为4
每次识别成功将数据写入update_transh_num.txt
"""
import os
import json
import glob
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
from model import convnext_tiny as create_model
from cap import cap_transh,get_img
def main(cap_img_path):
num_classes = 6
im_height = im_width = 224
# load image
img_path = cap_img_path
# testGlass.jpg testMetal.jpg testPlastic.jpg testPaper.jpg testTrash.jpg
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
# resize image
img = img.resize((im_width, im_height))
plt.imshow(img)
# read image
img = np.array(img).astype(np.float32)
# preprocess
img = (img / 255. - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225]
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img, 0))
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = create_model(num_classes=num_classes)
model.build([1, 224, 224, 3])
weights_path = './save_weights/model.ckpt'
assert len(glob.glob(weights_path+"*")), "cannot find {}".format(weights_path)
model.load_weights(weights_path)
result = np.squeeze(model.predict(img, batch_size=1))
result = tf.keras.layers.Softmax()(result)
predict_class = np.argmax(result)
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_class)],
result[predict_class])
print('<-------分类结果------->')
print(print_res)
print('<------------------------->')
transh_list=[predict_class,class_indict[str(predict_class)]]
return transh_list
def update_transh_num(num):
update_list = []
with open('update_transh_num.txt', 'r') as f:
for each_line in f:
update_list.append(int(each_line))
if len(update_list) != 4:
update_list = [0, 0, 0, 0]
update_list[num] = update_list[num] + 1
with open('update_transh_num.txt', 'w') as f:
f.write(str(update_list[0]))
for i in range(3):
f.write('\n' + str(str(update_list[i + 1])))
def rubbish2Classification(transh):
#4个垃圾的分类表,发别是可回收垃圾,有害垃圾,厨余垃圾,其他垃圾0
recyclable_waste=['galss','metal','paper','plastic']
kitchen_waste=['orange']
other_waste=['wastePaper','palsticBag','transh']
#hazardous_waste = ['battery']
if (transh in recyclable_waste):
return 0
elif (transh in kitchen_waste):
return 1
elif (transh in other_waste):
return 2
else:
return 3
if __name__ == '__main__':
cap_transh(r"D:\pyc_workspace\TF2.11\cap_photos",1)
file_name=get_img()
transh=main(file_name)
update_transh_num(rubbish2Classification(transh[1]))
print(transh)
cap.py
1.启动摄像头拍照并按序列命名,最后储存指定路径 2.返回最新图片路径地址 会产生两个配置文件: num_of_cap.txt:图片序列存放索引 D:\pyc_workspace\TF2.11\cap_photos:图片存放路径
"""
time:2024.4.22
author:wisdom
intruduction:
1.启动摄像头拍照并按序列命名,最后储存指定路径
2.返回最新图片路径地址
会产生两个配置文件:
num_of_cap.txt:图片序列存放索引
D:\pyc_workspace\TF2.11\cap_photos:图片存放路径
"""
import cv2
import os
def cap_transh(output_dir,flag=1):#flag=1正常拍照,非1清除数据
if flag != 1:
with open('num_of_cap.txt', 'w') as f:
for file in os.listdir(output_dir):
# 构建文件的完整路径
file_path = os.path.join(output_dir, file)
# 如果是文件,则删除
os.remove(file_path)
print("已删除文件:", file_path)
print("!清除所有内容!")
num = []
with open('num_of_cap.txt','r') as f:
for each_line in f:
num.append(int(each_line))
print(num)
if len(num)==0:
num_max=0
else:
num_max = max(num)
camera = cv2.VideoCapture(0) # 摄像头序号
if not camera.isOpened():
print("无法打开摄像头")
return
success, frame = camera.read()
camera.release()
print("cap_ing!")
num_max = num_max + 1
print(output_dir+r'\cap_'+str(num_max)+'.jpg')
file_name = str(output_dir+r'\cap_'+str(num_max)+'.jpg')
cv2.imwrite(file_name,frame)
with open('num_of_cap.txt', 'a') as f:
if len(num)==0:
f.write(str(num_max))
else:
f.write('\n' + str(num_max))
def get_img():
num=[]
output_dir=r"D:\pyc_workspace\TF2.11\cap_photos"
with open('num_of_cap.txt','r') as f:
for each_line in f:
num.append(int(each_line))
print(num)
if len(num)==0:
num_max=0
else:
num_max = max(num)
file_name = str(output_dir+r'\cap_'+str(num_max)+'.jpg')
#返回照片的地址
return file_name
if __name__ == '__main__':
cap_transh(r"D:\pyc_workspace\TF2.11\cap_photos")
str = get_img()
print(str)
new_cun.py
序与arduino进行串行通信,初始化上端机端口, 并向arduino发送舵机控制数据,并接收,分析超声波测距模块的数据, 并作出警示
"""
time:2023.3.13
author:wisdom
intruduction:程序与arduino进行串行通信,初始化上端机端口,
并向arduino发送舵机控制数据,并接收,分析超声波测距模块的数据,
并作出警示,无中断版本(使用中断效果不佳)
"""
import serial
import time
import os
#import music
def initConnection(portNo,baudRate):
try:
ser = serial.Serial(portNo,baudRate)#portNo:端口地址;baudRate:波特率
print("Device Connectde")
return ser
except:
print("Not Connectde")
def sendData(se,data,digits):
myString = "$"
for d in data:
myString += str(d).zfill(digits)#25填充为025;
try:
se.write(myString.encode())
print(myString)
except:
print("Data Transmission Failed!")
def control_dirction(ser,trach):
if (trach==0):
time.sleep(1)
sendData(ser, [88, 000], 3)
time.sleep(1)
sendData(ser, [140, 000], 3)
time.sleep(1)
sendData(ser, [88, 000], 3)
time.sleep(1)
elif(trach==1):
time.sleep(1)
sendData(ser, [88, 90], 3)
time.sleep(1)
sendData(ser, [140, 90], 3)
time.sleep(1)
sendData(ser, [88, 000], 3)
time.sleep(1)
elif (trach == 2):
time.sleep(1)
sendData(ser, [88, 180], 3)
time.sleep(1)
sendData(ser, [140, 180], 3)
time.sleep(1)
sendData(ser, [88, 000], 3)
time.sleep(1)
else:
time.sleep(1)
sendData(ser, [88, -90], 3)
time.sleep(1)
sendData(ser, [140, -90], 3)
time.sleep(1)
sendData(ser, [88, 000], 3)
time.sleep(1)
def rangeing(ser,flag):
sendData(ser, [888, flag*100+flag*10+flag], 3)
time.sleep(1)
try:
data = ser.read(1)#字符串
print(data)
time.sleep(1)
data=int(data)
if data!=0:#data==flag:
print("warning!"+str(flag))
os.system('play output.wav')
else:
print('prefect!')
except: #serial.SerialTimeoutException:
print("time out!")
finally:
ser.close()
def begin():#调用初始化
ser = initConnection("/dev/ttyUSB0", 9600) # linux
#自检
time.sleep(2)
sendData(ser, [666, 666], 3)
return ser
if __name__ =="__main__":
#ser = initConnection("/dev/ttyUSB0",9600)#linux
ser = initConnection("COM4",9600)#windows
time.sleep(2)
sendData(ser, [666, 666], 3)
time.sleep(2)
for i in range(4):
control_dirction(ser, i)
main.py
这里是垃圾分类的主程序,主要完成图形界面,更新图形界面的信息
"""
time:2024.4.22
author:wisdom
intruduction:
这里是垃圾分类的主程序,主要完成图形界面
"""
import tkinter as tk
import serial
import time
from PIL import Image, ImageTk
from cappredict import main,update_transh_num,rubbish2Classification
from cap import cap_transh,get_img
from new_cum import initConnection,sendData,control_dirction
class LoginApp:
def __init__(self, root):
self.root = root
self.root.title("登录")
self.root.geometry("400x200") # 设置窗口大小
self.label_username = tk.Label(root, text="用户名:")
self.label_password = tk.Label(root, text="密码:")
self.entry_username = tk.Entry(root)
self.entry_password = tk.Entry(root, show="*")
self.button_login = tk.Button(root, text="登录", command=self.login)
self.label_username.grid(row=0, column=0, padx=10, pady=10, sticky=tk.E)
self.entry_username.grid(row=0, column=1, padx=10, pady=10)
self.label_password.grid(row=1, column=0, padx=10, pady=10, sticky=tk.E)
self.entry_password.grid(row=1, column=1, padx=10, pady=10)
self.button_login.grid(row=2, column=0, columnspan=2, pady=10)
def login(self):
# 假设用户名为 "admin",密码为 "password" 才能登录成功
if self.entry_username.get() == "hnnu" and self.entry_password.get() == "123":
self.root.destroy() # 关闭登录窗口
app = ClassificationApp() # 进入分类界面
app.mainloop()
else:
print("登录失败")
class ClassificationApp(tk.Tk):
def __init__(self):
super().__init__()
self.title("垃圾分类")
self.geometry("500x400") # 设置窗口大小
self.labels = []
self.entries = []
trash_types = ["可回收垃圾", "厨余垃圾", "其他垃圾", "有害垃圾"]
# 添加6个文本框和标签
for i, trash_type in enumerate(trash_types):
label = tk.Label(self, text=f"{trash_type}:")
label.grid(row=i, column=0, padx=10, pady=10, sticky=tk.E)
entry = tk.Entry(self, width=10)
entry.insert(tk.END, "0")
entry.grid(row=i, column=1, padx=10, pady=10)
self.labels.append(label)
self.entries.append(entry)
# 添加分类按钮和退出按钮
self.button_classify = tk.Button(self, text="分类", command=self.classify)
self.button_classify.grid(row=7, column=0, padx=10, pady=10)
self.button_exit = tk.Button(self, text="退出", command=self.quit)
self.button_exit.grid(row=7, column=1, padx=10, pady=10)
# 加载初始图片
self.image_path = r"D:\pyc_workspace\TF2.11\test\hnnu.jpg"
self.load_image(self.image_path)
with open('update_transh_num.txt', 'w') as f:
print("分类信息清零!")
def classify(self):
cap_transh(r"D:\pyc_workspace\TF2.11\cap_photos", 1)
file_name = get_img()
transh = main(file_name)
update_transh_num(rubbish2Classification(transh[1]))
print(transh)
ser = initConnection("COM4", 9600) # windows
time.sleep(1.8)
sendData(ser, [666, 666], 3)
#time.sleep(2)
# 这里假设分类结果为一个列表,包含了每种垃圾的数量,例如 [3, 5, 2, 0, 1, 4]
classification_result=[]
with open('update_transh_num.txt', 'r') as f:
for each_line in f:
classification_result.append(int(each_line))
#classification_result = [3, 5, 2, 0, 1, 4]
# 更新文本框后面的数量
for i, value in enumerate(classification_result):
self.entries[i].delete(0, tk.END)
self.entries[i].insert(tk.END, str(value))
# 更新图片
self.image_path = get_img()
self.load_image(self.image_path)
control_dirction(ser, rubbish2Classification(transh[1]))
ser.close()
def load_image(self, image_path):
try:
with Image.open(image_path) as img:
img = img.resize((300, 300)) # 调整图像大小以适应标签
photo = ImageTk.PhotoImage(img)
self.image_label = tk.Label(self, image=photo)
self.image_label.image = photo
self.image_label.grid(row=0, column=2, rowspan=7, padx=10, pady=10)
except Exception as e:
print("Error loading image:", e)
if __name__ == "__main__":
root = tk.Tk()
app = LoginApp(root)
root.mainloop()
ele_flag.c
使用C语言编写用于arduino与PC进行通信,通信协议为串口
//最终版本
#include <MsTimer2.h>
#include <Wire.h>
#define I2C_ADDR 0x2D
#define numOfValRec 2//值的数量
#define digitsPerValRec 3//值的位数,例如255,007
#define test_num 8
int valsRec[numOfValRec];//接受数组
int stringLength = numOfValRec*digitsPerValRec + 1;//数组长度,+1式$的验证
int counter = 0;
bool counterStart = false;
String recString;
bool test_flag = false;
const int TrigPin = 4;
const int EchoPin = 3;
float range_flag=0;//储存超声波测距数据的变量
void setup() {
Wire.begin();
pinMode(TrigPin, OUTPUT);
pinMode(EchoPin, INPUT);
Serial.begin(9600);
}
void recData()//串口通信接受
{
while(Serial.available())
{
char c = Serial.read();
if (c == '$')
{
counterStart = true;
}
if(counterStart)
{if(counter<stringLength)
{
recString = String(recString + c);
counter++;
}
if(counter >=stringLength )
{
for(int i =0;i<numOfValRec;i++)
{
int num = (i*digitsPerValRec) +1 ;
valsRec[i] = recString.substring(num,num+digitsPerValRec).toInt();
}
recString = "";
counter = 0;
counterStart=false;
}
}
}
}
bool I2CWrite(unsigned char reg_addr,unsigned char date)//IIC舵机控制
{
Wire.beginTransmission(I2C_ADDR); //发送Device地址
Wire.write(reg_addr); //发送要操作的舵机
Wire.write(date); //发送要设置的角度
if(Wire.endTransmission()!=0) //发送结束信号
{
delay(10);
return false;
}
delay(10);
return true;
}
float range()//超声波测距,距离储存在float中
{
float cm;
unsigned char i;
int rang_value[5];
for(i=0;i<5;i++)
{
digitalWrite(TrigPin, LOW);
delayMicroseconds(2);
digitalWrite(TrigPin, HIGH);
delayMicroseconds(10);
digitalWrite(TrigPin, LOW);
cm = pulseIn(EchoPin, HIGH) / 58.0; //算成厘米
cm = (int(cm * 100.0)) / 100.0; //保留两位小数
rang_value[i]=cm;
//delay(100);
}
cm = 0;
for(i=0;i<5;i++)
{
cm = rang_value[i] + cm;
}
cm = cm/5.0;
return cm;
}
void loop() {
recData();
if((valsRec[0]==666) && (valsRec[1]==666))//$666666 自检查
{
I2CWrite(1,90);
I2CWrite(2,0*2/3);
delay(500);
test_flag = true;
}
else if((valsRec[0]==888) && (test_flag))
{
if(valsRec[1]==111)//检测垃圾桶1是否满载
{
I2CWrite(2,0*2/3);
delay(500);
range_flag = range();
if(range_flag<=test_num)//串口发送1
{
Serial.print(1);
}
else
{Serial.print(0);}
}
else if(valsRec[1]==222)//检测垃圾桶2是否满载
{
I2CWrite(2,90*2/3);
delay(500);
range_flag = range();
if(range_flag<=test_num)//串口发送2
{
Serial.print(2);
}
else
{Serial.print(0);}
}
else if(valsRec[1]==333)//检测垃圾桶3是否满载
{
I2CWrite(2,180*2/3);
delay(500);
range_flag = range();
if(range_flag<=test_num)//串口发送3
{
Serial.print(3);
}
else
{Serial.print(0);}
}
else if(valsRec[1]==444)//检测垃圾桶4是否满载
{
I2CWrite(2,270*2/3);
delay(500);
range_flag = range();
//Serial.println(range_flag);
if(range_flag<=test_num)//串口发送4
{
Serial.print(4);
}
else
{
Serial.print(0);
}
//valsRec[0]=90;
//valsRec[1]=270;
}
}
else if((test_flag) && (valsRec[0]!=888) )
{
I2CWrite(1,valsRec[0]);//设置舵机S1角度valsRec[0]
I2CWrite(2,valsRec[1]*2/3);//设置舵机S1角度valsRec[1]*2/3,因为S2是270舵机
delay(500);
}
}

















 126
126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









