






DeepSeek系列论文解读二之DeepSeek V3
DeepSeek V3
DeepSeek-V3 Technical Report
原文:https://arxiv.org/abs/2412.19437
总结
DeepSeek-V3是一个大型的专家混合(MoE)语言模型,总共有671B个参数,每个令牌激活37B个参数。它采用了多头潜在注意力(MLA)和DeepSeekMoE架构进行高效推理和经济高效的训练,这些在DeepSeek-V2中得到了验证。DeepSeek-V3还开创了一种无辅助损失策略来实现负载平衡,并使用多令牌预测训练目标来提高性能。该模型是在140万亿个高质量多样的令牌上预训练的,然后进行了监督微调和强化学习阶段。全面的评估表明,DeepSeek-V3的性能优于其他开源模型,并且与领先的闭源模型相当,但只需要2.788M个H800 GPU小时就可以完成完整的训练。
论文研究问题
论文的主要目标是实现高效的推理和成本效益的训练。为了解决这些问题,论文提出了以下几个关键点:
-
架构优化:DeepSeek-V3采用了多头潜在注意力(Multi-head Latent Attention,MLA)和DeepSeekMoE架构,这些在DeepSeek-V2中已经得到了验证,能够保持模型性能的同时实现高效的训练和推理。

-
无辅助损失的负载均衡策略:为了解决模型性能因负载均衡而退化的问题,DeepSeek-V3引入了一种无辅助损失的负载均衡策略,以最小化因鼓励负载均衡而对模型性能产生的不利影响。
-
多标记预测训练目标:DeepSeek-V3采用了多标记预测(Multi-Token Prediction,MTP)训练目标,这被观察到可以增强模型在评估基准上的整体性能。

-
高效的训练支持:支持 FP8 计算和存储,加速训练并减少 GPU 内存使用。设计 DualPipe 算法实现高效的流水线并行处理,通过计算-通信重叠减少通信开销。
-
预训练和上下文扩展:DeepSeek-V3在14.8万亿高质量和多样化的标记上进行预训练,并进行了两阶段的上下文长度扩展,以增强模型处理长上下文的能力。
-
后训练优化:包括监督式微调和强化学习,以进一步解锁模型潜力,并使其与人类偏好对齐。
-
经济高效的训练成本:尽管性能出色,DeepSeek-V3的训练成本仅为2.788M H800 GPU小时,训练过程非常稳定,没有经历任何不可恢复的损失峰值或回滚。
论文实验以及相关技术
架构和训练策略评估
-
无辅助损失的负载均衡策略 :通过与传统的辅助损失方法对比,验证了无辅助损失策略在保持模型性能的同时实现负载均衡的有效性。

-
多标记预测(MTP)策略 :在不同规模的模型上应用MTP策略,并与其他基线模型比较,评估MTP对模型性能的影响。
 ### 基础设施和训练框架测试
### 基础设施和训练框架测试 -
DualPipe算法 :通过实验验证了DualPipe算法在减少流水线气泡和隐藏通信开销方面的效率
-
跨节点All-to-All通信 : 测试了定制的跨节点All-to-All通信核的性能,确保高效的通信和计算重叠
-
内存占用优化 : RMSNorm 和 MLA 向上投影的重计算,CPU 中的指数移动平均(EMA),多令牌预测的共享嵌入和输出头
-
FP8混合精度训练框架 :在不同规模的模型上应用FP8训练,并与传统的BF16训练对比,验证FP8训练框架的有效性和准确性。
预训练和上下文扩展
- 长上下文扩展 :通过两阶段的上下文长度扩展训练,验证模型处理长上下文的能力,并在“Needle In A Haystack”测试中评估模型性能。
后训练优化
-
监督微调(SFT) :在多个领域的数据集上进行微调,评估模型在特定任务上的性能提升。
-
强化学习(RL) : 通过使用不同的奖励模型和策略优化,测试模型在对齐人类偏好和提升性能方面的有效性。
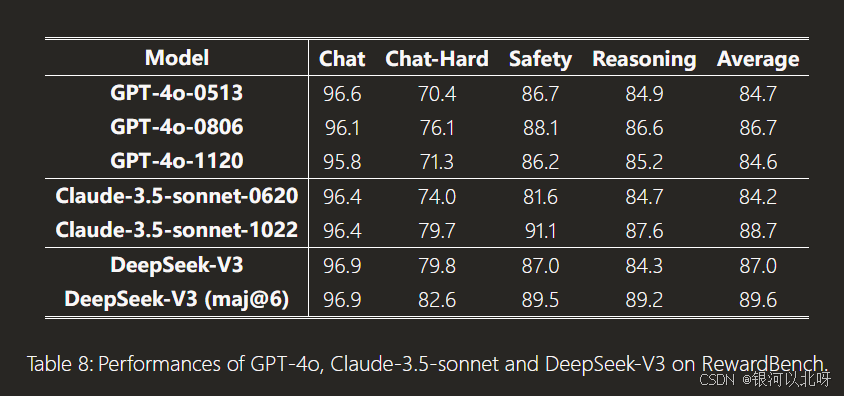 ### 综合基准测试
### 综合基准测试 -
多语言和多领域评估 : DeepSeek-V3 在一系列包括教育、语言理解、问答、编程和数学等多个领域的标准和开放式基准测试中进行了评估,并与当前最强的开源和闭源模型进行比较。(具体可见原文4.4 5.3)
经济性分析
- 训练成本分析 :分析DeepSeek-V3的总训练成本,包括预训练、上下文扩展和后训练阶段的GPU小时数和成本。
 ### 硬件设计建议
### 硬件设计建议
GPU小时数和成本。[外链图片转存中…(img-IPJWStGi-1739462810361)]
硬件设计建议
- 通信和计算硬件的优化 : 基于DeepSeek-V3的实施经验,提出针对未来AI硬件设计的通信和计算硬件的建议。这些实验和评估不仅验证了DeepSeek-V3模型的技术策略和性能,还展示了其在多个领域的应用潜力和经济效益。通过这些综合测试,论文全面展示了DeepSeek-V3作为当前最强开源模型的能力。

















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









