






首先Qiu博士的这篇论文是在21年发表的,23年还有一篇新的文章也是在这篇文章的基础上进行技术革新得到的,但是两篇文章中都有提到了分层语义树的概念且围绕着这一概念做出的许多改进最早都是来自于该篇。
一开始我是在拜读另一篇文章Behavioral-Semantic Privacy Protection for Continual Social Mobility in Mobile-Internet Services。这篇文章中在分层语义树模块引用了先前的工作即该篇文章,因此我也阅读了这篇论文。
这篇文章提出了一个移动语义感知隐私模型MSP,通过构建分层语义树,在此基础上可以根据生成的分层语义树进行隐私敏感度的评估,同时根据已生成的个人的分层语义树可以合成具有语义感知的合成轨迹。
因此,整篇论文都离不开一个点,就是如何构建分层语义树。
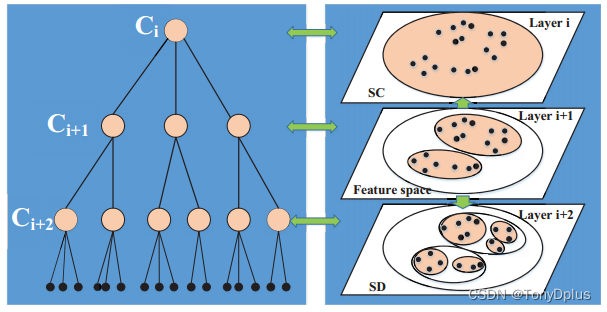
这是论文中构建出来的效果图,其流程为:
首先,根据语义特征,将地点进行聚类,形成中间层。这些地点被聚类为具有相似语义特征的群组,如学校、健身房等。
然后,从中间层开始,进行向上的语义概括操作,逐步生成更一般的语义类别,直到生成根节点。
同时,从中间层开始,进行向下的语义细化操作,根据停留时间特征(SD)将节点进一步细分为具体的子类。
最终,生成具有特定层数的层次深层语义树。
可以理解为除了根节点外,其他节点都代表着具体的语义类别。根节点代表了整体的移动语义,而其他节点则代表了更具体的移动语义类别。在根节点之下的节点是通过停留时间特征对停留点进行聚类而得到的,而在根节点之上的节点则是通过对聚类结果进行向上的语义概括而得到的,反映了更一般的语义类别。同时最后的叶子结点为用户访问过的,具体的停留点所代表的语义类别。同时因为停留时间聚类的缘故,具有相似停留时间且语义相近的点更会出现在同一个节点的叶子结点。
有了语义树,可以进行多种操作:

将语义敏感向量中每个语义类别的权重映射到一个合适的层数,使得每个权重对应的层数能够充分表达用户对位置隐私的个性化需求。
整体而言MRS位置隐私保护基于深层语义树,分为以下步骤:
构建深层语义树:根据用户个人轨迹和POI库,构建深层语义树。将访问的POI视为叶节点,将聚类后的POI视为内部节点。距离根节点越近的节点具有更广泛的语义属性。
适应性隐私保护机制:通过迭代执行的过程,将当前停留点映射到适当的叶节点,并将位置的隐私敏感性映射到语义树中的层数,以概括移动语义。
语义树的回溯操作:从叶节点回溯到内部节点,确定内部节点和语义候选集。语义候选集包含了所有内部节点的叶节点所对应的具有相似移动语义的POI。
K-匿名集合构建:在一定区域内筛选语义候选集,并根据最近邻原则构建K-匿名集合,以保护当前停留点的位置隐私。
选择伪造位置:从构建的K-匿名集合中随机选择一个POI作为伪造位置,用于保护实际停留点的位置隐私。















 4343
4343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









