







目录
(2) Model类self._load——加载定义好的模型
(2) YOLO类下的self.task_map——便捷加载预先定义好的模型
2.详解DetectionModel中parse_model加载模型
在上篇文章中记录了如何下载yolov8源码、环境安装配置和模型的一些官方给出的基本使用方法——文章链接:从零开始使用YOLOv8——环境配置与极简指令(CLI)操作
尽管官方给出的微调训练已经具有非常好的拓展应用性能,但对于一些特殊任务,可能需要更底层的代码修改(如进行强化学习的部署训练),此时需要对源码进行理解筛选,选出需要的模型源码部分进行复现。
本系列主要精力集中在对模型源码的使用上,不对其背后原理进行探究,旨在使用pycharm的debug功能了解yolov8实现功能的每一个流程步骤的顺序和其对应的功能函数。本部分专注于模型的加载部分代码,后续将继续对模型的预测和训练等进行解析。

一、模型加载流程
ultralytics支持多种加载模型的方式,应当前项目实际需要,此处只针对其中的两种数据格式——.pt 文件和 .yaml 文件。下面是根据官方文档使用设计的一个简单的模型加载测试代码。
from ultralytics import YOLO
# pt文件加载模型
yolo_pt_weights = './yolo_weights/best.pt'
yolo_model_pt = YOLO(model=yolo_pt_weights)
# yaml文件加载模型
yolo_yaml_weights = './yolo_weights/yolov8.yaml'
yolo_model_yaml = YOLO(model=yolo_yaml_weights)
1.一图总览
下图简略展示了YOLO模型两种加载模型方式的流程图。不同颜色的大方框代表其使用的不同的基本类信息。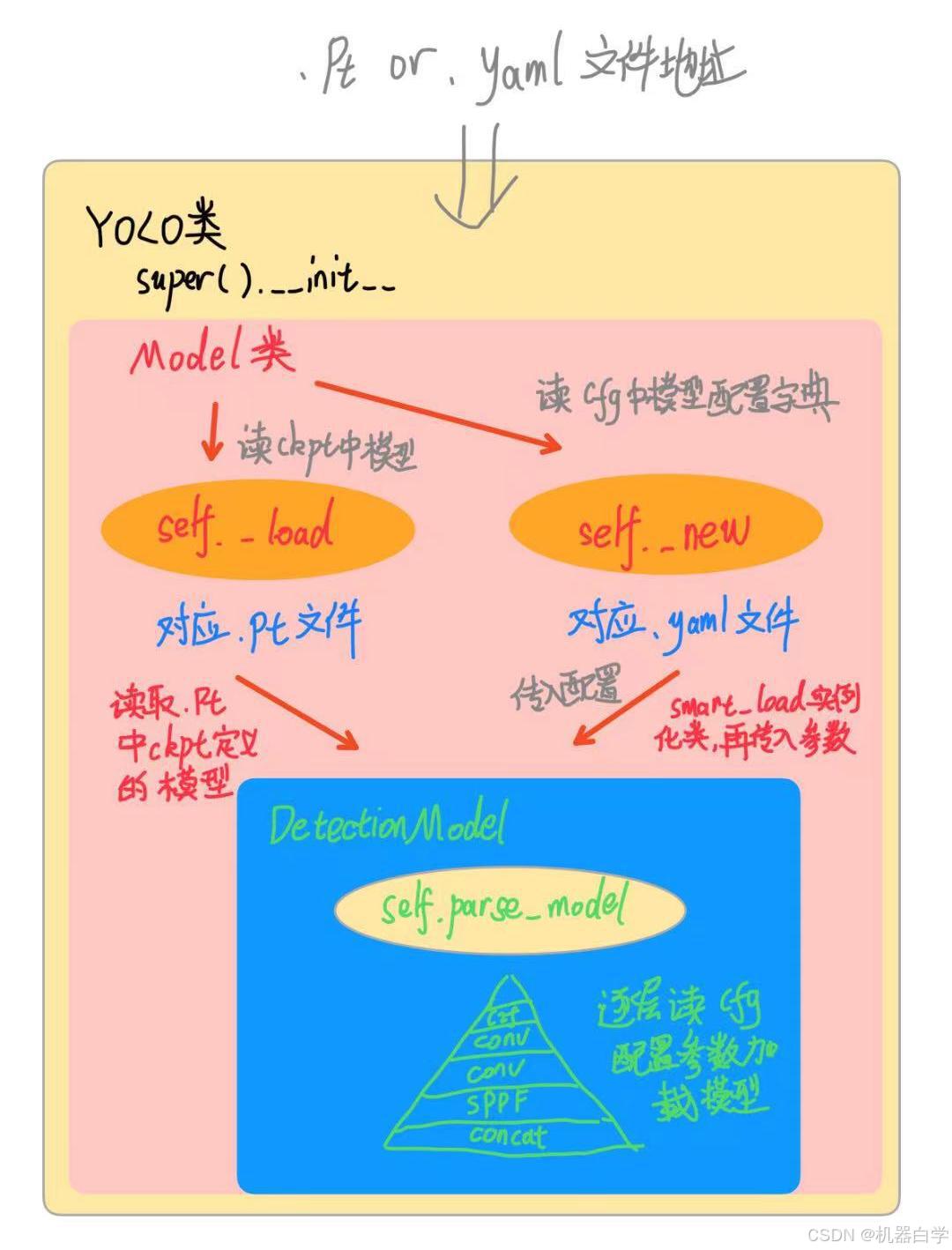
2. pt文件部署模型加载方式
这里的pt文件一般指的是根据官方训练教程得到的结果文件best.pt,这在模型部署时会加载使用的参数文件方式。
根据测试代码,在加载pt格式模型处设置红色暂停点,debug进入其中引用的文件和类。

(1) YOLO类
模型加载使用的最外层的类YOLO,写在 ultralytics/models/yolo/model.py 文件内,其在模型加载中的作用是初始化传参入其父类——Model类

(2) Model类self._load——加载定义好的模型
Model类基于nn.Module神经网络torch类,其在初始化模型加载中,主要功能是使用到自身的定义的self._load函数。Model 类定义在ultralytics/engine/model.py 中。


进入self._load函数,其主要功能是如果输入数据格式是'.pt',就使用utralytics/nn/task.py中的函数 attempt_load_one_weight 获得模型并设为Model的属性self.model,以及ckpt检查点信息。

(3) DetectionModel类
attempt_load_one_weight 首先通过定义函数torch_safe_load加载出pt文件中 ckpt 信息。通过debug中变量ckpt的信息,可以知道其是什么形式与数据类型。
ckpt 中最重要的就是训练使用的模型信息,这也是后面代码加载模型的关键。可以在debug变量中看到字典中model的值是一个DetectionModel类。

DetectionModel同样定义在当前 ultralytics/nn/task.py 文件中。

DetectionModel初始化中主要功能是在 parse_model 函数中实现,通过传入的模型 yaml 配置文件在torch环境搭建好网络层级结构。
在使用pt文件加载模型时,因为是训练好的模型结果,在训练模型时已经选择模型结构(如选择是yolov8m或者yolov8l)的yaml文件,因此之前从ckpt中获取的DetectionModel是已经初始化好的检测模型类。

首先查看一下模型配置属性 self.yaml 的数据类型和内容。可以通过查看debug中变量得知其是一个字典,保存的信息是写在配置文件yolov8.yaml中的。

由于此处使用pt文件加载时,DetectionModel已经加载好其结构和参数,放在ckpt的字典信息里,因此暂时不深入查看parse_model如何具体解析配置信息加载模型网络层,在下一个使用yaml加载模型处分析。
深入到DetectionModel类以后,基本算是完成了模型的加载了,然后就可以使用YOLO或Model中定义的一些功能函数实现不同目标的使用了。
分析DetectionModel类中属性model的获取方式可知,模型是通过配置文件yolov8.yaml来定义网络结构层次的,这在官方源码/ultralytics/cfg/models地址下有标准文件参考。

3.yaml文件部署模型加载方式
使用yaml加载模型和pt文件加载使用的类和流程是近似的,但yaml加载具有更好的拓展和灵活性。下面主要对yaml加载中使用的特定功能函数进行记录。
首先,在官方的yaml文件基础上,要先选择好要进行的任务类型和模型大小——此处与pt同例采用detect任务和yolov8m规模模型。
from ultralytics import YOLO
# yaml文件加载模型
yolo_yaml_weights = './yolo_weights/yolov8m.yaml'
yolo_model_yaml = YOLO(model=yolo_yaml_weights, task='detect')
(1) Model类self._new——创建新模型
此处是yaml第一个与pt不同分流处,pt在训练时已经加载好模型的结构参数等,因此采用load方式。而yaml是新建模型任务,需要重头开始搭建好模型。
可以在源码中看到,在Model类中定义初始化模型时,yaml使用当前类下的_new 函数。

具体来看,self._new主要靠传入模型或者调用self._smart_load来加载模型self.model

self.smart_load 也是定义在Model类下的功能函数,其也只是调用外部接口函数——self.task_map

(2) YOLO类下的self.task_map——便捷加载预先定义好的模型
task_map定义在外层YOLO类下,本质是一个提前定义好的关于模型的字典,可以根据字典的键直接取出对应模型类然后实例化。

比如此处我们设置任务为detect,初始默认预测那么就取出“model”模型类就好了,这正是smart_load中干的事。
因此yaml与pt加载模式殊途同归,本质都是调用DetectionModel类。
回到之前self._new,此时可以容易理解定义self.model中两个括号的含义了。
第一个括号内代表所要使用的模型类,可以是由外部model参数传入(默认模型外的其他自定义模型),也可以便捷调用已经定义好的几个经典的模型类;
第二个括号是要传入模型类初始化的配置参数,其由编写的yaml和用户选择一些参数决定。

二、DetectionModel类详解
在模型加载流程中,不管是哪种方式,最底层的模型加载逻辑都写在DetectionModel类中(其他模型也都在ultralytics/nn/task.py中),因此本部分记录该类详细的加载过程和逻辑。(其他模型也可以按下述方式解析:结合官方默认配置文件+源码加载信息打印)
剔除其他类的干扰,单独提出DetectionModel加载模型代码。verbose设置true打开模型加载过程中信息的打印。
from ultralytics.nn.tasks import yaml_model_load, DetectionModel
# DetectionModel单独加载模型
yolo_yaml_weights = './yolo_weights/yolov8m.yaml'
cfg_dict = yaml_model_load(yolo_yaml_weights)
DetectionModel(cfg_dict, verbose=True) # verbose是开启模型信息打印
1.基于配置文件和打印信息分析模型架构
首先,根据现有的yaml配置文件和模型加载过程中的打印信息,可以对模型结构有一个大致判断。模型网络层上分为两个大板块,每个板块包含多个模块,模块下是神经网络层级结构。
(1) 配置文件中的模型信息
配置文件中已经将模型网络结构清晰分为两个层次——backbone骨干网络和 head头检测网络,但我个人将最后的head的最后一层独立出来了,这一层是将多尺度的特征图转化到目标分类的类别 [nc] 。对于强化学习任务也许可以锁定前面的层参数,对最后的detect层进行训练,将其改造为输出强化学习的动作预测。

(2) 结合加载打印信息的模型网络分析
结合加载过程中的模型网络打印信息可以更详细的看出模型网络结构和参数配比。
首先看配置中的骨干网络层backbone,其对应打印的前十层信息,主要使用了三个网络模块——Conv(卷积)、C2f(变体残差)、SPPF(金字塔池化)。
在骨干层,图片输入的分辨率不断减小(配置中P1/2代表分辨率减半,例如输入640*640,经过网络层后输出320*320),模型参数量不断变大(打印信息中params参数量)
可以实例初始化一个 DetectionModel 传入一个随机的 torch.tensor,然后在模型预测过程中打印结果形状来观察model对输入的正向传播操作变化。
from ultralytics.nn.tasks import yaml_model_load, DetectionModel
import torch
# 实例化DetectionModel
yolo_yaml_weights = './yolo_weights/yolov8m.yaml'
cfg_dict = yaml_model_load(yolo_yaml_weights)
model = DetectionModel(cfg_dict, verbose=True)
# 传入一个随机tensor模拟3通道640*640分辨率的图片数据
source = torch.rand(1, 3, 640, 640)
print('ultralytics.input.shape', source.shape)
# 使用BaseModel自带的预测函数
result = model.predict(source)为了得到中间过程变量打印结果,需要进入ultralytics/nn/task.py/BaseModel 类中 self.predict函数function中引用的 _predict_once 功能函数。在进入网络层正向操作后,添加一个打印中间过程结果形状的代码。
# 源码添加中间过程打印代码
if type(x)!=list:
print(m.type, x.shape)
else: # 打印detect模块list输出形状
print(m.type, [r.shape for r in x])
由于加载模型也会调用一次当前添加打印的函数,因此查看形状从'ultralytics.input.shape'往后看。

# 1批量3通道640*640分辨率模拟输入——模型中间变量形状结果
ultralytics.input.shape torch.Size([1, 3, 640, 640])
ultralytics.nn.modules.conv.Conv torch.Size([1, 48, 320, 320])
ultralytics.nn.modules.conv.Conv torch.Size([1, 96, 160, 160])
ultralytics.nn.modules.block.C2f torch.Size([1, 96, 160, 160])
ultralytics.nn.modules.conv.Conv torch.Size([1, 192, 80, 80])
ultralytics.nn.modules.block.C2f torch.Size([1, 192, 80, 80])
ultralytics.nn.modules.conv.Conv torch.Size([1, 384, 40, 40])
ultralytics.nn.modules.block.C2f torch.Size([1, 384, 40, 40])
ultralytics.nn.modules.conv.Conv torch.Size([1, 576, 20, 20])
ultralytics.nn.modules.block.C2f torch.Size([1, 576, 20, 20])
ultralytics.nn.modules.block.SPPF torch.Size([1, 576, 20, 20])
torch.nn.modules.upsampling.Upsample torch.Size([1, 576, 40, 40])
ultralytics.nn.modules.conv.Concat torch.Size([1, 960, 40, 40])
ultralytics.nn.modules.block.C2f torch.Size([1, 384, 40, 40])
torch.nn.modules.upsampling.Upsample torch.Size([1, 384, 80, 80])
ultralytics.nn.modules.conv.Concat torch.Size([1, 576, 80, 80])
ultralytics.nn.modules.block.C2f torch.Size([1, 192, 80, 80])
ultralytics.nn.modules.conv.Conv torch.Size([1, 192, 40, 40])
ultralytics.nn.modules.conv.Concat torch.Size([1, 576, 40, 40])
ultralytics.nn.modules.block.C2f torch.Size([1, 384, 40, 40])
ultralytics.nn.modules.conv.Conv torch.Size([1, 384, 20, 20])
ultralytics.nn.modules.conv.Concat torch.Size([1, 960, 20, 20])
ultralytics.nn.modules.block.C2f torch.Size([1, 576, 20, 20])
ultralytics.nn.modules.head.Detect [torch.Size([1, 144, 80, 80]), torch.Size([1, 144, 40, 40]), torch.Size([1, 144, 20, 20])]2.详解DetectionModel中parse_model加载模型
在加载DetectionModel 处设置暂停点debug进入。

进入初始化加载模型的主函数parse_model,可以看到首先是获取加载模型所需的一些配置参数 args,第一个是模型的规模选择scale。

然后是模型的激活函数 act 选择。
 下面开始正式加载模型部分,遍历配置字典中“骨干网络backbone”和“头检测head”,首先判断当前模块是不是torch中已经定义好的标准模块还是在全局的global中定义的自定义模块,再根据模型规模中选择得到的 width 变量定义当前模块的数量 n(也就是网络的深度)。
下面开始正式加载模型部分,遍历配置字典中“骨干网络backbone”和“头检测head”,首先判断当前模块是不是torch中已经定义好的标准模块还是在全局的global中定义的自定义模块,再根据模型规模中选择得到的 width 变量定义当前模块的数量 n(也就是网络的深度)。

已知模块类型——Conv,模块参数——yaml配置定义后,就可以使用nn.Sequential 堆叠生成模块网络层级结构了,只需将模块参数列表args逐一(*args)传入模块Conv即可。如果不只一层模块,*(m(*args) for _ in range(n)) 将按n的数量将模块列表堆叠。

对于配置中的每个不同层级的不同模块都是m定义的一种类,最后这里类按层级叠加到 layers 中,这样就完成了完整模型的加载。(下方黄字笔误:23层)

最后配置文件中所有的层(23层)循环加载完毕后,将其配置到DetectionModel的model属性中,这样一个yolov8m模型就加载完毕了,后续就可以对其把玩了——进行预测部署,或模型训练,或网络架构修改等。

3.自定义模型接入ultralytics框架
研究其模型加载过程源码的一个好处是,ultralytics是一个非常友好的机器学习平台,其内部写好的训练逻辑(包括遗传算法,锚框算法等)或者平台其他接口都是十分丰富好用的。这样可以省去项目很多任务量,我们只需定义好我们自己的网络层级结构,写入配置yaml文件,在稍微修改一下其中一些模型加载逻辑,就可以实现自定义模型的训练部署等任务。
当然 ultralytics 自身也定义了很多内置官方模型yaml配置文件,在源码ultralytics/cfg/models 下,可放心食用。

(1) 一个极简尝试
这里做一个极简的测试,主要记录如果自定义模型可能需要修改模型加载的代码位置。
如果只想保留yolov8m模型中提取特征的网络层,即backbone网络。首先要新写一个模型网络的yaml配置文件

此时如果直接加载模型,由前面解析源码可知,会报找不到“head”层的错误,因此,加载模型的源码需要修改,我们可以直接复制过来只修改需要的部分(这里删除d["head"]就可以了,如果其他自定义模型,建议这里直接改为d)。parse_model和DetectionModel都在ultralytics/nn/task.py 文件中,记得import包也要复制过来,我偷懒选择直接全部import复制。还要添加一个导入BaseModel的import。


运行查看打印模型信息,确实只加载了骨干网络backbone。



















 3626
3626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









