







发表期刊:2024ECCV
论文概述:现有方法通过利用视觉语言模型(VLM)(诸如CLIP)的开放词汇识别能力来增强开放词汇对象检测。然而,两个主要的挑战出现:(1)概念表示的不足,在CLIP的文本空间中的类别名称缺乏文本和视觉知识。(2)对基本类别的过度拟合倾向,在从VLM到检测器的转移过程中,开放词汇知识偏向于基本类别。为了应对这些挑战,提出了语言模型指令(LaMI)策略,该策略利用视觉概念之间的关系,并将其应用于一个简单而有效的DETR类检测器,称为LaMI-DETR。LaMI利用GPT来构建视觉概念,并采用T5来研究跨类别的视觉相似性。这些类别间的关系细化概念表示,并避免过度拟合的基础类别。
一、研究背景及意义
开放词汇对象检测(OVOD)旨在从广泛的类别中识别和定位对象,包括推理过程中的基本类别和新类别。然而,现有的方法存在两个挑战:(1)概念表示。大多数现有的方法表示使用CLIP文本编码器的名称嵌入的概念。然而,这种概念表征方法在捕捉类别之间的文本和视觉语义相似性方面存在局限性,这有助于区分视觉混淆类别和探索潜在的新对象;(2)过拟合到基本类别。尽管VLM在新类别上表现良好,但在开放词汇检测器的优化中仅使用基本检测数据,导致检测器对基本类别的过拟合。因此,新的对象很容易被视为背景或基本类别。
(1)对概念表示不足很好理解,多数方法都是通过 CLIP 文本编码器生成的名称嵌入表示概念,但是这种方法无法捕捉到类别间的文本语义相似性与视觉语义相似性。
(2)对基本类别过拟合理解:模型在训练阶段过度学习基础类别(已标注的常见类别)的特征,却无法泛化到新类别,导致遇到未见过的物体时,错误沿用基础类别的判断逻辑(当出现浣熊新类别时由于模型没学过浣熊的特征,且过度依赖基础类别经验,可能将浣熊误判为 “猫”)

图解释:
(a)Name & CLIP TE:利用 CLIP 文本编码器处理类别名称,未挖掘两者的视觉特征(如颜色、体型差异),难以区分视觉上相似的类别,概念表示较浅层。
(b)Name & T5:通过 T5 模型处理类别名称,仍局限于名称本身的信息。
(c)Visual Concept & T5:结合视觉概念描述,通过 T5 生成包含视觉细节的文本特征。
!T5模型:是谷歌在 2020 年提出的预训练语言模型,核心创新在于将所有自然语言处理(NLP)任务统一为 “文本到文本” 的生成问题
在概念表示的问题方面:
(1) 与语言模型相比,VLM的文本编码器缺乏文本语义知识。如图1a所示,仅依赖于来自CLIP的名称表示会集中于字母组成的相似性,忽视了语言背后的层次性和常识理解。这种方法对分类聚类不利,因为它未能考虑类别之间的概念关系。
(2) 基于抽象类别名称或定义的概念表示,未融入视觉特征。如图 1 (b) 所示,海狮(sea lions)与儒艮(dugongs)在视觉上具有相似性,但若仅用类别名称表示概念,会将它们划分到不同簇中。这种仅依赖名称的表征方式,忽略了语言本可提供的丰富视觉语境 —— 这些语境本能够帮助模型发现潜在的新物体,提升对视觉相似类别差异的识别能力。
对基础类别的过拟合问题方面:
为充分利用VLM的开放词汇能力,采用一个冻结的CLIP图像编码器作为主干网络,并利用来自CLIP文本编码器的类别嵌入作为分类权重。论文认为,检测器训练应发挥两个主要功能:首先,区分前景和背景;其次,保持CLIP的开放词汇分类能力。然而,仅在基础类别注释上进行训练,而不结合额外策略,往往导致过拟合:新对象常常被错误分类为背景或基础类别。
本文研究目标:提高开放词汇检测器,通过增强概念表示和调查类别间的关系
二、方法
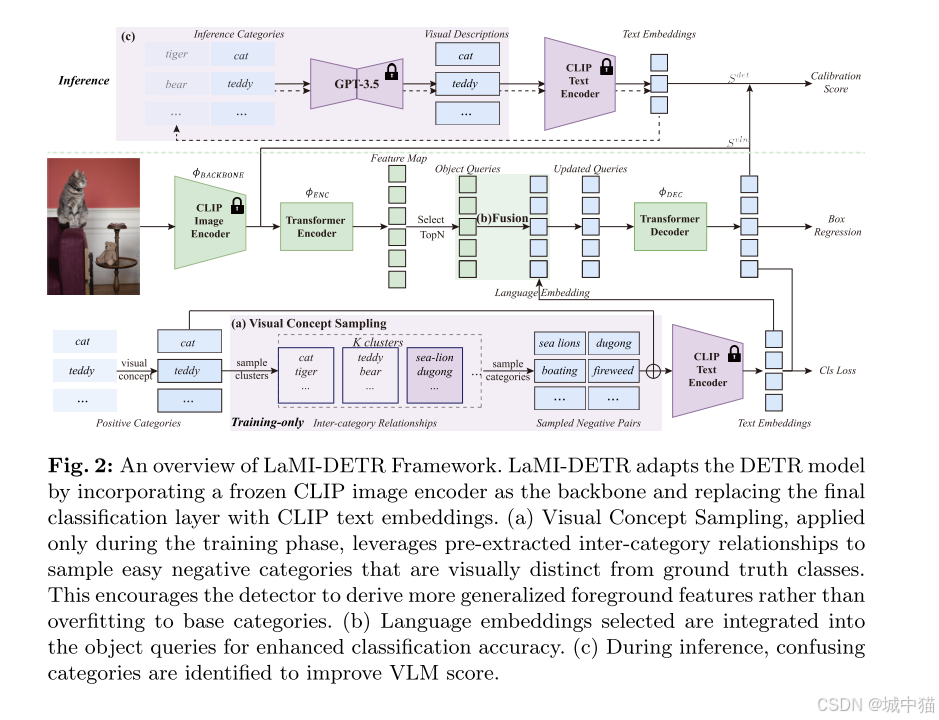
文章中方法主要为语言模型指令+DETR,下面先详细介绍语言指令模型细节,最后介绍模型整体架构、推理和训练。
首先是语言指令模型:与仅依赖VLMs的视觉-语言对齐的先前方法不同,论文旨在通过增强概念表示和研究类间关系来改善开放词汇检测器。该部分设计通过语言模型(如 GPT-3.5 和 T5)提取类别间的视觉概念关系,解决开放词汇检测中的 概念表示不足 和 过拟合 问题,提升模型对易混淆类别和新类别的检测能力。
在训练阶段,这些模块的协同工作:类别间关系提取生成的聚类信息用于视觉概念采样,选择负样本对;语言嵌入融合将更新后的文本嵌入融入查询特征,提升特征表示;易混淆类别处理在训练时可能生成区分性描述,帮助模型学习类别差异。
在推理阶段,类别间关系提取和易混淆类别处理生成的文本嵌入用于校准 VLM 分数,语言嵌入融合后的查询特征帮助预测边界框,视觉概念采样可能影响负样本的选择,从而优化模型的泛化能力。
(1)类别间关系提取(Inter-category Relationships Extraction)
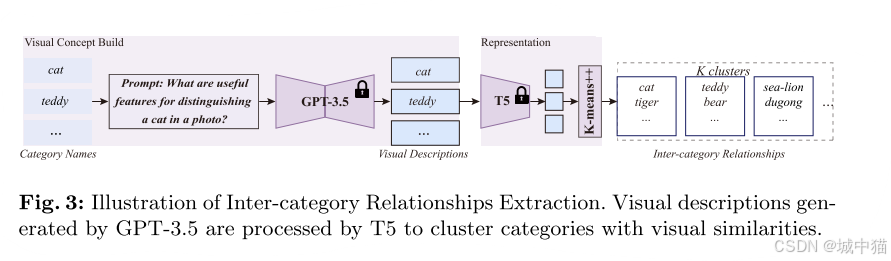
使用 GPT-3.5 为每个类别生成细粒度视觉描述 d(如形状、颜色、纹理)。将视觉描述 d 输入 T5 模型,生成文本嵌入 e。通过 K-means 聚类将嵌入 e 划分为 K 个簇,同一簇内的类别视为视觉相似。为后续的视觉概念采样和语言嵌入融合提供类别间的视觉相似性依据。
K-means聚类:一种经典的无监督学习算法,旨在将数据划分为 K 个簇,使同簇数据相似度高、异簇差异大
在 LaMI-DETR 中的应用:对 T5 模型生成的类别视觉描述嵌入进行聚类
确定簇数 K。
随机初始化质心,计算嵌入与质心的距离,划分簇。
迭代更新质心,直至收敛。
(2)语言嵌入融合
该部分通过融合视觉特征与文本语义,增强模型对开放词汇类别的理解,提升分类准确性。语言嵌入融合模块位于 Transformer 解码器 之后。首先生成 查询特征,Transformer 解码器生成查询特征 {qj},每个查询对应图像中的一个潜在物体。文本嵌入获取最初用类别名称的 CLIP 文本嵌入 {tj}
在更新阶段将视觉描述 dj 输入 CLIP 文本编码器,生成更丰富的文本嵌入 {tj′}。最后将查询特征与文本嵌入逐元素相加,得到融合后的特征 {qj⊕tj′}。
这里的初始和更新怎么理解呢:
初始阶段:CLIP 文本编码器对 “tiger” 名称生成嵌入。
更新阶段:输入视觉描述 “striped fur, orange coat”,生成更细致的嵌入。
qj⊕tj′ 结合了视觉特征(条纹)和文本语义(“striped fur”),增强模型对 “tiger” 的判别能力。
语言嵌入融合通过 动态更新文本嵌入 和 元素级加法操作,有效增强了视觉特征的语义表示
(3)易混淆类别处理(Confusing Category)
在 CLIP 文本空间中,基于余弦相似度为每个类别 c 找到最相似的类别 cconf。之后生成区分性描述,要求 GPT-3.5 生成强调差异的描述 d′,通过 CLIP 文本编码器生成新嵌入 tc′′,更新分类权重 TCLS′′。最后使用校准 VLM 分数用新权重计算 VLM 分数,强化对易混淆类别的区分。
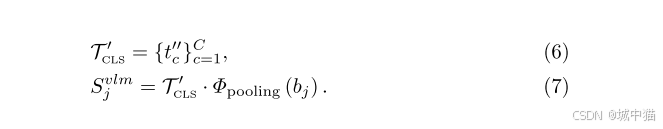
(4)视觉概念采样(Visual Concept Sampling)
基于聚类结果,对每个正类别 c,从不同簇中采样负类别 c′。调整类别出现频率 pc,避免同一簇内的负样本:
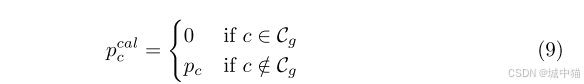
随机选择 Cfed 个类别计算损失,平衡类别分布。强制模型学习通用前景特征,减少对基础类别表面特征的过拟合。
文章图1视觉采样是什么,为什么要在clip之前进行视觉采样进行分类:
(1)挖掘训练数据的内在结构:视觉概念采样基于训练数据中的正类别,通过聚类、负样本对生成等操作,主动挖掘类别间的视觉语义关联(如同簇类别共享的视觉特征、不同簇类别的差异)。这一过程不依赖 CLIP 的预训练知识,而是从训练数据本身出发,让模型学习类别组织的底层逻辑.
(2)CLIP 虽擅长处理文本 - 图像关联,但其概念表示依赖自身预训练数据,可能无法精准捕捉当前训练数据中细粒度的类别关系
三、实验
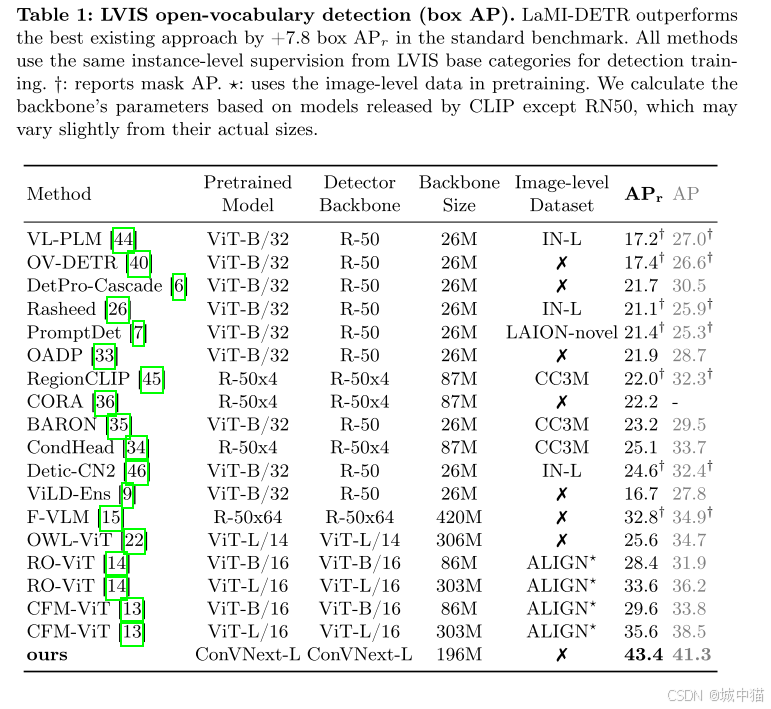
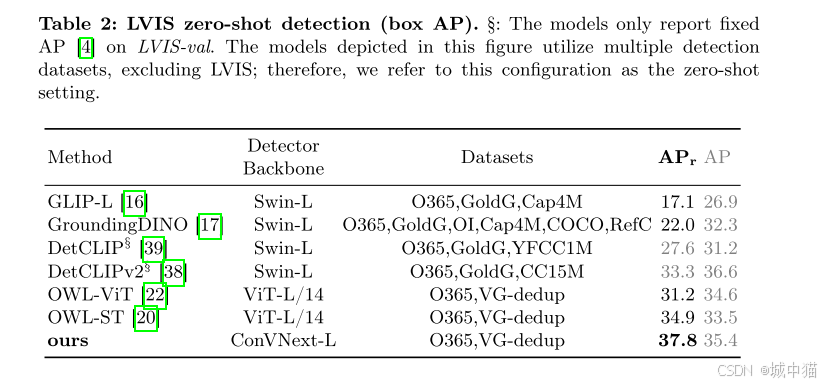
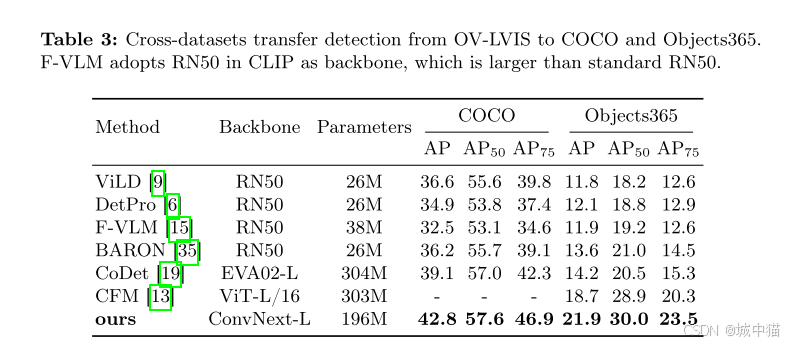 消融实验:
消融实验:
仅使用基础模型(无语言嵌入融合)时,APr=32.2。添加语言嵌入融合(公式 4)后,APr 提升至 33.0,验证了融合操作的有效性。
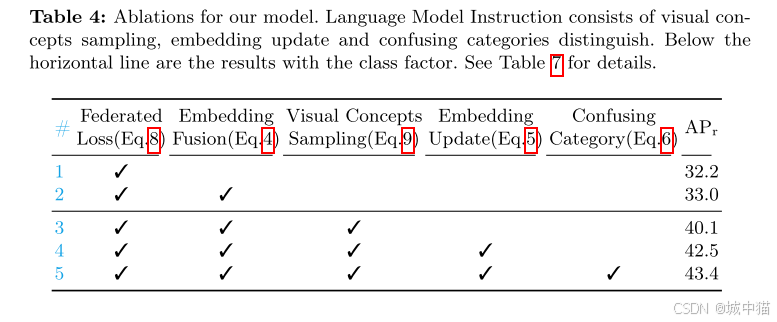
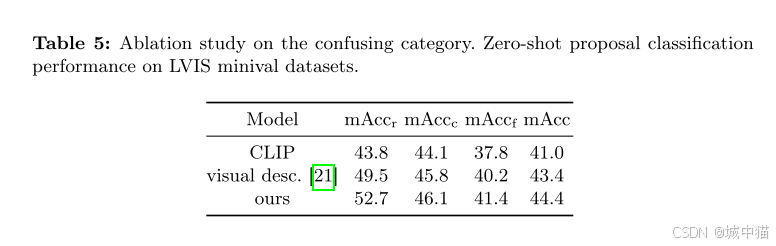
语言嵌入融合结合易混淆类别处理,使 “Mean Accuracy” 从 41.0% 提升至 44.4%,表明对相似类别的区分能力显著增强。


















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









