 Taming-3DGS:高效可控的3D高斯溅射优化
Taming-3DGS:高效可控的3D高斯溅射优化







Sigraph 2024 3DGS加速&压缩新工作Taming-3DGS论文及代码解读
写在前面:如果想了解更多关于3DGS的加速压缩新工作,可以关注笔者的Github仓库:Awesome-3DGS-Compress-Accelerate。
一、论文简介 🌟
1.1 Taming-3DGS基本信息
- 📖 题目:DashGaussian: Optimizing 3D Gaussian Splatting in 200 Seconds
- 🏫 单位:Carnegie Mellon University;Graz University of Technology;International Institute of Information Technology, Hyderabad;
- 🌍 主页:https://humansensinglab.github.io/taming-3dgs
- 🀄️ 论文摘要:3D Gaussian Splatting以其快速、可解释和高保真的渲染改变了新视图合成领域,然而其资源需求限制了它的可用性。特别是在资源受限的设备上,训练性能迅速下降,且往往因模型内存消耗过大而无法完成。该方法收敛时会产生数量不定的高斯体——其中许多是冗余的——导致渲染速度不必要地变慢,并阻碍了其在期望固定大小输入的下游任务中的应用。为了解决这些问题,本论文应对了在预算限制下训练和渲染3DGS模型的挑战。本论文使用了一种引导式的、纯增量式的致密化过程,将致密化导向能提高重建质量的高斯体。利用基于分数的致密化方法以及衡量高斯体贡献的训练时先验,模型大小以可控的方式持续增加,直至达到精确预算。本论文进一步解决了训练速度障碍:通过仔细分析3DGS的原始流程,本论文推导出了更快且数值等效的梯度计算和属性更新解法,包括一种用于高效反向传播的替代并行化方案。本论文还提出了在适当时既保持质量又能进一步减少训练时间的近似方法。综合来看,这些改进产生了一个稳健、可扩展的解决方案,具有更短的训练时间、更低的计算和内存需求以及高质量。评估表明,在预算受限的设置下,本论文在获得与3DGS具有竞争力的质量指标的同时,实现了模型大小和训练时间4-5倍的缩减。在预算更充裕的情况下,本论文测得的质量超越了原始方法。这些进展为移动设备等受限环境中的新视图合成打开了大门。

1.2 Taming-3DGS主要贡献
新视图合成(NVS)能够从多视图数据集预测未见视图,使用户仅需少量易于获取的照片即可自由探索3D内容。最先进的NVS解决方案能够产生照片级真实感的结果,为电子商务、娱乐和沉浸式通信提供高质量的用户体验。近期,NVS方法也已成为高质量3D表面重建的强大辅助工具。NVS领域的研究广泛涵盖了从基于图像和网格的方法到纯神经表示的各种方法。在这一领域中,3D Gaussian Splatting因结合了高质量图像合成、快速实时渲染和适宜的训练时间而日益普及。3DGS利用显式的、基于点的场景表示、可微渲染流程以及GPU优化的光栅化,以高帧率实现了照片级真实感的图像合成。然而,其优化过程难以控制;尽管该过程包含多种启发式策略,但往往造成资源浪费,并可能导致过度的内存开销。
从稀疏的输入点集开始,许多最终优化得到的图元是冗余的:在那些本可以用更少高斯体就足够的区域,高斯体往往只做出微小的贡献,而其他区域则仍然重建不足且模糊。这种高斯图元的低效分布不仅影响训练时间,还影响了该表示法的实用性。一个典型的3DGS模型对于单个无界场景可能会产生数百万个高斯体,并需要超过1GB的磁盘空间。如此巨大的内存占用和几何负载使得低端设备上的实时渲染变得困难,阻碍了其在网络流媒体或嵌入式系统上的AR/VR等受限环境中的应用。
3DGS的内存消耗不仅过大,而且难以预测:即使从相同数量的输入点开始,两个重建场景在高斯体数量(进而影响所需存储空间)上的差异也可能高达一个数量级。这阻碍了其在需要固定输入数量的下游应用(例如分类器网络)中的可用性,使其无法利用这种本应高效且显式的表示形式。同样,训练时间虽然尚可接受,但波动剧烈,且总体上未能体现3DGS极高的渲染速度。
为了驯服3DGS,论文提出在致密化过程中进行严格调节,以对其资源消耗提供严密控制。给定用户定义的模型大小,论文确保一种确定性的训练调度,能够产生确切数量的期望高斯体。为了利用更少的图元(平均减少5倍)实现高质量,论文解决了原始方法分布次优和高冗余的问题。论文提出了一种替代的致密化算法,该算法由灵活的、基于分数的高斯图元采样引导。论文建议的在预算限制下实现高质量的评分方案,结合了本论文为每个高斯体收集的、跨越多个采样训练视图的损失相关分量。致密化根据预定义预算,在得分最高的高斯体附近进行。与先前工作相比,论文的致密化使用了一种纯增量式的调度:在训练期间不需要对高斯体进行大量的修剪或剔除。因此,本论文避免了优化过程中可能违反用户硬件或预算约束的不必要峰值。
3DGS的冗余性并不仅仅局限于其最终的图元分布,因此论文仔细分析了训练流程中各个步骤的时间成本和质量权衡,并提出了替代的、更高效的方案。这包括重新审视反向传播的并行化机会,本论文将其从逐像素方法改为逐溅射方法。本论文实现了平均4-5倍的显著加速,在消费级硬件上将训练时间缩短至仅需几分钟。论文对驯服3DGS的贡献可以总结如下:
- 一种纯增量式、受预算约束的优化方法,能够完全控制模型大小和资源;
- 一种灵活的基于分数的致密化框架,允许针对特定用例的行为和优先级设置,例如通过指示重要的感兴趣区域;
- 使用等效和近似的替代方法,对相关训练步骤进行分析并实现显著加速。
二、Taming-3DGS方法论 🍀
论文方法概述如图2a所示。利用SfM点云作为初始化,结合预定的致密化调度,从校准的多视图图像中训练基于3DGS的模型。原始3DGS致密化算法不断向具有高位置梯度的区域添加图元(细节),分裂大的高斯体,克隆小的高斯体,并移除透明的高斯体。论文用一种基于可控采样的、执行频率较低的过程替换了该模块。每个阶段添加的新高斯体的最大数量是预先确定的:尽管论文的方法模仿了原始3DGS的增长曲线,但高斯体的峰值(及最终)数量完全由提供模型大小限制的用户控制(图2b)。为了最大化每个高斯体的质量,本论文的致密化过程由基于分数的排名引导,并采用高不透明度的高斯体来增加图元的表现力。此外,通过针对原始流程主要瓶颈提出的几项改进,包括一种更快、数值等效的反向传播解法,训练时长得到了显著减少。综合来看,这些措施产生了一种具有高可控性、灵活性和高性能的优化方案。

2.1 可预测的模型增长(Predictable Model Growth)
在整个优化过程中,3DGS通过添加高斯图元来解决重建不足的区域,从而不断致密化其表示,然而每个阶段添加的图元数量是基于简单的阈值操作决定的,无法控制渐进或最终的数量,这种进化自动机制虽然有效,但会导致难以预测且往往过大的模型尺寸以及波动的训练时间。
为了定义一种更简单、但同样有效且完全可预测的增长模式,论文研究了3DGS在MipNeRF360数据集室外场景中的致密化行为。图2b展示了使用原始方法训练时,每个场景中高斯体总数随训练进行的变化情况,请注意曲线已在初始和最终3DGS图元数量之间进行了重新归一化。论文发现,每一步增加的高斯体数量遵循二次递减的趋势。论文利用这一模式来确定每一步增加图元的调度,使用一条从SfM初始化开始并在用户定义的预算处精确达到峰值的抛物线:
A ( x ) = B − S − k N N 2 x 2 + k x + S ; k = 2 ( B − S ) N , ( 2 ) A(x) = \frac{B - S - kN}{N^2}x^2 + kx + S; \quad k = \frac{2(B - S)}{N}, \quad (2) A(x)=N2B−S−kNx2+kx+S;k=N2(B−S),(2)
其中 N N N 是致密化步骤的数量, B B B 是最终数量(预算), S S S 是初始化时SfM点的数量。由于3DGS随着时间推移会修剪低不透明度的高斯体,直接遵循累加调度产生的图元可能少于给定目标。为了避免这种情况,论文转而计算当前数量与累积目标数量之间的差值,并对相应数量的图元进行致密化。第5节展示了该方案的有效性以及较低预算限制导致的平滑质量下降。
2.3 带采样的可控致密化(Steerable Densification with Sampling)
原始3DGS方法认为,高斯体上的高位置梯度表明其附近采样不足,因此这些高斯体会被定期致密化,方式是克隆或分裂(取决于它们的大小)。前沿研究将3DGS优化过程重构为一系列随机朗之万梯度下降(SLGD)更新,在任何时刻,优化后的高斯体集合都可以解释为来自与3DGS总体损失相关的似然分布的样本。获得完整、高保真的重建需要一种能够微妙平衡优化与探索的解决方案,让图像损失也引导致密化过程似乎是直观的:高损失可能表明需要更密集的采样或额外的探索。
为了保持一种既可控又可解释的致密化过程,论文提出了一种灵活的解决方案,将图像损失等显著指标直接融入到该过程中。这通过两个关键特性得以实现:一种基于分数的、可定制的致密化候选者采样方法,以及显著降低的致密化频率。前者结合了诸如损失之类的显著逐高斯和逐像素指标,以决定每个图元的致密化概率。
降低致密化频率的动机在于损失、样本放置和优化之间的相互作用,一个高斯体导致高图像损失的原因通常有两个,要么是其邻域采样不足,要么是其被错误地放置,因此当利用损失进行引导时,频繁的致密化可能会导致错误放置的高斯体被重复复制,然而如果给予充足的时间和观测,3DGS会在致密化发生之前通过降低其不透明度来消除这些位置错误的高斯体。
论文以仅为3DGS五分之一的频率(即每500次迭代一次)执行致密化,给定 N N N 个相机视图集合 V = { v i } i = 1 N , M V = \{v_i\}_{i=1}^{N}, M V={vi}i=1N,M 个拟合高斯体集合 G = { g j } j = 1 M G = \{g_j\}_{j=1}^{M} G={gj}j=1M 以及N个渲染视图集合 R = { r i } i = 1 N R = \{r_i\}_{i=1}^{N} R={ri}i=1N,论文评估一个评分函数 F F F,该函数由逐高斯图元属性和投影的逐像素指标参数化,这涉及以下内容:
1、确定逐视图显著性矩阵 S v S_v Sv:对于每个视图 v v v,该矩阵指示那些可能采样不足(即具有高损失)或包含高频信息的像素,此外该函数还能实现对感兴趣区域的优先处理:
S v = 1 R O I ⊙ ( λ 1 L 1 ( v , r v ) + λ 2 E ( v ) ) , v ∈ V , ( 3 ) S_v = \mathbb{1}_{ROI} \odot (\lambda_1 L_1(v, r_v) + \lambda_2 E(v)), v \in V, \quad (3) Sv=1ROI⊙(λ1L1(v,rv)+λ2E(v)),v∈V,(3)
其中 L 1 L_1 L1是L1损失, E E E是拉普拉斯滤波器, 1 R O I 1_{ROI} 1ROI是指示感兴趣区域掩膜的二值矩阵, ⊙ \odot ⊙是逐元素乘积,而 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是超参数,在本论文的实验中均设置为0.5。
2、计算高斯分数
S
G
S_G
SG:论文计算一个全局分数向量
S
G
S_G
SG ,其中包含集合
G
G
G 中每个高斯体
g
g
g 的分数
S
g
S_g
Sg ,本论文通过评估函数
F
(
⋅
)
F(\cdot)
F(⋅) 并对所有
N
N
N 个视图进行求和来实现这一点:
S
g
=
∑
i
N
F
(
∇
g
,
c
i
g
,
1
i
g
,
D
i
g
,
S
i
v
,
B
i
g
,
z
i
g
,
o
g
,
s
g
)
,
S
G
=
[
S
g
1
,
.
.
.
,
S
g
M
]
T
,
g
j
∈
G
,
(
4
)
S_g = \sum_{i}^{N} F (\nabla_g, c_i^g, 1_i^g, D_i^g, S_i^v, B_i^g, z_i^g, o_g, s_g),\\ S_G = [S_{g_1}, ..., S_{g_M}]^T, g_j \in G, \quad (4)
Sg=i∑NF(∇g,cig,1ig,Dig,Siv,Big,zig,og,sg),SG=[Sg1,...,SgM]T,gj∈G,(4)
这里, ∇ g \nabla_g ∇g 是高斯体的位置梯度, c i g c_i^g cig 表示在视图 i i i 中被 g g g 覆盖的像素数量, 1 i g 1_i^g 1ig 是一个指示这些像素的二值矩阵, D i g D_i^g Dig 是一个保存了每个像素到 g g g 中心距离的矩阵, B i g B_i^g Big 包含每个像素对于 g g g 的混合权重,属性 z i g z_i^g zig、 o g o_g og 和 s g s_g sg 分别构成了 g g g 在视图 i i i 中的深度、不透明度和尺度。
S G S_G SG 代表了为收敛到最终场景而对每个高斯体进行重采样的需求,并作为论文基于分数的致密化的基础。算法1提供了关于此过程的更多细节。对于 F F F 的选择,本论文使用中位数缩放限制每个参数的范围以去除离群值,随后与 i i i 的光度损失相乘。经此缩放的参数随后被累加成加权和,其系数可针对特定用例进行调整。在下文中,本论文将解释每个参数(以及本论文建议的权重)在利用少量高斯体实现高质量方面的作用。
∇ g \nabla_g ∇g (50):论文采用了Kerbl等人提出的位置梯度模长作为致密化标准,根据作者的说法,高 ∣ ∇ g ∣ 2 |\nabla_g|_2 ∣∇g∣2可以被解释为3D不连续检测器,尽管已被证明有效,但仅依靠它通常会导致资源浪费和产生多余的高斯体。
c i g c_i^g cig (0.1): g g g的像素数量充当了那些倾向于拥有大投影的图元的指标,这些大投影会导致渲染图像呈现模糊的外观。
D i g D_i^g Dig (50):即使只覆盖少量像素的溅射在屏幕上也可能表现为细长的“条状物”,本论文通过对所覆盖像素到 g g g中心的累积距离进行评分,来鼓励对它们进行致密化。
S i v S_i^v Siv (10):本论文对由 g g g覆盖的像素的累积逐像素显著性分数进行加权(即 S i v S_i^v Siv与 1 i g 1_i^g 1ig的逐元素乘积之和),这使得先前计算的显著性能够直接引导致密化。
B i g B_i^g Big (50):渲染中使用的逐像素混合权重之和指示了具有高贡献度的高斯体,对它们进行致密化最有可能导致场景外观和质量发生可见的变化。
z i g z_i^g zig (5):每个高斯体的深度使本论文能够区分前景和背景。值得注意的是,对于视锥体之外的所有高斯体,该值为0:因此,它作为 g g g在拍摄中的可见性及其到相机的平均距离的综合度量,这种方式优先考虑致密化经常被观测到的图元,同时也不忽略极少被看到的背景高斯体。
o g o_g og (100):本论文在不透明度上赋予高权重,旨在引导致密化过程避开低不透明度的高斯体,因为低不透明度通常是漂浮物的特征,或者是优化过程目前正在逐步淘汰的高斯体的特征。
s g s_g sg (25):过大的高斯体——即使在训练期间未被近距离观测——也会损害对未见视图的泛化能力,对高斯体尺度的乘积进行评分可以产生尺寸更加均匀的图元。
给定最终的分数向量 S G S_G SG和拟添加的高斯体预算目标数量 B B B,本论文通过使用 S G S_G SG作为采样权重,从所有高斯体中随机重采样 B B B个图元来执行致密化。在实践中以及所有实验中,本论文使用 N = 10 N = 10 N=10个均匀采样的训练视图来计算逐像素显著性分数。

3.3 高不透明度高斯(High-Opacity Gaussians)
虽然3DGS的基本高斯图元可以产生高质量结果,但其表达能力受到刚性高斯衰减的限制。为了解决这个问题,Kerbl等人使用了不透明度大于1的简单截断高斯体,在层次化细节层次结构中近似高斯簇的外观。本论文发现,这些高不透明度高斯体也能增强使用少量图元建模不透明表面的能力。因此,在达到训练中点(15000次迭代)后,本论文将常规的受限高斯图元转换为高不透明度高斯体。这涉及将不透明度激活函数替换为绝对值函数,并在渲染过程中将混合权重的上限截断为1。如本论文的消融实验所示,这一改变对质量指标,特别是PSNR产生了积极影响。
3.4 3DGS运行时间分析和优化(3DGS Runtime Analysis and Optimization)
为了更好地理解3DGS的性能挑战,本论文对使用PyTorch编写并带有用于可微光栅化的显式CUDA扩展的原始训练流程进行了基准测试。本论文在图3a中提供了针对多个场景、在不同训练阶段每次迭代中各高级步骤所耗时间的细分。本论文注意到,在整个训练过程中,梯度的反向传播是主要的瓶颈,随着高斯体数量的增加,紧随其后的是ADAM优化器的更新。基于这些见解,本论文提出了针对性的解决方案来加速3DGS训练。
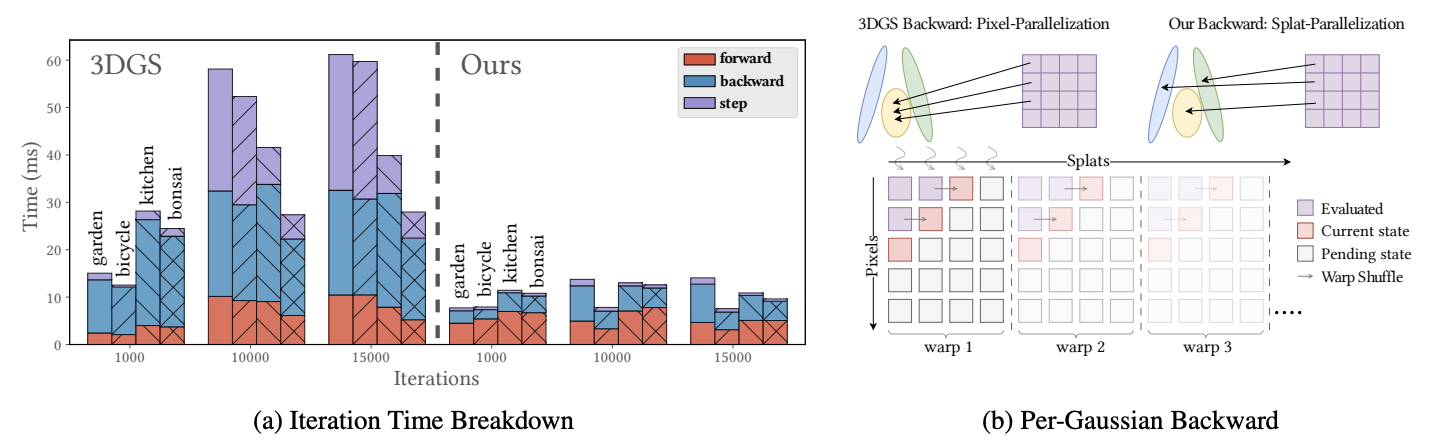
图3:(a) 在四个场景(花园、自行车、厨房、盆景)中,一次3DGS迭代的不同部分(前向传播、反向传播、优化器步骤)所花费的时间。左图:原始3DGS在不同训练阶段的分析。右图:使用本论文的预算致密化和性能优化。(b) 梯度反向传播。(上图)3DGS利用逐像素并行化进行反向传播,原子梯度加法产生频繁的冲突,从而减慢了反向传播速度,相反,本论文在投影的2D溅射上进行并行化,使得每个线程(和像素)一次只为一个高斯体做出贡献。(下图)梯度计算需要处理一组逐像素、逐溅射的值,导致对溅射⇐⇒像素状态表的隐式遍历,在前向传播期间,本论文为排序列表中的每第32个溅射存储像素状态,而在反向传播中,本论文将溅射分为大小为32的桶(buckets),每个buckets 被调度到一个CUDA线程束中,线程束使用束内洗牌以低成本生成它们分担的状态表。
3.4.1 基于Per-Splat并行化的反向传播(Backpropagation with Per-Splat Parallelization)
在原始3DGS反向传播中,梯度是从像素传播到高斯体上的,总梯度计算涉及计算许多逐像素、逐溅射的数值,然后通过归约在全局范围内进行累加。Kerbl等人采用了一种自然的方法,即将线程映射到像素,并从后往前遍历按深度排序的溅射。在一个图块内,每个线程按逆混合顺序处理溅射,计算逐像素梯度分量,并将其原子地加到对应溅射的累积梯度上。虽然这种做法是正确的,但这导致多个线程争夺对同一位置的访问,从而导致原子操作串行化,如图3b所示。每个高斯溅射为其属性维护大量梯度这一事实,进一步加剧了这种归约的开销。
本论文提出了一种解决方案,其中每个图块使用基于2D溅射而非像素的并行化方案,这种新方法允许线程维护逐溅射状态,并持续交换由透射率T和累积颜色RGB组成的逐像素状态(这与存储逐像素信息并交换更大的逐溅射数据形成对比)。忽略边界情况,让我们假设一个简化的设置,其中线程数、像素数和溅射数均为N,在每个时间点,线程i为溅射i计算梯度分量,为此它需要每个像素j在混合了前i个图元后的状态。在前向传播期间,每个线程在自动微分上下文中每隔N个溅射存储一个逐像素状态以供反向传播使用,从而产生可用的起始状态(0, j), (N, j), …∀j,利用这些状态,图块中的每个线程在反向传播开始时生成像素状态(i, j),然后线程通过快速协作共享来交换像素状态,在每一步中,线程i + 1应用默认的Alpha混合逻辑,将其接收到的(i, j)转换为(i + 1, j),并将此信息融入梯度中,更多细节请参考图3b。
本论文还观察到,由于遮挡的存在,遍历每个图块的深度排序溅射列表的尾部往往变得冗余,这种情况在前向传播中得以避免,因为前向传播会在饱和时终止。为了在反向传播中也能利用这一点,本论文跟踪整个图块中的最后一个贡献者,并利用它来跳过整组溅射与图块的配对。最后,本论文采用了Radl等人提出的更严格的剔除策略来降低整体光栅化工作负载,从而在前向和反向传播中最小化冗余溅射。
图3a揭示了随着高斯体数量的增加,ADAM更新占据了大量时间。在这些更新中,球谐函数(SH)——在59个优化的高斯属性中占据48个——是主要的时间消耗来源。为了解决这个问题,本论文将除首项以外的所有频带切换为批量更新调度,即每16次迭代仅执行一次ADAM优化步骤。原始3DGS实现在光栅化之前将第0阶SH频带(即基础颜色)与更高阶频带合并为一个单一的张量,这在前向传播过程中消耗了出乎意料的大量时间。本论文通过扩展可微光栅化器以从独立的张量加载高斯SH系数来避免这一问题。3DGS的损失计算涉及评估SSIM指标,该指标配置为使用11×11高斯核卷积:由于高斯核本质上是可分离的,本论文提出使用优化的CUDA核,通过两个连续的1D卷积来执行可微2D卷积。此外,本论文使用一个融合核来基于卷积结果评估SSIM指标。这加速了损失计算,并且在优化的高斯体数量相对于图像分辨率较低时(即在预算受限的训练情况下)效果尤为显著。这些措施——连同本论文的逐溅射反向传播——可作为原始3DGS的即插即用替换方案。除修改后的SH更新调度外,上述更改产生的结果与3DGS完全等效。本论文的实验表明,这些措施显著缩短了3DGS的训练时间,并且性能比最近发布的gsplat 1.0版本高出1.5到2倍。本论文在https://github.com/nullptr81/3dgs-accel提供了这些优化的源代码。
三、Taming-3DGS论文实验部分 🧪
待补充。
四、Taming-3DGS代码解读 💻
待补充。
写在最后
由于笔者🖊️精力有限且本文更多的目的是通过📒博客记录学习过程并分享更多知识,因此文中部分描述不太具体,如有不太理解💫的地方可在评论区👀留言。非特殊赶deadline⏰或假期⛱️期间,笔者会经常上线回复💬。如有不便之处,请海涵~
如果想了解更多关于3DGS的加速⏰压缩⚡️新工作,可以关注笔者的Github仓库:Awesome-3DGS-Compress-Accelerate。
另外,创造不易,转载请注明出处💗💗💗~

















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









