










第一篇论文:Attention Is All You Need 2017
简介
全新的网络架构Transformer,完全基于注意力机制,不包含递归和卷积,应用在机器翻译上。
注意力机制已经成为序列建模和转导模型的组成部分,允许对依赖项进行建模,无需考虑在输入和输出序列中的距离。
Transformer是一种避免重复的模型架构,完全依赖注意力机制来绘制输入和输出之间的全局依赖关系。
平均注意力加权位置降低了有效分辨率,使用多头注意力来抵消这种影响。
注意力机制概念和分类:
对于模型的每一个输入项,可能是图片中的不同部分,或者是语句中的某个单词分配一个权重,这个权重的大小就代表了我们希望模型对该部分一个关注程度。这样一来,通过权重大小来模拟人在处理信息的注意力的侧重,有效的提高了模型的性能,并且一定程度上降低了计算量。
分为三类:软注意(全局注意)、硬注意(局部注意)、自注意(内注意)
(1)软注意:对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
(2)硬注意:对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
(3)自注意:对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
自注意力:将单个序列的不同位置关联起来计算序列表示的注意力机制。
自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
Transformer是第一个完全依赖自注意力来计算输入和输出表示而不使用RNN或CNN的转换模型。
模型架构
编码器-解码器
Transformer对编码器和解码器使用堆叠的自注意力和逐点卷积层,如图所示:
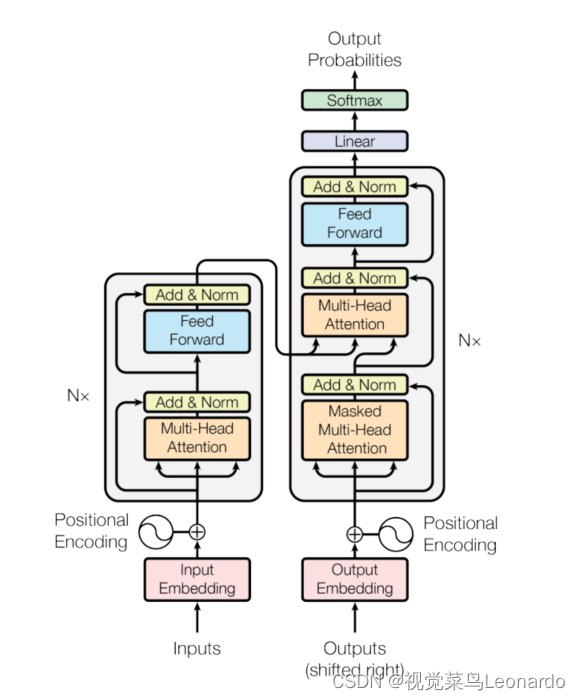
编码器(左)有两层子层,第一个是多头自注意力机制,第二个是全连接前馈网络,两个子层之间使用一个残差连接,然后进行归一化,每个子层的输出为:LayerNorm(x+Sublayer(x))。
解码器(右)与编码器相似,但多出了第三个子层,该子层对编码器堆栈的输出执行多头注意力。解码器同样引入了残差连接块,修改了解码器堆栈中的自注意力子层。
注意力
***********************************************************************************************************
***********************************************************************************************************
***********************************************************************************************************
转载:第四周(2)自注意力机制(Self-Attention) - 知乎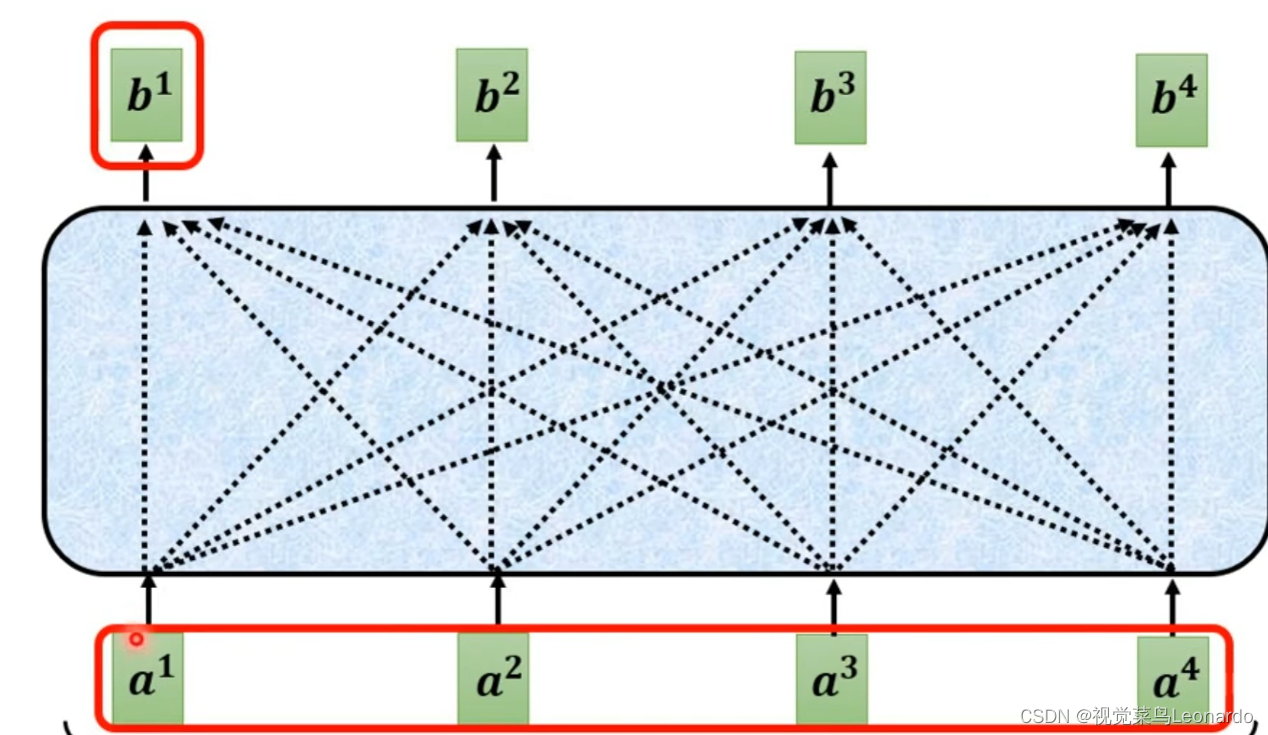

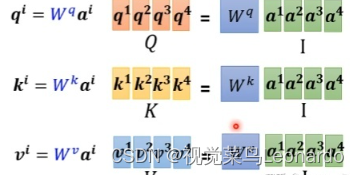

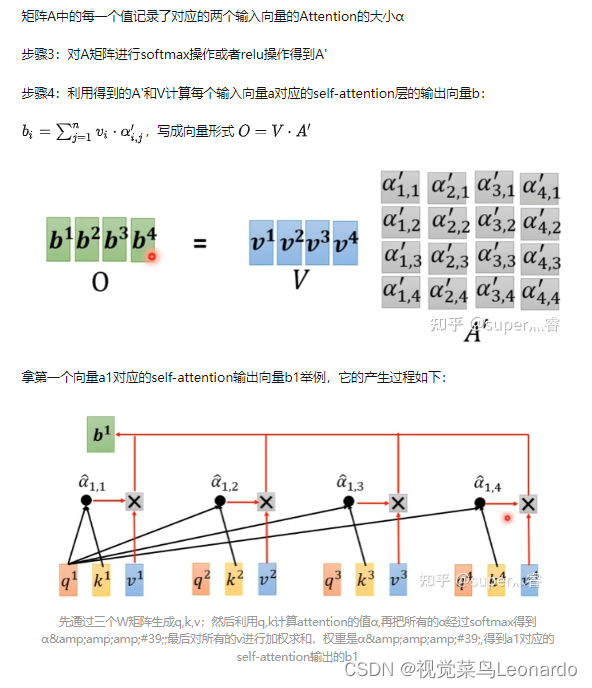
注意力函数可以描述为将查询和一组键值对映射到输出,query(Q,查询)、keys(K,键)、values(V,输出)。
***********************************************************************************************************
***********************************************************************************************************
***********************************************************************************************************
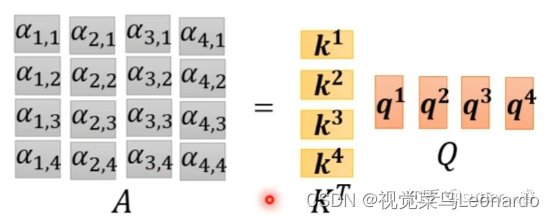
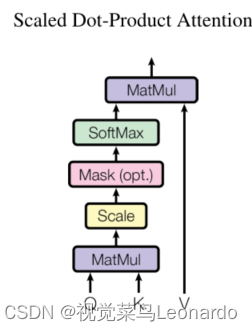
按比例缩放的点积注意力:
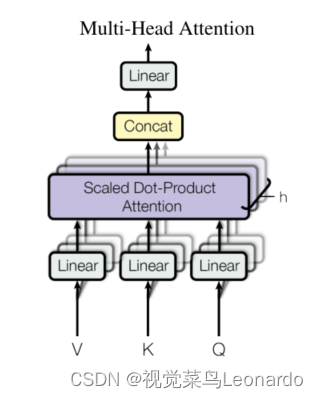
多头注意力由多个并行运行的注意力层组成:
未完………………………………………………………………………………………………
第二篇论文:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(Vision Transformer)
在计算机视觉中,注意力要么与卷积网络结合使用,要么 用于替换卷积网络的某些组件,同时保持其整体结构不变,论文表明注意力并不是完全依赖于CNN,直接应用于图像块序列的春变换器可能在图像分类任务上表现更好,设计了全新的网络:Vision Transformer(VIT)。
为了将Transformer引入计算机视觉,文章将图像拆分为块,并提供这些块的线性嵌入序列作为Transformer的输入,图像块的处理方式与NLP中的单词相同,利用可监督方式来训练模型。
在ImageNet上训练时,准确率比同等大小的ResNet低几个百分点,说明Transformers对于CNN缺乏对数据归纳总结的能力,缺少CNN的一些特性——平移特效性和局部性,需要大量的数据集。
当在模型更大的数据集上训练时,Transformer的准确率要领先现阶段最先进水平。
Transformer最核心的创新点是引入了自注意力机制,在图像领域,要将自注意力应用于图像需要每个像素都关注其他每个像素。在前人的研究中,有仅在每个查询像素的局部邻域中应用自注意力,但不是全局,而这种可以完全替代卷积;另一种方式是对全局注意力采用可扩展的近似值来更加适用于图像。
与文章最相关的为
















 5938
5938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









