







 该篇文章探讨了通过分析客户数据,尤其是人口统计、金融行为和产品偏好等因素,预测客户流失的可能性。使用了LogisticRegression、DecisionTree、RandomForest和SVM等模型,并进行了特征重要性分析,以识别影响客户流失的关键驱动因素。
该篇文章探讨了通过分析客户数据,尤其是人口统计、金融行为和产品偏好等因素,预测客户流失的可能性。使用了LogisticRegression、DecisionTree、RandomForest和SVM等模型,并进行了特征重要性分析,以识别影响客户流失的关键驱动因素。
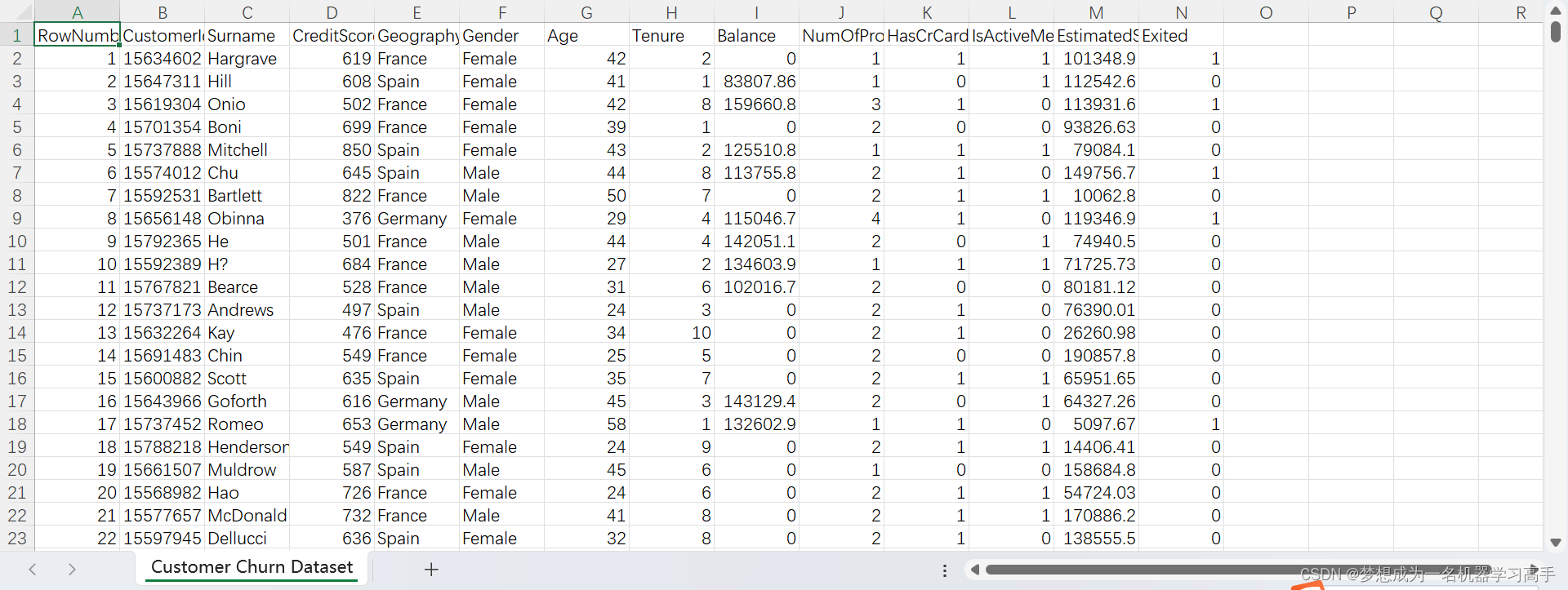
# 字段 说明 # RowNumber 每行数据的唯一标识符。 # CustomerId 客户的唯一标识符。 # Surname 客户的姓氏(出于隐私考虑,请对这些数据进行匿名处理)。 # CreditScore 客户在数据收集时的信用评分。 # Geography 客户所在的国家或地区,提供有关流失的地理趋势的见解。 # Gender 客户的性别。 # Age 客户的年龄,用于人口统计分析。 # Tenure 客户与银行合作的年限。 # Balance 客户的账户余额。 # NumOfProducts 客户购买或订阅的产品数量。 # HasCrCard 指示客户是否拥有信用卡(1表示是,0表示否)。 # IsActiveMember 指示客户是否为活跃会员(1表示是,0表示否)。 # EstimatedSalary 客户的预估工资。 # Exited 目标变量,指示客户是否已流失(1表示是,0表示否)。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder,StandardScaler
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score
from hyperopt import fmin,tpe,hp
from hyperopt import STATUS_OK
data = pd.read_csv('Customer Churn Dataset.csv')
pd.set_option("display.max_row",1000)
pd.set_option("display.max_column",1000)读入数据,同时导入需要用到的数据库对于数据的处理,我们可以发现前三列都是类似于ID的数据,对我们数据的分析没有任何用处,因此我们将前三列数据删除。
# 来看问题 # 探索性数据分析:通过多维度客户数据的深度挖掘,揭示潜在关联、趋势与异常,直观呈现客户特征与流失风险之间的内在关系。 # 客户细分:依据客户的人口统计特征、金融行为及产品偏好等信息,划分出具有不同流失倾向的群体,为精细化营销与服务策略提供依据。 # 流失预测建模:利用包含目标变量(Exited)的数据集训练预测模型,准确评估每个客户的未来流失概率,为预防性干预措施提供精准导向。 # 特征重要性分析:计算模型中各特征的贡献度或重要性得分,揭示影响客户流失的关键因素。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









